1. 引言
股票市场瞬息万变,风险很高,而对股票指数的预测可以为我们从整体上把握股市的变动提供有效的信息。沪深300指数是沪深证交所联合发布,以流动性和规模作为两大选样的根本标准,是一个能反映A股市场价格整体走势的指标。所以对于沪深指数的预测具有十分重要的意义。基于支持向量机的优良性能,考虑将其应用于股市指数的预测 [5] 。
支持向量机于1995年由Cortes和Vapnik等人正式发表,由于其在文本分类任务中显示出卓越性能,很快成为机器学习的主流技术,并直接掀起了“统计学习”在2000年前后的高潮。Vapnik等人从六、七十年代开始致力于此方面研究,直到九十年代才使抽象的理论转化为通用的学习算法,其中核技巧才真正成为机器学习的通用基本技术。
支持向量机是建立在统计学习VC维理论和结构风险最小原理基础上的,根据有限的样本信息在模型的复杂性和学习能力之间寻求最佳途径,以期获得最好的推广能力的新型神经网络。随着ε不敏感损失函数的引入,支持向量机从原来只处理分类问题逐步扩展到也能胜任回归 [6] [7] 。尤为值得一提的是通过构造核函数能在无需知道映射具体形式的情况下将非线性问题映射到高维线性空间,并对支持向量机的预测性能起到决定性作用 [8] [9] 。本文希望根据金融时间序列的有关特性,结合支持向量机引入核函数来提高支持向量机算法性能,增强统计学习方法在金融时间序列预测和特征数据分类中的分析能力 [10] 。
设选定的训练样本表示为:
,在SVR中,通过线性回归来找到函数
:
.
并满足如下的优化问题:
s.t.
其中,
表示线性近似的参数。
股票指数的预测问题更多是非线性回归,将数据用映射f映射至高维空间的方法进行处理,从而在高维空间中可进行相应的线性回归,用核函数代替所涉及到的内积运算。误差的存在是被允许的。这里需要引入松弛变量
,而损失函数则采用e-不敏感函数,其定义为:
容易得到下列优化问题:
s.t.
.
转化为对偶形式:
这里
,约束为:
.
用求解此二次规划的问题得到
和
的值,综上所述可以得到的回归方程如下:
.
2. 模型建立
模型假设:假设股票市场指数每日开盘价格与前一天的开盘价、最高价、最低价、收盘价、成交量、成交金额具有一定的相关性,即把前一天的开盘价、最高价、最低价、收盘价、成交量和成交金额作为自变量,则因变量为当天的开盘价 [11] 。
如图1所示为模型实现流程图:
3. 模型实现
3.1. 数据选取
本研究获取了从2007年1月4日至2017年12月29日的共计2676个交易日的交易数据作为分析数据。假设沪深指数每日的开盘价与上个交易日的交易情况有关系,而股票交易情况主要反映在每天的开盘价、最高价、最低价、收盘价、成交量、成交金额等指标上,所以本文选择了能够反映交易情况的开盘价、最富价、最低价、收盘价、交易量、交易额六个指标,用前一天的六个指标数据情况来回归预测当天的开盘价。
选取第1个到第2675个交易日每天的开盘价,最高价、最低价、收盘价、成交量和成交金额6个指标作为模型的自变量,该模型的因变量是第2个到第2676个交易日每天的开盘价,如下图2所示为沪深300指数每天的开盘价 [12] 。
3.2. 数据预处理
从样本的历史数据可以观察到,选取的6个特征变量在数量级上差别较大,为了防止数据溢出、大值主导小值,提高模型的预测精度,本研究考虑对时间序列数据进行中值归一化处理,其转化函数为:
表示归一化的数据中的第i个数值,
为每项归一化数据中的最大值,
为每项归一化数据中的最小值,
为区间中间值这里取0为中间值,这里的区间取得是[−2, 2]。
将处理后的每日开盘价归一化结果如图3所示。
3.3. 参数优化选择
既往研究证实了不同核函数对支持向量机预测性能影响不是很大,但核函数参数的选择却严重的影响支持向量机的推广泛化能力。从已有的研究结果来看,最常用的核函数高斯核函数在大多数情况下都获得了很好的预测效果,因此本研究主要根据既往研究基础上,引用高斯核函数,利用网格捜索法算法对高斯核函数的参数g和惩罚参数c进行优化选择。
首先采用网格搜索法对高斯核参数g和惩罚参数c这两个参数进行优化,在最佳参数的基础上训练支持向量机模型。在这里的两个参数用网格捜索法进行优化的基本思想是将参数c和g的可行区间(从小
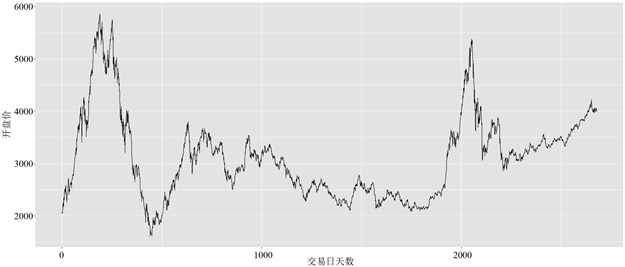
Figure 2. The daily opening price of the Shanghai and Shenzhen index (2007.1.4~2017.12.29)
图2. 沪深指数每日开盘价(2007.1.4~2017.12.29)
到大)分成一系列小区间,计算出各参数值的组合所对应的误差值并逐一比较选择最佳,从而求得该区间内的最小误差值和它所对应的最优参数值,这种方法使得我们捜索到的解基本上是全局最优解,避免了重大误差的存在。利用网格搜索法对支持向量机参数寻优,并得到最佳参数为:c = 0.5;g = 2。大体如图4所示为网格捜索法参数选择结果 [13] 。
网格捜索法可以找到在交叉验证意义下的最高分类准确率,也就是全局最优解,但若想在更大范围内寻找最佳参数c和g会很费劲,采用启发式算法不必搜索网格内的所有点,也能找到最优解。
3.4. 利用最佳参数训练SVM模型做拟合预测
通过以上参数最优化选择参数c和g训练支持向量机模型,并根据模型对原始数据进行模型拟合及预测,如图5所示利用网络搜素法优化得到的沪深指数开盘价回归预测和原始数据对比情况。并通过基于网络搜索法最终得到的模型拟合结果是,均方误差MSE = 2.12583e−5,相关系数R = 99.9521%。
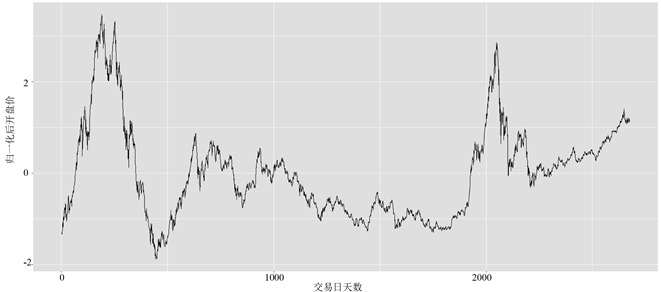
Figure 3. The daily opening price of the Shanghai and Shenzhen index after the normalization of the Shanghai and Shenzhen index (2007.1.4~2017.12.29)
图3. 沪深指数归一化后每日开盘价(2007.1.4~2017.12.29)

Figure 4. Optimal parameter graph of grid search method
图4. 网格搜索法最优参数图
另外,预测数据与实际数据之间差异可以通过以下误差图来描述,从图6中可以观察到回归预测数据与原始数据的开盘价误差量基本上维持在70以内。其次,经过相对误差分析可知,相对误差基本控制在4%以内,回归的预测精度较高,可显示该方法预测股票指数的效果较好 [14] 。
4. 实验结果
我们将基于网格搜索法优化的支持向量机模型和时间序列ARMA模型的分析结果分别用于沪深300指数回归预测,将最终得到的拟合结果进行比较,图7所示为两种模型拟合预测结果和原始数据的比较。
实验选取的原始数据前1000个交易日数据当作训练样本输入,第1001个交易日至1010个交易日的收盘价格当作测试样本输出。通过实验模型的拟合,ARMA模型与支持向量机模型的预测情况。
从图7可知,ARMA模型的预测趋势跟原始数据比较,整体的预测是失效的,并没有做出精准地预测。而对比的基于支持向量机模型预测趋势和原始数据比较,整体的预测准确性较高,并基本与原始数据的上涨或下降趋势基本相同。这验证了将支持向量机应用于股价预测问题很有效。而对于复杂的金融时间序列数据来说,传统的ARMA模型已经不能够准确地预测真实的数据走势,而支持向量机股价预测

Figure 5. Prediction of error distribution of data and actual data
图5. 预测数据和实际数据误差分布图
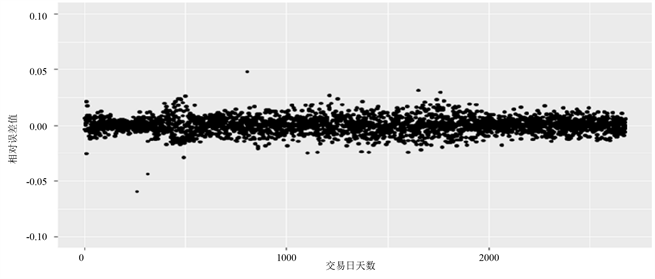
Figure 6. The distribution of relative error between predicted and actual data
图6. 预测数据和实际数据的相对误差分布图

Figure 7. Comparison of ARMA model and SVM fitting model
图7. ARMA模型与SVM拟合模型的比较
模型具有良好的非线性特征,可以很有效地拟合复杂函数,并对其进行准确预测 [15] 。
5. 结论
本文选用从国泰君安大智慧软件中下载的2676个交易日沪深300指数数据作为研究数据。采用建立支持向量机模型和ARMA模型的方法对数据进行分析研究,经过对原始数据预处理、最优参数选择、分别进行模型训练及预测、原数据与预测结果的拟合度进行对比分析等步骤来实证分析。结果表明基于支持向量机的模型的预测数据与原始数据拟合度较高;支持向量机模型的预测效果要远远优于ARMA模型的预测效果,支持向量机核函数参数的选取很大程度上决定了模型的预测精度,而传统的时间序列模型预测效果不是很好;SVR在一定时期内,可以为投资者进行投资提供一定的依据。
基金项目
辽宁省自然科学基金资助项目(201602461)。