1. 引言
1.1. 问题的产生
在现代战争中,各国军队对信息战的要求越来越高。为了及时、准确、有效地获取敌方情报,有针对性地对敌重要通信装备及其载体(如水面或水下目标、空中飞行目标、陆地固定目标等)进行监视、控制、干扰或打击,这就对通信信号的分析研究手段提出了更高的要求。因此,通过对同类通信辐射源信号特征的提取和分析,实现从一般通信信号的分类识别到个体信号的识别,对在信息化条件下提高军事通信对抗作战能力,保证在未来战争中情报信息的获取与利用,掌握战争的主动权具有重要价值和意义。本文尝试研究并解决以下问题:
问题一:分析并提取通信辐射源信号的特征,并基于这些特征建立识别聚类模型,并对第一组数据中500个信号样本进行聚类,区分出五种通信辐射源的信号。
问题二:根据问题一的聚类结果,对第二组数据所给出的两个降噪后的信号样本进行识别,将其归类,并对分类的可靠性进行分析。
问题三:对第三组数据中四个有噪声影响的实际信号进行识别,确定这四个信号是否属于问题一的五类,如果是,则又属于哪一类。
1.2. 数据重现
第一组数据给出了5种通信辐射源的侦测接收信号的500个信号样本(如表1所示),其采样频率均为
;第二组数据给出了2个降噪后的实际通信辐射源信号样本(如表2所示);第三组数据给出了4个有噪声影响的实际通信辐射源信号(如表3所示)。

Table 1. The first set of data (excerpt)
表1. 第一组数据(节选)
Table 2. The second set of data (excerpt)
表2. 第二组数据(节选)
Table 3. The third set of data (excerpt)
表3. 第三组数据(节选)
1.3. 问题的分析
问题一分析
问题一的关键是对信号的处理,即特征提取和聚类。其中,特征提取是指对信号数据进行处理的过程,特征提取的好与坏对聚类的情况和后期的信号个体的分类识别有着重要的影响。所以,本文需要建立一种具有优异性能的信号特征提取方法。查阅相关资料 [1] ,本文发现Hilbert-Huang变换是一种应用广泛的信号特征提取方法,它可以提取信号的时频分布特征,而且局部性良好,对平稳和非平稳信号皆可适用。在后文将介绍Hilbert-Huang变换的使用。
另外,本文需要对提取出的信号特征进行聚类分析,聚类分析是将信号特征分组成多个类的过程,使得同一组内的信号特征具有较高的相似度,而不同组中的信号特征相似度低。由于本文的信号特征数据都需要用来聚类,没有大量的学习样本可以使用,所以本文所以本文采用无监督聚类算法进行聚类 [2] 。
问题二分析
问题二主要是对问题一所建模型的应用,它主要包括:识别归类及其可靠性分析。
基于聚类模型中得出的5个类别,本文可以计算新的信号特征与5个聚类中心的信号特征的相似程度(Minkowski距离),显然新的信号应该被归入与其最相似的组内。与此同时,如果新的信号特征与各组的聚类中心信号特征的相似程度较为接近,则认为这种分类较为模糊,可靠性不高;否则则认为这种分类较为明确,有一定的可靠性。
问题三分析
在对问题三的信号进行降噪之后,该问题转化成对以上模型的综合应用,所以问题三的关键在于对信号进行降噪。查阅相关资料得知,受噪声影响的信号的表达式为
,并统计分析了第三组数据中所给的数据发现噪声其实是围绕着信号成正态分布的。因此可以设置一个阈值来对噪音进行过滤,获得一个降噪信号,再对其进行特征提取和分类。
如果发现该降噪信号与5个聚类中心的相似程度小于问题一聚类过程中出现的最小相似程度,则认为这个降噪信号不属于这5类;否则,归入其中一类。
2. 模型的阐述与求解(总流程如图1所示)
2.1. 数据特征提取模型
第一步:进行EMD分解
把目标信号的采样值输入Matlab,做出信号图像,设信号的时间序列形式
,用三次样条插值做出图像的上、下包络线,分别为
和
,则上、下包络的平均曲线为
.
用原信号的公式减去
,得到新的信号函数
,若
满足下列两个条件:
在信号数据序列里,
;
在任何时间点,由数据序列的局部极大值与局部极小值确定的包络均值为0。
则
为一个IMF分量,若不满足上述两个条件,则将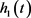 作为原信号重复上述步骤,直到得到一个IMF分量
。然后,将
从原始信号
中分离出来,得到一个新的信号
,即
作为原信号重复上述步骤,直到得到一个IMF分量
。然后,将
从原始信号
中分离出来,得到一个新的信号
,即
,
再用
作为原信号重复上述操作,求取新的IMF分量,直到
成为单调函数,停止循环。
为残余分量,表示信号的平均趋势。此时已提取出该信号的所有IMF分量,原信号可表示为

Figure 1. The total flow chart of classification and identification of communication radiation source signals
图1. 通信辐射源信号的分类与识别的总流程图
.
第二步:进行Hilbert变换
首先,对得到的每一个IMF分量进行Hilbert变换如下,
,
通过查表可进行求解,得到IMF分量的解析信号
,
其中,信号瞬时振幅为:
,
信号瞬时相位为:
.
去除残余分量后,原信号
的Hilbert谱为:
其中,
为信号的瞬时频率。
最后,对Hilbert谱进行积分,求取信号
的边际谱
,
其中,T为
信号的持续时间,边际谱反映出在信号持续时间内的幅度分布,即能量分布。
对第一组数据中的500个信号均执行上述两个操作,完成Hilbert-Huang变换,因数据量太大,以信号一为例,共得到8个IMF分量及其频谱(如图2所示)。
第三步:提取边际谱的特征
在边际谱中,能量重心和信息熵是衡量频域信息的重要参数,能量重心表示信号能量在频域中的集中点,信息熵表示信号能量在频域中分布的均匀程度,因此提取这两项参数作为信号特征。具体步骤如下:
Step 1 提取边际谱能量重心
用Matlab计算出信号的Hilbert谱矩阵为
,其中f为信号频域包含的频率成分,计算Hilbert谱的总能量为:
.
边际谱的总能量为:
.
则边际谱能量重心为:
,
即加权积分和与边际谱总能量的比值。
Step2 提取边际谱信息熵
将Hilbert谱矩阵中的值转换为0~1之间的概率值,
,
计算边际谱中幅度的概率分布
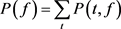 ,
,
得到边际谱的信息熵
,
以边际谱能量重心与边际谱信息熵组成辐射原信号样本的特征向量。
2.2. 识别分类模型(模糊均值聚类算法)
在前面的模型中本文已将辐射源信号数据转化成和其特征参数数据,下面本文将对不同信号的特征参数数据进行聚类,区分出5种通信辐射源的信号。

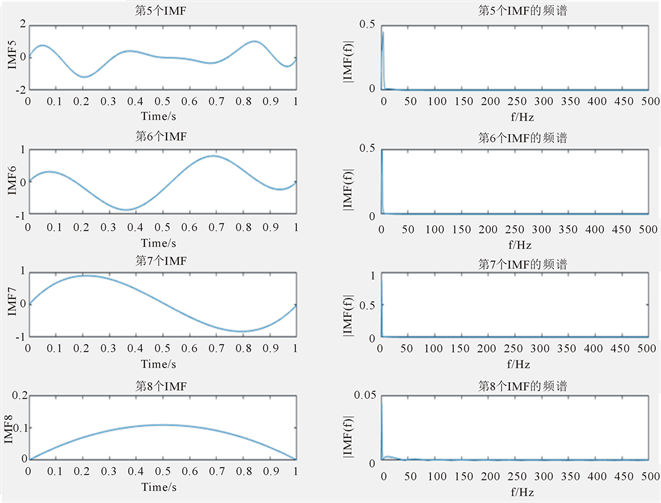
Figure 2. Eight IMF components and their spectra
图2. 8个IMF分量及其频谱
随着模糊集理论的出现,人们在K-均值算法的基础上提出了模糊均值聚类算法,其核心思想是:设数据集
,其中yi为第i个特征提取后的信号向量;它的模糊划分可用隶属度矩阵
表示,矩阵
的元素
表示第
个特征参数向量属于第
类的隶属度。
满足条件如下
, (1)
, (2)
. (3)
聚类目标函数,其一般形式为:
, (4)
其中,
是第i个聚类中心,且 是一个加权指数。
是一个加权指数。
隶属度矩阵的更新公式为:
. (5)
聚类中心的更新公式为:
. (6)
模糊均值聚类算法通过反复迭代优化目标函数,即可完成对数据集
的聚类,具体步骤如下:
1) 初始化聚类中心
;
2) 用
之间的随机数初始化隶属度矩阵P,使其满足(1)、(2)、(3)的约束条件;
3) 通过式(6)更新聚类中心;
4) 通过式(4)计算价值函数,并选取合适的距离形式和阈值e。比较
和
,若
,则停止迭代;否则用式(5)重新计算P值,返回步骤(3)。
模糊均值聚类算法需要两个参数:一个是聚类数目C,另一个是参数m。一般来说,C要远远小于聚类样本个数,同时要保证
。对于m,它是一个控制算法柔性参数,从相关资料中得知,当m过大,则聚类效果会很差,而如果m过小,则会接近于非模糊的均值聚类算法。因此在一般情况下,加权指数m = 2 [3] 。输出的结果是C个聚类中心向量
和
的一个模糊划分矩阵,这个矩阵表示的是每个向量对于各类的隶属度,其中隶属度的最大值即为该向量属于的类别,而C个中心向量则可视为该类的代表向量。
2.3. 归类模型
对于一个新的信号本文同样可以获取其特征参数向量
,计算该特征向量
与上文推导得出的C个中心向量
的距离,选取距离的最小值
其对应中心向量
所在组即为新信号的组别。
第二组数据中两个信号的分类结果如下表4所示。
3. 可靠性分析
定义一个的信号特征y与各组的聚类中心信号特征
的距离和为:
,
其中,k称为识别的可靠性,k的标准值取5个聚类中心向量之间距离的最大值
。
当
时,说明这次识别具有可靠性,反之则没有。k值越大,说明这次识别的可靠性越好。
对于问题二中的识别可靠性如下表5所示。
4. 小波阈值降噪模型
在实际通信信号的传输过程中,信号会受到噪声的影响,干扰信号的识别,无法直接用模型一进行分类,因此,需对信号进行降噪处理。资料表明,小波阈值降噪是一种常用的信号降噪方法,它具有去相关性、基的选择的多样性等特点,能刻画信号的非平稳特性且具有良好的时频特性,是一种理想的信号降噪方法。
小波阈值降噪通过小波的多分辨分析特性,将信号在不同尺度下进行分解,使交织在一起的各种不同频率组成的混合信号分解成不同频段的子信号,将各频段采用不同的阈值去噪后再进行重构,从而达到去噪的目的。共包括四个部分:
1) 对信号进行小波分析,将原始信号分解为一系列的近似分量和细节分量,信号的噪声主要集中表现在信号的细节分量上。
2) 选取阈值函数,即选择对超过和低于阈值的小波系数的模的处理方法。
3) 确定阈值,确定阈值即可确定噪声频段的范围,进行去除。
4) 小波重构,上述处理后可获得去噪后的小波系数和尺度函数,将其重构后可以得到去噪后的信号。
Table 4. Classification results for two signals
表4. 两个信号的分类结果
注:信号标号分别为两个信号在第二组数据中的列号。
Table 5. Reliability of recognition
表5. 识别的可靠性
应用小波阈值降噪方法对第三组数据中给出的信号进行降噪处理,得到4个降噪信号,代入前述模型进行特征提取及识别分类,从而求解该信号是否属于问题一中得到的五种类别。
通过小波阈值降噪对信号进行降噪处理的步骤如下:
第一步:对信号进行小波分析
信号
的小波变换公式为:
.
定义尺度子空间
和小波子空间
,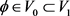 .小波基函数
可表示为:
.小波基函数
可表示为:
其中,
为相应于多分辨分析
的尺度函数。小波分解公式为
经过上述正交分解步骤,原信号被分解为尺度函数和小波函数,对小波函数选取阈值进行处理,可去除噪声。
第二步:选取阈值函数
阈值函数决定如何对超过和低于阈值的小波系数的模进行处理,即对含有噪声的波段进行处理的方法。由于软阈值处理后得到的结果较平滑,本文中选取软阈值函数进行去噪。其函数表达式如下:
,
其中,Y是信号x的小波系数,l为阈值,
表示软阈值化后的小波系数。
第三步:确定阈值
阈值的选取是否适宜直接关系到去噪效果,若阈值过大,会去除有用信息,阈值过小则去噪不完全。阈值选取的方法很多,本文中选择选取规则较保守的SURE阈值,以防有用信息被去除。SURE阈值的数学表达如下:
,
其中,s为噪声方差,wj为第j个小波系数,L为两数取小,I是示性函数,N是原信号经小波分解后得到的N个小波系数。
第四步:小波的重构
完成小波系数的处理后,信号的噪声已去除,此时需要把去噪后的小波系数与尺度函数重新组合成为一个信号,即得到去噪后的信号。
对任意整数j,k,由系数序列
,
表示系数,则重构公式为:
得到去噪后的信号。对于第三组数据中第1列的信号降噪后的信号图如下(图3)。
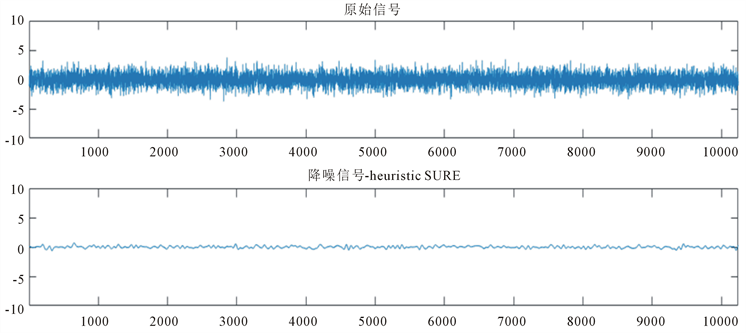
Figure 3. Noise reduction example for the first signal
图3. 信号一的降噪示例
Table 6. Classification results for the third group of data
表6. 第三组数据的分类结果
注:信号标号分别为四个信号在第三组数据中的列号。
第五步:将降噪信号代入上述模型,进行分类
第三组数据中的4个信号的分类结果如下表6所示。
5. 改进与推广
对于小波阈值降噪模型,小波分析中可选用的函数太多,本文只通过阅读文献确定合适问题三中信号特点的函数,因此本模型中在阈值确定及阈值函数步骤中采取的函数不能保证使附件三中所给信号在小波分析降噪的情况下效果达到最好,可多进行不同函数组合的搭配,从而增强降噪效果。
本模型着重解决通信辐射源信号特征的提取和分析,实现从一般通信信号的分类识别到个体信号的识别,从而确定信号来源及位置,在军事方面具有重要的现实意义。
一般噪声类型为加性白噪声,该噪声假设功率谱密度具有无限宽的带宽,是一种便于进行数学分析的理想化模型,应考虑在实际传输中形成的噪声的各种类型,由于模型中使用的方法均从时频方面考虑,有较强的稳定性,可尝试使用该模型,使其对其他类型平稳或非平稳噪声进行识别分类。