1. 引言
随着我国城市化进程的不断加快,城市供水管网的规模也不断增加,由于缺乏科学合理的规划、维护与运行管理,各大城市的供水管网爆管事故频发,严重影响了城市供水的安全性和经济性,对资源、环境、社会均产生了巨大的负面影响。目前水务公司发现爆管事故多依赖于人工报告,此为被动性爆管定位方法,此方法虽然可以确定准确的爆管点,但弊端也比较明显,检测效率较低,反应时间较长,发现事故时,可能已经造成了较大的损失。因此,需要开展供水管网爆管事故智能检测方面的研究,快速准确地确定爆管位置和事故影响范围,并做出相应的科学决策。
为了解决爆管定位的难题,各国学者均开展了大量的相关研究工作。1992年,Liggett等人 [1] 首先提出基于暂态的爆管定位方法,该方法的基本原理是爆管产生的压力波将先后传播到附近的几个压力监测点,根据传播路径和时间差来诊断爆管位置,但由于压力波传播路径比较复杂,且时间差通常很短,因此定位精度会受到严重影响;江朝元 [2] 等人综合运用负压波和流量检测法进行泄漏模式识别与漏点定位,可及时发现和定位泄漏点。基于水力模型的爆管定位方法也取得了一定的进展,Wu [3] 在此研究方向做出了代表性的工作,其结果被英国的水务公司所采用;Sanz [4] 等人后续推进了这方面的研究,其依据爆管的水量变化过程,不断校核管网模型的空间分布参数,其结果展示出了较高的爆管定位精度;程伟平 [5] 等人利用监测资料与低压供水模型相结合的管网爆管水力学模型实现了爆管定位,并分析了爆管点位置与周围压力变化的关系。随着人工智能技术的快速发展,数据驱动的智能爆管分析方法成为了国内外学者的热点关注问题。Tao [6] 等人应用人工免疫网络并结合最近邻方法,推测爆管事故的发生;Zhang [7] 等人采用支持向量机分析爆管区域;陶涛 [8] 等人通过SCADA (Supervisory Control and Data Acquisition)监测系统收集压力数据,对比爆管前后两个时刻的压力值变化,绘制爆管压降等值线图,最后通过压降中心来定位爆管点,以上三个研究均是基于机器学习的方法,通过训练模型达到对实测数据的异常辨识功能,从而确定爆管的位置。
针对智能化的爆管定位问题,本文提出了一种基于人工神经网络(ANN)的供水管网爆管定位方法,利用ANN的模式识别功能,建立爆管位置与压力监测点水压化率之间的非线性映射关系,实现爆管位置的确定。此外,本文选取了一个案例管网,通过大量的模拟爆管事故,验证了所提出方法的可行性。
2. 研究方法
2.1. 基于ANN的爆管定位模型构建
供水管网发生爆管事故时,会引起系统的压力变化,且不同爆管位置所引起的压力变化规律也是不同的。基于上述现象,本文在管网模型中假设大量爆管事故的发生,以事故发生后供水管网监测点的压力变化值作为输入条件,反向推求爆管位置。ANN是一个具有高度非线性的超大规模连续时间的动态系统,是由大量的神经元广泛互连而形成的网络,具有强大的自学习能力、联想存贮能力、高速寻优能力等特性,在生物、医学、经济学领域广泛应用 [9] 。因此,本文利用ANN来建立爆管位置与监测点压力变化率之间的映射关系,构建的ANN爆管定位模型结构详细介绍如下。
1) 模型输入层
模型输入层的变量为爆管发生时的监测点压力变化率,计算方法如式(1)所示:
(1)
式中:
为监测点i的压力变化率;
为管网正常运行工况下监测点i的压力值;
为爆管事故时监测点i的压力值。
爆管的位置假设发生在模型的节点处,两个压力监测点很难准确描述爆管的位置,在监测点个数无冗余的条件下,三个压力监测点可测算其扰动半径,再通过管道长度及其连接关系,可大致确定爆管在管网中位置,因此所构建的模型输入层神经元个数为3,输入压力变化率值为
、
和
。
2) 模型隐含层
研究表明,对于一般的非线性映射问题,选用一个隐含层即可得到较理想的结果。隐含层的神经元个数无法直接确定,目前理论上还没有一种科学和普遍的确定方法,为避免训练时出现过拟合现象,保证足够高的网格性能和泛化能力,一般应遵循如下原则:在满足精度要求的前提下,选取尽可能紧凑的结构,即选择尽可能少的隐含层神经元个数。
3) 模型输出层
模型输出层的变量为爆管点距三个压力监测点的距离
、
和
。为了提高ANN模型的精度,在此对三个距离值分别建立ANN模型,因此所构建模型的输出层神经元个数为1,输出值为
。
通过以上过程,即可建立反映爆管点位置与监测点压力变化率关系的ANN模型,关系式如(2)所示:
(2)
式中:
为ANN模型中所确定的函数关系。
2.2. 爆管定位模型训练及应用
当ANN模型的输入层数据和输出层数据变化范围较大,可能会导致模型训练时间长或难以收敛,因此在模型训练前首先对输入输出数据进行标准化预处理。对SCADA系统采集的历史爆管事故的监测点压力数据和爆管位置数据进行处理,标准化处理公式如公式(3)所示:
(3)
式中:X为原始数据,
为标准化处理后的数据;对于模型输入层数据,
和
分别为监测点压力变化率的最大值和最小值,
和
的取值分别为1和−1;对于模型输出层数据,
和
分别为爆管点距监测点距离的最大值和最小值,
和
的取值分别为0.8和0.2。
经过多次训练后,不断修正参数,使神经网络模型的输出值和观测值之间的均方误差值达到合理范围内。当系统识别出供水管网内发生爆管事故时,将监测点的实时水压监测数据经预处理后,作为模型输入数据输入到训练好的ANN爆管定位模型,可得到各模型输出值。由三个模型的输出值分别确定满足距离值要求的节点编号集合S1、S2和S3,求三个集合的交集S1∩S2∩S3,可确定管网爆管位置。
3. 应用案例
3.1. 案例介绍
本文选用的供水管网案例有1个水源,30个节点,50根管道,各管道的尺寸如表1所示。各节点的用户需水量均为0.05 m3/s,各节点高程均为48 m,管道粗糙度系数均为140,水源水头为100 m [10] 。管网拓扑结构图如图1所示,图中数字表示节点编号。
3.2. 爆管数据获取
为了保证ANN模型的精度达到要求,需要大量的数据对模型进行训练,因此利用EPANET2软件模拟大量的爆管事故,以获得训练ANN模型所需的数据 [11] 。假定所有的爆管事故引发的流量变化均发生在管网节点处,可利用EPANET提供的扩散器系数(Emitter Coefficient)来模拟不同节点不同程度下的爆管事故。模型训练及测试数据的获取流程如下:
1) 选定监测点组合,调用EPANET水力引擎,计算正常工况下,管网中各监测点的压力值;

Table 1. Data list of pipe size of water distribution systems
表1. 供水管网管道尺寸数据列表

Figure 1. Topology of water distribution systems case
图1. 供水管网案例拓扑结构图
2) 设定Emitter Coefficient的取值范围,管网内所有节点均为可能爆管点,利用蒙特卡洛(Monte Carlo)方法模拟大量单点爆管事故,并调用EPANET水力引擎,计算爆管事故时的监测点压力值;
3) 由前述公式(1)计算监测点压力变化率;
4) 分别计算管网各节点到三个监测点的距离。
模拟1000次爆管事故,即可获得1000组实验数据,选取其中的900组作为模型训练数据,剩余100组作为模型测试数据。
3.3. 爆管定位模型训练及应用
1) 模型训练
初步选定三个水压监测点的节点编号为12、15和23,各监测点的位置如图1中红色圆圈标记所示,进行ANN爆管定位模型的训练与测试。MATLAB提供了GUI界面的神经网络工具箱,具有简洁、友好的人机交互功能,因此本文直接利用MTALAB内置的神经网络工具箱构建并训练和测试ANN模型 [12] 。为表示方便,定义输出值为爆管点距节点12的距离的ANN模型为M1,对应节点15为M2,对应节点23为M3。对于各个ANN模型,不断调整隐含层神经元的个数和训练函数的相关参数,当模型训练误差逐渐趋于稳定并满足要求时,即完成模型训练过程。
2) 模型测试
将100组测试数据中的压力变化率数据,分别输入训练好的三个模型,可得到各模型的输出值。模型M1、M2和M3的输出值分别表示爆管点距节点12、节点15和节点23的标准化距离值。分析各模型的输出值与期望输出值的近似程度,可判断所构建的ANN爆管定位模型的准确性。
4. 结果与分析
4.1. ANN爆管定位模型准确性分析
对于模型M1,将监测点12,15和23的压力变化率和各爆管位置距监测点12的距离值导入MATLAB的神经网络工具箱,经过多次调整,最终选择隐含层神经元个数为10个,训练函数为traingd,最大失败次数设置为6,学习因子设置为0.5,经过100,000次训练后,误差逐渐趋于稳定,模型误差变化曲线如图2所示。对模型M2和M3,重复上述过程,可得到相应的误差变化曲线,在此不再详细论述。
将100组测试数据中的压力变化率数据分别输入模型M1、M2和M3,得到各模型的模型输出值。以测试数据中的爆管事故为例进行分析,假定节点19发生爆管,首先将三个监测点的压力变化率输入各模型,M1的输出值
,M2的输出值
,M3的输出值
;其次,分析可能的爆管节点位置,满足
的节点编号集合S1 = {5,7,17,19},满足
的节点编号集合为S2 = {19},满足
的节点编号集合为S3 = {15,19,27,31},S1∩S2∩S3 = {19},确定爆管位置为节点19。因此利用所构建的ANN定位模型可以实现爆管定位。
为了分析ANN爆管定位模型的定位精度,分别作模型M1、M2和M3的输出值与期望输出距离拟合曲线图,如图3~图5所示。图中X轴表示期望输出距离标准值,Y轴表示模型输出距离标准值。在模型的定位精度为100%的条件下,期望输出与模型输出应相等,拟合曲线应为通过原点的45˚直线,如各图中的紫色虚线所示。图3~图5中的绿色实线表示模型的实际模型输出与期望输出的实际拟合曲线,可看出与理想拟合曲线结果非常接近。
为了定量表征实际拟合曲线的精度,选择相关系数(R2)指标来表征模型输出值与期望输出值的拟合程度,R2的计算公式如式(4)所示:
(4)

Figure 3. Fitting curve for expected output and model output of M1
图3. M1期望输出与模型输出拟合曲线

Figure 4. Fitting curve for expected output and model output of M2
图4. M2期望输出与模型输出拟合曲线
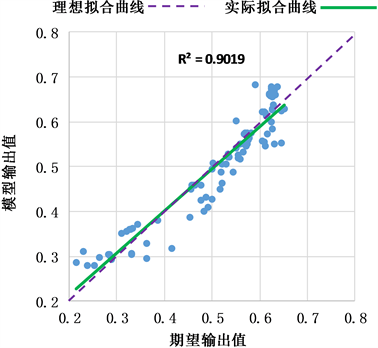
Figure 5. Fitting curve for expected output and model output of M3
图5. M3期望输出与模型输出拟合曲线
式中:SSE为残差平方和,SST为总平方和。
经计算得,模型M1的R2为0.9667,M2的R2为0.8463,M3的R2为0.9019。R2值越大,表示模型精度越高,一般认为R2超过0.8时即认为拟合度较好。上述结果表明,利用ANN构建爆管定位模型,可得到较准确的爆管定位结果。
4.2. 不同监测点组合对模型精度的影响分析
为分析ANN模型定位精度受监测点组合因素的影响,本文选择了4种典型的监测点组合,分别是:1) 集中式监测点布置(图6(a)),节点编号为12、15和23;2) 边界点布置(图6(b)),节点编号为4、23和26;3) 最远节点布置(图6(c)),节点编号为11、20和31;4) 水源入口节点布置(图6(d)),节点编号为2、12和21。
 (a) (b)
(a) (b) (c) (d)
(c) (d)
Figure 6. Position distribution of different combinations of monitoring points
图6. 不同监测点组合位置分布
监测点组合1的模型精度在前述中已经给出,对后三组监测点组合,仍分别利用900组数据进行训练,100组数据进行测试,利用R2和MSE两项指标评估各模型的精度。表2列出了四组监测点组合下的各模型的R2和MSE (均方误差)值。组合1的R2平均值最大,说明当监测点均匀分布在管网内部,而不是建立在管网的边界上时,监测点检测管网爆管的准确性会比较高。从实际的角度看,监测点离爆管的位置越近,监测点的压力变化幅度越大,越容易检测到爆管。在管网内部均匀布置监测点,使监测点到任意节点的距离相对小,所以可以更准确的确定爆管点位置。四个组合中,均为M2模型的R2值最小,但从位置上分析,与边界效应的关系不明显。
MSE指标值越小,表示模型输出值与期望输出值的偏差越小。表2中MSE平均值与R2平均值的结果一致,组合1的MSE最小,组合1的监测点布置效果最好,其它三个布置方式差异不显著。但在单个模型的指标(R2值和MSE)比较中,结果不统一。组合3中的模型M1的MSE值最大,但相对应的R2值在该组合内以及其它组合中,均不是最小值。
Table 2. Statistics of model accuracy for different combinations of monitoring points
表2. 不同监测点组合下的模型精度统计
5. 结论
针对供水管网爆管事故定位难题,本文建立了一个基于ANN的供水管网爆管定位方法,利用ANN的模式识别功能,建立了爆管位置与三个压力监测点水压变化率之间的非线性映射关系,充分利用供水管网SCADA系统采集的压力数据,实现爆管定位,并应用于一个案例供水管网。主要结论如下:
1) 通过R2这一指标评估了所构建的ANN爆管定位模型的精度,验证了所提出的爆管定位方法的准确性,为快速精确实现爆管事故定位提供了新的解决方法;
2) 监测点组合的选取会影响基于ANN的爆管定位模型的精度,选择均匀分布的监测点可以提高模型的精度,进而提高爆管事故定位准确度。
基金项目
本次研究是在国家自然科学基金(51708086, 91547116, 51320105010)、中国博士后科学基金(2016M601309)的资助和支持下完成的。
参考文献