1. 引言
2016年3月,AlphaGo以总分4比1战胜韩国围棋选手李世石;2016年5月,AlphaGo以总分3比0战胜中国围棋选手柯洁;2017年10月,Alpha Zero问世,通过自己学习围棋,以100:0完胜AlphaGo Lee (AlphaGo和李世石联队)。上述事件将人们的视野转向人工智能这一领域,也说明了人工智能在计算机领域内,开始得到广泛重视,并获得了迅速发展。
人工智能(Artificial Intelligence,简称AI),最初是在1956年,由John McCarthy, Marvin Minsky、Arthur Samuel和Claude Elwood Shannon (信息论创始人)等在达特摩斯(Dartmouth)会议上提出的 [1] 。但是关于AI的定义,一直以来却不断被人诠释。维基百科对于人工智能的解释是,“区别于人类或其他动物智能,而由机器表现出来的智能被称为人工智能”。在计算机科学看来,人工智能研究领域就是智能机器人(Intelligent Agents) [2] 。Russell在其书《人工智能:一个现代方法》(《AI:A modern approach》)中系统归纳了人工智能的各种定义,他给将其分为四类:类人思考(Thinking Humanly)、类人行动(Acting Humanly)、理性思考(Thinking Rationally)、理性行动(Acting Rationally),具体说就是从类人和理性的思考与行动两个大维度给予了解读。该书最终对AI的定义,更倾向于理性这个维度 [3] 。鉴于上面的总结,我们对人工智能给出以下定义:“人工智能是研究赋予机器完成人类对于周围环境做出理性反应所展示出的智能的科学。”
2017年7月,我国正式发布《新一代人工智能发展规划》,从国家层面制定了未来10多年人工智能的战略部署,目前我国各企业和领域对人工智能人才需求很旺盛,却明显人才供应不足。据麦肯锡70页特辑报告论述《中国人工智能的未来之路》指出,我国的研究人员在基础算法研究领域仍远远落后于英美同行,美国50%以上的数据科学家拥有10年以上的工作经验,而我国这个比例不足10%,更有超过40%的数据科学家工作经验尚不足5年,且人工智能科学家大多集中于计算机视觉和语音识别等领域,其他领域人才相对匮乏 [4] ,这些都是未来一段时间,我国各大高校和各人工智能培训机构需要努力的方向。
近期我们用百度指数对比分析了两个关键词——“人工智能”和“人工神经网络”(如图1~4),总结得到以下结论:1) 人工智能和深度学习的关注度总体呈上升趋势,尤其是人工智能研究愈演愈烈;2) 随着国家对人工智能领域的重视,相关区域(经济发达地区)和人群(30到39岁青年男性人群)加大对该领域在科研、应用开发和培训关注和投入;3) 预计在随后几年内,人工智能之花会逐渐结出丰硕果实,惠及普通民众。
本文重点介绍人工智能和人工神经网络的研究进展及其相关技术,深刻揭示人工智能、机器学习、神经网络和深度学习等概念之间的关系,总结人工智能研究领域存在的问题并提出发展建议,所做工作对于人工智能的深入研究具有一定的参考价值。

Figure 1. General trend of the Baidu index for AI and ANNs
图1. 人工智能和人工神经网络百度指数整体趋势
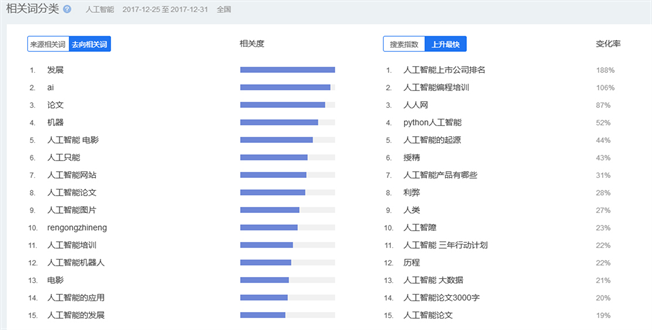
Figure 2. The direction related words and fast rising correlation words of AI
图2. 人工智能搜索去向相关词和上升最快相关词
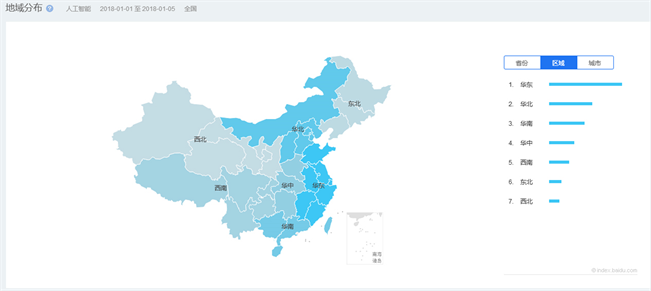
Figure 3. Regional distribution of the Baidu index for Artificial Intelligence
图3. 人工智能百度指数搜索的区域分布
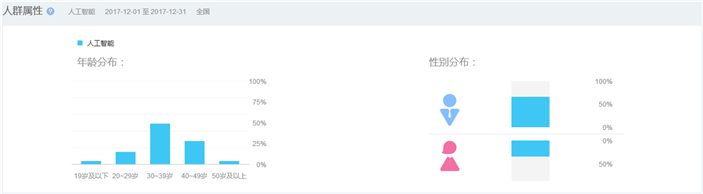
Figure 4. Population attributes of the Baidu index for AI
图4. 人工智能百度指数搜索的人群属性
2. 研究进展
2.1. 人工智能研究进展
1956年John McCarthy, Marvin Minsky、Arthur Samuel和Claude Elwood Shannon等学者在Dartmouth会议上正式提出人工智能概念 [1] 。1958年,John McCarthy开发人工智能研究中最流行的编程语言LISP。
随后很多专家学者编制开发了各式各样的人工智能程序,例如下跳棋程序、数学定理证明程序等。1965年,Herbert Simon甚至预言20年内智能机器将能够取代人工,这就是人工智能的第一次研究高潮。但是人工智能研究者低估了解决实际问题的困难程度,很多项目进展迟滞。1973年,SirJamesLighthill给英国科学研究委员会做了《关于人工智能的综合调查》(《Artificial Intelligence: A General Survey》)的报告,在报告中称:“迄今为止,人工智能的研究没有带来任何重要影响。”,其后,美国政府和英国政府大幅度削减人工智能研究的经费。因此,随后几年,被称为“人工智能的冬天”。
20世纪80年代中期,专家系统的兴起,又使得人工智能研究热潮再度掀起。
20世纪80年代末,随着低成本的个人微型计算机可以更有效率的运行LISP程序,而专门运行LISP程序的机器随之衰弱,退出市场。人工智能研究的低潮再次到来。
1997年5月11日,IBM公司生产的国际象棋计算机“深蓝”在比赛中战胜当时的国际象棋世界冠军加里·卡斯帕罗夫,成为人工智能发展领域的一个里程碑。
20世纪90年代末到21世纪初,随着计算能力的提升,人工智能开始介入后勤、数据挖掘和医学诊断等领域,并取得相应成果。AI又开始了它的第三次高潮至今 [2] 。
人工智能发展曲线,如图5所示。
2.2. 人工神经网络研究进展
1943年,W. S. McCulloch和W. Pitts提出了的M-P模型 [5] 。该模型根据生物神经元的结构和工作机理构造了一个简化的数学模型(如图6)。其中,xi代表神经元的第i个输入,权值wi为输入xi对神经元不同突触强度的表征,θ代表神经元的兴奋阀值,y表示神经元的输出,其值的正和负,分别代表神经元的
兴奋和抑制。该模型的数学公式可以表示为:
,如果所有输入之和大于阀值θ则y值为
正,神经元激活,否则神经元抑制。该模型作为人工神经网络研究的最简模型,一直沿用至今。
1949年,D. Hebb给出了Hebb学习规则 [6] 。该规则认为权值调整量
正比于神经元的输入向量X和输出向量Y的相关性,其数学表达为:
,其中 被认为是学习率。该规则根据神经元之间连接的激活水平来调整权值(输入输出相关性强,则权值增大,相关性弱,则权值减弱),训练神经网络,这个过程与人类观察和认知世界的过程相吻合,至今还在被许多人工神经网络学习算法所使用。
1957年,F. Rosenblat提出了感知器(Perceptron)模型,这是一个由线性阀值神经元组成的前馈人工神经网络,可实现与或非等逻辑门,用于实现简单分类 [7] 。
1960年,B. Widrow和M. Hoff提出了自适应线性单元,一种连续取值的人工神经网络,可用于自适应系统。随即人工神经网络进入第一个研究高潮期 [8] 。
1969年,人工智能创始人M. Minsky和S. Papert发表《Perceptrons》一书,书中指出:单层Perceptron不能实现异或门(XOR),多层Perceptron不能给出一种学习算法,因此毫无使用价值 [9] 。鉴于两人在人工智能领域的地位,该书产生极大反响,人工神经网络研究陷入低潮。
1982年,加州理工大学教授H. Hopfield提出Hopfield人工神经网络,在著名的旅行商(TSP)问题这个NP (Nondeterministic Polynomial)完全问题的求解上获得当时最好结果,引起了巨大的反响,使人们重新认识到人工神经网络的威力 [10] 。
1985年,Rumelhart等人重新给出了多层感知机权值训练的BP算法(Backpropagation Algorithm) [11] ,事实上,1975年哈佛大学的Paul Werbos发明了BP算法 [12] ,因为当时正值人工神经网络冰河期,因此未受到应有的重视),该算法通过实际输出对比理论输出产生的误差(Error),反向微调各层连接权值系数从而优化网络权值,从而解决了Minsky认为不能解决的多层感知机的学习问题。藉此,带来人工神经网络研究的二次热潮。
20世纪90年代中期,随着统计学习理论和支持向量机的兴起,人工神经网络学习理论性质的不明确、试错性强、使用中充斥大量“技巧”的弱点,使得人工神经网络研究又进入低谷,NIPS会议甚至多年不接受人工神经网络为主题的论文。
三层人工神经网络模型,如图7所示。

Figure 7. The ANN model for 3 layers
图7. 三层人工神经网络模型
2010年前后,随着算法改进、计算速度提升和大数据的涌现,“深度学习”在自然语言处理(Natural Language Processing,NLP)、图像识别、下棋(AlphaGo、Master [13] 、AlphaGo Zero [14] )、自动驾驶等应用领域取得显著成绩,人工神经网络又再度焕发青春,从而掀起持续至今的第三次高潮。
综上,与其他技术发展的Gartner曲线(如图9,一般技术发展只经历一次低潮,发展阶段包括:技术萌芽期、期望膨胀期、泡沫化低谷期、复苏期、实质生产高峰期 [15] )不同的是,人工智能和人工神经网络的发展到目前为止都经历了三起两落(如图5和图8),且两者的高潮期和低谷期多有重合。低潮多是因概念被过渡泡沫化后的幻灭或者遇到解决实际问题的瓶颈,而高潮也多是踏踏实实、兢兢业业的研究者坚持研究或者转换思路取得新的突破,赢得大家的认可,进而促成。
从成就来看,人工智能目前所能做的,基本上都是弱人工智能领域(弱人工智能和强人工智能两个概念由J. Searle在1980年提出 [16] ),诸如下棋、自动驾驶、智能导购、智能金融、智能医疗等领域,而且当前有Google公司提供的TensorFlow和Facebook提供的Pytorch等开源平台,但是随着弱人工智能的不断成熟和聚合,类似美国Waston公司制造的索菲亚机器人(2017年10月26日,沙特阿拉伯授予该“女性”机器人公民身份)有着综合各种弱人工智能成就强人工智能的潜力和趋势。所以从模仿人脑功能角度看,人工智能发展又可以划分为三个阶段:计算智能阶段、感知智能阶段和认知智能阶段,前两个阶段,都属于弱人工智能,最后一个阶段属于强人工智能。
其中,人工智能实现的诸如自然语言处理、图像和语音识别等成就,多是深层人工神经网络(DNN)做出的,而人工神经网络之所以能起到如此作用,我们以为其主要是源于人工神经网络可以对任意连续函数进行任意逼近(仅有一个隐含层的人工神经网络,只要隐层神经元足够多,可以对任意函数进行任意逼近) [17] [18] ,而深度学习人工神经网络相比只有一个隐层的人工神经网络,层次分明,且相同效果情况下参变量个数更少 [19] 。我们对人工神经网络的数学模型进行了表述如下,假设把人工神经网络每一层的输入变量和输出变量作为向量看待,可以得到人工神经网络简化的数学形式,如下:
其中,Y为人工神经网络输出向量,Xi为第i层的输入向量,Fi为第i层的激活函数。从该数学形式看,人工神经网络的训练就是每层输入在不同激活函数下进行的反复迭代的过程,这个训练(或迭代)的过程符合生物的成长和进化过程,而其有监督的BP算法或无监督的贪婪算法(Greedy Algorithm) [20] 也符合生物成长、进化过程中环境的奖惩机制。这就进一步阐释了,人工神经网络能部分模拟人脑功能的原因。由深度学习延伸的增强学习网络(Reinforcement Learning)则从算法角度引入了环境奖惩机制 [21] ,从而在围棋游戏、自动驾驶等领域取得显著进展;而对抗生成网络 [22] (Generative Adversarial Networks)则从模型

Figure 8. Development curve of ANNs
图8. 人工神经网络发展曲线图

Figure 9. The hype cycle of Gartner (picture from Wikipedia)
图9. 技术成熟度Gartner曲线(图片源自维基百科)
角度引入生成网络和对抗(专家)网络的对抗生成机制,在图像生成方面取得斐然的成绩,该模型甚至被YannLeCun (人工智能领域另一个神一样存在的人物,Hinton的学生)称为“20年来机器学习领域最酷的想法”。
3. 相关技术
人工智能提出后,从最初的工业机器人,到现在的服务型机器人、甚至情感机器人,一直为人们所津津乐道。同时,机器人的制造也催生了相应领域的硬件和软件的发展,硬件方面,如:机器人的大脑(微处理器)、传感器(视觉传感器、声学传感器、力学传感器、位置和姿态传感器)、驱动器(舵机等);软件方面,主要集中在机器学习的方面。
机器学习(Machine Learning,缩写ML),这个概念是当时在IBM工作的Arthur Samuel(参加Dartmouth会议的成员之一)于1959年提出的,其对机器学习最初的定义是,让计算机在未经严格编程的情况下具备学习能力的领域 [23] 。机器学习主要是从算法入手,使用算法来解析数据,从中学习,然后对真实世界中的事件作出决策和预测。其算法按照学习形式主要分为三类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和半监督学习(Semi-supervised Learning)。其中,监督学习就是训练样本数据和分类识别结果已知,其对人工神经网络的训练就是监督人工神经网络对照相应输入得到相应输出的过程;无监督学习就是只知训练样本数据而分类识别结果未知,通过训练学习让神经网络对样本进行自行认知和分类;而半监督学习介于监督学习与无监督学习之间,其通过部分已知和部分未知分类识别结果的样本数据,对神经网络进行训练,以防止神经网络的过度拟合(Overfitting),并促成其泛化能力(Generalization Ability)的考量。三者的主要区别在于是否对训练样本进行标记(或打标签)。而机器学习的具体研究方法有:回归算法(通过最小二乘法对所有训练样本数据进行函数拟合的学习过程)、决策树(通过类别的相关属性递归判断,并最终确定所属分类的学习过程)、人工神经网络、支持向量机(通过不断调整划分超平面的方向,寻找对已知样本数据尤其是具有支持向量特点的样本数据“最大间隔”的划分超平面的学习过程)、贝叶斯分类器(通过贝叶斯概率模型,寻找最小化分类错误率的贝叶斯最优分类器的学习过程)、集成学习(通过结合多个现有学习算法构建一个综合学习器进而完成学习任务的算法)、聚类(通过计算样本之间的“闵可夫斯基距离”,将样本数据划分为若干不相交的子集或簇的学习过程)、表征学习等 [24] 。通过研究分析,我们做如图10所示概括。
人工神经网络(Artificial Neural Networks,缩写ANNs),其起源可以追溯到1943年,心理学家W. S. McCulloch和数理逻辑学家W. Pitts提出了MP模型(两个科学家名字的首写字母缩写命名),是受大脑神经元启发构建的计算模型 [5] 。据研究,人的大脑拥有数以亿计的神经细胞,每个神经细胞都和其它神经细胞有数以万计的连接,这些连接由每个神经细胞伸出的“突触”建立,可见我们的大脑,其实就是一张密密麻麻的网。人工神经网络最初的构想是通过建立人脑一样的网络从而让机器像人一样思考和学习 [25] 。东南大学魏海坤教授,对人工神经网络的定义是:人工神经网络是指用大量简单计算单元(即神经元)构成的非线性系统,它在一定程度和层次上模仿了人脑神经系统的信息处理、存储及检索功能,因而具有学习、记忆和计算等智能处理功能 [26] 。人工神经网络的关键是人工神经网络的结构(Architecture)、权值(Weights)/阀值(Bias)和算法(Algorithms),比如,人工神经网络设计几层,每一层多少个神经元,每个神经元之间怎样连接,以及利用什么算法优化调整神经元连接的权值或阀值。Simon Haykin在其书《人工神经网络原理》中,曾说:“人工神经网络是一种高级复杂运算量巨大的参数估计” [27] 。而台湾大学李宏毅教授也高屋建瓴的指出,“人工神经网络的训练就是从一堆函数集中择优的过程” [28] 。这些说法都很有见地。另外人工神经网络根据层数和是否有反馈,有如图11的分类,所谓反馈神经网络就是一种将输出经过一步时移再接入到输入层的神经网络模型,它需要运行一段时间才能趋于稳定,Hopfield网络是反馈神经网络中最简单应用最广泛的模型 [10] ,而图7所示神经网络属于前向神经网络,目前神经网络研究的模型多是前向神经网络。
深度学习(Deep Learning,缩写DL),这个概念是Hinton提出的 [29] ,因此Hinton也被称为“深度学习之父”。深度学习是指基于软件的计算机通过模拟人类大脑神经元的功能,彼此相连,形成一个阶层类的“人工神经网络”。不同于浅层学习算法或传统式机器学习的手工获取特征,深度学习使用多层非线性处理单元变换数据输入,上层输出作为下层输入,自动提取数据特征 [30] 。我们以为,深度学习,从模型结构角度来看,其本质可以理解为多层网络;从学习算法角度看,其本质可以理解为多种算法的分层处理。近几年深度学习越来越火,同时引领了图像识别和语音识别等领域的很多突破性进展,可以说其快速发展得益于算法的不断改进(无监督的贪婪算法、分布式算法 [1] 等)、硬件速度的提升(GPU和TPU等专用领域集成电路的诞生)和在线大数据(Big Data)的爆发。
对于这些概念和技术之间的关系可以总结为:人工智能是一个领域,涉及硬件和软件,而其软件方面的研究,延伸出了机器学习,人工神经网络是研究机器学习的一种方法思路,同时更是一个模型,所以有它自己的独立性,深度学习又从算法和模型两个角度对人工神经网络进行了延伸。它们之间的关系,我们用图12表示。自此我们可以看出,人工智能目前有两个研究思路,一是采用“自上而下”的专家指导思路(符号推理、知识工程均属于此思路),采取“如果–就”(if-then)规则;二是采用“自下而上”的数据学习思路(深度学习人工神经网络属于此思路),采取从数据中寻找模式的“迭代”(for)规则。

Figure 10. Classification of Machine Learning algorithms
图10. 机器学习算法分类

Figure 11. Elements and classifications of ANNs
图11. 人工神经网络要素和分类
4. 存在问题与展望
Hope Reese在2016年12月3日,撰文《2016年人工智能十大失败案例》(《Top 10 AI failures of 2016》) [31] ,Synced在2017年12月23日,撰文《2017年人工智能十个失败案例》(《2017 in Review: 10 AI Failures》) [32] ,我们对所有20个失败案例进行了汇总分析,发现这些失败案例主要分两类:错误(识别错误、生成错误)和偏见(种族歧视、性别歧视)。而这两类,我们以为也是可以解释的,错误原因在于模型的鲁棒性不强,而偏见则源于深度学习对数据的过度依赖性。但是据此,就有人说“所谓人工智能,无非是人工智障”,我们以为是不合适的,因为任何事物的成长都有一个从不成熟到成熟的过程。相比人工智能和人工神经网络在提出之初的成就,现在的成就可以说是相当斐然的,因此,相信人工智能和人工神经网络的未来是光明的。
由此我们对人工智能和人工神经网络作出以下五个方面的展望:
1) 模型和算法有待进一步改进,以消除错误和偏见现象,加强人工神经网络的鲁棒性和价值观引导。新的模型和算法也有待于进一步提出。现有的人工神经网络模型基本都是前向人工神经网络,因为其算法复杂度低,但据神经解剖学家研究发现人类的大脑是浸润在反馈连接之中的;算法方面,据“神经科学之父”弗农·蒙卡斯尔认为,不同的大脑皮层区域有一个相同的、强大的通用算法,造成区别的原因是它们连接对象的不同 [33] 。这一点,也给我们以模型和算法创新的启示。而前不久“深度学习之父”Hinton最新撰写的论文《Dynamic Routing Between Capsules》,提出胶囊(Capsule)理论,来模拟人脑做图像识别的机制,也是一次向神经科学靠近的尝试 [34] 。
2) 人工神经网络一直被冠以“黑箱化操作”的技术。所以其可视化研究,有助于让人们了解其内在细节,进而有助于其的进一步发展,虽然卷积人工神经网络的可视化取得一定成效 [35] ,但是其他种类的人工神经网络可视化还有待进一步研究。这里提供一种思路供大家参考,可以就训练好的网络进行总体可视化处理,然后再对该网络每一层的任一神经元看做“输出”,做可视化处理。
3) 向自然界各种生物的强大基因学习。地球上的生物,都经历了上亿年的进化,可谓是相当精密的仪器,据说,台湾地区有一种薄翅蜻蜓,能不吃不喝单程飞行7000 km,从亚洲飞到非洲,去传播基因,途中还能繁殖出下一代,它的低耗和繁殖能力,让当前制作的各种机器和模型自愧不如,因为据报道,我国的“天河二号”年耗电量达到2亿度,每天耗费电费10万元。另外,理所当然认为当前图像和语音识别技术多是围绕听觉和视觉两个维度在做,因为当前的编码还只能对声音和图像进行编码,相对触感、气味和味觉的编码还处于萌芽阶段,而人类具有听觉、视觉、触觉、味觉、嗅觉等多个维度,甚至人类还有最终的知觉,这也可以解释,为什么人类在对物体的分类识别等方面优于计算机,高维度的生物在一定程度上要优于低维度的生物。类似的功能还有很多,都是可以作为人工智能下一步的发展方向。综上所述,可以分别从硬件、算法效率和编码的角度进行改进和探索。
4) 人工神经网络的去“技巧化”也是一个需要被研究的课题。当下人工神经网络模型的建立和训练,基本靠的是经验和“技巧”,缺乏有效的理论指导。因此我们认为,人工神经网络的数学化,有助于其长足发展,类似于香农创立“信息论”,从而为数字通信的发展指明了方向。我们以为,人工神经网络的理论化思路可以藉由两个方向入手:一是归因到经典数学问题,二是创造新的概念和理论体系。
5) 量子通信最近也发展的如火如荼,而量子有不确定性、不可克隆、测量坍塌的特性,纠缠量子具备纠缠特性等等,都可以用于从一个全新的视角来定义和理解世界,因此量子与深度学习的结合,肯定能碰撞出新的成功。2015年5月,Nathan Wiebe等发表了《量子深度学习》(《Quantum Deep Learning》),采用量子的训练方法训练玻尔兹曼机来代替经典算法中的对比散度算法在时间复杂度上有所提升 [36] ;2015年,中国科学技术大学的杜江峰老师组也在美国的物理评论快报(PRL)发表了《Experimental Realization Of A Quantum Support Vector Machine》,并率先在一台NMR(核磁共振)实现的量子计算机上演示了这个算法,对MNIST手写笔记中的6和9进行了分类 [37] ;2017年7月,清华交叉信息研究院的博士研究生郜勋和段路明教授,在《Nature Communications》上发表《量子多态深度人工神经网络的有效表征》(《Efficient Representation of Quantum Many-Body States with Deep Neural Networks》) [38] 。研究表明这两个领域结合部也是值得进一步探究。我们以为,人脑的很多特性具备量子的特性,或者从某种程度讲,人脑应该是一个量子态的人工神经网络,在空闲状态下,大脑中的每个神经元应该是处于量子叠加态的,但是遇有需要集中注意思索的情况,神经元的状态就会坍塌。据此,我们觉得,可以考虑构建量子人工神经网络来模拟人脑的诸多功能。
基金项目
1) 国家自然科学基金项目(61472446);
2) 国家自然科学基金项目(61701539);
3) 数学工程与先进计算国家重点实验室开放课题项目(2016A01)。