1. 引言
近年来,我国股权众筹行业高速发展,项目数量和平台数量都大幅增长。股权众筹在增加投资者理财方式的同时,更完善了小微企业的融资渠道,从而提高了金融市场的效率,促进了我国创新创业,推动了经济结构转型。股权众筹虽然有优势有活力,可以降低获取信息的成本,但也不可避免地存在着虚假信息,各利益相关者信用风险问题很大,所以股权众筹行业乱象丛生 [1] 。尤其是这两年互联网众筹平台跑路、倒闭、作假事件屡屡发生,互联网金融行业的信用风险不容乐观。如何对股权众筹信用风险进行分析,并采取量化的方法对其进行风险评级,进而提高小微企业抵御风险的能力,已成为学术界、工业界研究的重点 [2] 。
从过去的研究来看,对小微企业风险的研究大部分集中在定性分析上,即使涉及到定量方法,也多是层次分析法、模糊评价法等传统方法。这些方法不适合股权众筹平台这种影响因素繁多复杂的系统,而且评价结果的可靠性和精确性无法保证。随着互联网技术的不断创新发展,风险评价也向着标准化、系统化和精确化方向推进,出现了新的将计算机模拟与风险评价相结合的方法。支持向量机法(SVM)作为一种备受推崇的数据挖掘技术,已经在文本识别、人脸识别、银行信用风险评估等诸多实践领域得到广泛应用 [3] 。本文将SVM方法引入我国小微企业风险评级中,以提高风险评价精度和效率。
2. 构建小微企业风险评级指标体系
小微企业所面临的风险因素多而复杂,本文从科学、全面、量化和可操作等角度出发,建立一套科学合理的风险指标体系。根据小微企业的特点,将风险评价指标体系分为5个一级指标和18个二级指标,指标体系具体构建为行业市场环境、产品竞争力、企业基本情况、管理团队素质和财务数据表现五个一级指标,其相应的二级指标以及与一级指标的关系如图1。
3. SVM的基本原理
支持向量机(SVM)核心思想是建立一个最优分类线或最优超平面作为决策曲面,将多类样本正确地进行分类。即先通过一定量的样本进行训练,通过不断检验与优化得到较高的训练精度,确定一个最优的决策函数再对分类问题进行处理。我们以二分类问题为例分析一下具体过程 [4] 。
3.1. 线性可分问题
图2中分别是两类样本,支持向量机方法就是寻找最优分类线将两类样本分开,分类线表示为
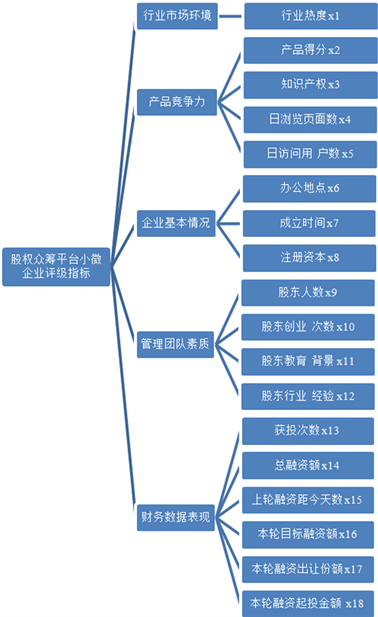
Figure 1. Risk rating system for small and micro businesses in China
图1. 我国小微企业风险评级指标体系
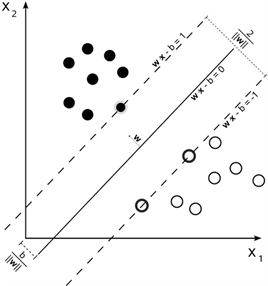
Figure 2. Finding the optimal classification line for two types of samples
图2. 寻找两类样本的最优分类线
,最优分类线代表着最大分类间隔,可用如下最优化问题表示:
(1)
(2)
其中的约束要求各数据点
到分类面的距离大于等于1。其中,
为数据的分类。
引入Lagrange函数可将上述问题转化为对偶问题:
(3)
(4)
(5)
求解上述问题得到最优解:
(6)
将参数代入原式,即可得到最优分类平面。
3.2. 线性不可分问题
对于线性不可分问题,原来对间隔的要求不能达到。引入松弛变量
,使约束条件弱化为:
。但是,我们仍然希望该松弛变量
最小化。于是,在优化目标函数中使用惩罚参数
来引入对
最小化的目标。此时模型为:
(7)
(8)
以此为原问题,其对偶问题为:
(9)
(10)
(11)
求解得到最优解为:
(12)
3.3. 非线性问题
对于非线性问题,可以将低维空间中的曲线(曲面)映射为高维空间中的直线或平面。数据经这种映射后,在高维空间中是线性可分的。设映射为
,则高维空间中的线性支持向量机模型为:
(13)
(14)
(15)
由于数据被映射到高维空间,
的计算量比
大得多。此时引入了 “核函数”:
(16)
由上式可见,核函数的作用是,在将
映射到高维空间的同时,也计算了两个数据的在高维空间的内积,使计算量回归到
的量级。
4. 基于SVM的风险评级
4.1. 收集并处理样本数据
根据图1风险评价指标体系搜集相关的样本数据,本文选取130家小微企业作为研究对象,并搜集他们2017年的原始数据资料,部分企业数据见表1。
观察数据集中每一个评级的数量分布,结果见表2。
可见,各个评级的样本分布相对均衡。

Table 1. Original data of the first 10 enterprises
表1. 前10家企业原始数据
我们进一步观察每一个指标的取值分布,见表3。
观察发现数据取值范围差异很大,因为SVM要用到距离,所以必须做标准化处理,这里采用Min-Max标准化方法处理,结果见表4。
可以看到所有数据都在0~1之间,可以进行后续的距离计算。
4.2. 组建样本训练集,训练模型
把前91家公司数据作为训练集,后39家公司数据作为测试集,用SVM来进行模型构建。SVM有两个主要的参数可以设置:核函数参数kernel和约束惩罚参数C。其中约束惩罚函数C为对超过约束条件的样本的惩罚项。C值越大,惩罚越大,支持向量机的决策边界越窄。我们选用最简单的线性核函数,C采用200,训练得到最初的模型。
4.3. 模型性能评估
首先,要得到我们训练的模型在测试集上的预测结果,然后对模型的性能进行评估。模型准确率、
表2. 各评级分布
Table 3. Statistical data of various indicators
表3. 各项指标统计数据
Table 4. Statistical data of various indicators after standardization
表4. 标准化后各项指标统计数据
召回率和f1-score见表5。
具体的评级预测结果见表6。
该混淆矩阵中对角线的元素表示模型正确预测数,对角元素之和表示模型整体预测正确的样本数。而非对角线元素上的值则可以反映模型在哪些类的预测上容易犯错,例如评级2均有三次被预测为0和1。
最终分类正确率:0.866666666667。
4.4. 模型性能提升
各项指标可以进一步提高,我们进行参数调优,可以改善模型性能,进一步提升模型效果。
首先是核函数,通过循环依次取不同的核函数,准确率见表7。
可以看到,最好的是“rbf”这个核函数,可将正确率提升至:0.883333333333。
核函数确定后,我们再来看C的取值。第一次给定这样一个列表:c_list = [0.01,0.1,1,10,100,500],循环依次取值,准确率见表8。
可以看到,在C = 500左右模型效果提升很大,可以进一步探究C = 500左右的正确率变化情况。所以给定这样一个列表c_list2 = [100,200,300,400,500,600],循环依次取值,准确率见表9。
可以发现C = 500时模型效果确实不错,可将正确率提升至:0.933333333333,评价指标及混淆矩阵见表10和表11。
为了进一步提升模型的效果,我们重点关注惩罚因子C是否会有更优的取值。因为求SVM最优参
表5. 模型评价指标
表6. 模型评级结果
Table 7. The corresponding accuracy of each kernel function
表7. 各核函数对应准确率
Table 8. The corresponding accuracy of each C value
表8. 各C值对应准确率
Table 9. The corresponding accuracy of each C value
表9. 各C值对应准确率
表10. 模型评价指标
表11. 模型评级结果
数本质上是一个二次凸规划问题,即求解函数最优值,而遗传算法最主要的用处就是函数最优化。因为遗传算法是一种高效的随机搜索算法,而且克服了诸如网格搜索法等容易陷入局部最优的缺点,可以通过多次尝试,找到全局最优解。同时遗传算法也会同时考虑kernel参数,避免模型出现过拟合现象 [5] 。我们基于遗传算法的SVM算法如下:
步骤1:初始化种群,随机生成初始种群个体;
步骤2:将种群中各个体基因串解码为相应核函数编号、核函数参数和错误惩罚因子,并将参数代入SVM,以训练数据和测试数据对其进行训练和测试;
步骤3:按照适应度计算法则,计算每个个体的适应度值;
步骤4:判断是否满足终止条件,如果满足终止条件,退出循环,遗传优化结束,得到优化参数组合,否则转到步骤5;
步骤5:执行选择算子,按照最优保存、最差取代的原则进行;
步骤6:执行交叉算子和变异算子,交叉概率取0.7,变异概率取0.1,形成新一代个体后,返回步骤2继续执行。
我们用这个模型来进行参数优化,最终选取核函数“rbf”以及惩罚因子C = 700,评价指标及混淆矩阵见表12和表13。
正确率可以达到:0.966666666667。
4.5. 模型对照
为了更好的说明模型效果,我们以逻辑回归模型作为对比,且选择调优后的参数,这里C = 1000,penalty = “l1”,solver = “liblinear”,评价指标及混淆矩阵见表14和表15。
正确率可以达到:0.85,效果不如SVM模型。
5. 结论
通过对我国小微企业风险评级的研究,我们发现:
1) 与逻辑回归方法相比,SVM方法在准确率等各项评价指标都明显更优,而且可以通过参数调优不断提升指标,从而更好的对企业风险进行评级。该方法对小微企业风险评价与预测这一复杂的领域有
表12. 模型评价指标
表13. 模型评级结果
表14. 模型评价指标
表15. 模型评级结果
很重要的指导作用。
2) 对SVM参数直接调优可以得到更好的效果,本文引入了遗传算法进行参数调优,可以得到最优化的结果。