1. 引言
我国近年风电发展迅猛,截止到2015年,我国风电新增装机容量30.5 GW,同比上升26.61%,连续六年位居全球新增装机容量首位;累计装机容量达到145.1 GW,其中并网容量达到129 GW,占全部发电装机容量8.6%。2015年,风电总发电量1863亿千瓦时,占全部发电量的3.3%。与风资源分布特性及电网负荷布局相匹配,我国的风电发展以并网型为主,呈现典型的集群开发、弱电网接入、长距离外送的特点。风电的波动性、随机性给电网的有功平衡和电压调整带来了压力,增加了电网规划和调度的难度,也成为制约风电进一步发展的瓶颈 [1] 。掌握风电波动性在不同时间、空间尺度上的内在规律是解决大规模风电并网运行难题的关键基础。现今风力发电主要利用的是近地风能,但近地风具有波动性、间歇性、低能量密度等特点,因而风电功率也是波动的。大规模风电场接入电网运行时,大幅度地风电功率波动会对电网的功率平衡和频率调节带来不利影响。因此,我们要实现对风电场发电功率的尽可能准确地预测,这样,电力调度部门就能够根据风电功率变化预先安排调度计划,保证电网的功率平衡和运行安全。
2. 问题提出
实时预测是风电功率预测的一种,它要求滚动地预测每个时点未来4小时内的16个时点(每15分钟一个时点)的风电功率数值。根据国家能源局颁布的《风电场功率预测预报管理暂行办法》中的要求,实时预测的误差不能大于15% [2] 。
实验风电场由58台风电机组构成,每台机组的额定输出功率为850 kW。实验中统计出了2016年5月10日至2016年6月6日时间段内该风电场中指定的四台风电机组(A、B、C、D)输出功率数据(分别记为PA,PB,PC,PD;另设该四台机组总输出功率为P4)及全场58台机组总输出功率数据(记为P58)。
根据风电功率预测精度要求现提出以下三个问题:
问题一:风电功率实时预测方法及误差分析。
问题二:研究风电机组的汇聚对于预测结果误差的影响。
问题三:提高风电功率实时预测精度的探索。
通过解决上述三个问题,找出阻碍风电功率实时预测精度进一步改善的主要因素。研究风电功率预测精度是否能无限提高。
3. 问题分析
1) 问题一:风电功率实时预测方法及误差分析。
该问题是电功率的实时预测及误差分析,其主要研究目的是建立一定的数学模型来尽可能准确地做出风电功率的实时预测,并使的预测结果的误差在满足国家相关规定的基础上尽可能小,以便提供给电力调度部门,方便其优化调度安排。
该问题属于预测类的数学问题,且是直接利用历史数据,使用一定的数学模型进行预测。常见的方法有人工神经网络法、时间序列法(AMAR)、遗传算法、灰色分析预测法、卡尔曼滤波法、及其它算法。
问题一要求至少用三种预测方法对PA PB PC PD P4 P58这六个量在未来16个时点的风电功率数值进行预测,并对结果进行误差分析,确定实时预测的相对误差不能大于15%。由于实验中所要求的16个预测结果是滚动预测所得,一般来说,风电功率的预测值与实测值之间存在相对较大的误差,这就需要我们对结果进行误差分析后再根据分析结果对模型进行进一步优化。
基于以上考虑,我们可以分别用时间序列法建立数学模型一,用灰色分析预测法建立数学模型二,用人工神经网络法建立数学模型三,对结果进行预测,并将预测结果进行比较,同时分别对各模型所的预测结果进行分析。
2) 问题二:研究风电机组的汇聚对于预测结果误差的影响。
本问题要求分析风电机组的汇聚对与预测数据误差的影响。在我国主要采用集中开发的方式开发风电,各风电机组功率汇聚通过风电场或风电场群(多个风电场汇聚而成)接入电网。众多风电机组的汇聚会改变风电功率波动的属性,从而可能影响预测的误差。故而对风电机组的汇聚和其相应的预测数据误差进行分析,得出二者之间的关系,将对我们分析预测大规模的风电场群的风电功率提供参考 [3] 。
即问题二实质上是研究风电机组的台数与对应的风电功率预测值的相对误差之间的关系。
因此,我们可以用问题一中预测结果的相对误差,比较单台风电机组功率(PA, PB, PC, PD)预测的相对误差与多机总功率(P4, P58)预测的相对误差,再用时序分析法建立模型四来拟合确定台数的风电功率预测值的相对误差与对应风电机组的台数之间的函数关系,进而对风电机组汇聚给风电功率预测误差带来的影响做预期。
3) 问题三:提高风电功率实时预测精度的探索。
从问题一和问题二的结果我们可以看出模型一、模型二、模型三所得出的预测结果都存在一定程度的误差,而提高风电功率实时预测的准确程度对改善风电联网运行性能有重要意义。因而在模型一、模型二、模型三的基础上,构建有更高预测精度的实时预测方法是非常必要的。
通过对问题一的求解,我们可以分别得到模型一、模型二、模型三的拟合优度,再利用三个拟合优度的比值来确定三个模型所得预测值的权重,进而用组合预测的方法得出模型五,使得预测精度进一步提高。
4. 建立模型与预测精度研究
4.1. 模型一(非平稳时间序列模型)
4.1.1. 数据预处理
首先取58台5月30号的96个样本数据序列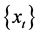 得到如下图1。
得到如下图1。
由图1表明:该样本构成的时间序列为非平稳时间序列。
由此对该样本值进行有序差分变换
差分算子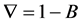
对96个样本值进行一阶差分可得到如下 序列图2。
序列图2。
有图2表明:该序列已平稳,则原时间序列可表示为

Figure 2. Data difference processing sequence curve
图2. 数据差分处理序列曲线

即自回归–滑动平均模型 。
。
4.1.2. 平稳随机时间序列模型的识别
计算偏自相关系数及自相关系数
自相关函数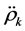
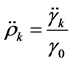
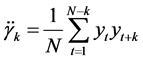
偏自相关函数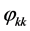
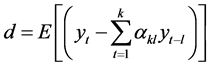
当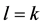 时,第
时,第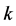 系数
系数 为平稳序列
为平稳序列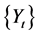 的偏自相关系数。
的偏自相关系数。
运用统计学软件我们得到该平稳序列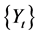 PACF、ACF。
PACF、ACF。
4.1.3. 模型识别与模型参数估计
1) 模型识别
我们运用经典的Box-Jenkins模型识别方法。
对于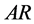 模型,其偏自相关函数满足下式
模型,其偏自相关函数满足下式

对于 模型,其自相关函数满足下式
模型,其自相关函数满足下式
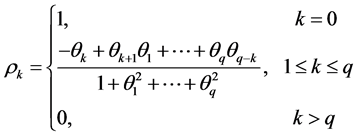
对于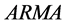 模型,同时具备
模型,同时具备 和
和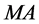 模型的特征 [4] 。
模型的特征 [4] 。
由此我们给出三种模型的基本特征如表1。
由上面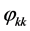 、
、 统计特性,我们可以判断该模型属于
统计特性,我们可以判断该模型属于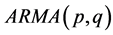 。
。
2) 模型参数估计
由1)我们得到该模型属于 模型,因此我们对该模型进行参数估计,由该模型可推得
模型,因此我们对该模型进行参数估计,由该模型可推得

我们令 ,则
,则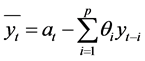 ,这样就将原
,这样就将原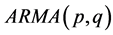 变成
变成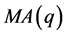 模型,我们根据
模型,我们根据 的参数估计对
的参数估计对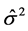 、
、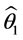 ,…,
,…, 进行估计。
进行估计。
若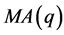 的阶数较低我们可直接求解。
的阶数较低我们可直接求解。
若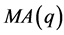 的阶数较高,可运用线性跌代法求解 [5] 。
的阶数较高,可运用线性跌代法求解 [5] 。

Table 1. Characteristics of three basic models
表1. 三种基本模型特征
4.1.4. 模型定阶
根据AIC最小信息准则法进行模型定阶,经过逐步的模型拟合,矩估计模型参数估计,我们最终得到当模型的阶数为 模型,拟合效果达到最优。
模型,拟合效果达到最优。
由此我们确定模型为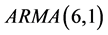 。
。
4.1.5. 建立预测模型
对于 模型,由于样本个数
模型,由于样本个数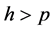 ,因此残差项
,因此残差项 ,这里运用统计spss软件可求得则预测方程为
,这里运用统计spss软件可求得则预测方程为
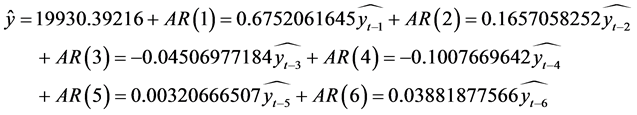 。
。
4.1.6. 实时预测
运用预测方程对5月31号的数据进行预测得到如下曲线图5。
从图3中表明:基本上符合了58台电机组5月31号的输出电功率的趋势。但预测明显存在延时性,以及预测精度不高,现在我们对其进行误差分析 [6] 。
4.1.7. 误差分析
通常用三个指标来对模型进行评估:
均方根误差:
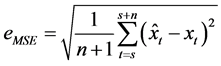
平均绝对误差:
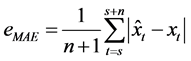
平均相对误差:
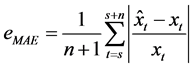
在这里我们仅运用相对误差进行分析如下。
将数据代入公式我们得到表2。
为了减小误差我们将采用组合预测的方法使误差达到最低。
4.2. 模型二(人工神经网络模型RBF)
4.2.1. 构造神经网络结构图
一般的我们选取隐层为3的结构图,它能更好地对误差进行反向修正。由此我们构造如图4。
4.2.2. 输入变量的的选择
我们利用模型一建立好的时间序列模型选择输入变量。
在模型一中表明:原始的电功率序列 进行1阶差分处理的序列
进行1阶差分处理的序列 可识别为
可识别为 模型。
模型。
由此我们选择输入的变量为最近的6个历史数据及最近的一个残差 为组。
为组。
Table 2. Error analysis of time series model
表2. 时间序列模型误差分析
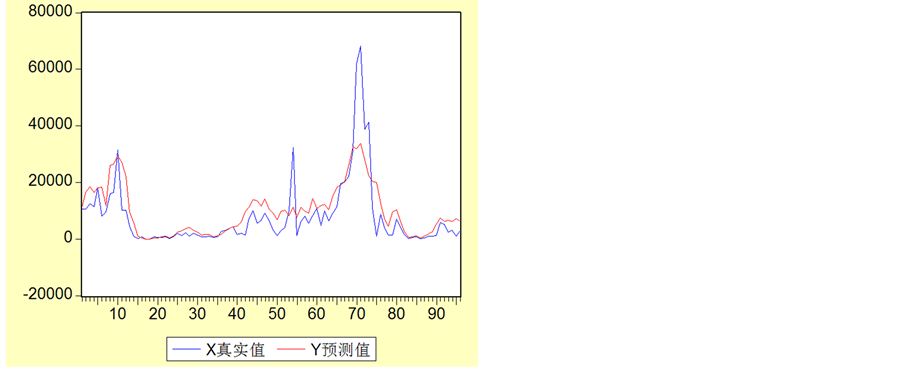
Figure 3. Comparison curve of prediction data and real value
图3. 预测数据与真实值的比较曲线图

Figure 4. Neural network structure diagram
图4. 神经网络结构图
4.2.3. 网络输入输出数据的归一化处理
对输入输出的数据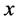 采用以下公式
采用以下公式
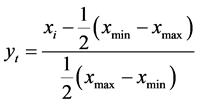
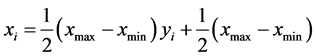
进行归一化处理使其落在[−1,1]区间。
4.2.4. 网络训练及预测结果输出
对输入选择的变量进行网络函数训练。
第一步我们对输入的变量从输出层得到输出值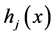

第二部从隐含层输出函数为
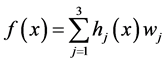
由此我们根据LAMP算法可得到如下曲线图5。
4.2.5. 模型误差分析
我们同样取P58台电机组的5个数据进行误差分析得到如下表3。
Table 3. Error analysis of neural network
表3. 神经网络误差分析
4.3. 模型三
灰色预测矩阵
同理我们仅取P58台机组的6个历史数据运用灰色预测法进行预测。
灰色预测基本原理如下:
首先,进行一次累加
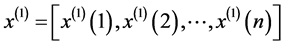
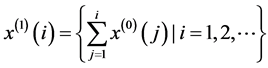
其中,显然有 ,
,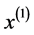 表示累加后的数列 [7] 。
表示累加后的数列 [7] 。
然后,参数估计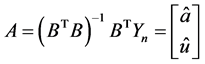
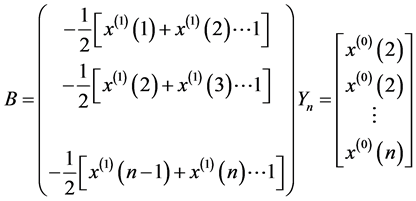
其次,累加数列 的灰色预测模型
的灰色预测模型
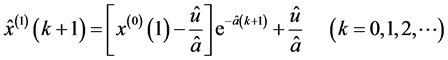
由此,求原始数列的灰色预测模型

最后,进行模型精度的方差检验
历史数据残差为:
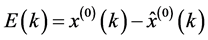
相对残差为:

预测结果:
对模型的预测结果。
得到真实观测与拟合曲线的对比基本重合。
同理我们对模型进行误差分析得到如下表4。
1) 问题二
我们分别运用三种模型对PA、PB、PC、PD、P4、P58进行误差分析,我们仅取相对误差进行分析如下表5。
表5表明:多机组的误差总体上小于单机组的误差。
Table 4. Error analysis of grey model prediction
表4. 灰色模型预测误差分析
Table 5. Relative error analysis of PA, PB, PC, PD, P4 and P58
表5. PA、PB、PC、PD、P4、P58相对误差分析
因此我们期望为了尽可能准确预测,尽量使多台电机共同运作,以使能够更好的对未来发电输出功率进行预测。
2) 问题三
为了进一步提高风电功率的预测精度,我们建立了组合预测模型其表达式如下。
设三种模型分别表示为P1、P2、P3则组合预测模型为
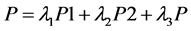
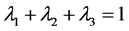
3种预测模型的方差、误差分别为 、
、 、
、 、
、 、
、 、
、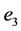 则
则
组合预测误差的方差为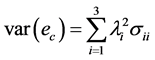 。
。
当三种预测方法的预测误差分别服从零均值正太分布时,可用以下式估计
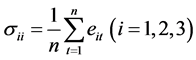
由此我们可得出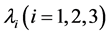 的估计值为
的估计值为
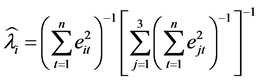
由此证明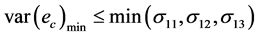 ,表明组合预测的方法优于单一预测方法 [8] 。
,表明组合预测的方法优于单一预测方法 [8] 。
5. 结论
1) 模型一的评价
优点:对于短、近期预测比较显著。
缺点:延伸到更远的将来,就会出现很大的局限性,导致预测值偏离实际较大而使决策失误。
不适用于对长远数据的预测。
2) 模型二的评价
优点:BP神经网络是一种有效的非线性建模方法;具有很强的容错性和很快的处理数据能力。
缺点:网络结构的选择尚无一种统一而完整的理论指导,理解起来比较费劲,对模型学习速度慢。
3) 模型三的评价
优点:算法简单、可利用较少数据建模。
缺点:对于复杂的非线性系统来说预测的效果不是很理想。
4) 总结:
对于风电机组群问题我们同样采用问题三的模型,即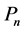 时我们采用组合预测模型。这样可以尽量提高预测精度,但是不可能得到无限提高。
时我们采用组合预测模型。这样可以尽量提高预测精度,但是不可能得到无限提高。
基金项目
2013湖南省教育厅课题13C862。