1. 引言
近年来,数字信息、电子资源和在线服务的数量呈指数级增长。信息超载出现了一个潜在的问题,即如何给用户过滤和有效地传递相关信息。这是一个可以过滤用户不需要的信息和可以预测用户需要的物品的系统。这样的系统被称为推荐系统。
假设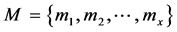 是所有用户的集合,
是所有用户的集合, 是所有可能的被推荐的项目,
是所有可能的被推荐的项目,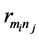 是用户mi对项目nj的评分。
是用户mi对项目nj的评分。
 (1)
(1)
R是一个完全有序的集合。对于每一个用户 ,推荐系统的目的是选择最符合用户的兴趣的项目
,推荐系统的目的是选择最符合用户的兴趣的项目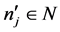 。我们可以指定如下:
。我们可以指定如下:
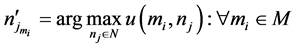 (2)
(2)
协同过滤系统可以分为两类:基于内存的协同过滤和基于模型的协同过滤。基于内存的协同过滤,其基本思想是用统计的方法得出所有用户对物品或者信息的偏好,然后发现与当前用户口味和偏好相似的邻居用户群 [1] 。基于模型的方法就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。基于模型的方法比基于用户的协同过滤方法更有扩展性。
推荐系统有两个潜在的问题。一是可扩展性,即一个推荐系统多快可以产生推荐,第二是改善给一个用户的推荐准度。纯协同过滤推荐系统能够比纯基于内容和基于人口统计学推荐系统产生更好的推荐效果,但是,由于冷启动问题,导致推荐效果的偏差。
本文提出一个混合方案,能进行更准确的预测和推荐,并用来解决冷启动问题。我们提出的方案是基于一个级联的混合推荐技术,其基于项目的评分,特征和人口信息构建项目模型。评估算法的数据集是MovieLens和FilmTrust。
2. 相关研究
2.1. 基于项目的协同过滤推荐系统:项目评分信息
基于项目的协同过滤推荐系统用离线平台建立一个计算项目相似度的模型 [2] 。主要有以下三步:
1) 检索由活跃用户评价过的所有项目。
2) 使用检索的项目的集合计算目标项目的相似性。选择k个最相似的项目的集合,也称为具有它们的相似性的目标项目的邻居。
3) 通过计算对k个最相似的项目的活跃用户评价的加权和来进行对目标项目的预测。
2.2. 基于内容的推荐系统:项目特征信息
基于内容的推荐系统是基于项目的文本信息推荐项目。在这些系统中,感兴趣的项目由其相关联的特征定义,例如新闻过滤系统使用文本的词作为特征。
我们从IMDB下载关于电影的信息,并应用TF-IDF方法从关于每部电影的信息中提取特征 [3] 。我们构建了IMDB中的电影的关键字,标签,导演,男演员/女演员,以及用户评论的向量。此外,我们利用WordNet使用Java WordNet Interface克服特征之间的同义词问题,同时找到(文本)特征之间的相似性。
2.3. 基于人口统计学推荐系统:项目人口统计信息
人口统计学推荐系统是基于用户或项目的个人属性对其进行分类,并基于人口统计分类进行推荐。在我们的工作中,我们使用关于电影的类型信息作为其人口统计信息,并构造一个矢量。
3. 改进的算法
令 ,
,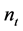 ,R,D,F分别为活动用户,目标项目,用户项目评级矩阵,项目
,R,D,F分别为活动用户,目标项目,用户项目评级矩阵,项目 的人口统计矢量和项目
的人口统计矢量和项目 的特征向量。让
的特征向量。让 ,
,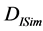 和
和 表示项目之间的评级,人口统计信息和项目间的特征相似性。 此外,令
表示项目之间的评级,人口统计信息和项目间的特征相似性。 此外,令 ,
, 和
和 分别表示在计算所有项目之后的特征相关性之后找到的候选项目之间的评级相似性,计算所有项目之后的特征相关性之后发现的候选项目之间的人口统计相似性,以及计算评分之后发现的候选项目之间的特征相似性。
分别表示在计算所有项目之后的特征相关性之后找到的候选项目之间的评级相似性,计算所有项目之后的特征相关性之后发现的候选项目之间的人口统计相似性,以及计算评分之后发现的候选项目之间的特征相似性。
提出的算法可以总结如下:
步骤1:使用评级数据,人口统计数据和特征数据来计算项目之间的相似度,并存储该信息 [4] 。两个项目之间的修正的余弦相似性用于测量已经评过分的项目的相似度。两个项目之间的向量相似性用于测量使用人口统计和特征向量的相似性。
步骤2:提高的相似性 由函数
由函数 定义,其将
定义,其将 ,
, 和
和 ,
, ,
,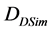 和
和 组合在训练集中的项目集合上。此函数使用公式(5)进行预测。它可以规定如下:
组合在训练集中的项目集合上。此函数使用公式(5)进行预测。它可以规定如下:
 (3)
(3)
等式(3)告诉我们选择使训练集中的项目集(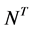 )上的所有用户(
)上的所有用户( )的效用最大化(即减少MAE)的函数。表1给出了在训练集上检查的函数的不同组合以及观察到的它们各自最低的MAE。这表明在施加特征相关性后发现的候选邻居项目中对评级和人口统计相关性进行了级联混合设置后给出了最小误差。
)的效用最大化(即减少MAE)的函数。表1给出了在训练集上检查的函数的不同组合以及观察到的它们各自最低的MAE。这表明在施加特征相关性后发现的候选邻居项目中对评级和人口统计相关性进行了级联混合设置后给出了最小误差。

Table 1. A SAMPLE OF FUNCTION(F)WITHk = 20
表1. k = 20的函数样本
令 是在应用特征相似性之后找到的k个候选邻居的集合 [5] 。我们通过在训练集中的项目集合上的
是在应用特征相似性之后找到的k个候选邻居的集合 [5] 。我们通过在训练集中的项目集合上的 ,
,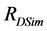 ,
, 的线性组合来定义提高的相似性
的线性组合来定义提高的相似性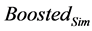 ,如下:
,如下:
 (4)
(4)
公式(4)中,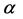 ,
,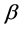 和
和 参数表示相互影响的三个相似点。我们假设
参数表示相互影响的三个相似点。我们假设 。
。
步骤3:通过使用以下公式来预测目标项目 上的活动用户
上的活动用户 的评分
的评分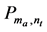 :
:
 (5)
(5)
4. 实验
4.1. 数据集
我们使用MovieLens (ML)和FilmTrust (FT)数据集用于评估我们的算法。MovieLens数据集包含943个用户,1682个电影和100000个评分记录。规模为1 (差)至5 (优)。MovieLens数据集被用在很多研究
项目中。这个数据集的稀疏性约93.7% (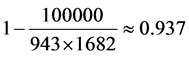 )。
)。
我们通过FilmTrust创建了第二个数据集。检索的数据集包含1592位用户,1930电影和28645评级,
规模为1 (差)到10 (优)。此数据集的稀疏度约为99.06% ( )。
)。
4.2. 评价指标
我们在本文中的具体任务是预测已经被实际用户评分的项目的分数,并且检查该预测如何有助于用户选择高质量项目。考虑到这一点,我们使用平均绝对误差(MAE)。
MAE测量推荐系统的预测评级和用户分配的真实评级之间的平均绝对偏差。其计算如下:
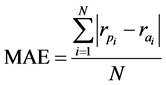
其中 和
和 分别是等级的预测值和实际值,N是已经评分的项目的总数。对于MovieLens数据集,如果用户对其评分为4分或更高,则认为该项目很好,否则为差 [6] 。类似地,对于FilmTrust数据集,如果用户对其评分为7分或更高,则认为项目良好,否则为差。
分别是等级的预测值和实际值,N是已经评分的项目的总数。对于MovieLens数据集,如果用户对其评分为4分或更高,则认为该项目很好,否则为差 [6] 。类似地,对于FilmTrust数据集,如果用户对其评分为7分或更高,则认为项目良好,否则为差。
此外,我们使用覆盖度来衡量推荐系统可以推荐多少项目。我们随机选择每个用户的20%评级作为测试集,并使用剩余的80%作为训练集。我们将训练集进一步细分为测试集和用于测量参数灵敏度的训练集。为了学习参数,我们通过随机选择在80%的训练集上进行5重交叉验证,每次随机选择不同的测试和训练集合,并取结果的平均值。
我们将我们的算法与几种不同的算法进行比较:使用皮尔逊相似性的基于用户的协同过滤,基于项目的协同过滤使用修正的余弦相似度,朴素贝叶斯分类方法使用项目特征信息,用于生成推荐的朴素混合方法,用于进行概率推荐的个性诊断算法 [7] 。此外,我们调整了所有算法的参数。
4.3. 正选择邻居大小的最优值(k)
我们将活动用户的邻居数目从0改到100,并计算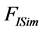 ,
, ,
, 的相应MAE。结果如图1所示:
的相应MAE。结果如图1所示:

Figure 1. Determining the optimal value of neighbourhood size
图1. 确定邻域大小的最优值k
图1表示对于MovieLens数据集的MAE对于k = 20是最小的。所以对于进一步的实验,我们选择邻域大小为20。
4.4. 学习参数的最优值(α, β, γ)
通过产生参数值的所有可能组合产生36个参数集,范围从0.1到1.0,差值为0.1。表2给出了所学习的参数集的样本。参数设置α = 0.5,β = 0.3,γ = 0.2,α = 0.7,β = 0.2,γ = 0.1分别在MovieLens和FilmTrust数据集下给出最低的MAE。值得注意的是,组合相似性在很大程度上取决于特征相似性,即α。此外,对于MovieLens和FilmTrust数据集,参数的值是不同的,这是由于这两个数据集具有不同的密度,评分分布和评级量表。
4.5. 改进的算法与其他算法的比较
1) MAE方面的性能评估:图2显示我们的算法明显优于其他算法。对于FilmTrust数据集我们观察到类似的结果。我们可以从项目集合的结果中得出结论,应用 ,
, ,
, 后对推荐结果具有互补的作用。
后对推荐结果具有互补的作用。
2) MAE,ROC灵敏度,覆盖率与其他算法的在线成本的比较:表3显示了在线成本(在最坏情况下)每个算法具有的最低MAE和覆盖率。这里,P是针对训练示例的特征的数量(即针对电影的特征)。值得注意的是,对于FilmTrust数据集,与MovieLens数据集相比,对于所有算法,ROC灵敏度更高。我们认为这是由于评分分布的原因。此外在FilmTrust数据集下,算法的覆盖率低得多,这是由于其非常稀疏(99%)的原因 [8] 。该表描述了BoostedDemoFeature是可扩展和实用的,因为其在线成本小于或等于其他算法的成本 [9] 。
3) 新项目和新用户冷启动问题下的性能评估:当将新项目添加到系统时,则不可能从用户获得该项目的评分数据,因此协同过滤推荐系统不会推荐该项目。这个问题被称为新项目冷启动问题。为了在这种情况下测试我们的算法,我们选择1000个来自测试集的用户/项目对的随机样本 [10] 。在对目标项目进行预测时,训练集中已经对目标项目进行评分的用户的数量被保持为1,2和5。在表4中,对应的MAE由MAE1,MAE2,MAE5表示。表4表明,所提出的方案在新项目冷启动中表现良好。
Table 2. A sample of parameter set with k = 20
表2. k = 20的参数集样本
Table 3. A comparison of the proposed algorithm
表3. 各种算法成本,精度,覆盖率比较
Table 4. Performance evaluation under new item cold-start problem
表4. 冷启动下的性能评估

Figure 2. MAE of the proposed algorithm with others, against various neighbourhood sizes
图2. 不同邻域下改进算法与其他算法的MAE对比

Figure 3. Performance of algorithms under different sparsity levels
图3. 不同稀疏水平下的算法性能
对于新用户冷启动问题,其中用户的信息不完整,我们使用线性回归模型来找到一个项目的活动用户的评分的近似值 [11] 。我们使用的是此评分,而不是公式(5)中的活跃用户的实际评分预测生成的评分。
 (6)
(6)
在(6)中,J的选择来自训练集,发现MovieLens为10,FilmTrust数据集为5。评分 通过线性回归模型:
通过线性回归模型: ,其中
,其中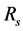 ,
, 是目标项目的向量和相似项目的向量。参数
是目标项目的向量和相似项目的向量。参数 和
和 可以通过两个相似矢量找到。这个模型用于克服基于项目的协同过滤中项目之间的误差。我们使用这种模型只有当我们有不完整的用户参数时才有意义。
可以通过两个相似矢量找到。这个模型用于克服基于项目的协同过滤中项目之间的误差。我们使用这种模型只有当我们有不完整的用户参数时才有意义。
4) 不同稀疏性下的性能评价:为了检查稀疏性的影响,我们通过丢弃一些随机选择的条目来增加训练集的稀疏度。但是我们保持每个稀疏训练集的相同的测试集。我们检查了提出的算法的性能与以纯用户为基础的协同过滤,基于项目的协同过滤和一个朴素的混合推荐算法。图3表示在所提出的不同算法的情况下,性能不会快速降低。这是因为项目的特征仍然可以用于找到类似的项目。此外,同义词检测算法了丰富项目特征,同时也可以找到项目之间的相似性。
5. 结束语
在本文中,我们提出了一个独特的层叠混合推荐方法,使用评级数据,人口统计数据和特征数据相结合的方法来计算项目之间的相似度。实验表明我们的方法优于传统的推荐算法。