1. 引言
随着科学技术的发展,混凝土越来越广泛地应用到各个工程建设中,并且根据使用功效的差别,可以配置不同类型的混凝土。然而随着掺合料、粗骨料、细骨料等比例的变化,混凝土的抗压强度也受到极大的影响 [1] [2] [3] [4] 。混凝土的抗压性能是设计混凝土配合比的一个重要参考指标,然而配合比与抗压性能之间并不是简单的线性关系,而是极其复杂的非线性关系。近年来,为了更快地预测某种配合比混凝土的抗压强度,许多试验和研究方法被开发出来。机器学习的各种方法也被用来预测各种类型混凝土的强度,例如神经网络 [5] ,支持向量机 [6] ,高斯过程 [7] ,相关向量机 [8] 等。本文使用一组实际数据,建立各种机器学习方法的混凝土抗压强度的预测模型,并通过交叉验证的方法来验证各种机器学习方法的可靠性。
2. 实验数据
本文研究的数据来源于台湾重华大学信息管理系的叶怡成教授,数据下载地址为, http://archive.ics.uci.edu/ml/datasets/Concrete+Compressive+Strength。该数据总观测值为1030个,没有任何缺失数据,其中共有9个分量,可细分为输入变量8个,分别为:水泥,矿渣,粉煤灰,水,超减水剂,粗骨料,细骨料和养护龄期;输出变量1个,混凝土抗压强度。该数据是没有经过放缩处理的原始数据,表1中列出了数据的最大值和最小值。
通过对数据的初步了解,可以看出,这些数据可以把混凝土的抗压强度作为因变量,其他变量作为自变量,建立一定的回归模型,并做出相应的预测。然而该数据过于复杂,传统的方法并不能获得一个较好的结果,于是考虑使用机器学习的方法。
3. 机器学习
机器学习是计算机科学的子领域,它使计算机能够在没有明确编程的情况下学习 [9] 。不同于传统方法的模型驱动,机器学习是数据驱动,它探索构建了从数据中学习并对数据进行预测的算法 [10] 。
传统的统计模型大多对数据的具体分布有一定的要求或者是假定,然而在现实中,真实的数据可能不满足那些假定或要求,这个时候再用传统的方法,它们的某些优良的性质将不可能得到,甚至某些结论都是错误的。这个时候选择机器学习的方法会比较合理,机器学习法不需要对数据分布做任何假定,并且产生的结果也可以用交叉验证的方法来进行评价。
3.1. 决策树回归
决策树分类是通过一定的规则对数据样本进行分类的过程,当数据结构为连续形变量时,称为决策树回归 [11] 。该方法模型是将数据样本不断地进行划分,根据不同的条件,数据将划分到不同的分支结构下面,并且这种分支结构能够保证数据对这一条件依赖的差别达到最大,从而最后将所有数据划分到各种不同的分支下 [12] 。这样得出的每一次划分,得出的偏差比其他划分方法都小,从而对于全部划分,能够保证最小偏差。使用R软件的程序包 进行决策树回归,得出的决策树如图1。
进行决策树回归,得出的决策树如图1。
3.2. Boosting回归
Kearns和Valiant提出了强学习器和弱学习器的概念,并且证明出两者可以等价,即弱学习器可以提升为强学习器,这就是Boosting算法的由来 [13] 。后来,Boosting算法被用于回归分析,以训练误差较大的回归算法做弱学习器,通过Boosting算法将误差较大的回归算法,如决策树回归,当作弱学习器,从而构造出训练误差较小的强学习器。通过弱学习器提升为强学习器的方法各有不同,从而有各种不同的Boosting方法。本文采用的是基于模型的Boosting算法,并且弱学习器选择决策树回归。在R软件中可以使用程序包 进行Boosting回归。
3.3. 随机森林
随机森林由Breiman提出,是决策树的一种组合方法 [14] 。该方法的基本原理是 [15] :
1) 将所有观测值当作bootstrap抽样的样本,并且得出一组抽样样本;
2) 随机选择抽样样本的部分数据建立决策树,并且对数据随机划分;
3) 重复1)和2)过程m次,获得m个决策树,构成随机森林模型;
4) 数据预测时,每个决策树对因变量进行预测,得出m个预测值,最后取出现次数最多的数值作为该因变量的预测值。
该方法的优点在于随机性的引入增强了抗噪声的能力,并且能够有效地避免过拟合的情况,对复杂的数据有较强的适应能力。在R软件中可以使用程序包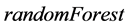 进行随机森林回归。
进行随机森林回归。
3.4. 人工神经网络回归
人工神经网络是由大量的节点构成,其相关原理是,将上层节点的值加权后传递给下一层,依次传递到最终输出节点,再根据输出节点的误差大小情况给前面节点层一个激励或者抑制的信号,从而改变权重,最后经过反复传递,达到输出误差在某个范围内。某一节点的加权过程可以表示为 [16]

其中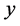 表示该节点层的输出值,
表示该节点层的输出值, 为激活函数(activation function),
为激活函数(activation function), 、
、 和
和 分别代表该节点层第
分别代表该节点层第 个节点的权重、值和阈值。使用R软件的程序包
个节点的权重、值和阈值。使用R软件的程序包 进行人工神经网络回归,权值衰弱选取(0.1, 0.5),隐藏节点取(4, 5, 6),经过6次试验,选取样本内的预测相对误差值最小的方案,权值衰弱取0.5,隐藏层节点个数为4。
进行人工神经网络回归,权值衰弱选取(0.1, 0.5),隐藏节点取(4, 5, 6),经过6次试验,选取样本内的预测相对误差值最小的方案,权值衰弱取0.5,隐藏层节点个数为4。
3.5. 支持向量机回归
在一般的线性回归问题中,假设拟合函数为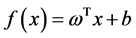 ,支持向量机的目的是最小化
,支持向量机的目的是最小化 ,使得
,使得
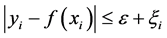
其中, 表示误差,
表示误差, 是对误差的惩罚,
是对误差的惩罚, 和
和 指松弛因子。该二次规划问题可以转化为其对偶问题,
指松弛因子。该二次规划问题可以转化为其对偶问题,

在非线性问题中,支持向量机的基本思想是应用非线性映射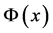 ,将数据样本
,将数据样本 投影到某个高维的特征空间,然后在该特征空间内进行线性回归,最后将结果返回到原始空间 [17] ,公式如下:
投影到某个高维的特征空间,然后在该特征空间内进行线性回归,最后将结果返回到原始空间 [17] ,公式如下:

Table 2. Results of cross validation error
表2. 交叉验证误差结果

其中,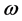 和
和 分别表示权重和阈值。
分别表示权重和阈值。
在高维特征空间中数据样本的内积运算 较为复杂,因此考虑使用核函数
较为复杂,因此考虑使用核函数 近似,核函数能够使得向量在映射前后的内积相等,核函数可以选多项式函数,径向基函数以及Sigmoid函数等 [18] [19] 。在R软件中可以使用程序包
近似,核函数能够使得向量在映射前后的内积相等,核函数可以选多项式函数,径向基函数以及Sigmoid函数等 [18] [19] 。在R软件中可以使用程序包 进行支持向量机回归,该程序包使用的是径向基函数。
进行支持向量机回归,该程序包使用的是径向基函数。
4. 交叉验证
交叉验证,是一种的统计学方法,先将样本数据分割成n份,依次取出一份作为测试集,剩余部分作为训练集,用机器学习方法建立模型后,将测试集带入模型,从而得出预测值的相对误差,依次进行n次以后,可以得出n个预测误差,取其均值作为该方法的交叉验证的误差,最后通过比较误差来判断各种建模方法的可靠性。本文中对所有机器学习方法采用的都是10折交叉验证(10-fold cross validation),使用R软件随机将数据分成10份,并且后面的计算全部使用这些已经分好的集合。
本文总共使用了决策树、Boosting、随机森林、人工神经网络、支持向量机这五种方法来对该混凝土的抗压强度数据进行回归分析,并且对这五种方法都进行了十折交叉验证,通过对比十折交叉验证的结果,可以看出五种方法对混凝土抗压强度预测的可靠性。接下来看看机器学习法得出预测值的相对误差的均值、最小值和最大值,的结果如表2所示。
可以看出使用随机森林回归得出的十折交叉验证的误差均值最小为0.145,因此可以考虑使用随机森林建立抗压强度的模型。
5. 结论
影响混凝土抗压强度的因素跟多,为了建模具有复杂结构的数据,引入机器学习的方法。通过各种主流的机器学习方法对一组实际数据建立相关模型,随后使用交叉验证的方法,检测各种机器学习方法的可靠性,发现误差均值最小的为随机森林法。