1. 引言
通过结合成像技术和光谱技术,高光谱遥感可以同时获得空间和光谱连续的数据。光谱数据在检测地球表面中是一种有效的工具,被广泛用于农业,矿物学,对地观测,物理学,天文学,化学成像和环境科学中 [1] 。这些应用中的常用技术是对高光谱图像中每个像素进行分类。但是,高光谱图像的高数据维与不断提高的空间分辨率给传统的分类任务提出了新的挑战,提高高光谱图像的分类精度一直是遥感领域的研究热点。
限制高光谱图像分类精度的主要原因有两个:第一,与传统的图像分类问题 [2] 相比,高光谱图像的分类问题具有数据空间维数高,训练样本难以获得的特点,即所谓的“维数灾难” [3] ,这使得传统的在低维空间中表现良好的分类方法在高光谱图像分类问题上表现的不尽如人意。传统的解决维数灾难的方法是对高光谱数据进行降维处理后再分类 [4] [5] [6] ,但传统的线性特征提取方法,如PCA、ICA,NFWE等,在降维的过程中舍弃了高光谱图像中光谱维上的细节信息,降维后的图像与多光谱无异,因而失去了“高光谱”的意义。第二,传统的方法把高光谱图像中的像元作为独立的光谱曲线进行分类,忽视了图像中的空间信息 [6] 。为了利用图像中的空间信息,已有的文献从图像中提取纹理特征,结构特征,形态学特征等空间特征作为光谱特征的补充 [6] [7] [8] 。但是各种的空间特征的抽取都需要人员的干预甚至设计,最终的分类效果与特征的好坏具备直接的关系,导致分类的准确率很大的依赖于人的经验,可能某一种空间特征在某一数据集上表现良好但是在其他数据集上结果却完全相反。
综上可知,高光谱图像分类问题在降维和空间特征提取两方面均有改进的空间,因此,本文提出了一种基于深度学习的高光谱图像分类方法,针对已有的分类方法中的缺陷,关注了深度学习中的两种常见模型——自动编码网络和卷积神经网络。自编码网络 [9] 可以实现非监督的提取数据的特征,恰当设置非线性激活函数即可有效提取得到数据的非线性特征。卷积神经网络 [10] [11] 作为一种成功的视觉模型,已经在图像分类 [2] ,人脸识别 [12] ,目标检测 [13] 等领域取得了巨大的成功,被证明能够自动从图像中有效的提取对分类结果有益的特征 [14] ,避免了人工设计并抽取特征的过程。本文的分类算法流程图如图1所示。首先利用堆叠自动编码机对高光谱数据进行光谱维上的降维,然后将卷积神经网络作为分类器,将以待分类像元为中心的矩形内的高光谱数据立方体作为卷积神经网络的输入,进行空谱联合分类,获得最终的分类结果。
2. 基于堆叠自编码网络的高光谱数据降维
自动编码网络由其基本单位——自动编码机堆叠而成。自动编码机是一个三层前馈神经网络,由输入层,隐藏层,重构层构成。自动编码机的编码及解码过程如公式 [15] (1) (2):
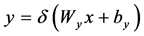 (1)
(1)
 (2)
(2)
式中,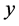 是原始数据的特征表达,
是原始数据的特征表达,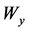 ,
,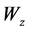 ,
,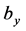 ,
,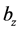 分别为输入层到隐藏层,隐藏层到重构层的权重及偏移系数,一般取
分别为输入层到隐藏层,隐藏层到重构层的权重及偏移系数,一般取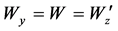 ,
, 为非线性映射函数,一般取为sigmoid函数,即:
为非线性映射函数,一般取为sigmoid函数,即:
 (3)
(3)
通过调节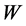 ,
,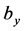 ,
,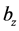 使得输入
使得输入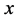 和重构
和重构 之间相似。一般采用交叉熵函数衡量
之间相似。一般采用交叉熵函数衡量 和
和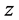 之间的距离,训练时采用分批训练,每一批的样本数为
之间的距离,训练时采用分批训练,每一批的样本数为 ,则损失函数为:
,则损失函数为:
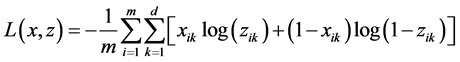 (4)
(4)
公式(4)中,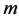 是每一批训练样本的个数,
是每一批训练样本的个数, 是输入层与重构层的维数。
是输入层与重构层的维数。
使用随机梯度下降训练网络参数,参数的更新规则为(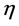 代表学习率):
代表学习率):
 (5)
(5)
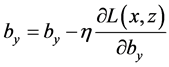 (6)
(6)
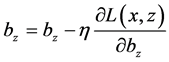 (7)
(7)
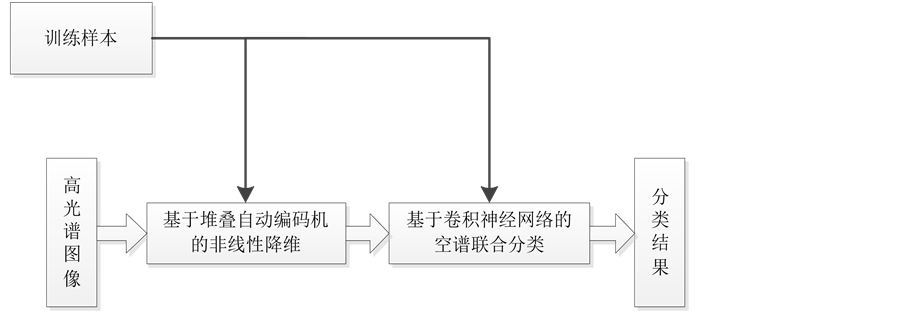
Figure 1. The flowchart of the proposed algorithm
图1. 本文分类流程
自动编码网络由若干个自动编码机层叠而成,上一层自动编码机隐藏层的输出作为下一层自动编码机的输出层的输入。其训练共分为三个阶段 [15] ,共包括预训练,展开和微调3个步骤:
步骤1 预训练过程。逐层训练组成自动编码网络的多个自动编码机,下层自动编码机隐藏层单元输出作为其上层自动编码机的输入参与训练。
步骤2 展开过程。预训练完成后,下层AE输出单元与其上层AE合并为一层,将多个AE连接成一个自动编码深度网络。
步骤3 微调过程。展开的自动编码网络采用反向传播算法对预训练得到的初始权值进一步调整,进一步减少误差。
3. 基于卷积神经网络的空谱联合分类
卷积神经网络由卷积层,池化层,全连接层和softmax分类层组成 [15] 。一般地,在卷积层中对网络的输入或者前一个隐藏层的输出进行卷积操作生成特征图,卷积操作生成的每一张特征图都会与偏置项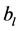 相加,随后非线性激活函数会作用在特征图中的每一个像素上。接下来,池化层会以非重叠的方式从每一个特征图中选取局部的主特征,也就是对特征图进行降维操作。整个过程可以用公式 [16] 表示为:
相加,随后非线性激活函数会作用在特征图中的每一个像素上。接下来,池化层会以非重叠的方式从每一个特征图中选取局部的主特征,也就是对特征图进行降维操作。整个过程可以用公式 [16] 表示为:
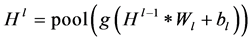 (8)
(8)
式中,*代表卷积操作,pool代表最大化池操作。
数个卷积层和池化层交替重叠能够从输入中逐层的提取特征。之后,提取的特征在拉伸成为一个向量后送入全连接层。在全连接层,首先通过与权重矩阵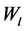 相乘和偏置
相乘和偏置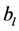 相加进行线性变换,然后将非线性函数作用在变换后的每一个分量上,有:
相加进行线性变换,然后将非线性函数作用在变换后的每一个分量上,有:
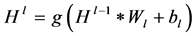 (9)
(9)
激活函数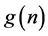 取公式(3)中的sigmoid函数。全连接层的输出被送至softmax层进行分类。卷积神经网络中的参数为权重矩阵
取公式(3)中的sigmoid函数。全连接层的输出被送至softmax层进行分类。卷积神经网络中的参数为权重矩阵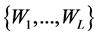 以及偏置
以及偏置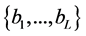 。网络通过反向传播算法进行训练,损失函数为:
。网络通过反向传播算法进行训练,损失函数为:
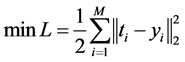 (10)
(10)
通过使用随机梯度下降 [11] 算法获得最优的参数值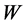 和
和 。
。
为了对降维后的高光谱数据进行空谱联合的分类,本文设计了如图2所示的卷积神经网络结构。取以待分类像元为中心的矩形内的数据立方体作为卷积神经网络的输入,取矩形的大小为 ,则网络输入的尺寸为
,则网络输入的尺寸为 ,其中
,其中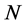 是高光谱图像降维后的光谱维度。与一般的图像分类方法,如人脸识别相比,本文分类任务的空间维度并不高,因此本文的卷积神经网络中不包含池化层的空间降维操作。卷积神经网络由三个卷积层,一个全连接层和一个softmax分类层组成。每个卷积层的卷积核大小为
是高光谱图像降维后的光谱维度。与一般的图像分类方法,如人脸识别相比,本文分类任务的空间维度并不高,因此本文的卷积神经网络中不包含池化层的空间降维操作。卷积神经网络由三个卷积层,一个全连接层和一个softmax分类层组成。每个卷积层的卷积核大小为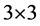 ,卷积核的个数为
,卷积核的个数为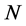 ,全连接层的输入维数均为
,全连接层的输入维数均为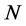 ,输出维数为30,softmax分类层的输入个数为
,输出维数为30,softmax分类层的输入个数为 ,输出个数为高光谱图像中的地物种类数。
,输出个数为高光谱图像中的地物种类数。
4. 实验和分析
4.1. 实验数据集描述
本实验使用两组高光谱数据集检验本文算法的分类性能,分别是IndianPines数据集和University of Pavia数据集。前者为AVIRIS采集的农业区高光谱图像,图像大小为145像素 × 145像素,共包含220个波段,去掉其中的20个水吸收严重的波段,得到包含200个波段的高光谱数据。后者为ROSIS采集

Figure 2. The structure of convolution natural network for hyperspectral classification
图2. 用于高光谱图像分类的卷积神经网络结构
的城区高光谱图像,图像大小为610像素 × 340像素,共包含115个波段,去除其中水吸收严重的12个波段,将其余103个波段作为高光谱数据。Indian Pines数据以及University of Pavia数据的假彩色图及标记模板如图3(a)、图3(b)和图4(a)、图4(b)所示。
4.2. 实验结果与讨论
4.2.1
. Indian Pines数据集
为了证实本文的算法确实有效,将本文的算法与以下分类算法进行对比:
1) PCA-SVM [9] :利用主成分分析对高光谱图像进行降维,然后采用SVM方法进行分类。
2) Autoencoder-SVM [15] :利用自编码网络对高光谱进行降维,然后使用SVM分类器进行分类,此结果用于证明Autoencoder在降维方面的优越性。
3) PCA-MOR-SVM [9] :利用主成分分析对高光谱数据进行降维,然后对前3个主成分提取形态学特征作为光谱特征的补充 [1] ,接下来采用SVM分类器进行分类
4) PCA-CNN:利用主成分分析对高光谱数据降维,然后使用本文提出的卷积神经网络进行分类。
PCA和Autoencoder在降维方面各有优势,PCA能够用较少的维数表示原始数据中的大部分信息,而SAE则能够更好的保留数据的特征。本文的堆叠自动编码机的结构参照文献 [14] 设置,经过堆栈自动编码机降维后的数据维数为40,自动编码机具有4层结构,每一层的节点数为200-40-40-40。在1)中同样取前40个主成分进行分类;在2)中利用SAE降维后的维数为40,并且使用SVM进行分类;在3)中

Figure 3. The result of classification of Indian Pines. (a) Pseudocolor image; (b) Ground truth map; (c) PCA-SVM: 80.47%; (d) Autoencoder-SVM: 85.48%; (e) PCA-MOR-SVM: 91.13%; (f) PCA-CNN: 95.27%; (g) Autoencoder-CNN: 98.64%
图3. Indian Pines数据集分类结果。(a) 假彩色图像;(b) 分类参考图;(c) PCA-SVM: 80.47%;(d) Autoencoder-SVM: 85.48%;(e) PCA-MOR-SVM: 91.13%;(f) PCA-CNN: 95.27%;(g) Autoencoder-CNN: 98.64%
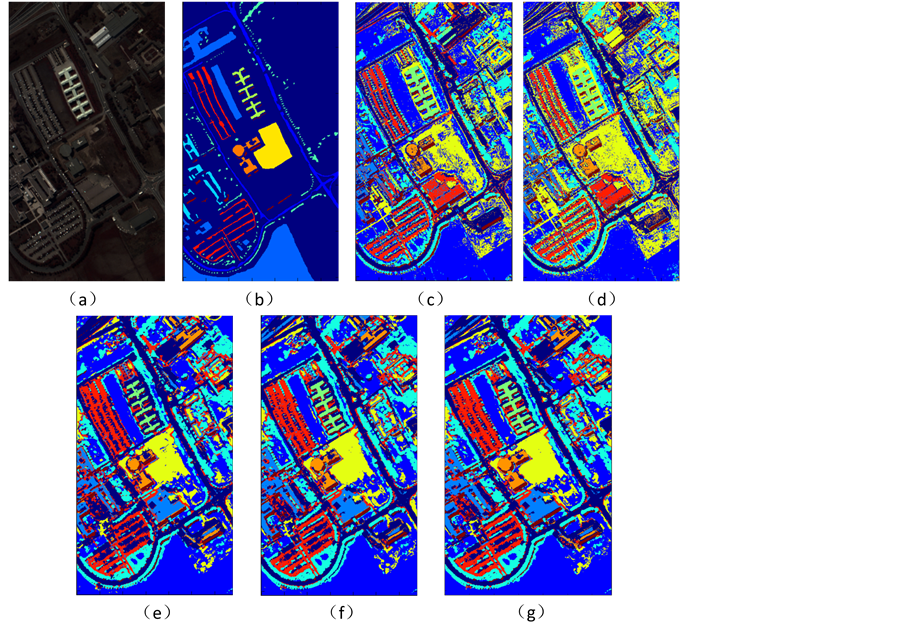
Figure 4. The classification result of University of Pavia. (a) Pseudocolor image; (b) Ground truth map; (c) SVM: 80.01%; (d) Autoencoder-SVM: 94.14%; (e) PCA-MOR-SVM: 98.16%; (f) PCA-CNN: 98.56%; (g) Autoencoder-CNN: 99.26%
图4. Indian Pines数据集分类结果。(a) 假彩色图像;(b) 分类参考图;(c) SVM: 80.01%;(d) Autoencoder-SVM: 94.14%;(e) PCA-MOR-SVM: 98.16%;(f) PCA-CNN: 98.56%;(g) Autoencoder-CNN: 99.26%
同样取前40个主成分进行分类,并且依据文献建立半径为2的圆形结构元素,对前3个主成分进行四次开闭运算,得到的形态学特征作为光谱特征的补充;在4)取PCA降维后的前40个主成分,并使用本文提出的CNN进行空谱联合分类。表1给出了图像详细的训练训练集的个数,测试集的个数以及分类数量。图3中为一次实验的结果图,图5是每一种地物的分类情况。从视觉角度看,仅利用光谱信息的分类对噪声比较敏感,分类结果中含有许多许多细小斑点,而综合利用光谱与空间信息的方法则能够获得比较完整的地物区域。
4.2.2. University of Pavia数据集
为了进一步证明本文的算法确实有效,使用同样的方法对University of Pavia数据集进行分类。PCA降维方式同样保留前40个主成分,Autoencoder的结构为103-40-40-40,即使用深度为4的自动编码网络进行降维处理,降维后的光谱维度为40。Pavia大学数据集的类别数量以及训练和测试样本数量如表2所示,图4为分类的结果,图6为每一类地物分类的精度。从Pavia大学数据的分类结果可以得到与
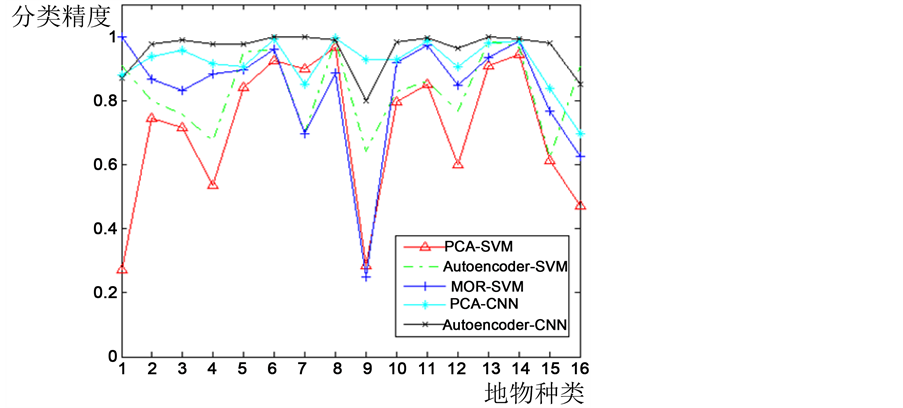
Figure 5. Classification accuracy of Indian Pines data
图5. Indian Pines数据分类精度
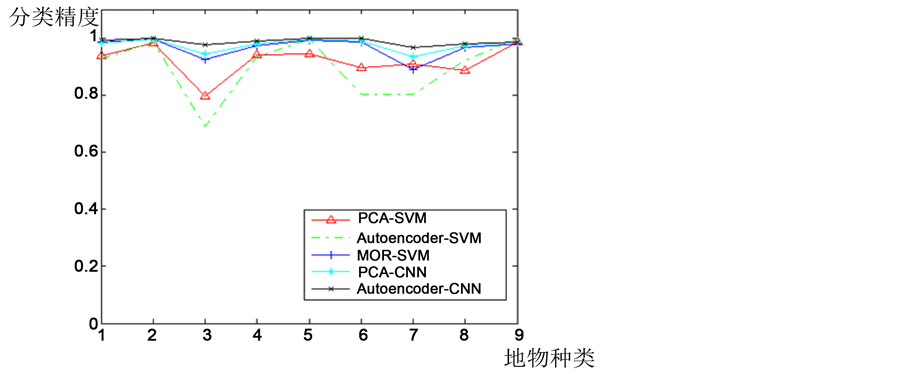
Figure 6. Classification accuracy of Pavia University data
图6. Pavia University数据分类精度

Table 1. Class labels and train-test distribution of samples for the Indian Pines datasets
表1. Indian Pines高光谱影像的类别和样本数
Table 2. Class labels and train-test distribution of samples for the University of Pavia
表2. Indian大学高光谱影像的类别和样本数
之前的类似结论,即:1) 非线性降维方式优于线性降维方式;2) 加入空间信息有利于分类精度的提升;3) 使用卷积神经网络能够自动的提取对分类有利的特征。
5. 结论
本文从限制高光谱图像分类精度的两点出发,提出了基于深度学习的高光谱图像分类方法。在降维方面,针对PCA等线性降维方式不能提取光谱维上的非线性特征这一问题,使用了自编码网络提取光谱维度的非线性信息;另外,设计了一种卷积神经网络结构,能够自动的提取对分类有利的空间特征,并在分类时能同理利用光谱信息和空间信息;从而获得比传统分类方法更精确的分类结果。