1. 引言
物流业是支撑国民经济发展的基础性、战略性、先导性产业,物流高质量发展是推动经济高质量发展不可或缺的重要力量 [1] 。进行物流需求预测可以促进行业健康发展、合理配置资源、提升综合效益,是优化物流活动的重要举措之一。
贵州省是西南地区的交通枢纽,长江经济带的重要组成部分,同时也是国家生态文明试验区、内陆开放型经济试验区。精确预测贵州省的物流需求变化,对西南地区物流业的高质量发展具有重要意义。
进行物流需求预测的方法可以分为定性方法和定量方法。定性方法包括德尔菲法、市场调查法、场景规划法等,结论多受专家意见和主观判断的影响。目前学者们进行物流需求预测时多采用定性方法,包括时间序列法、回归模型法和组合预测法等。缪辉等 [2] 建立多元线性回归模型对贵州省物流需求进行预测。欧光军等 [3] 构建了GM(1,6)模型,对湖北省物流进行预测研究。李义华等 [4] 构建了一种滑动无偏灰色模型,对湖南省未来七年的农产品冷链物流需求量进行了分析预测。王秀梅 [5] 集合了偏最小二乘法、时间序列ARIMA法和二次指数平滑法,分别预测了我国三大类农产品的冷链物流需求趋势。李思聪等 [6] 结合GM(1,1)和多元线性回归模型对我国农产品冷链物流市场进行需求预测。袁瑜等 [7] 构建了包含五种单一预测模型(Pearson相关系数法、回归分析法、弹性系数法、指数平滑法、趋势外推法)的组合预测模型,来探究国家物流枢纽的未来货运需求。
随着人工智能技术的发展,许多智能预测方法也被逐渐应用到物流需求研究中。李敏杰等 [8] 在对我国水产品冷链物流需求的实证分析中,证明了径向基(Radial Basis Function, RBF)神经网络的有效性。杨麒等 [9] 证明反向传播神经网络(Back Propagation Neural Network, BPNN)预测方法较二次指数平滑方法具有更好的拟合性能和预测精度。黄建华等 [10] 提出了改进GM-BPNN组合预测方法,提高了物流需求预测的精确度。肖红等 [11] 构建了算术优化算法(Arithmetic Optimization Algorithm, AOA)优化最小二乘支持向量机(Least Squares Support Vector Machine, LSSVM)的智能预测模型,用于对西部陆海新通道的重要枢纽城市进行物流需求分析。
以BP神经网络为代表的机器学习方法,可以捕捉物流数据中复杂的非线性关系,从而适应和学习历史数据,适合用于物流需求预测。但BP神经网络也存在一定的缺陷:对初始化值敏感度较高,易陷入局部最优。本文使用粒子群优化算法(Particle Swarm Optimization, PSO)优化BP网络的权重和偏差,为训练提供更稳健的起点,帮助BP网络更好地泛化数据,提高模型的预测精度。
2. 研究方法
2.1. BP神经网络
BP神经网络是一种基于误差反向传播的前馈型人工神经网络。在正向传播过程中,输入数据被传输到网络中,应用权重和激活函数进行计算并输出结果。在反向传播过程中,将输出结果与真实值的误差向后传播,以调整网络中的权重和偏差。BP神经网络通过迭代过程进行训练,训练数据被重复地呈现给网络,使用反向传播算法不断更新权重和偏差,直到收敛到最小误差才停止。
2.2. PSO算法
PSO算法是一种受自然启发的优化算法,其灵感来自于鸟群觅食行为。算法的基础是群体协作和信息的社会共享。优化之初,随机生成n个粒子,每个粒子都具有速度属性和位置属性,粒子的位置代表解空间中的一个解,粒子的速度代表粒子下一步迭代时移动的方向和距离。
粒子根据当前速度、当前位置、自身个体极值和种群全局极值对速度和位置进行动态更新,更新公式如下:
(1)
(2)
式中,k是迭代次数,i是粒子序号,d是粒子维度序号,ω表示惯性权重,c1表示个体学习因子,c2表示群体学习因子,r1和r2是区间[0,1]内的随机数,
是粒子i在第k次迭代中第d维的速度向量,
是粒子i在第k次迭代中第d维的位置向量,
是粒子i在第k次迭代中第d维的历史最优位置,
是群体在第k次迭代中第d维的最优位置。
2.3. PSO-BP预测模型
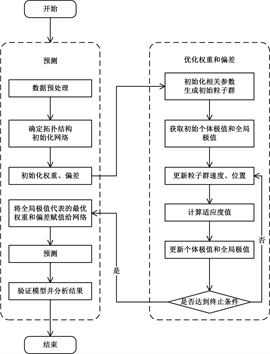
Figure 1. Process of PSO-BP prediction model
图1. PSO-BP预测模型流程
尽管BP神经网络能有效应用于各种机器学习任务,但它也有一些缺点和局限性:对初始化值敏感度较高;易陷入局部最优;当网络复杂或数据集过小时易出现过拟合等。
使用PSO算法优化BP神经网络的权重和偏差可以有效弥补单一BP网络的不足:PSO是一种全局优化算法,擅长于找到复杂非凸目标函数的全局最优值,有助于避免BP网络陷入局部最优,从而提高网络性能;PSO可以快速调整BP网络的权重和偏差,加快学习过程,降低停滞风险;PSO对初始化敏感度较低,可以为训练提供了更稳健的起点;能够帮助BP更好地泛化数据,降低过拟合风险。
本文组建新的PSO-BP预测模型,通过优化BP神经网络的权重和偏差,使网络训练具有更高的预测精度和更快的响应速度。PSO-BP预测模型的流程如图1。
3. 数据来源与处理
3.1. 指标体系构建
贵州省物流需求指标体系如表1所示,包含区域经济水平、交通运输能力和居民消费能力三大指标。区域经济水平包括第一产业增加值X1、第二产业增加值X2、第三产业增加值X3、交通运输、仓储和邮政业增加值X4、社会消费品零售总额X5。交通运输能力包括货物周转量X6、铁路营业里程X7、公路通车里程X8、第三产业从业人员X9、载货汽车数X10。居民消费能力包括农村居民人均可支配收入X11、城镇居民人均可支配收入X12。选取货运量Y (万吨)近似代替物流需求进行预测。

Table 1. Logistics demand indicator system in Guizhou Province
表1. 贵州省物流需求指标体系
3.2. 数据来源
数据来源于2001~2021年《贵州省统计年鉴》,2001~2021年贵州省的物流需求历史数据如表2所示。
Table 2. Historical data of logistics demand in Guizhou Province from 2001 to 2021
表2. 2001~2021年贵州省物流需求历史数据
续表
3.3. 灰色关联度分析
灰色关联度分析(Grey Relational Analysis)是一种多变量关联度分析方法,用于研究不同因素之间的关联程度,特别适用于处理非确定性和不完整信息的情况。灰色关联度分析的主要思想是通过将不同因素之间的数据序列进行比较和关联,以揭示它们之间的联系,包括以下步骤:
(1) 确立参考项和比较项。在分析中,选择一个作为参考项的变量,将这个参考项的值与其他变量的值进行比较。本文选择货运量Y作为参考项,第一产业增加值X1、第二产业增加值X2、第三产业增加值X3、交通运输、仓储和邮政业增加值X4、社会消费品零售总额X5、货物周转量X6、铁路营业里程X7、公路通车里程X8、第三产业从业人员X9、载货汽车数X10、农村居民人均可支配收入X11、城镇居民人均可支配收入X12作为比较项。
(2) 数据标准化。首先,采用均值化方法对不同变量的数据进行标准化处理,以消除不同单位和量纲的影响。计算公式为:
(3)
式中,
表示变量i第k年的无量纲值,
表示变量i第k年的实际值,
表示变量i的平均值。
2001~2021年贵州省物流需求无量纲化数据见表3。
Table 3. Non dimensional data of logistics demand in Guizhou Province from 2001 to 2021
表3. 2001~2021年贵州省物流需求无量纲数据
(3) 计算差值。对无量纲化后的数据进行求差,计算公式如下:
(4)
式中,
为变量i第k年的无量纲值与货运量Y第k年的无量纲值作差的绝对值,
表示变量i第k年的无量纲值,
表示Y第k年的无量纲值。
(4) 计算关联度。根据无量纲数据,使用灰色关联度函数,计算参考项与比较项之间的关联度值。计算公式如下:
(5)
式中,ri为变量i与货运量Y的灰色关联度值,n为总年数,ρ为分辨系数。
货运量Y与其他变量的灰色关联度值见表4。
Table 4. Grey correlation values between freight volume Y and other variables
表4. 货运量Y与其他变量的灰色关联度值
灰色关联度值的大小表示了两个数据序列之间的相关程度,值越大,关联度越强。货运量Y与其他指标的关联度值均在0.6以上,说明所选指标均与货运量Y有相似的变化趋势或影响因素,存在较强的关联关系。
4. 物流需求预测
4.1. 网络结构设置
网络结构是影响神经网络数据学习能力的重要因素,确定网络结构是各种机器学习任务的关键步骤。BP神经网络通常由输入层、隐藏层和输出层组成。输入层和输出层的大小应该与数据的维度相匹配,根据选取的指标可知输入层的节点个数为12,输出层的节点个数为1。根据问题的复杂程度,本文使用一层隐藏层来构建神经网络模型。可以通过经验公式确定隐藏层节点个数的范围:
(6)
式中k代表隐藏层节点个数,n代表输入层节点个数,m代表输出层节点个数,a取0~10之间的常数。经过多次试验确定,k取8。
BP神经网络的目标误差取10−6,学习率取0.01。
4.2. PSO-BP模型与BP模型的比较
为评价PSO算法对BP网络的优化效果,将PSO-BP模型的预测结果和BP模型的预测结果进行比较,见图2。
根据表5可知,在对贵州省2017~2021年物流需求的预测过程中,PSO-BP模型预测结果的相对误差均小于BP模型,说明通过PSO算法优化BP网络的权重和偏差可以提高预测精度。
选取均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)作为模型性能的评价标准。RMSE、MAPE和MAE的值越小,说明预测偏差越小,预测效果越好。
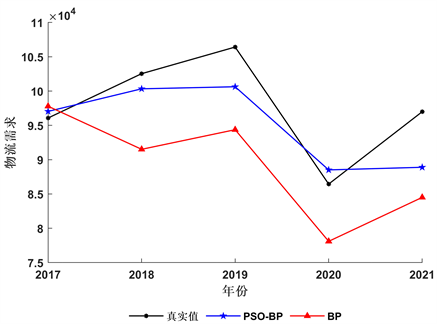
Figure 2. Prediction results of two models
图2. 两种模型的预测结果图
Table 5. Comparison of prediction results between two models
表5. 两种模型的预测结果对比
Table 6. Comparison of evaluation indicators between two models
表6. 两种模型的评价指标对比
根据表6可知,PSO-BP模型的RMSE、MAE和MAPE较BP模型分别降低了53.0%、58.1%和58.3%,说明PSO-BP模型的预测性能优于BP模型。这是由于PSO算法降低了网络初始权重和偏差对BP的影响,提升了BP模型的预测性能。
4.3. 未来三年物流需求预测
使用PSO-BP模型进行未来三年的物流需求预测时,需要输入12个二级指标未来三年的预测值。灰色预测方法利用微分方程的解来逼近时间累加后形成的新时间序列所呈现的规律,建模所需信息少,运算简便且精度较高,自提出以来就被广泛应用于数据量小、数据完整性较低的序列预测问题,其中最典型的是GM(1,1)模型。
因指标的历史数据量较少,本文使用GM(1,1)模型预测12个二级指标未来三年的数据,将得到的指标预测值作为PSO-BP模型的输入。首先对12个指标的时间序列进行级比检验,平移转换后序列的所有级比值都位于区间
内,说明平移转换后序列适合构建灰色预测模型。然后构建灰色预测模型,得到后验差比C值,12个指标的C值均小于0.2,说明模型预测精度较高。使用GM(1,1)模型所得的指标预测值见表7。将表7的指标预测值代入训练好的PSO-BP模型,得到2022~2024年贵州省物流需求的预测值,见表8。
Table 7. Predicted values of indicators
表7. 指标预测值
Table 8. Predicted logistics demand in Guizhou Province from 2022 to 2024
表8. 2022~2024年贵州省物流需求预测值
5. 结论
本文选取了12个指标构建贵州省物流需求指标体系,通过灰色关联分析证明了指标选取的合理性。运用PSO算法优化BP网络的权重和偏差,建立了PSO-BP预测模型。在对贵州省2001~2021年物流需求数据的实证分析中,比较PSO-BP模型和单一BP模型的预测效果,发现PSO-BP模型的预测效果和性能更佳。最后,运用GM(1,1)模型获得了12个指标未来三年的预测值,将其代入训练好的PSO-BP模型获得了贵州省未来三年的物流需求量。结果表明,贵州省物流需求量在未来三年呈持续增长态势。
参考文献