1. 引言
由于传统线下零售商超的数字化、信息化能力不足,因此ERP系统中的存在大量的沉睡数据。如何科学合理的刺激市场经济,满足市场需求,增强经济增长的内生动力,为市场主体的发展营造更好的环境,是企业的重要战略。为了应对多变的市场变化,制定合理的零售策略,我们将通过对客流量进行预测分析 [1] ,并充分考虑老旧ERP系统不稳定因素的影响,除了采用常用的均值、去除空值等方式来对数据的异常值进行预处理外 [2] ,我们还使用Arima时间预测模型对实验数据进行异常值补全,最后利用、SArima模型、Holt-Winters模型进行客流量的预测。本文旨在研究多种数据补全策略对商超客流量预测的影响。Arima模型时常用的时间预测模型,可以用作短期数据补全。SArima模型和Holt-Winters模型是时间序列中常用的预测模型 [3] [4] 。对客流量的预测具有一定的应用研究价值。本研究提出了基于多种数据补全策略特征工程的SArima模型和Holt-Winters模型,并利用2021年2月至2021年4月某商超线下实际客流量进行了模型训练和预测,来预测多种数据补全策略对商超客流量的影响 [5] 。同时我们还进行了对比研究与误差分析,以评估模型的准确性和实用性。
总体而言,本文的研究为预测商超购物客流量提供了有效的理论依据与可行的方法。通过使用多种数据补全策略对数据进行预处理;引入不同的模型,使我们能够更加精准的预测商超客流量,为企业的下一步规划,提供了强有力的理论依据,让数据发声,用数据说话。该研究对于零售行业的销售预测、运营策略、销售营销都具有一定的理论和实践意义。
2. 文献综述
客流量预测是零售企业管理的重要内容 [6] ,它可以帮助提高顾客消费转化效率,优化资源配置等 [7] 。客流量预测的方法有很多,其中一种常用的方法是基于时间序列的分析 [8] 。时间序列是指按照时间顺序排列的数据序列,它反映了数据随时间变化的规律和趋势。时间序列分析是利用历史数据来建立数学模型,从而对未来数据进行预测的技术。
近年来,很多学者对此进行了研究,主要分为以下三种预测的方法:
1) 基于统计学方法的客流量预测 [9] [10]
时间序列分析的方法有很多,其中比较经典和常用的是自回归移动平均模型(ARMA) [11] 和自回归综合移动平均模型(ARIMA) [12] 。这两种模型都是基于线性回归的思想,将当前时刻的数据表示为过去时刻数据和误差项的线性组合。ARMA模型由两部分组成,分别是自回归部分(AR)和移动平均部分(MA)。AR部分表示当前时刻的数据与过去时刻数据之间的关系,MA部分表示当前时刻的数据与过去时刻误差项之间的关系。ARMA模型适用于平稳时间序列,即时间序列的均值、方差和自相关性不随时间变化的序列。
然而,在实际应用中,很多时间序列并不是平稳的,例如客流量数据可能受到季节性、趋势性等因素的影响 [13] 。为了处理非平稳时间序列,可以对原始数据进行差分处理,即用相邻两个时刻的数据之差代替原始数据,从而消除非平稳性 [14] 。这样得到的新序列称为差分时间序列,它可以用ARMA模型进行建模和预测。这种在ARMA模型基础上引入差分处理的方法称为自回归综合移动平均模型(ARIMA)。
何雪晴(2019)使用网络搜索数据和降噪处理进行的旅游客流量预测研究中,引入了经验模态分解方法进行降噪处理,使用经验模态分解方法对每个搜索指标数据分别进行了分解 [15] ,一定程度上避免了不同搜索指标之间噪声的干扰,提升了预测的精度。
段然(2017)对某铁路局全部列车旅客乘车数据进行清洗和规约,将数据划分为节假日和非节假日两种类型,对具有周期性的非节假日数据选用在传统ARIMA模型中加入周期性的SARIMA模型进行预测,而对节假日数据则选用波动系数模型进行预测 [16] 。最后,通过计算预测值与真实值的相对误差来评价模型的预测准确度,最终验证SARIMA模型与波动系数模型相结合的方法对铁路客流量的预测较为准确。
2) 基于机器学习的客流量预测 [17]
方昇越(2022)基于XGBoost模型,对短时客流量进行预测 [18] ,过对地铁客流内外部因素的特征分析,判断客流在时间和空间上的分布特点,确定相邻时段客流、预测时段、工作日和雨雪天气四个特征变量,最终确定短时客流量XGBoost模型,可以有效提升客流量预测的精度 [19] 。
鄢仕林(2022)通过对机场航线客流量分析,构建了GM(1,1)模型对序列的趋势性进行预测,并使用支持向量机模型对模型预测值的残差进行修正补偿 [20] ,通过实证分析发现该模型预测精度较高,可以为航线新开航线客流量预测提供决策支持。
马毅(2022)提出的一种改进的PAPSO-BP预测算法模型,对短期客流量情况进行了预测,改进粒子群算法。针对传统粒子群算法容易陷入局部最优值这一缺陷,对其做出改进:将惯性权重设置为随粒子适应度值自适应变化,且在位置更新公式中加入扰动因子 [21] ,仿真结果证明该改进的PAPSO方法有效提高了算法精确度。
冒志恒(2022)使用神经网络模型,结合历史数据对短时客流量进行预测。考虑到反向传播(Back Propagation, BP)神经网络的不足,提出改进BP神经网络模型预测精度的方法,构建了两种组合预测模型,即GA-BP模型和MEEMD-BP模型 [22] ,最终结果表明,组合预测模型在提升短时客流量预测的准确性上都有较好的效果,但使用MEEMD算法改进数据质量的MEEMD-BP组合模型对BP神经网络模型的预测精度提升更大。
蔡纯(2019)针对游乐园行业、管理者和游客三方面主体进行了细致的需求分析;然后,以此为依据,设计了基于多源数据的游乐园运营分析指标体系,旨在从多元视角,整合乐园游客、设备、销售等相关的实时运营数据,分析挖掘游乐园多源数据背后的关联与规律。使用传统回归预测模型和三种数据挖掘预测模型——SVR模型、决策树回归模型和BP神经网络模型进行比较 [23] ,分析了适用于游乐园客流量预测的有效模型。
成翔(2018)针对商铺客流量的特点,分析了影响商铺客流量的环境因素和产品因素,研究了不同因素导致的影响,为取舍预测数据建立了理论基础,再对数据进行学习从而提出最适当的数据分类的方法,并在理论上分析了不同的商铺客流量预测的方法 [24] ,证明了基于BP神经网络的商铺客流量预测是可行的。
3) 结合多种方法的客流量预测 [25]
邓雨菲(2022)针对旅游客流量的真实数据,基于ARIMA-ATT-LSTM模型对景区客流量进行精准预测 [26] ,为高峰期旅客爆满、景区拥堵、环境破坏、安全隐患、淡季旅游资源闲置等问题提供了理论支持。
常昊(2022)采用LSTM神经网络对地铁短时客流量进行预测,通过建立ARIMA短时客流预测模型实现周期性客流的波动特征提取,采用Light GBM预测算法实现对客流峰值的泛化,建立LSTM预测模型,在此基础上,提出LGB-LSTM并联模型,通过对客流空间和时间数据特征提取 [27] ,解决预测精度和非线性最优拟合问题。
殷志敏(2022)使用杭州市AFC系统的所有地铁站刷卡数据信息,对数据进行处理后建立短期客流量预测模型,从站点和时间两个方面对客流量数据特征进行分析,对工作日和周末分别建立客流量LightGBM预测模型,将LightGBM模型和LSTM模型进行加权融合 [28] ,最终预测精度得到提升。
吕高帆(2019)使用K-means聚类算法对原有历史数据进行数据聚类处理,结合CART机器学习算法及统计学分析方法的优势,提出一种建设性较强,且适用性突出的无人超市客流量组合预测模型 [29] ,为管理者提供比较及时的客流分布,而且可以更好地为决策者提供可参考的决策信息。
张璐(2022)基于最小二乘支持向量机风电功率预测模型求解短期风功率预测问题,采用了一种基于密度的聚类算法以目标风功率属性特征密度作为分群指标模型对训练样本进行聚类与划分,对风电机组的异常数据进行识别并排除 [30] ,提高模型预测结果的准确性。
3. 模型方法
3.1. Arima
Arima (Autoregressive Integrated Moving Average model)模型,即差分整合移动平均自回归模型,又称整合移动平均自回归模型或整合滑动平均自回归模型 [31] ,是时间序列预测分析方法之一,通过发现数据之间的相互关联性,以时间为轴,进行线性预测。Arima模型主要由三部分构成:AR、I、MA。
AR是“自回归”(Autoregressive)模型,因为其变量只包含一个值,即它本身,所以称其为自回归。AR(p)模型的含义为当前的时间点所对应是值等于过去p个时间点所对应的值的回归,其中p为阶数,公式为:
.
I是集成(Integrated)的含义,是对数据进行了关于时间的差分,因为时间序列分析对数据的平稳性具有一定的要求,因此在进行模型训练前,应通过一定的数学方法将现有数据序列转换为平稳的数据序列,一般采用的方法是进行差分,公式为:
用t时刻的数据值减t − 1时刻的数据值,此时得到的新的数据序列称之为1阶差分序列。按照此规律,再次进行相同操作将得到2阶差分序列,公式为:
一般的时间序列算法最多进行2阶差分,若数据依然不具备平稳特征,此时可以认为数据缺乏平稳性,不具备进行时间预测的前提,此时应当更换数据集,或是探究造成数据不平稳的缘由。
由于数据具有一定的周期性,所以引入了一种特殊的季节性差分S,即将原本的数据按照一定的周期拆分,让t时刻的数据值减t − T时刻的数据值,此时得到的便是带有季节性的差分序列。
MA是移动平均(Moving Average)模型或滑动平均模型,MA(q)是当前时刻的数据值等于过去q个历史预测误差值的回归,其中q为阶数,公式为:
将上述的AR(p)和MA(q)两个模型进行结合,就得到了Arima模型,公式为:
.
由于时间序列算法在进行训练时,要求数据必须是平稳的。因此在数据准备阶段,我们应当对数据的平稳性进行检验,如果数据不平稳,那么应当进行差分,至多2轮后,若数据平稳,继续进行实验,其中差分阶数d是Arima模型中参数d的值。通过AIC_BIC检验,确定p,q的值,最后利用Arima(p,d,q)模型进行预测。Arima模型实验流程图1如下:
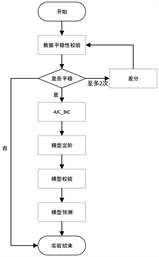
Figure 1. Flowchart of Arima model experiment
图1. Arima模型实验流程图
3.2. Holt-Winters
Holt-Winters模型,是在Holt模型的基础上引入了Winters季节项,是一种较为高效的预测模型。与其他时间序列模型只能使用平稳序列数据不同,它对有线性趋势和周期波动的非平稳序列也同样适用。
Holt-Winters模型主要分为如下两类:
1) Holt-Winters加法模型又称为加性季节模型。因此我们应当有
用于描述时间序列的线性趋势也就是趋势因子
,设两个平滑参数
,
,公式如下:
同时还应当有对季节T进行描述的季节因子
,设一个平滑参数
,公式如下:
我们假定时间序列
的趋势因子
与季节因子
是相加关系,公式如下所示:

三个平滑参数
、
、
,其取值都在0到1之间,是模型预报值与实测预测值之间的平衡权重。参数
、
、
越大,表示时间序列
的非平稳性越强,模型的可预报时间越短。如果能用较小的参数
、
、
与历史数据吻合上,则可预报时间较长。
2) Holt-Winters乘法模型。
Holt-Winters乘法模型又称为乘性季节模型,与加法模型类似,我们设三个平滑参数
、
、
,其取值都在0到1之间,因此将得到如下公式:
可以看到用于描述时间序列的线性趋势的
不变,
和
中的减法运算变成除法运算。与加法模型不同,在乘法模型中,我们将假设
和
相乘后的结果是
在预测是将三个平滑参数
、
、
的值都设置为0,此时根据公式计算预测值。因此乘法模型是非线性模型,能够更好的处理随趋势成分变化的季节波动的振幅变化,所以它比加法模型更依赖一个好的初始值。
Holt-Winters模型的具体实验流程如图2。
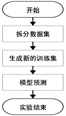
Figure 2. Flow chart of Holt-Winters model experiment
图2. Holt-Winters模型实验流程图
3.3. Mean-Value
Mean-Value方法,称为均值填充方法,是常用的异常值填充方法,可以分为两类均值填充方法。
全局均值填充,每次填充时,都计算将当前全部数据的平均值,将本次计算的平均值用作填充异常值。并在下次计算时,将本次结果也用作计算集的一部分。具体公式如下:
区域均值填充,每次填充时,将采用当前值前后m个区域内的数字作为数据集,计算平均值,当遇到连续异常值时,应当跳过异常值向后取数,进行填充,具体公式如下:
全局均值填充可以更好的对平稳数据填充,但较容易收到极值的影响,而导致填补值出现异常。
区域均值填充可以对异常值数据的前后进行记录,不易收到极值影响,较为稳定,因此在本实验中,我们将使用区域均值填充作为均值填充算法。具体实验步骤如下图3。
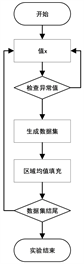
Figure 3. Flowchart of Mean-Value model experiment
图3. Mean-Value模型实验流程图
4. 实证分析
从某零售企业获取某卖场的每日成交数据,用于作为客流量预测的数据集,分别对数据集的异常值进行删除空值、Mean-Value填充、Arima填充等方法进行处理,然后创建基于多种数据补全策略的Arima模型、SArima模型和Holt-Winters模型进行预测,采用不同的评价指标对模型进行对比,来分析多种数据补全策略对零售商超卖场客流量预测的影响。
4.1. 数据准备
客流量数据来自于某头部零售商超卖场成交数据,由于数据量较为庞大,且因为ERP系统不稳定,因此数据中存在大量的异常值,因此在使用这些数据进行训练模型前,应当对数据进行预处理。常用的数据预处理方式包括数学方法、统计学方法等。例如在处理异常值时,应当分为如下状况:
重复值:当发现重复值时,应当删除多余重复值,并只保留一条有效数据。
缺省值:当数据中出现缺省值时,应先判断数据类型,如果是有规律数据,应当按照客观规律填入;例如,4月5日,[缺省值],4月7日,则此时的缺省值应当填入4月6日。若是数据为统计类数据,应当按照数据规则,填入平均数、中位数或以其他数学规则填入,如果无法找到对应规则填入,应当删除这条无效数据。
异常值:当数据中发现数据远超出于其他数据时,即数据极大或数据极小,又或者是数据不符合常识,例如,顾客生日为1900年1月1日;这时应当按照缺省值的补全策略来完成数据的修补。
使用上述规则对数据进行清洗后,可以基本保证数据的准确性与有效性。
在数据存入数据仓库后,我们就可以依据自己的实验,来抽取所需要的数据,使用数据导出工具,框选好时间日期后,选择相对应的卖场,对全部成交数据进行汇总,得出了某卖场的真实客流量数据。
本文中选取了某头部零售商超卖场真实客流量数据,由于数据在进入数据仓库时只进行了简单的清洗,去除了无效值,因此我们对异常值的处理将按照实验规划,采用删除空值、Mean-Value填充、Arima填充方法进行处理。同时为了保证实验的严谨性、准确性、可复用性,实验的测试集将只进行数据清洗,不进行任何数据补全,且数据完备率大于95%,并保证测试集完全相同。所以我们将以时间升序的方式,对数据进行抽取。将时间作为索引项,可以绘制出如下的折线图,为了构建疫情因素影响的模型,我们将使用2021年3月1日至2021年8月31日的数据作为本次实验的数据集。其中2021年3月1日至2021年7月31日的数据作为训练集,2021年8月1日至2021年8月31日的数据集作为测试集。生成的基于多种数据补全策略不同时间序列图像如下图4、图5、图6、图7所示。通过对模型的训练最终实现预测,并对比分析各个模型的精准度。
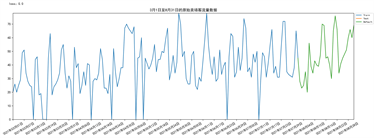
Figure 4. Statistical diagram of original store passenger flow data
图4. 原始卖场客流量数据统计图

Figure 5. Statistical diagram of store traffic data with outliers deleted
图5. 删除异常值的卖场客流量数据统计图
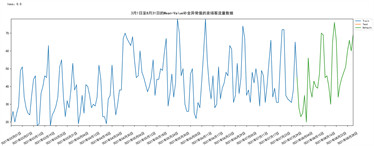
Figure 6. Statistical diagram of customer traffic data of Mean-Value complete outlier
图6. Mean-Value补全异常值的卖场客流量数据统计图

Figure 7. Statistical diagram of shopping mall traffic data with Arima model completing outliers
图7. Arima模型补全异常值的卖场客流量数据统计图
4.2. Arima模型预测
使用Arima模型时,必须保证数据序列的平稳性,所以在进行模型训练前,应当首先判断数据序列是否具备平稳性,绘制图像的差分图,如图8所示。
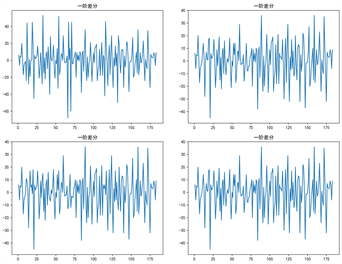
Figure 8. First-order difference graphs of four data completion methods
图8. 四种数据补全方法的一阶差分图
通过观察分析可知,四份数据均在1阶时稳定,此时显著水平p值、ADF的检验结果、显著性水平分别如下表1所示:

Table 1. 0-order data ADF verification
表1. 0阶数据ADF校验
4.3. SArima模型预测
建立SArima模型,在上一步中,我们已经确定数据在1阶时,具有稳定性,因此SArima模型的三个参数(p,d,q)中,可以认定差分阶数d = 1。接下来应当确定p和q两个参数,我们有多种方法来定阶,常用的方法为绘制ACF图和PACF图,通过观察ACF图与PACF图可以大概确定模型的p,q值。但是由于这种方法所生成的p,q值具有较强的主观性与经验性,所以可以使用AIC_BIC热力图的方式,来确认生成的模型参数。
1) 不进行任何数据补全的SArima模型
对数据进行预处理后生成的AIC_BIC热力图如下图9所示。
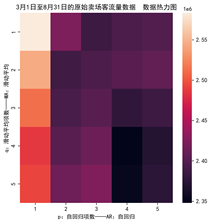
Figure 9. Raw data AIC_BIC heat map without data completion
图9. 不进行数据补全的原始数据AIC_BIC热力图
可以看到,图9中深色区域的部分为(p,q)的值分别为(4,4),在使用网格搜索,对P、D进行调优,利用SArima模型对客流量进行预测,绘制折线图,如下图10所示。
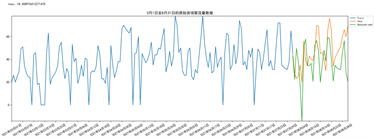
Figure 10. Prediction effect of SArima model
图10. SArima模型预测效果图
将预测值与真实值进行求差计算,制作统计表,如下表2所示。
Table 2. Error table of SArima model prediction results
表2. SArima模型预测结果误差表
2) 删除异常值的SArima模型
对数据进行预处理后生成的AIC_BIC热力图如下图11所示。
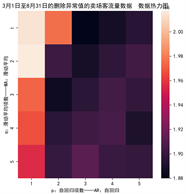
Figure 11. AIC_BIC heat map of data with deleted outliers
图11. 删除异常值的数据的AIC_BIC热力图
利用Arima模型对2021年的客流量进行预测,绘制折线图,如下图12所示。
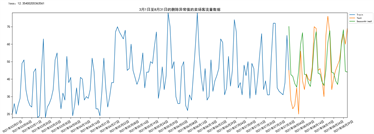
Figure 12. Prediction effect of SArima model
图12. SArima模型预测效果图
将预测值与真实值进行求差计算,制作统计表,如下表3所示。
Table 3. Error table of SArima model prediction results
表3. SArima模型预测结果误差表
3) 使用Mean-Value填补异常值的SArima模型
对数据进行预处理后生成的AIC_BIC热力图如下图13所示。
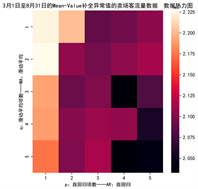
Figure 13. AIC_BIC heat map with Mean-Value completion of outliers
图13. 使用Mean-Value补全异常值的AIC_BIC热力图
利用Arima模型对2021年的客流量进行预测,绘制折线图,如下图14所示。
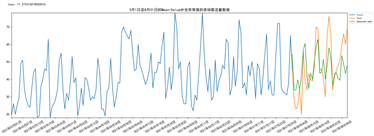
Figure 14. Prediction effect of SArima model
图14. SArima模型预测效果图
将预测值与真实值进行求差计算,制作统计表,如下表4所示。
Table 4. Error table of SArima model prediction results
表4. SArima模型预测结果误差表
4) 使用Arima填补异常值的的SArima模型
对数据进行预处理后生成的AIC_BIC热力图如下图15所示。
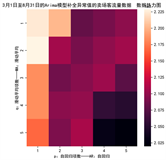
Figure 15. AIC_BIC heat map using Arima model to complete outliers
图15. 使用Arima模型补全异常值的AIC_BIC热力图
利用Arima模型对2021年的客流量进行预测,绘制折线图,如下图16所示。

Figure 16. Prediction effect of SArima model
图16. SArima模型预测效果图
将预测值与真实值进行求差计算,制作统计表,如下表5所示。
Table 5. Error table of SArima model prediction results
表5. SArima模型预测结果误差表
4.4. Holt-Winters预测
采用网格调参的方式,找到Holt-Winters模型在数据集上的最优解,得到的结果如下所示。
1) 不进行任何数据补全的Holt-Winters模型
Holt-Winters模型生成的预测图如下图17所示:
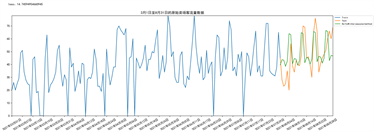
Figure 17. Prediction effect of Holt-Winters model
图17. Holt-Winters模型预测效果图
Holt-Winters模型预测的结果与真实值之间的误差如下表6所示:
Table 6. Error table of prediction results of Holt-Winters model
表6. Holt-Winters模型预测结果误差表
2) 删除异常值的Holt-Winters模型
Holt-Winters模型生成的预测图如下图18所示:
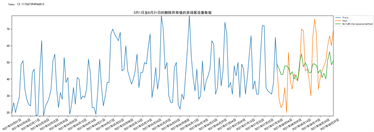
Figure 18. Prediction effect of Holt-Winters model
图18. Holt-Winters模型预测效果图
Holt-Winters模型预测的结果与真实值之间的误差如下表7所示:
Table 7. Error table of prediction results of Holt-Winters model
表7. Holt-Winters模型预测结果误差表
3) 使用Mean-Value填补异常值的Holt-Winters模型
Holt-Winters模型生成的预测图如下图19所示:
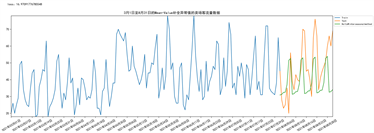
Figure 19. Prediction effect of Holt-Winters model
图19. Holt-Winters模型预测效果图
Holt-Winters模型预测的结果与真实值之间的误差如下表8所示:
Table 8. Error table of prediction results of Holt-Winters model
表8. Holt-Winters模型预测结果误差表
4) 使用Arima填补异常值的Holt-Winters模型
Holt-Winters模型生成的预测图如下图20所示:
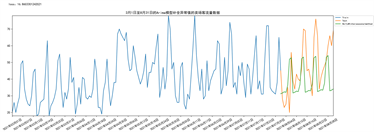
Figure 20. Prediction effect of Holt-Winters model
图20. Holt-Winters模型预测效果图
Holt-Winters模型预测的结果与真实值之间的误差如下表9所示:
Table 9. Error table of prediction results of Holt-Winters model
表9. Holt-Winters模型预测结果误差表
4.5. 对比分析
对基于多种数据补全策略的SArima模型、Holt-Winters模型训练效果进行对比分析,使用常用的误差损失函数来判断模型的效果。
1) 均方差误差MSR值越小,预测值与真实值的误差越小。
2) 均方根误差RMSE值越小,预测值与真实值的误差越小。
3) 平均绝对误差MAE值越小,预测值与真实值的误差越小。
4) 平均绝对百分比误差MAPE值越小,预测值与真实值的误差越小。
公式中n代表样本个数,
为预测值,
为真实值。
在实验结束中,我们将分别对应多种数据补全策略情况下分别生成Holt-Winters模型、SArima模型,并使用2021年8月1日至2021年8月31日的数据集作为测试集,使用MSE、RMSE、MAE和MAPE值进行统计,制表10如下。
Table 10. Results of evaluation indexes of the three models
表10. 三种模型评价指标结果表
根据表中数据,我们可以发现,在进行了数据补全后,SArima模型效果在各个指标上均优于Holt-Winters模型,而未进行数据补全时,Holt-Winters模型具有较低的损失,其原因是SArima模型不单单考虑了数据之间的线性关系,还计算了N天前的数据,因此如果数据中存在较多的干扰异常值时,SArima模型效果会下降,即便删除了这些异常值,SArima模型在拟合时,由于周期性改变,因此也无法继续进行正确的预测。在使用了Mean_Value与Arima模型进行异常值填充后,SArima模型的预测效果得到了大幅度的提升,Holt-Winters模型在进行填充后反而错误率提高,原因时因为Holt-Winters模型只考虑普通线性关系,当预测数量越多,误差也就越大。对比两种异常值填充的方法,我们发现使用Arima模型进行的数据填充在SArima模型和Holt-Winters模型中,都有一定程度的提升。
总体而言,在进行时间序列预测时,我们应在数据清洗完成后,对异常值进行处理,可以极大的提升模型预测效果。并且在进行异常值填充时可以考虑使用Arima模型作为填充策略,在一定程度上,可以增强模型的预测效果。
5. 结语
本文研究了多种数据补全策略对商超客流量预测的影响,分别使用不进行数据补全、删除异常值、基于Mean-value、基于Arima模型的数据补全的SArima、Holt-Winters模型建立了客流量预测模型。通过多个评价指标的对比,表明若数据只进行简单补全操作时,Holt-Winters模型的效果较好,而使用复杂的补全方式后SArima模型的效果较好,并有了较大的提升,优化效果达到了Holt-Winters模型的两倍以上;并且对比两次实验,发现SArima模型会受到不同补全策略的干扰,但是,当使用一定的补全策略后,将达到一个较好预期的结果。所以得到结论,不同的补全策略将极大影响Sarima模型的稳定性,且使用Arima模型进行数据补全将提升模型的准确程度。
由于现有的模型都只是考虑了特征之间的线性关系,并没有考虑到其他非线性特征对模型预测的影响,例如当天的天气、是否为节假日、是否有促销活动等。未来可以通过特征工程的方法,将这些特征添加到预测中去,或使用大语言模型,先对各项特征进行向量化,将向量特征添加到预测中去,来提高模型预测的精度。
总之,本研究为客流量预测的数据补全提供了一些参考,但仍需要进一步改进和完善,以更好地应对实际应用需求。
基金项目
2020年襄阳市农业领域重点科技创新计划项目“基于多源异构大数据平台的精准农业智能化服务系统的研发与应用”(项目编号:2020ABA002240)。