1. 引言
港口作为世界航运的中心枢纽,港口服务的质量决定了其在世界港口群上的核心竞争力强弱。在港口竞争日趋激烈的情况下,港口自身的服务水平也成为货主们选择的重要因素。目前,很多港口都采用了集卡预约到港模式,与传统的集卡集中进港模式相比,既能让货主有充裕和弹性的集卡入港时间,又能够给货运公司安排和调度集卡运输带来极大便利,同时也能缓解集卡集中到港造成码头闸口的拥堵及排队现象。港口码头能否准确及时地把握每日到港的集卡信息,决定了港口码头能否高效率地完成日常工作,同时影响着港口码头周边疏港道路的拥堵情况。因此,对实际的集卡到港数量进行预测,对于合理制定或及时调整码头作业调度计划具有十分重要的现实意义。
对于客货运量预测研究,绝大多数学者采用单一模型对客货运量进行预测。最常见的方法有人工神经网络、时间序列预测方法、灰色模型等 [1] 。神经网络具有良好的非线性拟合能力和较强的学习能力,Han等 [2] 利用深度置信网络(DBN)提取流量数据的基本特征,并建立深度神经网络模型和内核极限学习机分类器对流量进行预测。Du等 [3] 为预测城市交通客流量,建立一种深度不规则卷积残差长短期记忆网络(LSTM)模型,还进一步融合了其他外部因素以促进实时预测。自回归综合移动平均(autoregressive integrated moving average, ARIMA)模型在数据的线性部分表现出良好的拟合能力,且理论简单、分析结果易懂。Kumar等 [4] 提出一种利用季节性ARIMA模型的预测方法,通过使用有限的输入数据来对交通流量进行短期预测。灰色预测所需的样本量较少,对时间序列短、原始数据少、信息不完整数据的建模具有独特优势,短期交通预测在智能交通系统中发挥着重要作用。Guo等 [5] 提出一种新的灰色GM模型来预测交通量,并将其与季节性自回归积分移动平均(SARIMA)预测模型进行比较,研究发现,改进的灰色模型的预测精度均优于SARIMA模型。
以上方法在交通流预测领域有着广泛的应用,但因为客货运量的影响因素比较多,具有非线性和不稳定性的特点,若仅采用单一模型进行预测,难以进一步提高短期流量的预测精度。而组合模型可以综合各个模型的优点,减少各模型的预测风险和不确定性,从而有效地提高模型预测的准确性和可信度。刘杰等 [6] 为预测交通枢纽短期的客流量,将BP神经网络和最小二乘支持向量机进行组合,结果表明,两模型组合的预测精度较单一模型更加优秀。柯桥、邵梦汝等 [7] [8] 采用BP神经网络模型与灰色模型相结合的方法来预测货运量与短期交通量,为流量预测提供了一种新思路。田瑞杰等 [9] 针对现有绝大多数交通流量预测方法所采用的数据、模型均较为单一的问题,将时序模型与人工神经网络进行组合,并将其应用于交通流量预测。Raza等 [10] 提出一种基于遗传算法优化的人工神经网络和局部加权回归组合模型来实现最优预测。
从已有研究可以看出,大部分预测客货运量的研究仅利用了交通流量自身信息进行预测,只有少部分学者会将其他影响因素纳入考虑之中。另一方面,单个预测方法具有局限性,在某些情况下预测精度难以满足要求。实践表明,单一的预测方法都有其自身的特点和缺陷,例如BP神经网络中隐含层神经元数目的选择会对预测效果产生一定的影响,灰色模型在自学习、自适应方面较差等。现有研究采用组合预测方法以提高预测精度。因此,采用组合模型预测的方法来对客货运的交通流量进行预测是未来交通运输业预测方面的发展趋势之一。
目前,关于集装箱港区集卡到港量短期预测的研究比较少。本文将选用BP神经网络模型、ARIMA模型以及灰色GM(1, 1)模型中的二者进行组合,建立组合预测模型来预测集装箱港区集卡的每日到港量。本文的创新之处在于:1) 将船期表和码头堆存费率作为影响因素,并对这些因素进行处理提取特征值作为自变量。2) 构建不同的组合预测方法,并在小样本数据的条件下,对不同的组合预测方法进行对比分析,以期找到预测精度最高的组合预测方法。
2. 组合预测模型构建
组合预测的理念是在1969年Bates等人首次提出的。组合预测可以将多个单一的预测模型结合起来,从而获得一个包含了有多个预测信息的新预测模型。该方法可以弥补单一模型在特定情况下预测的局限性,从而实现模型之间的互补。本文使用BP神经网络模型 [11] 、灰色模型 [12] 以及ARIMA模型 [12] 来进行预测并进行两两组合预测。
2.1. ARIMA-BP模型
ARIMA模型在数据的线性部分表现出良好的拟合能力,在非线性部分则不够理想,而BP神经网络具有良好的非线性拟合能力和较强的学习能力,可以有效解决数据的非线性问题。港口集卡到港量数据具有线性与非线性特点,BP神经网络能有效弥补ARIMA模型中所忽略的非线性信息 [13] 。因此将ARIMA模型和BP神经网络模型使用加权组合法进行结合,使两者的优势互补。ARIMA-BP加权组合预测的结果由两部分组成,具体组合预测步骤流程图见图1。
具体公式为:
(1)
式中:若m为集卡到港量数据调查天数,
(
)为ARIMA-BP组合模型的集卡到达量预测值;
、
(
)分别为ARIMA模型与BP神经网络模型的预测值;
、
分别为ARIMA模型与BP神经网络模型在组合预测中的权重。
组合模型预测误差为:
(2)
式中:
(
)为实际时间数据序列;
(
)为组合模型预测误差,
为ARIMA模型的预测误差,
为BP神经网络模型的预测误差。
2.2. 灰色–BP神经网络模型
BP神经网络是一种定量的非线性分析方法,而灰色模型为定性分析,它可以准确预测与分析研究对象的发展趋势,而且不需要太多的数据样本。灰色–BP神经网络模型是将BP模型和灰色GM(1, 1)模型
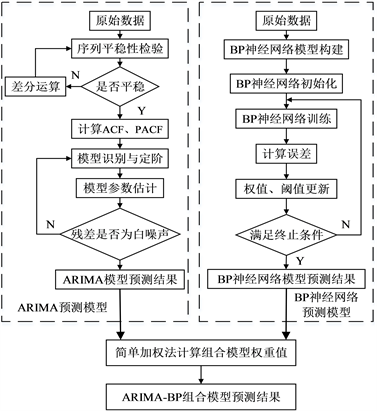
Figure 1. ARIMA-BP combined model prediction flow chart
图1. ARIMA-BP组合模型预测流程图
组合起来,它是一种综合定性分析与定量分析的预测方法,该方法适用范围广,能够很好地拟合非线性关系,还可以有效地解决复杂系统的建模问题,并根据具体的问题特征灵活地建立模型,从而提高预测精度。其常用的组合模式分别有并联、串联和嵌入,本文采用的是串联式的灰色–BP神经网络组合模型,拓扑结构见图2。

Figure 2. Topology structure of Gray-BP neural network combined prediction model
图2. 灰色-BP神经网络组合预测模型拓扑结构图
具体方法步骤如下:
1) 首先构建灰色GM(1, 1)模型来拟合原始样本数据,得到灰色模型对原始数据样本的预测值;
2) 然后进行BP神经网络的建模和参数设定;
3) 接着将灰色GM(1, 1)模型所得到的预测结果替代BP模型的输入数据,将原始样本数据作为BP模型的输出数据;
4) 最后通过反复学习训练,得到灰色–BP神经网络组合模型的预测结果。
2.3. 灰色–ARIMA模型
灰色模型具有较好增长特性的特点,但其预测精度不算高,只适用于指数增长型数据的中短期预测,并且对初始值和背景值具有依赖。为了改善其在交通量预测中存在的缺陷,将ARIMA模型和灰色GM(1, 1)模型进行组合,不仅能够提高预测结果的准确性和适用性,还能使模型得到更加灵活地应用。灰色–ARIMA预测模型拓扑结构见图3。

Figure 3. Gray-ARIMA prediction model topology structure diagram
图3. 灰色-ARIMA预测模型拓扑结构图
具体方法步骤如下:
1) 设原始数据序列为
,首先构建灰色预测模型,并拟合原始数据序列,得到一个拟合序列,接着利用残差检验法对灰色模型预测结果进行检验。
2) 对
拟合序列求误差序列
:
(3)
3) 对误差序列
进行非负处理,找出误差序列
中的最小值,记为
,令
,得到序列
。
4) 判断误差序列
的平稳性,并且对非负处理后的误差序列
做单位根检验(ADF),得到差分阶数d。
5) 建立ARIMA模型,得到自相关图和偏自相关图来初步判定参数p和q的值,然后再根据AIC(Akaike information criterion)准则来确定最优模型,且得到该模型的误差预测序列
。
6) 对
进行差分还原,得到序列
,接着将
序列还原成原始数列的预测数列,还原公式为:
。
7) 模型适应性检验。将差分还原后的ARIMA模型预测结果进行白噪声测试,如果测试没有通过,那么说明还有相关数据信息还未被充分挖掘,则应该重新修改模型的相关参数并构建模型,直到通过测试为止。
8) 将灰色GM(1, 1)预测结果
和差分还原后的ARIMA模型预测结果
相加,得到组合模型的最终结果
,即:
。
3. 预测精度评价指标
为了衡量不同预测模型的预测精度,采用三项统计学误差指标对不同模型的预测精度进行评价,分别为均方根误差(RMSE)、平均绝对百分比误(MAPE)以及平均绝对误差(MAE)。各项误差指标的大小可以直观地反映出不同模型的预测效果,MAE、MAPE和RMSE数值越低,那么说明该模型预测数据更加精准。
4. 实证分析
4.1. 集卡到港量的主要影响因素
以上海外高桥二号码头振东为研究对象进行数据采集,本次研究采用的是上海外高桥二号码头2020年11月~2021年1月之间采集的28天的10点~16点之间6个小时的集卡到港量,通过对于外高桥二号码头的实地调研以及相关网站的数据调查,获得港口码头的船期表,船舶开截港时间以及码头堆存的相关费用。
根据上海外二集装箱码头的堆存保管收费标准,堆场不同箱型不同存放时长有着不同的收费标准。由于进口货物存在免费堆存时间,所以本文选择了在免费堆存时间内的船舶数量和在极限免费堆存时间下的船舶数量(当日提前三天的靠港船舶数量)作为两个因变量。
船舶的靠港都会吸引大批集装箱卡车抵达港口集散集装箱,而船舶的进出港时间均以船期表为准。在对其因变量进行分析时,由于港口码头堆场对于出口集装箱没有提供免费堆存时间,因此绝大多数货主以及货运公司为了减少成本的开支,在送出口集装箱时会选择将集装箱在船舶靠港当天或提前一天运送至港口堆场。同理,船舶在进入港口之前有一个开截港时间,其作用是使得运送出口箱的货主在船舶驶离港口前将货物运送至港口码头。在处理开截港数据时,由于考虑到开截港时间跨度为3~14天不等以及货主大多考虑到经济因素不会将货物过早地运送至集装箱码头而导致需要交付过多的堆存管理费用,因此选择当天截港的船舶数量作为一个因变量。
按照上文所述的方法处理了收集到的数据后,一共得到28份数据,将上海外高桥二号码头的船舶到港时间、开截港时间、当日星期数与当日集卡到达量数据进行处理并将数据分为预测集和验证集,来检验模型的准确性。以此为基础进行集卡到港量的预测。
4.2. 不同预测模型的参数设计
4.2.1. BP神经网络模型预测
使用矩阵工厂MATLAB对BP神经网络模型进行训练。建立三层BP神经网络预测模型,将船舶的开截港时间与码头堆存费率等五个因变量分别作为五个神经元输入,将当日集卡到达数量作为输出。接着对28天集卡到港数据进行划分,选择前21天的数据为训练部分数据进行训练,其余的7天数据为测试数据来验证模型的准确性。
将处理完的训练数据通过激励函数进行处理,并且确定神经网络结构,输入层神经元数为5,输出层神经元为1。增加网络的层数亦或是增加隐含层的神经元数量都可以减少BP模型的预测误差,但是随着网络层数的增加,网络的复杂程度也会因此增加,所以大部分情况下则优先考虑增加隐层神经元数目。隐含层节点通过试凑法来进行选择,确定初始隐含层节点数公式如下所示。
(4)
其中
、
分别为输入层和输出层的神经元个数,b为调节常数,b
[1, 10]。
根据公式并经过反复试验,得出:当l = 10时,预测值的误差最小,得到最优化的BP神经网络结构5-10-1。设置参数:网络训练次数设为2000次,学习速率设为0.2,训练目标设为0.001。
4.2.2. ARIMA模型预测
使用社会科学统计软件SPSS对ARIMA进行建模分析。将28天的集卡到达量作为研究对象,前21天的数据作为原始样本输入,剩余7天的数据采用ARIMA模型进行模型检验,通过与实际数据的对比来对预测结果进行评价。
首先判断数据的平稳性,对集卡到达量原始数据做时序图,原始时序图数据波动较大,因此原始数据是非平稳序列;接着对序列进行一阶差分处理后可见检验统计量中p值等于0,说明不存在单位根,序列趋于平稳,即一阶差分后时间序列为平稳序列,故d取值为1;然后对p和q进行定阶,通过自相关图(ACF)和偏自相关图(PACF)可以判断该序列的ACF和PACF均为拖尾,故p > 0,q > 0;最后采用最小AIC准则,取自回归阶数p值为1,移动平均阶数q值为1,即选定最优模型为ARIMA(1, 1, 1)。残差ACF和残差PAC系数的绝对值也均小于0.3,则表示所有数据之间具有相互独立性,即认为残差序列为白噪声序列,代表有用信息已经被提取,建模可以终止。
4.2.3. 灰色GM(1, 1)模型预测
建立灰色GM(1, 1)模型,将港口集卡到港量数据作为灰色模型的输入,使用MATLAB进行建模预测,得到该模型平均相对残差为0.12,平均级比偏差为0.13,认为GM(1, 1)对原数据的拟合达到一般要求。
4.2.4. 灰色–BP神经网络模型预测
运用灰色GM(1, 1)模型所需样本数据少、序列的完整性和可靠性差的特点,选取28天集卡到达量的前7天作为灰色GM(1, 1)模型的输入,得到未来的21集卡数量预测结果;接着将该结果设为BP模型训练的输入数值,并将28天真实数据的后21天作为BP模型训练的输出数值。参数设置:BP神经网络隐含层节点按照公式和反复试验后选取8,确立BP神经网络的结构为1-8-1,参数设置与3.2.1.节BP神经网络模型建模参数相同。
4.2.5. ARIMA-BP模型预测
上文已经建立的BP神经网络和ARIMA模型通过加权组合法进行组合预测,保持其参数不变,加权组合法的权重
利用误差倒数法来计算,误差倒数法是利用均方根误差RMSE来决定模型在组合预测中的占比。权重
计算方式为:
(5)
(6)
(7)
式中:
、
分别为ARIMA模型、BP神经网络模型预测结果的RMSE。
根据具体数据求得:
= 334.4644,
= 165.6193。计算得到:
= 0.3311,
= 0.6689,故ARIMA-BP神经网络组合模型的预测值为:
4.2.6. 灰色–ARIMA模型预测
选取28天集卡到达量数据作为研究对象,并选取其前21天作为原始数据,剩下7天作为验证集对模型预测结果进行准确度验证。首先使用MATLAB构建灰色GM(1, 1)模型来拟合集卡到港量的原始数据,并且预测出第22至28天的集卡到达量;接着建立ARIMA的误差序列预测模型,将处理过后的灰色残差带入ARIMA模型,由于p值为0.005 < 0.05,数据已经平稳,即d = 0;最后结合ACF和PACF图,并采用最小AIC准则,发现自相关和偏自相关系数皆为拖尾,且都在二阶之后落入置信区间,故取自回归阶数p值为2,移动平均阶数q值为2,得到最优模型为ARIMA(2, 0, 2),ARIMA输出指标平稳的R2 = 0.426,表示拟合程度及格。
4.3. 模型对比结果分析
各模型的预测结果如图4所示。从单一模型看,BP神经网络模型计算出的结果的决定系数R = 0.88298,可以看出BP网络的训练结果与原始数据差别不大,得到的R接近1,表明BP神经网络模型得到了较好的训练,该模型的MAPE为6.7%,认为BP神经网络对原数据的拟合较为优秀,能够明显表现原始数据的波动情况。ARIMA模型和灰色GM(1, 1)预测模型MAPE分别为14.2%和14.5%,但预测数据整体呈增长趋势,对原始数据的变化趋势走向预测并不是特别的理想,故ARIMA模型和灰色GM(1, 1)模型整体的预测效果表现上一般。
从组合模型看,灰色-BP神经网络模型的MAPE为8.7%,通过折线图我们可以发现BP神经网络减缓了灰色模型的指数上升趋势,但是仍然无法较为精准的描述数据的走势。ARIMA-BP神经网络模型组合的MAPE为3.3%,该组合模型对原数据的拟合较为优秀,能够较为优秀且稳定的描述数据的变化趋势。灰色–ARIMA模型的MAPE为11.2%,其预测值在第四天以后预测的效果并不是特别理想,周一至周四还能大致描述原始数据的走向,而周五至周天的预测曲线则与原始数据走向相反,该模型对数据的走势不是那么精准但可以看出灰色–ARIMA组合模型拟合数据较其单一模型的精度有所提升。
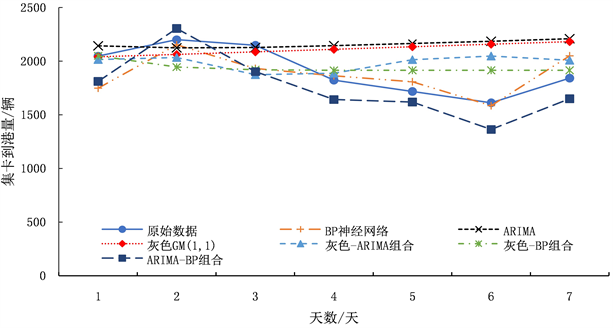
Figure 4. The prediction results of each model were compared with the actual data
图4. 各模型预测结果与实际数据对比
各个模型的误差指标如表1所示,其中,ARIMA-BP组合模型的MAE为66.5879,RMSE为88.9875,MAPE为3.3%。ARIMA-BP神经网络组合预测模型预测结果与实际数据误差在一个小范围内,均低于单一预测模型和其他组合预测模型的误差值,百分比误差较小,交通流数据吻合度高,预测效果相对较好,在一定程度上说明了ARIMA-BP神经网络模型在小样本数据情况下进行预测具有明显的优势。结果表明:ARIMA-BP神经网络组合模型的预测结果与实际数据的变化走向最为接近,其次是BP神经网络模型、灰色–BP神经网络模型以及灰色-ARIMA模型,可见BP神经网络模型增加考虑船期表以及码头堆存费率因素对集装箱码头公路集疏运需求预测方法的适用性。从整体分析,组合模型成功结合了不同预测方法的优点,弥补了各自的劣势,有效降低了单一模型在预测过程中由于环境的多重因素对预测结果的影响,所以组合模型的稳定性、可靠性以及预测精度较单一模型更加优异。

Table 1. Prediction model error comparison
表1. 预测模型误差对比
5. 结论
1) 本文针对港口公路集疏运货运需求历史数据及其本身特点,将船舶的开截港时间和码头堆存费率作为影响因素,建立ARIMA模型、BP神经网络模型以及灰色GM(1, 1)模型,并且将三个预测模型进行两两组合以提高预测精度。借助Matlab软件完成从数据处理和模型的构建,实现了各组合模型的短时交通流的精确预测。
2) 通过以上海外高桥二号码头集卡到港各项数据作为这六个预测模型的输入并进行对比分析。结果表明:ARIMA-BP组合预测模型对港口集疏运货运需求具有较好的预测效果,并证明了考虑船期表以及码头堆存费率因素下利用BP神经网络预测模型对集装箱码头公路集疏运需求预测方法的适用性。
3) 为进一步提高模型的准确度,需要增加大量的实验数据,还要对算法设计进行改进,使模型有更好的精准度和适用性。其次,本文在建立AIRMA-BP神经网络模型加权组合时采用的是误差倒数法,但给BP神经网络分配了较大权重,有可能会对预测结果产生不利影响。在今后的研究中,可以使用其他加权方法或者是动态权重的方法,以进一步提高集卡到港量预测的准确率。
基金项目
国家自然科学基金面上项目:疏港路网货车流运行优化方法(71971136)。