1. 引言
现如今,全球面临的最大挑战是气候变化问题。在现代化工业中,煤炭、石油、天然气的大量使用产生了数量巨大的二氧化碳(CO2)、二氧化硫(SO2)、臭氧(O3)等温室气体是造成全球气候变暖的主要原因。我国实施的“双碳”计划是新时代绿色发展理念的重要组成部分,力争2030年前实现碳达峰,2060年前实现碳中和 [1] 。
学者们利用不同方法对碳排放量进行预测分析,主要包括STIRPAT模型、情景分析法、IPAT模型、LEAP模型、蒙特卡洛动态模拟、中国能源环境综合政策评价模型、ARIMA模型、BP神经网络组合模型和系统动力学模型。黄蕊等使用STIRPAT模型和情景分析法预测了江苏省能源消费碳排放量发现,当人口和经济低速增长,技术高速增长时,2020年碳排放量预测值为202.81兆吨。长三角城市群是中国最大的城市群之一,已跻身于国际公认的六大世界级城市群。2019年,长三角城市群的碳排放量占全国碳排放量的13.6%,是中国碳排放重要来源区域。赵成柏和毛春梅利用ARIMA模型和BP神经网络组合模型,预测了中国碳排放强度的变化,结果表明,2020年中国碳排放强度比2005年下降了34%。结合长三角地区四省市的发展现状,参照现行长三角地区各省市国民经济 [2] ,基于改进的线性回归函数,利用GM(1,1)模型,在原有数据的基础上,模拟长三角地区2023~2025年的碳排放量,并预测长三角地区碳达峰和碳中和的时间节点。
2. 基于数理分析模型的发展现状研究
2.1. 描述统计分析模型的建立
描述统计源于生物学研究。严格意义上的描述统计学特指上世纪末至本世纪二十年代之间的以高尔顿为先导,而以卡尔·皮尔逊为代表的用于对生物资料进行分析所提出的一系列统计方法。其后,不少学者发现生物统计中的一些基本思想、方法和概念也适用于非生物学领域,尤其在社会、经济及管理领域中 [3] 。其通过图表或数学方法,对数据资料进行整理、分析,并对数据的分布状态、数字特征和随机变量之间关系进行估计和描述的方法。
假设第t年时,长三角区域内对应的新能源汽车产量为
,全国范围内对应的新能源汽车产量为
,定义一个变量:
其中,
表示第t年长三角区域新能源汽车产量与全国范围内新能源汽车产量比值。
再定义一个变量:
其中,
表示t时刻长三角区域新能源汽车产量在全国占比的增长率。
最后定义一个变量:
其中,
表示第t年长三角区域新能源汽车的生产量增长率相对于全国新能源汽车生产量增长率的比值。
分母的绝对值作用为,当全国新能源汽车生产量增长率小于0时,求绝对值可以修正长三角区域与全国新能源汽车产业的生产量增长率比值。
2.2. 描述统计分析模型的求解
随不可再生能源的日渐枯竭以及环境污染的日益严重,世界各国逐渐将目光聚焦于新能源的研究与开发,其中卓有成效的新能源汽车领域,经过三十年的时间从规划到量产,我国的新能源汽车产业取得了不小的成就,从2009年数百台的销量到2020年130余万余台的销量,科技方面也有所突破,相关基础设施也在逐渐的完善过程中 [1] 。
在中国知网等数据统计网站采集了2011~2022年对关键词(平均续航里程、平均指导价、供油国石油储量等)的数据,进行建模分析,用2011~2020年的数据用来验证模型的精度,截取部分数据,得到表1所示内容:

Table 1. Production data of four provinces of Yangtze River Delta and the whole country in from 2017 to 2022
表1. 2017~2022年长三角四省份及全国产量数据

Figure 1. Chart of the ratio between the output of Changjiang Delta new energy car and nationwide new energy car
图1. 长三角地区新能源汽车产量与全国范围内新能源汽车产量历年比值图

Figure 2. Annual growth rate chart of national proportion of new energy vehicle production in Changjiang Delta
图2. 长三角地区新能源汽车产量全国占比历年增长率图
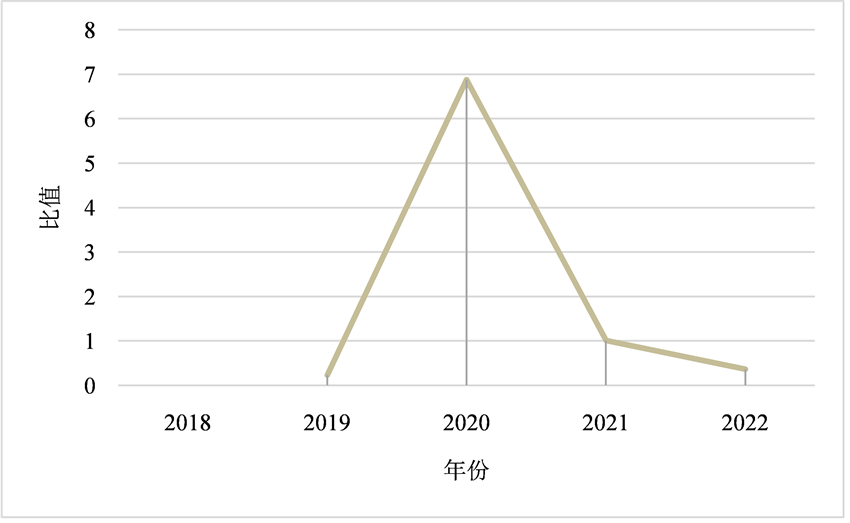
Figure 3. Ratio chart of output of new energy car between Changjiang Delta and the whole country
图3. 长三角地区与全国新能源汽车的生产量增长率历年比值图
由图1可知,长三角地区新能源汽车产量占全国范围内新能源汽车产量比重总体呈现逐年增长趋势;由图2可知,历年产量占比增长率呈正数;由图3可知,每年长三角地区新能源汽车产业较全国其他地区增长率更高、比重更大、发展速度更快。
2.3. 基于多元线性回归的竞争模型的建立
新能源汽车是我国汽车产业高质量发展的战略选择,也是助力我国实现“双碳”目标的重要举措。新能源汽车行业的快速发展,给传统燃油汽车带来了巨大的挑战。接下来通过建立各因素与新能源汽车产业和传统汽车产业的函数关系,研究我国新能源汽车与传统燃油汽车的市场竞争关系。
分析可知,在理想状态下若只存在一种类型的汽车,则汽车的销量增长量与汽车的生产量,汽车的需求量有关,则得到如下的关系式:
其中,
表示汽车的销售增长量,
表示t时刻汽车的生产量,
表示t时刻汽车的市场需求量。
进一步,如果同一个市场中存在着两种类型的汽车,则另一个汽车的生产量对第一种类型的汽车增长量有一定的影响,得到新能源汽车增长量的表达式如下所示:
其中,
表示新能源汽车的增长量,
表示新能源汽车的生产值,
表示市场汽车需求量,
表示传统汽车的生产量。
同理,得到传统汽车汽车增长量
的表达式如下所示:
回归模型(linear regression model)是一种特殊的数学回归模型,能够确定变量之间的相关性并且可以针对某一变量进行目的性预测。由于汽车保有量受到多个因素的影响,故建立多元回归模型,具体表达式如下所示:
其中,
为常数项,
称为回归系数,
为随机误差项,
为非随机的自变量,y为随机的自变量 [4] 。
2.4. 基于多元线性回归的竞争模型的求解
将收集到的2010~2022年新能源汽车与传统汽车生产量与销售量的数据如表2所示:
Table 2. Table of production and sales data of new energy vehicles and traditional vehicles from 2010 to 2022
表2. 2010~2022年新能源汽车与传统汽车产销数据表
分析表2中关于新能源汽车产量、传统汽车产量和市场汽车的需求量的数据,通过作出新能源汽车产量、传统汽车产量、市场汽车需求量这三个数据关于年份的散点图。在改进拟合前,本文使用万辆作为数据的单位,并全部做二阶多项式拟合得到的三个散点图和拟合曲线如图4~图6所示:
上面3个二阶散点图中拟合曲线的拟合优度R2分别为0.8498、0.9156、0.8706均大于0.84,拟合优度大,自变量对因变量的解释程度高,自变量引起的变动占总变动的百分比高。在改进拟合前,直接使用Stata 16 SE将这三个变量作为自变量,以新能源汽车的保有量为因变量,考虑到存在的异方差或自相关的情形,使用“OLS + 稳健标准误”的基本思想进行三元线性回归得出的结果如表3所示。
得到的结果拟合优度R2为0.9477,观测值拟合的效果好;F值为236.96很大,说明十分符合线性关系;P值为0.0000 < 0.0001,故置信区间达到99.99%以上,说明本次拟合结果好。以新能源汽车的生产量
、传统汽车的生产量
、传统汽车的需求量
为自变量,新能源汽车的增长量
为因变量,得
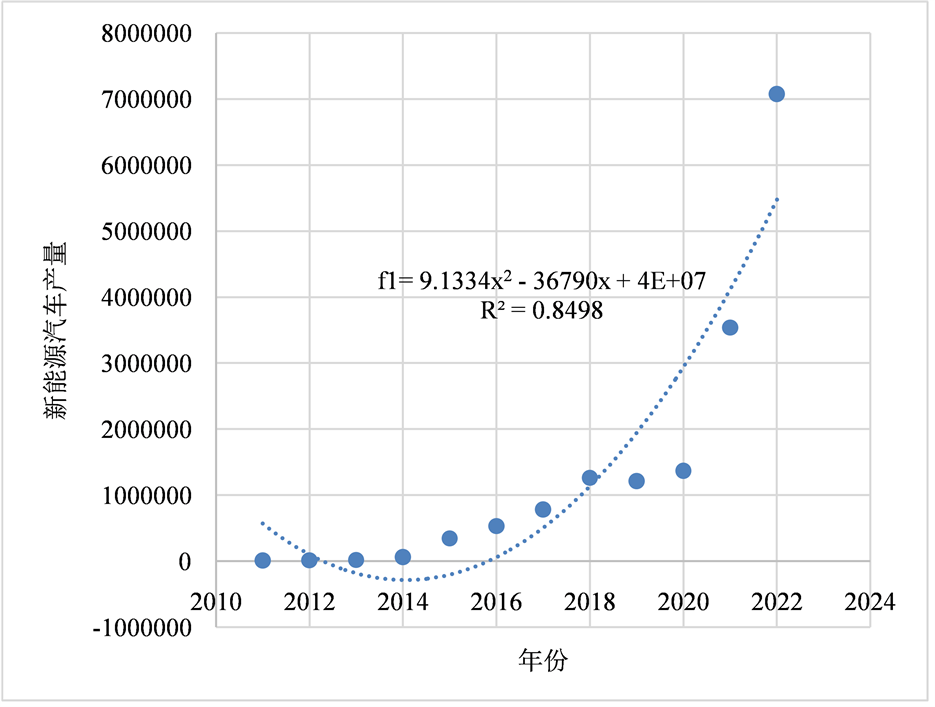
Figure 4. The fitting graph of the relationship between production and year of new energy vehicles
图4. 新能源汽车产量与年份关系拟合图

Figure 5. The fitting graph of the relationship between the production of new energy car and time
图5. 传统汽车产量与年份关系拟合图

Figure 6. The fitting graph of car demand and time
图6. 汽车需求量与年份关系拟合图
Table 3. New energy vehicle sales growth rate of three linear regression results
表3. 新能源汽车销量增长率三元线性回归得到的结果
到表达式为:
使用SPSS进行多元线性回归,得到各变量的系数如表4所示:
Table 4. New energy vehicle sales growth rate of ternary linear regression coefficient
表4. 新能源汽车销量增长率三元线性回归得到的系数
首先将得到的系数代入拟合关系式
,得到具体表达式如下所示:
再将图6~图8中的三个拟合表达式代入到回归得出表达式中,得到如下新能源汽车与新能源汽车的生产量
、传统汽车的生产量
、传统汽车的需求量
的关系式:
同上述模型求解过程,三元线性回归得到的结果如表5所示:
Table 5. The traditional car sales growth rate is the result of three linear regression
表5. 传统汽车销量增长率三元线性回归得到的结果
得到结果的拟合优度R2为0.6659,观测值拟合效果较好;F值为23.78较大,表明比较符合线性关系;P值为0.0002,故置信区间达到99.98%以上,表明拟合结果好。以新能源汽车的生产量
、传统汽车的生产量
、传统汽车的需求量
为自变量,传统汽车的增长量
为因变量,得到表达式为:
各变量的系数如表6所示:
Table 6. The coefficient of traditional car sales growth rate by ternary linear regression
表6. 传统销量汽车增长率三元线性回归得到的系数
首先将得到的系数代入拟合关系式
,得到:
再将图6~图8中的三个拟合表达式代入回归得出表达式中,得到如下新能源汽车与新能源汽车的生产量
、传统汽车的生产量
、传统汽车的需求量
的关系式:
将
和
的图像在Matlab R2021a中在同一个图窗画出如图7所示。
由上图可知,拟合改进前得出的新能源汽车和传统汽车的保有量明显可看出其拟合出来的曲线是不符合实际情况的,拟合存在问题,故在后续需要对对操作步骤进行改进。
在改进得到拟合曲线的过程中,操作步骤与拟合改进前的操作步骤一致,只是进行如下改进。首先在改进拟合后,不是使用万辆作为数据的单位,而是选用辆作为数据的单位。其次,使用指数拟合做出新能源汽车产量的拟合图;使用二阶多项式做出传统汽车产量、市场汽车需求量关于年份的拟合图,最终得到的折线图和拟合曲线中,其他的拟合图以及拟合曲线都没有变化,仅新能源汽车产量与年份的拟合图有所变化,如图8所示。
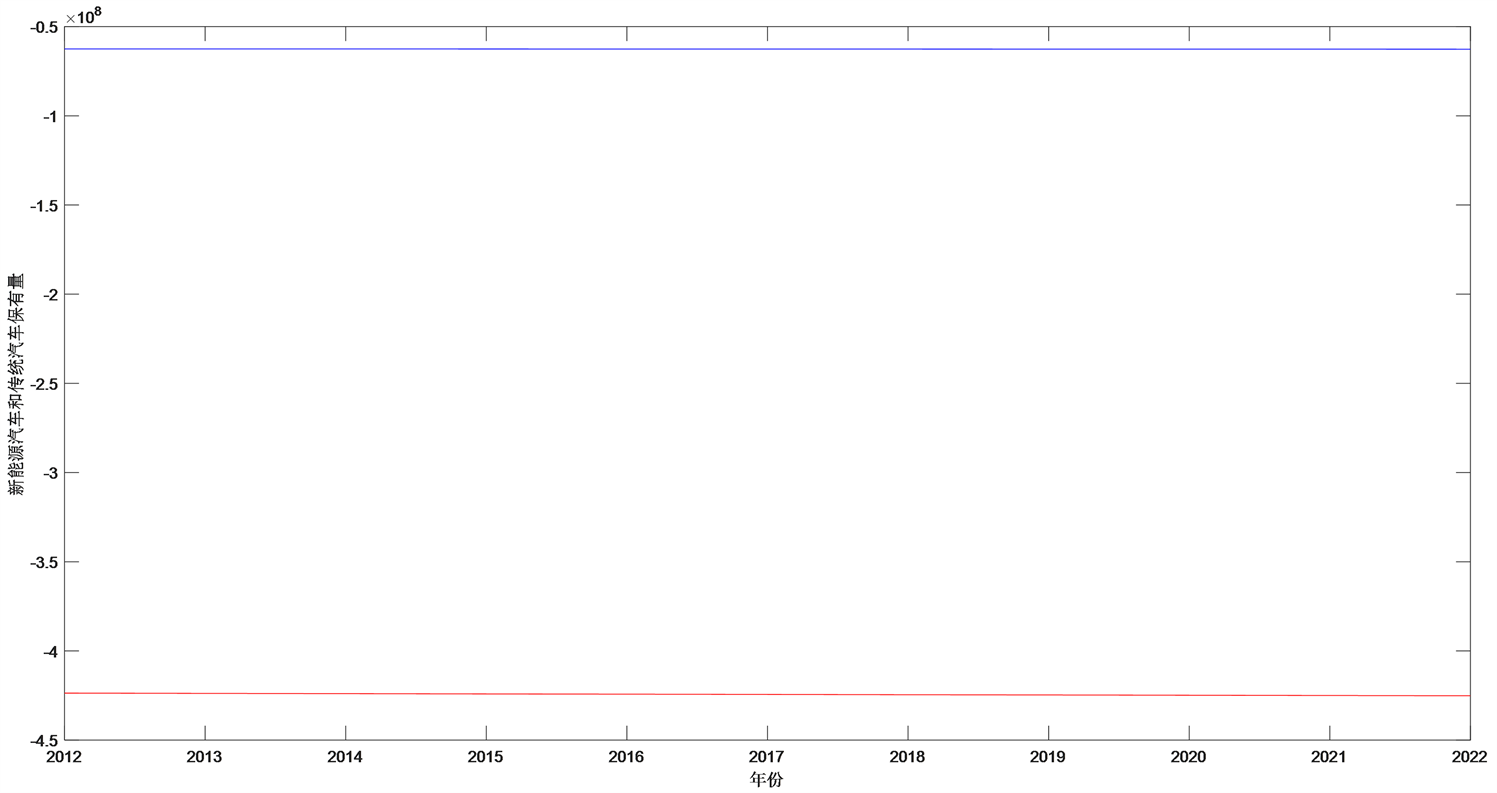
Figure 7. The previous d1(t) and d2(t)’s fitting curve images were improved
图7. 改进前d1(t)和d2(t)的拟合曲线图像

Figure 8. The fitting graph of the relationship between production of new energy vehicles and time
图8. 新能源汽车产量与年份关系拟合图
在改进当使用Stata 16 SE进行回归分析时,不直接使用三元线性回归模型,而是改成使用三次一元线性模型得到新能源汽车销量的拟合结果如表7所示:
Table 7. New energy car sales growth after the improvement of fitting analysis results
表7. 新能源汽车销量增长拟合改进后得到的分析结果
以此得到的新能源产量、传统产量、需求量这三个变量的拟合优度R2分别为0.9441、0.0740、0.1126,可知新能源产量与新能源销量增长的相关程度最大;F值分别为168.85、0.80、2.77主要变量的F值很大,说明十分符合线性关系;P值分别为0.0000、0.3922、0.1268,主要变量的P值为0.0000 < 0.0001,故置信区间达到99.99%以上,说明本次拟合结果好。得到的各变量系数如表8所示:
Table 8. The improved new energy car sales growth rate of the ternary linear regression coefficient
表8. 改进后新能源汽车销量增长率三元线性回归得到的系数
同理,在使用线性回归求解传统汽车销量的拟合结果时,也把三个变量求解,得到的结果如表9所示:
Table 9. The analysis results are obtained after the improvement of traditional car sales growth fitting
表9. 传统汽车销量增长拟合改进后得到的分析结果
得到的新能源产量、传统产量、需求量的拟合优度R2分别为0.5175、0.0328、0.0817,可知新能源产量与传统汽车销量增长的相关程度最大;F值分别为34.62、0.42、1.38主要变量的F值较大,说明比较符合线性关系;P值分别为0.0002、0.5326、0.2680,主要变量的P值为0.0002 < 0.0003,故置信区间达到99.97%以上,说明本次拟合结果好。得到的各变量系数如表10所示:
Table 10. The improved new energy car sales growth rate of the ternary linear regression coefficient
表10. 改进后新能源汽车销量增长率三元线性回归得到的系数
最后,将得到的两组数据分别结合三个拟合曲线,得到如下两个新的表达式:
因较大数据计算后会超过Matlab所允许的数据范围,故在使用Mablab R2021a画新能源汽车产业和传统汽车产业的增长率对比图时需要将横坐标年份的数据减去2010以修正,使得区间变为[0, 16],在软件中画出改进后的新能源汽车和传统汽车增长率对比图,如图9所示:

Figure 9. The improved d1(t) and d2(t) fitting curve images
图9. 改进后d1(t)和d2(t)的拟合曲线图像
综合上文分析不难发现,新能源汽车保有量的相关影响因素众多,指标之间的重复性会导致输入样本数据信息的大量重叠。中国新能源汽车市场形成了传统车企与新势力车企共同投资建设及相互竞争的格局。新能源汽车产业保有量逐年升高,且每年增长量都有所增高,保持较高的增长速度;虽然传统汽车产业保有量也逐年升高,但每年增长量增高不大,保持较低甚至负的增长速度,故新能源汽车和传统汽车之间存在竞争关系。
3. 基于GM(1,1)模型长三角地区新能源汽车保有量预测
3.1. GM(1,1)灰色预测模型的建立
灰色预测是一种对含有不确定因素的系统进行预测的方法,有助于解决样本数量少、数据信息少和信息不完整等不确定的问题 [5] 。灰色预测GM(1,1)模型首先是利用随机原始离散非负的数据列,通过一次累加的方式得到新的离散数据列,建立相应的微分方程模型,用一阶线性微分方程的解来逼近时间累加后形成的新时间序列所呈现的规律。它通过一个序列即可进行计算,是一阶线性的动态模型 [6] 。建立GM(1,1)灰色预测模型的具体过程如下:
首先,假设
为非负序列,并根据已有的数据构建最初的数据序列:
对于上述表达式,有
。
再将建立的数列进行一次累加,生成如下所示的累加数据序列:
其中,
。
其次,对累加生成的序列进行处理,得出的紧邻均值生成序列为:
式中,
。
定义灰色微分方程(近似微分方程)的表达式如下:
构建白化方程,表达式如下:
使用最小二乘法的思想,对参数a和参数b进行估计,得到:
得到最终的GM(1,1)模型的时间响应表达式如下:
其中,
。
还原值为:
该模型的预测结果是否可取需要进行下述检验,计算公式如下:
绝对残差:
相对残差:
平均相对残差:
精度:
原始序列均方差:
残差序列均方差:
方差比:
3.2. 利用GM(1,1)模型进行预测
仅有8个数据样本,且预测未来三年长三角地区新能源汽车保有量为短期预测,而灰色预测模型正好适合样本少,短期预测问题的运用。公安部发布的长三角地区历年新能源汽车保有量的数据如表11所示:
Table 11. New energy car ownership scale of Yangtze River Delta from 2015 to 2022
表11. 2015年~2022年长三角地区新能源汽车保有量表
根据3.1中建立的GM(1,1)预测模型,利用最小二乘法,使用PyCharm Community Edition软件求解得到:
得到的长三角地区新能源汽车保有量数据序列X的预测模型为:
最终得到长三角地区新能源汽车保有量的模拟数据,以及模拟数据和实际保有量的比较值,如表12所示:
Table 12. GM(1,1) prediction model compares the simulated data and the actual data of the Yangtze River Delta new energy car ownership
表12. GM(1,1)模型对长三角地区新能源汽车保有量模拟数据与实际数据对比
下面对预测的结果进行精度检验,得到的计算结果如下所示:
平均相对残差:
精度:
方差比:
该模型的精度大于84%,因此预测的结果比较合理。通过实际统计数据和模拟数据的对比处理可以看出,新能源汽车保有量的模拟数据和实际数据最大偏差不超过26%,精准度可达84%以上,方差比预测精度为一级,充分说明GM(1,1)预测模型预测精度较好,能够应用于新能源汽车保有量预测。
将k = 9,10,11代入预测模型
,得到全国范围内未来3年的新能源汽车保有量,如表13所示:
Table 13. Predicted number of Yangtze River Delta new-energy vehicle ownership in 2023~2025
表13. 2023~2025年长三角地区新能源汽车保有量预测值
画出的2015年到2025年的长三角地区新能源汽车保有量曲线图如图10所示:

Figure 10. A forecast figure of new-energy car ownership in the Yangtze River Delta from 2015 to 2025
图10. 2015年到2025年的长三角地区新能源汽车保有量预测图
从上图可以看出,长三角地区新能源汽车的发展从初期的缓慢增长逐步迈入快速发展时期,且增速逐渐加快。根据现有的预测结果充分说明长三角地区新能源汽车产业有巨大的发展空间 [7] 。
4. 基于赋权改进的拟合曲线实现双碳时间预测
碳达峰是指我国承诺在2030年以前,不再增长二氧化碳的排放量,达到排放峰值之后再逐步降低。碳中和是指企业、团体或个人测算在一定时间内直接或间接产生的温室气体排放总量,然后通过植物造树造林、节能减排等形式,抵消自身产生的二氧化碳排放量,实现二氧化碳“零排放”。在查询相关文献后,分析可知碳排放量与各能源消耗量以及该地区森林覆盖面积均有关,收集到的各能源消耗量、森林覆盖面积如表14所示:
Table 14. Table of data on energy consumption and forest cover
表14. 各能源消耗量和森林覆盖面积数据表
在计算碳排放量时,必须转化成标准统计量,参照《中国能源统计年鉴》给出的具体换算系数 [7] ,如表15所示:
Table 15. Table of conversion coefficient between each energy source and standard coal
表15. 各能源与标准煤换算系数表
各种能源的碳排放系数,如表16所示:
Table 16. Table of carbon emission coefficient of each energy source
表16. 各能源碳排放系数表
设煤炭、石油、天然气、电能这四种能源的消耗量分别用
表示,其对应的系数(换算系数*碳排放系数)为
,则碳排放总量的计算公式为:
利用能源消耗量、能源与标准煤换算系数、碳排放系数得到表17所示的长三角地区碳排放量数据:
Table 17. Data table of carbon emissions and total carbon emissions from energy sources in Yangtze River Delta
表17. 长三角地区各能源碳排放量及总体碳排放量数据表
分别作出原油、天然气、电能等关于年份的拟合图先如下图12~图14所示:
从图11可知,原油碳排放量表达式与时间拟合曲线为:

Figure 11. The fitting diagram of crude oil carbon emission and time in Yangtze River Delta
图11. 长三角地区原油碳排放量与时间拟合图
从图12可知,天然气碳排放量表达式与时间拟合曲线:

Figure 12. The fitting diagram of natural gas carbon emission and time in Yangtze River Delta
图12. 长三角地区天然气碳排放量与时间拟合图
从图13可知,电力碳排放量与时间拟合曲线:

Figure 13. Power carbon emission and time fitting graph in Yangtze River Delta
图13. 长三角地区电力碳排放量与时间拟合图
由于煤炭的折线图中存在着一个向上较为突出的孤立点,所以在此处引入拟合修正因子,分别作出线性拟合曲线和二阶多项式拟合曲线,结果如图14和图15所示:

Figure 14. Linear fitting diagram of coal carbon emission and time in Yangtze River Delta
图14. 长三角地区煤炭碳排放量与时间线性拟合图
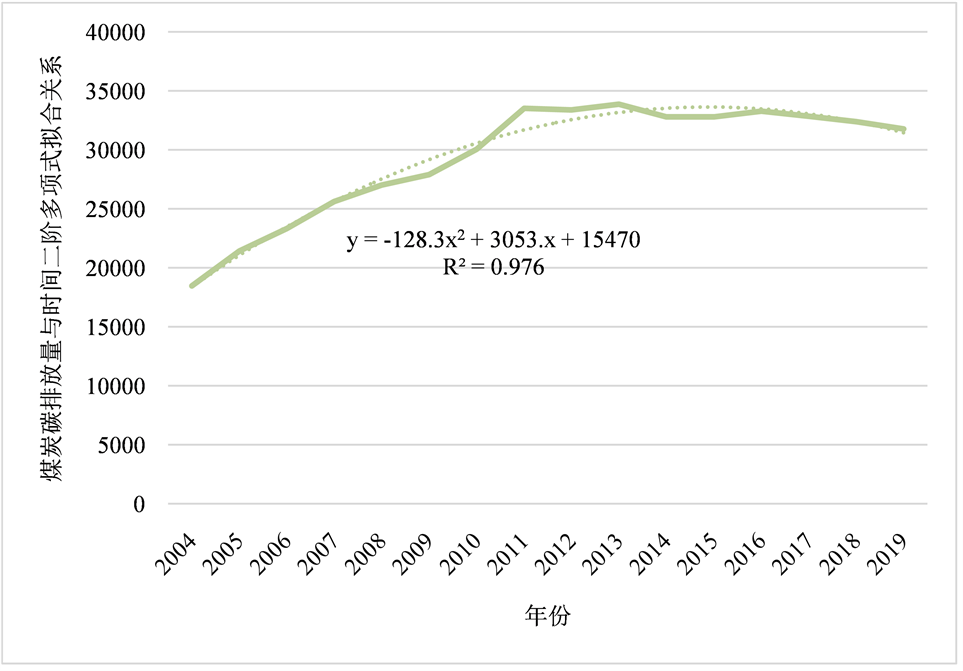
Figure 15. Second order polynomial fitting diagram of coal carbon emission and time in Yangtze River Delta
图15. 长三角地区煤炭碳排放量与时间二阶多项式拟合图
经过分析可知,线性拟合曲线拟合优度为0.7155,提供向上的修正量;二阶多项式拟合曲线拟合优度为0.9769,提供向下的修正量。由于折线图上存在一个向上突出的偏差点,所以需要向上修正,才能得到最精确的拟合曲线。提供分析,已经综合考虑其他影响因素,最终给线性拟合曲线赋权值0.3,给二阶多项式拟合曲线赋权值0.7,得到的最终拟合曲线为:
将
四个表达式相加,使用Matlab R2021a画出碳排放量关于时间的拟合曲线如图16所示:

Figure 16. Prediction of fitting curve of carbon emission in Yangtze River Delta
图16. 长三角地区碳排放量拟合曲线预测图
从国家统计局的《中国统计年鉴》中收集关于长三角地区三省一市和总体的碳吸收量,数据如表18所示:
Table 18. Table of carbon absorption coefficient in Yangtze River Delta region
表18. 长三角地区碳吸收量系数表
作出长三角地区碳吸收总量关于年份的散点图,如图17所示。
因长三角地区碳吸收量关于年份变化不大,加上考虑到实际情况下森林等碳吸收量变化不大,为了简化模型,取均值727.5万吨为每年的碳吸收量。得到的长三角地区碳净排放量如图18所示。
所以由图16和图18可知,长三角地区预测在2029年实现碳达峰,在2061年实现碳中和。

Figure 17. Scatter plot of total carbon uptake in Yangtze River Delta region with respect to year
图17. 长三角地区碳吸收总量关于年份的散点图
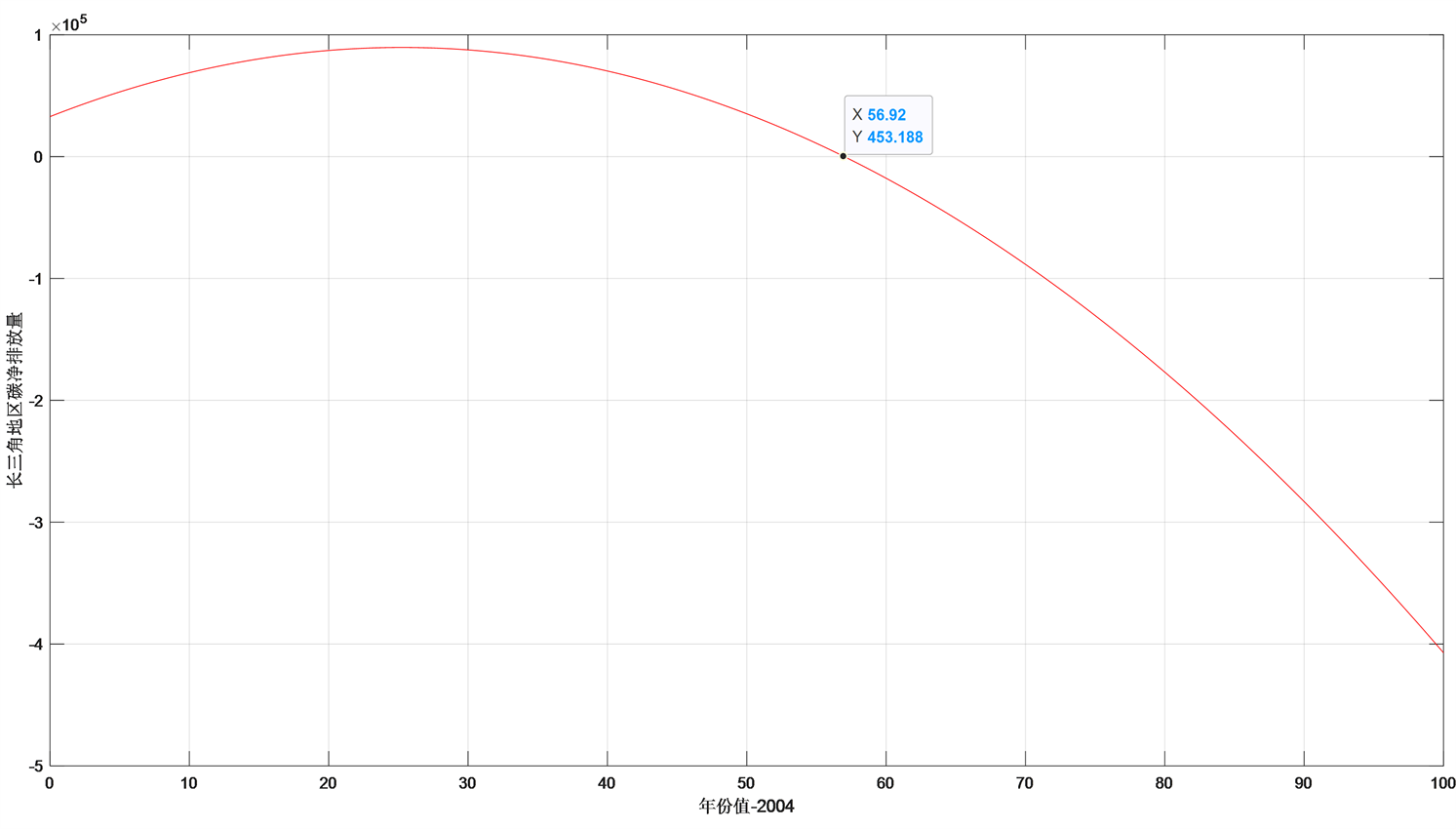
Figure 18. Fitting curve of net carbon emission in Yangtze River Delta
图18. 长三角地区碳净排放量拟合曲线图
5. 结语
使用描述统计分析模型,利用2011~2020年长三角地区及全国新能源汽车产量数据,画出逐年对比图,可知近5年来长三角区域新能源汽车产量占全国范围内新能源汽车产量的比重总体呈现逐年增长的趋势,说明长三角地区新能源汽车产业在全国的影响和作用越来越大;每一年长三角区域新能源汽车比全国新能源汽车的增长率都要高,说明长三角区域新能源汽车产业总体发展速度比全国新能源汽车产业的发展速度要快。
通过理想状态的假设,逐渐增加影响因素进行推导,分析2010~2022年长三角地区新能源汽车与传统汽车的生产量和销售量,以及市场的汽车需求量,使用二阶线性回归得到新能源汽车产量、传统汽车产量和汽车需求量关于年份的拟合表达式。首先直接使用SPSS进行三元线性回归,得到新能源汽车销量与新能源汽车产量、传统汽车产量、汽车需求量这三个自变量的关系,再代入其关于年份的拟合式,得到初版的竞争模型,使用三次一元拟合回归分别得到新能源汽车销量与新能源汽车产量、传统汽车产量、汽车需求量的三个拟合关系式,并将三个自变量与年份的拟合式代入,从优化后新能源汽车和传统汽车的拟合曲线,得到中国新能源汽车市场形成了传统车企与新势力车企共同投资建设及相互竞争的关系。
建立GM(1,1)灰色预测模型,根据2015~2022年长三角地区新能源汽车保有量的数据,预测2023~2025年长三角地区新能源汽车保有量。通过对煤炭、原油、天然气、电能这四种能源对年份的拟合进行赋权改进,得到长三角地区将于2029年实现碳达峰,2061年实现碳中和。