1. 引言
自21世纪以来,人类便开始逐渐步入数字信息化时代,人们周围始终存在着海量数据,这些海量数据中隐藏着有待发掘的关键信息,对人们进行决策起到一定的支撑作用。在此背景下,数据分析与挖掘技术逐渐地被广泛应用到经济社会发展中,其产生和发展就是为了帮助人们更好地利用这些海量数据,并从中发现并利用数据中潜藏的有用信息。
基于这种背景,本文主要运用数据分析与挖掘技术对科技创新绩效进行分析,挖掘其中隐藏的运行模式,并对未来两年的科技创新绩效进行预测,希望能够帮助政府部门在制定科技创新相关决策时提供理论依据,合理制定科技创新政策,优化创新资源的投入和要素的分配。
2. 研究设计
2.1. 背景与研究目标
在知识经济时代的今天,创新逐渐变成驱动经济发展的重要源泉。现阶段科技创新越发重要,创新主体已从企业发展为政产学研用多主体协同的新阶段。创新能力是推动国家经济社会可持续发展,和经济结构逐步优化的重要支撑,是国家综合竞争力的本质所在 [1] 。根据相关统计,科技创新在发达国家的经济发展中扮演着决定性作用,大大超过了劳动和资本要素投入的贡献率;相较于发达国家,发展中国家经济发展水平较低,相应的科技创新贡献率比发达国家低 [2] 。因此,提高科技创新投入、加强科技创新能力、增强科技创新绩效,对于发展中国家而言,是十分必要的。
因此,本项目将采用2000年至2019年期间由《中国科技统计年鉴》收录的数据资料,进行分析:
1) 对科技创新绩效的相关影响属性进行分析,识别关键因素;
2) 预测2020年和2021年的科技创新绩效。
2.2. 分析步骤与流程
本项目的数据分析与挖掘方法主要参考CRISP-DM数据分析模型流程 [3] ,该模型将数据处理过程分为6个步骤:业务理解(Business Understanding)、数据理解(Data Understanding)、数据准备(Data Preparation)、建立模型(Model Building)、评估(Testing and Evaluation)和部署(Deployment),具体如图1所示。
因此,本项目主要包括以下步骤:
1) 采用探索性分析方法处理原始数据,厘清原始属性彼此的相关性;
2) 利用Lasso特征选择模型提取影响因素中的关键属性;
3) 综合灰色预测方法、支持向量机预测模型,建立组合预测模型;
4) 运用建立的预测模型,拟合2020年和2021年科技创新绩效的期望预测值。
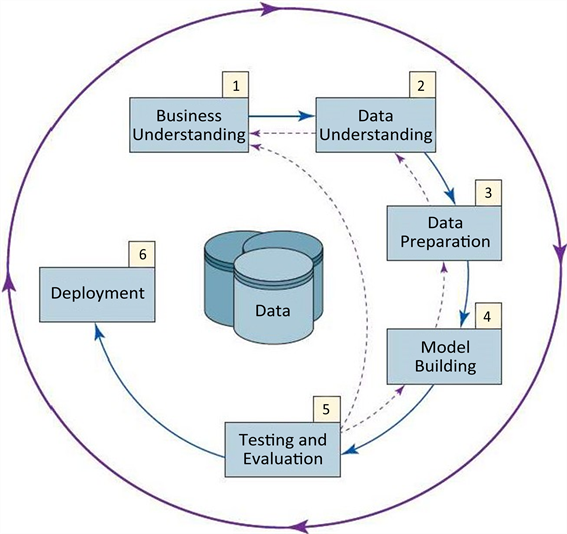
Figure 1. CRISP-DM data analysis process
图1. CRISP-DM数据分析过程
3. 科技创新绩效影响因素分析
3.1. 变量解释
影响科技创新绩效(y)的因素有很多,在阅读大量的相关文献 [4] - [10] 后,通过创新管理理论对创新绩效的解释以及对实际情况的观察,考虑了一些与资源消耗关系密切且有相关关系的因素,初步选取以下属性为自变量,分析他们之间的关系各项属性名称及属性说明如下表1所示。

Table 1. Property name and description
表1. 属性名称和说明
3.2. 描述性统计分析
首先,对各个属性对象的描述性统计分析结果见表2所示。其中科技创新绩效(y)的均值和标准差分别是912,541.95和796,991.97,这说明中国各年份科技创新绩效存在巨大差异;自2011年后,各年份科技创新绩效提升幅度比较大。
Table 2. Descriptive statistics for each attribute
表2. 各个属性的描述性统计
3.3. 相关性分析
通过运用Pearson相关系数方法求出原始创新绩效数据的Pearson相关系数矩阵。因此,对原始数据经过相关性数据分析后得到所有属性之间相关系数矩阵如下表3所示。
Table 3. Pearson correlation coefficient matrix for each variable
表3. 各变量Pearson相关系数矩阵
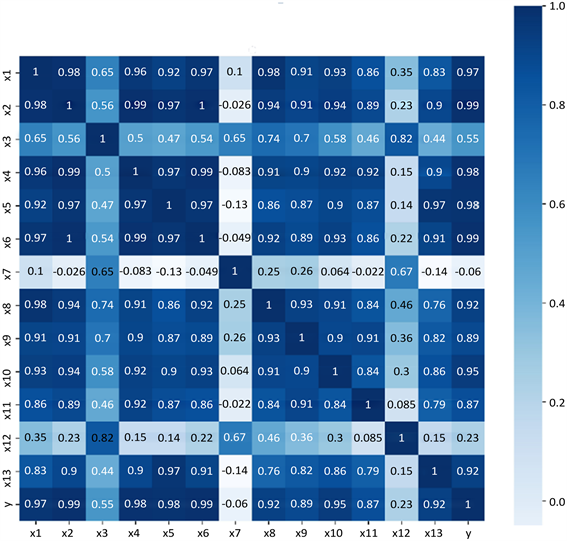
Figure 2. Correlation heat map of each variable
图2. 各变量相关性热力图
根据表3可知,国家科技奖项(x7)与科技创新绩效(y)的线性关系不显著,呈现负相关关系。其余变量与科技创新绩效呈现正相关关系,按照相关系数大小排列,依次是x2、x6、x4、x5、x1、x10、x8、x13、x9、x11、x3和x12。同时,各变量彼此之间的多重共线性现象较为严重,例如,属性x2和x6之间保持着完全一致的共线性;x1与除了x3、x7、x12外的其他变量存在着严重的多重共线性;x7与各个变量的共现性不明显;x4与除了x7、x12之外的其他变量有严重的共线性。
通过上述分析可知,选取的各个变量除了x7外,其他变量与y的相关性较强,可以用作科技创新绩效预测分析的关键变量,但这些变量之间存在着一定的信息重复,需要对变量再做更深一步的筛选分析。如图2所示,根据颜色深浅的程度可看出各个变量除了x7与y为负相关之外,其他变量与y存在着一定的相关性。
4. 预测模型构建
4.1. 科技创新绩效关键因素识别
Lasso回归法属于压缩估计的正则化方法之一。它通过构建惩罚函数得到一个更精炼的模型,使其在设定某些系数为零的同时压缩某些系数,保留了子集收缩的优点,是一种有偏估计范畴的处理复共线性数据的方法。
当多重共线性存在于原始数据特征中时,Lasso回归可以被视为处理共线性的有效方法,可以有效地筛选多重共线性存在的数据属性。面对海量的数据,信息降维可以用尽可能少的数据来解决问题,用Lasso模型选择特征属性也是信息降维的一种有效方法。Lasso模型在理论上对数据类型的限制并不多,任何类型的数据都可以采用,同时一般无需对数据进行标准化处理。
Lasso回归法的优点在于能够很好地弥补最小二乘法和逐步回归方法对于局部最优估计的缺失,可以很好地识别特征数据,同时有效解决多重共线性存在于多个个特征之间的问题。缺点是若有一组相关度较高的数据出现时,Lasso回归倾向于在其中选择一个显著的特征数据而忽略了所有其他数据,这样的情形会造成结果的不稳定。虽然Lasso回归方法有如此弊端,但在合适的场景下依然能展现满意的效果。本文研究数据中同样存在一定的多重共线性,运用Lasso回归方法识别关键特征属性是必要的步骤。
使用Lasso回归进行关键属性选取,结果见表4所示,得到各个属性的系数。由表4可知,利用Lasso回归方法识别影响科技创新绩效的关键影响因素是研究与试验发展(R&D)人员全时当量(x1)、研究与试验发展(R&D)经费内部支出(x2)、科技拨款占公共财政支出的比重(x3)、税收(x4)、按技术合同构成分全国技术市场成交合同金额(x5)、研究与开发机构机构数(x6)、国家科技奖项(x7)、高技术进出口贸易总额合计(x8)、国际科技合作项目(x10)、平均每万名职工中专业技术人员(x11)、商标注册(x13)。
Table 4. Coefficients of each variable
表4. 各变量系数表
4.2. 建立预测模型
4.2.1. 灰色预测模型
灰色预测法是对包含不确定因素的复杂系统的拟合预测的一种方法。在适用灰色预测模型前,需要对原始数据序列进行数据变换处理,处理后的数据序列称为生成列。累加和累减两种数据处理方式是灰色预测常用的处理方式。
灰色预测以灰色模型为基础,GM(1,1)模型是众多灰色模型中使用频率最高的。其检验模型精度的后验差标准如表5所示。
Table 5. Reference table for post-test difference test
表5. 后验差检验参照表
灰色预测模型具有很强的通用性,适用于多数的时间序列场景,拟合表现不错,特别适用于对数据产生机理不明确且规律性较差的情况。该模型的优点是预测精度高,模型精度可验证,参数估计方法简单,对小数据集的预测效果很好;缺点是对原始序列的数据平滑度要求较高,灰色预测模型在原始序列的平滑度不佳的情况下,拟合预测精度不高,甚至无法通过方差检验,导致只能放弃使用灰色预测模型。
4.2.2. 支持向量机回归模型
SVR (Support Vector Regression,支持向量回归)是在做拟合时,采用了支持向量的思想,来对数据进
行回归分析。给定训练数据集
,其中
。对于样本
通常根据模型计算的
与实际值
的差异度来衡量损失,当且仅当
时计算损失为零。SVR的基本思路可以描述为:允许
与
至多存在
的偏差。只有当
时,才认为有损失。当
时,认为预测准确。
由于支持向量机具有相对完善的理论基础以及良好的特性,在分类、回归、聚类、时间序列分析、异常点检测等众多应用方向,人们对该模型的研究和应用都非常广泛。具体研究包括统计学习的理论基础,建立各种模型,改进模型对应的优化算法,以及实际应用等方面的内容。
相比较于其他方法,支持向量回归的好处在于:既适合线性模型,又能很好地把握非线性关系的数据与特征;避免局部极小化问题,提高泛化性能,解决高维度问题,而无需担心多重共线性问题;虽然过程中不会直接排除异常值,但会让异常引发较小的偏差。缺点是在面对数据资料的数据量巨大时,计算复杂度较高,且耗时较长。
5. 预测模型的实证研究
基于Lasso回归,选取研究与试验发展(R&D)人员全时当量(x1)、研究与试验发展(R&D)经费内部支出(x2)、科技拨款占公共财政支出的比重(x3)、税收(x4)、按技术合同构成分全国技术市场成交合同金额(x5)、研究与开发机构机构数(x6)、国家科技奖项(x7)、高技术进出口贸易总额合计(x8)、国际科技合作项目(x10)、平均每万名职工中专业技术人员(x11)、商标注册(x13)变量,通过灰色预测模型得出这些变量2020年和2021年的预测期望值,见表6。
基于表6的预测结果,将其代入科技创新绩效的支持向量机回归预测模型,得到2020年至2021年科技创新的预测值,如下表7和图3所示,其中y_pred表示科技创新绩效的预测值。
Table 6. Predicted values of each variable
表6. 各变量预测值
Table 7. Projections of STI from 2000 to 2021
表7. 2000年至2021年科技创新的预测值

Figure 3. Comparison of real and predicted values of STI performance
图3. 科技创新绩效真实值与预测值的对比
根据灰色预测模型和支持向量机模型的预测结果,可以得出,该模型的组合预测方法对科技创新绩效的拟合与预测表现较好,模型的精度较高,能够一定程度上反映科技创新绩效的发展方向。
6. 结论
从科技创新绩效的发展历程和预测结果来看,我国科技创新绩效发展较为稳健,自2005年开始保持高水平的增长态势,科技创新活力十足。2010年以后,科技创新绩效波动较大,在科技创新发展步伐放缓的阶段,科技创新投入的力度加大和科技创新的高质量转型,是推动科技创新能力升级的主要动力源。结合2020年和2021年的预测结果,未来我国科技创新绩效继续较高速率的增长,整体发展形式稳中向好,因此应当不断增强政府的政策引导和策动作用,激发科技创新动力,拓宽科技创新空间,为科技创新能力的发展提供坚实的基础。
本研究的主要成果和不足:通过分析我国科技创新绩效的影响因素,构建识别和预测模型,对我国科技创新的发展进行量化分析,预测其未来发展趋势。但由于数据统计的滞后性,对长远阶段的预测精度不够,后续可以通过分析区域性、季度性数据,提高模型对于未来期望的预测和指导力度。