1. 引言
近年来,建筑向着更高更柔的趋势发展,风对建筑的影响也越来越大。根据风荷载功率谱和相干函数可以构造风荷载功率谱密度矩阵,由模态变换得到广义力功率谱密度矩阵,从而计算高层建筑结构的响应和等效风荷载 [1]。因此对基底力矩功率谱的研究是具有重大意义的。近些年来,许多研究学者对高层建筑的风荷载基底力矩功率谱进行了大量的研究 [2] - [8]。风洞试验和计算流体动力学是研究高层建筑基底力矩功率谱两种最常用的方法,然而风洞试验花费的成本较大,计算流体动力学的计算时间较长。因此,运用一种新的方法来研究高层建筑的基底力矩功率谱是极具意义的。
在计算机技术不断发展的今天,人工智能在人们日常生活中随处可见。而机器学习是人工智能的核心,能够让计算机从大量的数据中找出隐藏的规律,从而做出准确的预测。机器学习一经问世就被广泛应用于许多工程领域 [9] [10] [11] [12]。近些年来,一些研究学者开始将机器学习运用在风工程领域中。Hu & Kwok [13] 运用了机器学习中的三种算法去预测圆柱体表面的风压,结果表明梯度提升回归树算法能够很好地预测圆柱体的平均风压和脉动风压。Lin等 [14] 采用了机器学习中的五种算法去评估矩形圆柱体的侧风振动,结果显示梯度提升回归树算法能够很好地预测侧面矩形圆柱体的侧风响应。尽管如此,机器学习在风工程领域的运用还处在初步阶段,而且以往机器学习在风工程领域的应用案例并不具备代表性。CAARC高层建筑标准模型是由英联邦咨询航空研究委员会(CAARC: Commonwealth Advisory Aeronautical Research Council)提出的 [15],已被公认为不同风洞实验室验证风场模拟的基准模型 [16] [17] [18]。为了将机器学习应用于代表性模型来预测风效应并验证不同机器学习算法的可行性,本研究将CAARC高层建筑标准模型作为基准模型,通过三种不同的机器学习算法对高层建筑的风荷载功率谱进行预测。
2. 数据收集
为了获取大量的高层建筑标准模型风荷载功率谱数据集用于机器学习模型的训练和测试,本研究对高层建筑标准模型进行了大量的风洞试验。风洞试验中用到的模型的缩尺比为1:300,缩放后的尺寸为101.6 mm (深度) × 152.4 mm (宽度) × 609.6 mm (高度),图1给出了缩尺后的CAARC高层建筑标准模型的尺寸和测量层的分布。试验模型沿高度方向共有七个测量层,每个面都有五个测点,因此每个测量层总共有20个测压点,每个测量层的详细测点分布如图2所示。
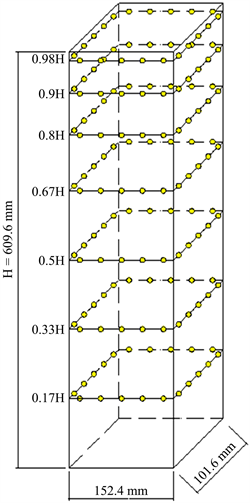
Figure 1. Dimension of CAARC standard tall building model and the distribution of measurement layer
图1. CAARC高层建筑标准模型尺寸图和测点层分布图
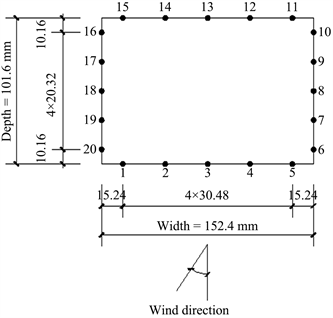
Figure 2. Measurement point distribution of the measurement layer
图2. 测点层的测点分布图
在风洞中模拟了中国荷载标准规范 [19] 中规定的四类地貌的风场条件,风洞转台上方不同高度的平均风速剖面图和湍流强度剖面图如图3所示,可以看出。四种不同地貌类别的平均风速剖面和湍流强度剖面与在设计规范中规定的一致。表明了风洞试验的准确性。
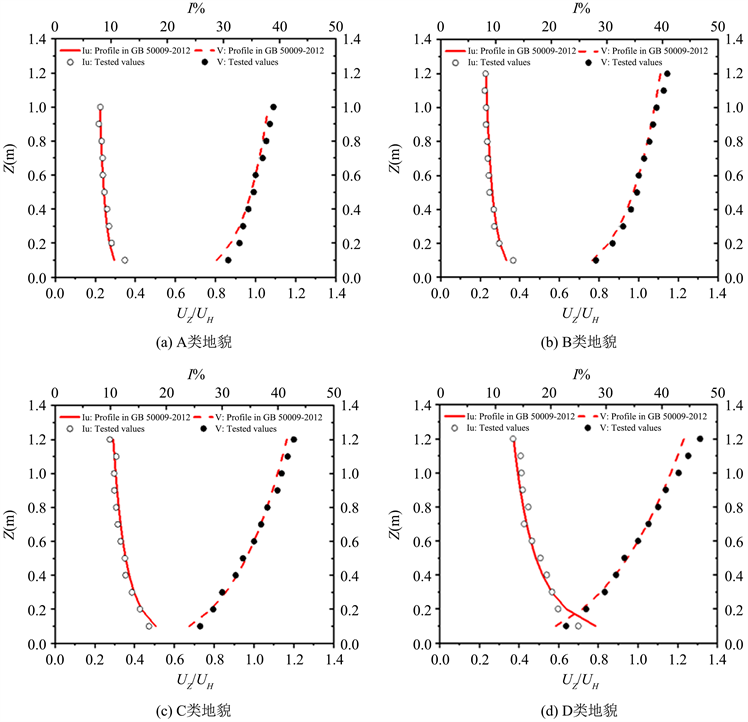
Figure 3. Mean wind speed profiles and turbulence intensity profiles
图3. 平均风速剖面和湍流强度剖面
因为CAARC高层建筑标准模型是一个对称的模型,所以进行风洞试验时角度的变化范围是从0度到90度,每隔5度进行角度的变化。为了获得大量的功率谱数据,在每个风向角度下对四种地貌类别都分别单独测量了100次。因此,本研究通过风洞试验收集到了53,200组关于不同地貌类别、风向角和不同测量层高度的CAARC高层建筑标准模型的风荷载功率谱数据。
为了验证机器学习模型的可行性,需要将得到的数据集划分成训练集和测试集。Hu等 [20] 将80%的数据集去训练机器学习模型,其余20%的数据集用于测试机器学习模型的性能。因此,本章同样将80%的数据集去训练机器学习模型,其余20%的数据集用于评估机器学习模型的性能。
3. 机器学习算法和超参数优化
本研究将采用三种机器学习算法包括:梯度提升回归树、XGBoost和直方图梯度提升回归树去预测高层建筑标准模型风荷载基底弯矩功率谱。本研究的机器学习模型的输入为风向角、湍流强度还有折算频率,输出是顺风向基底弯矩功率谱、横风向基底弯矩功率谱和扭转向基底弯矩功率谱。
3.1. 超参数选取方法
3.1.1. 交叉验证
优化训练模型的超参数是非常有必要的,只有选取了模型的最佳超参数才能实现机器学习模型的最佳性能 [21]。为了选取最优的超参数同时避免超参数优化过程中的过拟合问题,通常采用交叉验证的方法去选取机器学习的最优超参数。交叉验证可以解决如何划分数据集的问题,提供了一种可靠的评估模型性能的方法 [22]。在本研究中,K折交叉验证方法用于选取机器学习模型的最佳超参数。K-fold交叉验证方法将数据集分成K个相同数据大小的数据集,选择其中的一个数据集用于评估模型的性能,其余K-1个数据集用于训练模型。这个过程会进行多次,以避免随机抽样造成的偏差 [23]。K折交叉验证的最终估计值是通过对交叉验证进行平均而得到的 [24],如图4所示。K的值将影响交叉验证的性能,Refaeilzadeh等 [25] 建议K等于10,这是一个实践中效果最好的数值。因此,本研究使用10折交叉验证方法来评估机器学习算法的超参数。
3.1.2. Tree-Structured Parzen Estimator
与其他超参数优化方法相比,Tree-structured Parzen Estimator (TPE)寻找超参数的最优值表现出更好的性能 [26],并且不会受到需要优化的参数数量的影响 [27]。因此,本研究以10折交叉验证的均方误差为目标函数,利用Tree-structured Parzen Estimator优化方法寻找10折交叉验证均方误差最小的参数即为最优超参数。
作为贝叶斯优化的一种变体,Tree-structured Parzen Estimator将超参数空间分为两组,即好的超参数和坏的超参数 [28],如下所示:
(1)
其中
是一个设定的值;y是目标函数的值;
和
分别表示超参数为好和坏的概率。在每次迭代中,Tree-structured Parzen Estimator将最大化等式(2)中定义的预期改进(EI)。当预期改进达到最大值时,获得的超参数即为最优超参数。
(2)
3.2. 梯度提升回归树
梯度提升回归树算法是一种boosting集成学习方法,如图5所示。梯度提升回归树的工作原理是新的弱学习器可以获得前一个弱学习器学习到的经验,新的弱学习器会不断减少真实值与预测值之间的残差 [29]。与线性模型相比,梯度提升回归树模型可以更灵活地对输入特征进行非线性和交叉变换,预测精度较高。
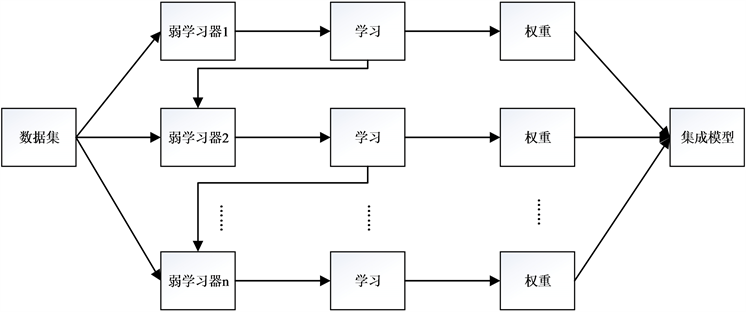
Figure 5. The boosting ensemble learning method
图5. Boosting集成学习方法
梯度提升回归树算法有一个称为学习率的参数,决定了每个弱学习器对最终模型的贡献,最终模型的预测结果是弱学习器的预测结果乘以学习率的总和 [30]。梯度提升树的另外两个重要的超参数是树的最大深度(max_depth)和决策树的数量(n_estimators),这三个参数通过Tree-structured Parzen Estimator 和10折交叉验证的方法优化,三个参数取值见表1。表中的logunniform表示搜索空间是对数均匀的,uniform表示搜索空间是连续均匀的。

Table 1. Hyper-parameters of gradient boosting regression tree model
表1. 梯度提升回归树模型的超参数
3.3. XGBoost
XGBoost是一种基于梯度提升回归树的改进算法,目的是提高计算效率和模型的灵活性 [31]。XGBoost会对模型进行一定的惩罚,同时对函数进行泰勒展开,可以降低模型的方差和复杂度 [32]。XGBoost算法可以表示为 [33]:
(3)
上式中
是XGBoost的目标函数;
用来衡量预测值和实际值之间差异;
表示惩罚模型复杂度的正则化,其计算公式如下:
(4)
式中T是决策树中的叶子数量;
是每片叶子的复杂度;w是每片叶子的向量分数;
是衡量惩罚轻重程度的参数。
XGBoost的八个超参数通过Tree-structured Parzen Estimator和10折交叉验证的方法优化,具体数值见表2。其中,subsample是训练模型的子样本与整个训练数据集的比率;gamma指定了节点分裂所需的最小损失函数下降值;min_child_weight是指子集中权重的最小总和;reg_alpha和reg_lamda分别是L1正则化的权重和L2正则化的权重。
Table 2. Hyper-parameters of XGBoost model
表2. XGBoost模型的超参数
3.4. 直方图梯度提升回归树
直方图梯度提升回归树算法是梯度提升回归树实验性的实现 [14]。直方图的思想是通过将连续的浮点特征值离散成为k个值去生成一个直方图,直方图的宽度为k。根据直方图中每个离散值在直方图中的累计量去选择数据的特征,找到一个最好的分割点。因此,直方图梯度提升回归树可以减少分割增益的计算量,可以通过直方图相减的方法去得到叶节点的直方图,花费的代价变小了,进一步加速了模型训练的过程。在本研究中,对直方图提升回归树算法的四个参数包括:树的最大深度、学习率、max_iter还有max_bins通过Tree-structured Parzen Estimator 和10折交叉验证的方法优化,具体数值见表3。
Table 3. Hyper-parameters of histogram gradient boosting regression trees model
表3. 直方图梯度提升回归树算法的超参数
4. 结果和分析
4.1. 不同机器学习算法的对比
在上一个小节中确定了三种机器学习算法在不同数据集下的最优超参数。本节将用80%的数据去训练选取了最优超参数的机器学习算法模型,用20%的数据测试机器学习算法模型的性能,选出均方误差最小的机器学习算法模型作为最终模型去预测风荷载功率谱。三种机器学习算法模型在不同测试集中的均方误差见图6。
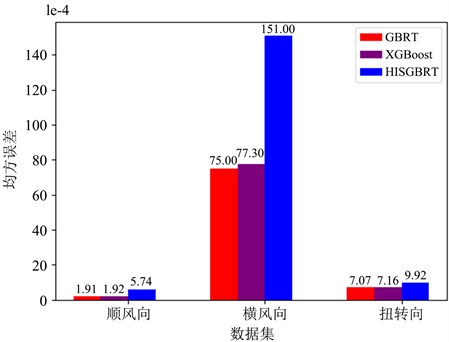
Figure 6. Mean squared error of different algorithms on different datasets
图6. 不同算法在不同数据集上的均方误差图
从图6中可以看出,最小均方误差值所对应的算法都是梯度提升回归树算法。因此,选取具有最优超参数的梯度提升回归树算法模型作为最终模型去预测顺风向基底弯矩系数功率谱、横风向基底弯矩系数功率谱和扭转向基底弯矩系数功率谱。
4.2. 最终模型预测风荷载功率谱
上个小节已经确定梯度提升回归树模型为最终模型,本节将最终模型的预测值与试验值以及先前研究学者提出的公式拟合值进行对比。
唐意 [34] 综合谱的曲线的变化特点还有主要作用机理,提出的顺风向基底弯矩功率谱表达式如下所示:
(5)
上式中,
表示的是折算频率,
、
、
、k和
都是待定的参数。
全涌 [35] 根据大量的测力试验提出了横风向基底弯矩功率谱拟合公式如下所示:
(6)
上式中,
是折算频率,S,
,
,
都是待定的参数。
李永贵 [36] 基于大量试算的基础上提出了扭转向底弯矩功率谱的计算公式如下所示:
(7)
上式中的
同样代表的是折算频率,其它是待定的参数。
对公式(5)到公式(7)的参数进行拟合,风场类型记为w,当
时,风场类型为A类,
时为D类风场,
,
分别表示为B类风场和C类风场,对顺风向、横风向、扭转向功率谱的计算公式的参数进行拟合,计算公式为:
顺风向:
(8)
(9)
(10)
(11)
(12)
横风向:
(13)
(14)
(15)
(16)
扭转向:
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
将机器学习模型预测值与公式拟合值以及试验值在B类地貌0度风向角下进行了对比,如图7所示,从图中可以看出机器学习模型的预测值和公式的拟合值都与试验值都吻合得较好。
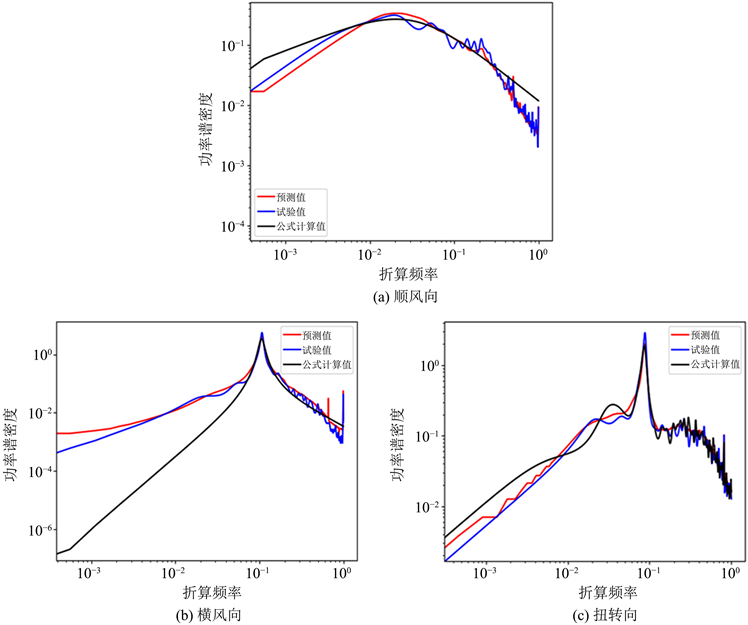
Figure 7. Comparison of power spectrum under 0 degrees wind direction angle of exposure category B
图7. B类地貌0度风向角下功率谱对比图
为了更加精确的对比公式拟合值和机器学习模型预测值两者与试验值的误差大小,表4给出了三个方向下公式拟合值跟机器学习模型预测值两者与试验值的均方误差大小。从表中可以看出,机器学习模型风荷载功率谱预测值的均方误差在横风向和扭转向都比公式拟合值要小,其中机器学习算法模型的横风向基底弯矩功率谱预测值的均方误差远远小于公式(6)的拟合值。虽然机器学习模型功率谱预测值在顺风向的均方误差要比公式(5)的拟合值要大,但是两种的均方误差相差不大,而且从图7可以看出机器学习模型在低频段的功率谱预测值表现得比公式拟合值要好。因此,机器学习模型预测风荷载功率谱比公式拟合值表现得更好。
为了表明机器学习最终模型的预测性能,表5列出了最终机器学习模型顺风向、横风向、扭转向基底弯矩功率谱预测值与试验值之间的相关系数。相关系数计算公式如下所示:
(35)
式中,
代表试验值X与机器学习模型预测值Y的相关系数,
表示试验值与预测值之间的协方差,
和
分别表示试验值和预测值的方差。
Table 4. Comparison of the mean square error between the fitted value of the formula and the predicted value of the machine learning model
表4. 公式拟合值与机器学习模型预测值的均方误差对比
Table 5. The correlation coefficient between the predicted value of the machine learning model and the experimental value
表5. 机器学习模型预测值与试验值的相关系数
从表中可以看出,机器学习模型的预测值与试验值之间的相关系数达到了0.97以上,进一步表明了机器学习模型预测风荷载基底弯矩功率谱的可行性。
5. 结论
本研究开展了机器学习算法对高层建筑标准模型功率谱预测的研究,通过风洞试验获得大量高层建筑功率谱数据集去训练和测试三种机器学习算法:梯度提升回归树、直方图梯度提升回归树和XGBoost。机器学习模型的输入是湍流强度、风向角和折算频率,输出是顺风向基底弯矩系数功率谱、横风向基底弯矩系数功率谱和扭转向基底弯矩系数功率谱。结论总结如下:
1) 介绍了三种机器学习算法的超参数并采用Tree-structured Parzen Estimator和交叉验证的方法优化算法的超参数。
2) 通过对比三种算法在测试集的均方误差,发现梯度提升回归树算法预测高层建筑标准模型顺风向、横风向和扭转向的基底弯矩功率谱的性能是最好的。
3) 最终机器学习模型顺风向、横风向和扭转向基底弯矩功率谱的预测值与试验值之间的相关系数都不低于0.97,表明了最终机器学习模型的良好预测性能。
4) 通过对比最终机器学习模型预测值和公式拟合值与试验值的对比,表明了最终机器学习模型可以很好地预测不同地貌、风向角和折算频率下的顺风向、横风向和扭转向基底弯矩功率谱。