1. 引言
“i2010数字图书馆倡议”是一个Europeana (欧洲数字图书馆1)倡议,目的是使所有的人能够访问获取欧洲的科学文化资源并为子孙后代保存这些科学文化资源:书籍、期刊、电影、地图、照片、乐曲等。而欧洲科学文化资源的数字化以及这些数字化内容的获取的一个关键因素是明确数字化内容的权利(版权、著作权、知识产权等,以下简称权利)地位。尤其对于那些准备数字化所有内容的图书馆来说,这是一个重要的问题。多数情况下,图书馆可以识别、跟踪并联系权利人(或其代理)请求允许对其作品进行数字化,但通常这些过程耗时量大、费用高。也可能出现经过“精细检索”都无法识别、跟踪权利人的情况,这种情况下的工作被认为是“孤儿”作品——著作既不能被使用也不能依法确定进行数字化;另一个难题是对“绝版”著作的处理——即那些权利人声称不用做商用的著作。这种情况下,把这种类型的著作内容变成在线获取就会与该著作的使用相冲突,或是影响权利人的经济利益。
2. ARROW项目
欧洲数字图书馆著作权利信息及孤儿著作注册获取(ARROW [1] )项目于2008年9月开始,旨在便于数字化项目中作品权利的管理。它由欧洲委员会下的“ICT政策支持”主题计划之二——欧洲数字图书馆提供资金的合作支持。ARROW项目包括西班牙、法国、英国、德国等欧盟国家中图书价值链的主要的参与者:各国国家图书馆、书目机构、作家协会、出版商、版权管理机构等。意大利出版商协会担任该项目的协调员,CINECA2担任主要技术支持。ARROW项目范围主要针对图书,目的是为了验证该内容类型的可行性,主要目标包括:用实践演示如何处理数字权利问题;促进作者、出版商、图书馆之间的合作;使用现有技术尽可能的实现“精细检索”程序自动化;提供各种权利所有者的联系信息。
3. ARROW系统作为互操作服务的推动者
ARROW项目系统是一个分布式的基础设施,它由以下几部分(图1)组成:1) ARROW网络门户服务部分:介于用户与系统之间的界面。2) 权利信息基础架构(RII):它是ARROW系统的骨干及引擎,RII使ARROW能查询并检索来自网络数据库的信息、处理这些信息并采取相应的措施、最终根据计划好了的工作流交换信息。3) ARROW工作注册部分(AWR):用于存储RII工作流以结构化方式收集的所有相关的信息片断,这种结构化方式可以在ARROW服务框架内检索并使用相关信息。4) 孤儿作品的注册部分(ROW):它是AWR的子集,主要针对那些已经宣布为“可能孤儿”的作品。
ARROW在创建分布式数据资源网络中扮演着“互操作促进者”的角色,它确保所有社区之间实现了互操作并成功解决了以下问题:1) 跨国层面的数据不能够互操作。由于欧洲图书馆的作用,使得只有图书馆领域所具备的特点足以能够满足ARROW实现互操作的目标,从而轻松实现了跨国层面数据的互操作性。2) 图书馆目录与在版图书目录之间缺乏互操作性,并且它们之中没有一个可以与复制权利组织(RRO)的著作实现互操作。3) 保存在不同领域的数据以“图书”层面的形式予以创建表达,而权利却是根据“作品”措辞进行定义。
ARROW与EDITEUR的专家合作为项目中包含的不同来源的元数据的自动交换设计了一套特别的信息,并于2011年10月正式发布了这套名为“用于权利信息服务的ONIX”(ONIX-RS)的1.0版。ONIX-RS在很大程度上依赖于ARROW的初始工作,但迄今为止它已扩展到了可以容纳权利领域的其他信息流,因此,它可以被其他组织或协会用来进行该领域的工作。同时ARROW系统也把VIAF4服务整合进它的工作流程,这样做的目的是为了获取关于著者及其他作者更多的信息(如生卒年、国籍及所有曾用名等)。
4. 权利信息基础架构(RII)
ARROW的权利信息基础架构部分负责管理复杂的工作流程(图2),该工作流程从图书价值链条(图书馆、在版书目数据库以及复制权利机构)中数据资源各个部分内检索信息。该流程对收集到的信息进行处理以获得版权状态以及与提交状态相对应的著作及相关著作的出版状况。工作流终端获得的其他重要结果包括:由RRO提供的一套涉及许可状况、支持该许可状况的原因以及可能是孤儿作品的鉴定等信息。RII接收来自图书馆的关于某一作品的数字化及使用的许可申请,它会向包括在工作流中的数据提供者查询该著作的出版地(TEL、VIAF、Bip、RRO)并对收集到的结果进行编辑。RII这样做的目的是为了提供结果信息的正确状态。
最初的图书馆请求是在表达水平上执行的(更确切地说,最初的图书馆请求是指“资源”一词,资源术语支持一个表达实例,如某一本图书的特定印刷版本),而提供的工作流的终端响应则代表了著作的水平。这就意味着最初的请求通过了识别、匹配、工作、聚类、表达以及相关作品的识别及表达阶段,每一个阶段都针对著作的权利状况添加了相应的信息片段。
从图2可以看出,RII工作流可以分成三个主要阶段:
第一阶段:主要包括图书馆领域,涉及到TEL作为主要的参与者、VIAF作为著者信息的来源。这一阶段的主要包含下列信息:作品最初显示属于哪个图书馆;相同著作的显示列表;其它与该作品相关的著作及各自的显示列表;每一位作者及每部著作的其他参与者的一套权威信息(包括作者常用名及其他不同形式的名称、生卒年、国籍等);每部著作的版权状况(该著作是否受到版权保护,或者不能确定该著作的版权状况)。
第二阶段:主要是在图书在版领域,涉及到Bip组织或ARROW系统中每个国家的数据库。这一阶段主要包含下列信息:著作的附加显示列表及与该著作相关的著作列表;在版/孤儿状态以及该著作及相关著作的每一个显示的商业可用性;每一部著作的出版状态;该著作目前属于在版还是孤儿;或是不能确定。
第三阶段主要是在复制权利机构领域,涉及RRO或ARROW系统中每个国家的数据库并增加了前面图书馆和Bip领域内获得的结果信息。这一阶段主要包含以下信息:由RRO提供的一套关于许可状况信息及支持该决策的缘由信息;著作的孤儿状况,不能确定或不能找到权利人则可能被认定为孤儿的著作,或者不是孤儿但是无法明确断定该信息。
从上述工作流程中可以检索到如下信息片段:著作信息;显示信息;著作及该著作所显示信息之间的关系;著者及其他参与者信息;可识别著者与他们参编著作之间的关系;每个信息片断与提供该信息(TEL、VIAF、Bips、RROS)片段的参考资源之间的关系;一套ARROW关于每部著作的认定:版权状况、出版状况及孤儿状况。ARROW著作注册表(AWR)为系统处理过的每一个请求的所有信息片段提供存储和维护。
5. RII架构层
为了提高系统的灵活性、可扩展性、可维护性及可重复利用性,RII系统建立了如图3所示的架构层。
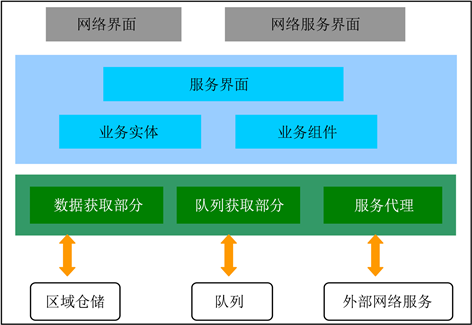
Figure 3. RII hierarchical architecture diagram
图3. RII分层架构图
显示层处于应用的最顶端。它由两部分组成:一部分是向终端用户展示结果的网络界面;另一部分是向外部服务揭示机读数据的网络服务界面。
服务层有业务实体和业务组件两部分组成。前者是指应用领域建模,每个业务实体都建模为不包含任何逻辑方法的JavaBean;由于业务组件部分包含了系统所必需的、必要的逻辑及所需的进程,因而,服务的逻辑工作方法是由“业务组件”部分来执行的。该进程由恰当的管理者完成,每位管理者负责一个或多个业务实体并对这些实体进行复杂详尽的阐述。服务层通过定义良好的界面向终端用户揭示服务的逻辑方法。
数据层既可为RII系统内的数据维护提供获取,也可为外部服务揭示的数据提供获取。RII数据层由三个主要组成部分:1) 数据获取部分。这部分提供了抽象的界面以便于对底层持久性存储的访问。这种持续性数据是中立的而且独立于服务层。2) 队列5获取部分。RII架构是一个基于消息队列的异步架构。它提供了抽象的界面以便于底层队列的访问获取。3) 服务代理。由于服务层必须使用外部异构服务揭示的数据,因此有必要实施不同类型的链接器以便于处理它们的沟通语义。服务代理脱离了所有外部服务的沟通特色,目的是为了使这种互动对于服务层来说是透明的。
6. ARROW著作注册(AWR)与孤儿作品的注册(ROW)
在ARROW工作流程的末端植入了RII仓储和ARROW著作注册(AWR)。相应的AWR成为了ROW的基础。实际上,存储在AWR中的作品随时随地都可能作为“可能孤儿”著作而被添加到ROW中。ARROW系统内关于孤儿著作注册设计最初是由HLEG在关于数字资源长期保存、孤儿著作以及绝版著作的报告中提出的,其中包括建立关于权利清理中心以及孤儿著作数据库的建议以及主要原则。此外,为了定义ROW的要求,系统小组对ARROW联盟及欧盟国家中的利益相关者(包括共同管理组织和复制权利机构)进行了咨询,并由HLEG确定候选机构负责孤儿作品数据库和权利结算中心的运行。
为了确保与ISTC国际机构仓储提供的服务之间实现互操作,AWR在设计的同时也把著作的ISTC元数据考虑在内。通过一个网络界面可以公开检索包含在ROW中的著作信息,从而使得权利人可以(单独或通过共同管理组织或代理)要求自己的权利。
7. ARROW试用及系统验证
ARROW项目于2011年2月完成,2001年9月,ARROW系统在法、德、西班牙及英国等国家中用来试验检索出版的著作。在法国的使用试验中与下列机构或数据库进行了连接:法国国家图书馆目录;虚拟国际权威文档数据库;在版数据库中的电子图书;法国RRO中心的全部著作。在德国的试用实验中连接了德国国家图书馆目录、虚拟国际权威文档数据库、在板数据库中交付书籍目录、德国RRO中心的全部著作。在西班牙的试用实验中连接了西班牙国家图书馆目录、虚拟国际权威文档数据库、在版数据库中查找的数字漫画图书、西班牙RRO中心的全部著作。在英国的试用试验中连接了英国国家图书馆目录、通过英国RRO中心查询在版数据库中的尼尔森图书、英国RRO版权授权机构、出版商授权协会以及作者授权和收集协会的全部著作及数据库。
在斯布鲁克大学图书馆的领导下根据试点国家的应用状况对系统进行了验证,结果(表1)表明与传统手工检索相比,使用ARROW检索作者、出版社、作品及著作的权利状况获得了巨大的益处:利用ARROW可以节约的检索时间从西班牙的72%到英国的97%不等。在大型的数字化项目中,这种检索时间的节约就意味着大幅降低了那些图书馆和那些需要检索图书版权的人或机构的成本。
为了进一步验证ARROW的有效性,大英图书馆利用ARROW随机对自己馆藏的1870年到2010年间出版的140本图书进行了检索研究,结果有力的验证了ARROW的高效节时。同时,大英图书馆也试图用这次研究确定ARROW是否可以接收图书数字化许可并把对权利人进行的“手工”精细检索与“自动”精细检索的结果相比较。

Table 1. Comparison table of time saved by using ARROW
表1. 使用ARROW节约的时间对照表
另外,英国的惠康图书馆与2011年开始了一项主题为“现代遗传学及其基础”的数字化试点项目,利用ARROW对1850年至1990年间的1400册图书进行数字化。这个项目最初由惠康信托提供资金支持,旨在评估一项包括版权著作在内的、并根据时间和成本进行精细检索的数字化项目的可行性。目的是寻求权利人的数字化许可并使作品可通过网络免费获取。惠康信托决定使用英国RRO服务作为识别图书权利人的向导。而英国的RRO使用ARROW系统帮助惠康信托处理数据记录并加速精细检索进程。截止到2011年11月,英国RRO正在为试验图书实施精细检索,并能够在2012年提供所需的授权许可。2011年4月,开始了ARROW的增益项目。目前,ARROW的增益项目已经全面展开,它的主要目标是扩展ARROW覆盖的国家范围,并把其服务分析和扩展至图像领域。目前,ARROW增益项目包括下列13个欧洲国家的利益相关者:西班牙、法国、硬骨、意大利、德国、奥地利、斯洛文尼亚、荷兰、挪威、芬兰、丹麦、比利时和瑞典。
8. 对我国孤儿作品版权的启示
随着孤儿作品越来越多,如果不能够对其进行充分利用,将会造成严重的资源浪费。因此迫切需要完善孤儿作品使用权制度的设计 [2]。用户的权利和所有者的权利都是版权制度的基本组成部分。我们可以借鉴国外孤儿作品的强制使用制度;或者是利用法律上的例外原则而设计的孤儿作品问题解决方法;或者是由图书馆等文化设施制作数字化资料,对孤儿作品加以复制,并注明仅用于本国科学研究,不做商业使用,类似于国外的扩展集中许可制度 [3]。我国目前没有正式的立法或法规对孤儿作品的所有权和使用权进行界定,更没有建立一套完善的系统对孤儿作品进行管理。新技术应用日益广泛的今天,如何把新技术应用到图书领域也是每位从业者需要思考的问题。加快孤儿作品的使用权的立法和开源系统设计,建立孤儿作品开源信息数据库,已经是刻不容缓的事情。
NOTES
1Europeana是一个欧洲数以百万计已经数字化了的图书、绘画、电影、博物馆物体以及档案记录的接入点。它是一个来自欧洲科学文化机构的权威信息源,是图书馆、博物馆、档案馆及创意产业之间的知识交流平台。
2CINECA是一个非营利性的机构,它由意大利51所大学、国家海洋和地球物理实验研究所、国家研究委员会、教育、大学及研究部组成。现在是意大利最大的计算机中心,它开发先进的信息技术应用及服务,像一个学术界、纯研究领域、工业界以及公共管理领域之间的联盟。
3Drupal是一个开源的内容管理平台。主要用于构造提供多种功能和服务的动态网站。这些功能包括用户管理、发布工作流、讨论、新闻聚合、元数据等。
4VIAF是The Virtual International Authority File首字母的缩写。
5队列(又称为伫列)是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。在这种数据结构中,最先插入的元素将最先被删除,最后插入的元素将最后被删除。