1. 引言
随着云计算以及智能电网 [1] 系统的高速发展,海量电力数据经智能电网的计量系统 [2] 涌入云端进行处理。计量系统不仅为智能电网系统提供实时数据,还为云端计算提供了大量实时数据支撑。但是,大量计量终端产生的海量实时数据使云计算的性能逐渐达到了瓶颈,较长的网络延迟也使云计算模型的实时性大打折扣。同时,单纯的海量电力数据的积累并没有价值,只有通过数据挖掘、机器学习等手段,对海量电力数据进行深入分析并加以利用,才能使数据的价值发挥到最大。边缘计算 [3] 模型被提出并得到广泛应用。基于边缘计算模型使得数据可用在更接近计量终端进行处理,同时边缘设备的计算资源可以有效支持各种学习算法的训练,从而实现计量系统下的实时电量科学预测。利用科学有效的机器学习方法对海量电力数据进行学习,实现电量预测,为电网实时负荷提供参考数据,结合电量预测的实时电价预测可以提高电网效率、提高用户合理安全用电的用户体验 [4] 。
本文在计量系统下,基于边缘计算模型提出了一种基于机器学习的电量预测方法,实现了对海量电力数据的信息挖掘和对实时电量的精准预测。
2. 系统模型
2.1. 边缘计算
边缘计算模型是一种新型计算模型,旨在将应用服务程序的全部或部分计算任务迁移到网络边缘侧的边缘设备端执行,以满足实时性、隐私保护、降低能耗、快速连接等关键要求。由于原有云计算模型的大量计算任务被迁移到更靠近数据源头的附近执行,边缘计算模型极大的节省了海量数据往返云端的传输时间,提高了数据传输效率,保证了数据处理的实时性,同时降低了网络拥塞的可能性。
图1为边缘计算模型图,手机、笔记本电脑等设备产生海量数据并提交给边缘设备,边缘设备不仅执行部分计算任务,还向云端提供海量数据,同时将结果反馈到数据源头。
2.2. 基于边缘计算的电量预测模型
边缘设备相比云端更靠近数据源头,边缘计算模型下,边缘设备相对计量终端更强的计算能力,使得电量预测可以在边缘侧使用计算复杂度和精度都较高的各种学习算法。
目前的电力计量系统是通过集中器收据计量终端数据,然后上传计量管理中心,本文在计量系统下,通过在目前的电力集中器下增加边缘计算模块,海量电力计量数据传递到集中器,边缘模块就是一个边缘设备,基于边缘模块的计算能力,以在线学习的方式结合机器学习算法,本文采用梯度提升树(GBDT),完成对计量数据的训练和实时预测,并将实时电量预测数据返回给计量终端。其模型如图2所示,由于海量电力终端数据传递至边缘设备后,不再传递至云端,而是直接利用边缘设备自身的计算资源对数据进行处理,极大地提高了数据的处理效率。另外,对于每时每刻产生的新的电力数据,采用在线学习的方式可以快速地完成训练并作出预测,极大地提高了数据处理的实时性。
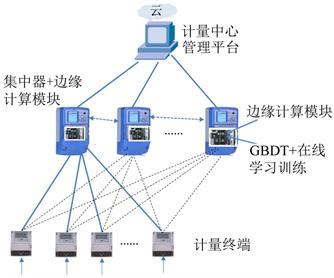
Figure 2. Electricity forecasting model based on edge computing
图2. 基于边缘计算的电量预测模型
3. 基于梯度提升树的电量预测方法
3.1. 在线学习与离线学习
机器学习通常分在线学习与离线学习两种学习方式。
离线学习又称批量学习,是指在学习过程中,将所有或者大批量样本全部训练完毕后,才更新机器学习模型的权重。离线学习学得的模型通常是有效的,不会因某些样本的错误而使整个模型失效。但是,在实时性要求较高的任务中,离线学习方式就无法胜任。
在线学习是指在学习过程中,随着样本的输入而进行训练,单个或少量新样本的输入,会执行训练并更新模型的权重,新的模型与新的样本又会参与进下一次训练中。由于每次训练的样本数量少,所以在线学习的速度很快,并能实时更新权重,学习到样本的变化。在线学习的方式十分适合训练无时无刻都在变化的真实世界的数据。
3.2. 梯度提升树学习方法
梯度提升树(GBDT, Gradient Boosting Decision Tree)是一种十分有效的机器学习算法,无论是在分类还是回归问题上,都有十分优秀的表现。将GBDT算法应用于实时电量预测中,能够得到良好的预测效果。
在机器学习领域,梯度提升树最早由Friedman [5] 提出,属于集成学习Boosting家族,是其中重要的一员,并以其强悍的学习效果占据着重要地位。其以CART树为弱学习器,利用加法模型与前向分步算法实现学习的优化过程。
梯度提升树采用最速下降法的思想,对于损失函数:
(1)
运用最速下降法,可得下一次迭代点:
(2)
对于加法模型:
(3)
联立公式(2) (3),并取步长
可得:
(4)
其中,
代表本次迭代需要学习的CART树,
为其参数。
即利用损失函数的负梯度在当前模型的值:
(5)
作为残差的近似值,来拟合一个CART树。
在计量系统下,每30秒采集到一个电力数据
,
,其中,
表示第
次收集到的电力数据的时间等特征,
表示第
次收集到的电力数据的电量标签,即真实电量。
以在线学习的训练方式,以当前时刻电力数据
为输入,下一时刻预测电力数据
为输出的基于GBDT的电力预测方法算法步骤如下:
第一步,对于初始时刻,即
,利用先验知识给出一个随机值
作为第一个电量预测标签,并向计量系统返回第一个电量预测数据
并输出。
第二步,对于第
次训练,输入训练电力数据集:
(6)
并初始化模型:
(7)
其中,
表示1到
个时刻的电量标签,即每个时刻的真实电量,
表示使损失函数最小的初始化模型,即第一个CART树的参数。
第三步,对
,
为选定的迭代次数,分a,b,c,d四小步有:
a:对每个时刻
的电力数据
,计算当前模型负梯度:
(8)
b:对
拟合一个CART树,得到第
棵树的叶节点区域
,
。这些叶节点区域
会将训练数据集
分为
份。
c:对
,计算:
(9)
即为能使当前模型的损失函数达到极小值的第
棵CART树的叶节点区域
对应的输出。
d:更新模型:
(10)
第四步,得到最终模型:
(11)
第五步,对下一时刻
,利用最终模型计算预测电量标签:
(12)
第六步,向计量系统返回预测电量数据
并输出。保存训练电力数据集
以及当前模型
。返回第二步,进行第
次训练及预测。
3.3. 基于边缘计算的电量预测流程
海量电力数据被依次传递至边缘设备,边缘设备采用在线学习的方式,一个电力数据或少量电力数据到来后便完成一次GBDT训练,并更新一次模型,再做出预测。
图3为训练流程,由于初次预测时,并没有任何有效数据得到训练,所以生成一个或少量随机值作为第一个时刻或初始的某段时刻的预测值。之后,有效的电力数据依次得到训练并获得模型,依次对下一个时刻做出预测。
4. 实验验证
通过智能电表收集终端数据并传递至边缘计算设备,采用本文介绍的方法获得预测结果。以每隔30秒为1个时刻,从计量终端收集相关电力数据,并将数据上传到边缘模块进行训练,得到预测模型后预测下一个时刻的电量数据,并反馈给计量系统,并由计量系统显示出来。训练时,以年月日时分秒为特征,电量为标签,在线学习训练数据量为1时预测效果如图4所示,为3时如图5所示,为5时如图6所示。预测电量趋势与实际获取的电量趋势相同。
图7为不同的预测时刻数量对应的平均绝对误差 [6] ,由于在线学习使用的数据量不同,所以迭代次数不同,但预测时刻数分别为1、3、5对应的平均绝对误差趋势相同,开始训练时,数据量太少,预测精度不高,导致平均绝对误差迅速升高,但经过一段时间的数据采集和训练之后,预测模型的效果变得越来越好,预测精度越来越高,平均绝对误差开始下降,且最终能趋于一个较低的平均绝对误差值。预测时刻数为1时的平均绝对误差低于预测时刻书为3和5,表明短期实时预测 [7] 的效果更好。
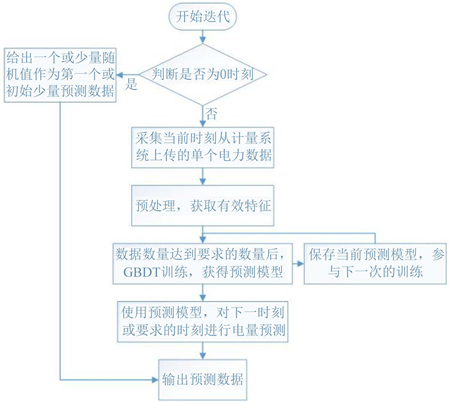
Figure 3. GBDT and online learning training process
图3. GBDT + 在线学习训练流程
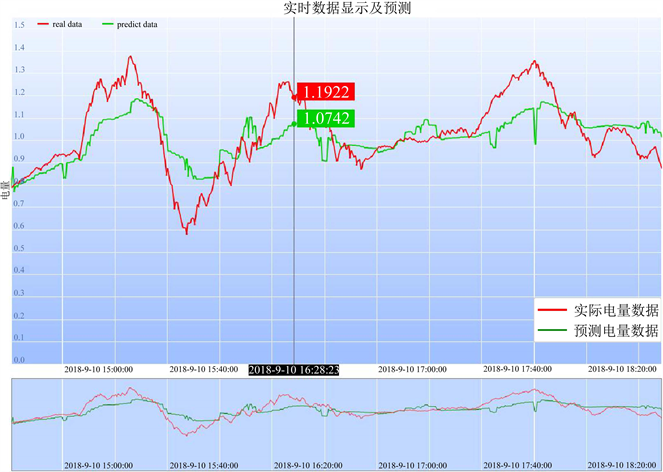
Figure 5. Three-time prediction effect
图5. 三个时刻预测效果
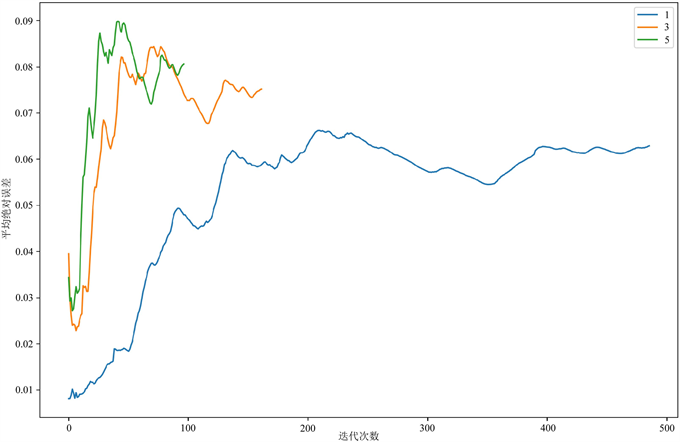
Figure 7. Average absolute error of different forecast times
图7. 不同预测时刻数的平均绝对误差
5. 总结
随着智能电网系统的高速发展,海量电力数据涌入计量系统,合理高效的数据处理具有重大意义。本文首先介绍了边缘计算模型,机器学习算法中的GBDT算法以及在线学习方式,然后将其结合提出了一种在计量系统下基于边缘计算的电量预测方法,最后实验验证了方法的可行性。
基金项目
国家重大研发计划(No. 2018YFB0904900和2018YFB0904905)支持。