1. 引言
在批改过不同程度的德语学习者的作文之后,笔者发现:当德语名词该变复数时,中国的德语学习者在很多情况下都不把名词变为复数名词。这篇论文的目的是,从理论上解释这种复数错误(名词到底何时该变成复数形式),然后从此理论推导出假设,在哪些情况下中国的德语学习者对这种名词变复数的错误更宽容。然后通过实验来验证这个假设。解释这种变复数的错误的尝试的理论基础是“语言迁移”现象的存在,而这种变复数的错误可能是一种语言迁移现象,因为中文中的名词没有数的区分(transnummeral)的,继而不存在数的变化。在语言学研究中有理论认为,中文的名词是“群体名词”(Massennommen) (或者类似的名词),一个中文名词的最基础的含义代表的是一个实体的种类,所以从此引出假设:中国的德语学习者对德语名词,特别是抽象名词(Abstrakta),在表示类别或者普遍性(generisch)的时候的这种变复数错误最宽容。因为,第一,一个抽象名词的含义最接近于一个纯理念、一个表示种类的名称(Gattungsbezeichnung);第二,表示类别或者普遍性的(generisch)名词用法也具有表示一类实体的含义。所以在中文名词和德语中的表示种类和普遍性的抽象名词之间存在紧密的联系。也可能存在中国的德语学习者对这种变复数的错误不那么宽容的可能。如果这样的话,这种情况很可能会发生在那些“不表示种类和普遍性的”德语的“具体名词”处,因为具体名词(Konkreta)更容易被认知,不表示种类和普遍性的用法毫无疑问地表示一个物体或者多份物体。所以,这篇论文的完整假设如下:中国德语学习者趋向于在德语名词该变复数却不变复数时更宽容;在抽象名词表示种类或者普遍性时表现的最宽容;在具体名词不表示种类和普遍性(nicht generisch)时最不宽容。
本论文的的主体部分分为理论部分和实践部分。在理论部分中将会介绍现有的相关研究的结果,这对本论文的研究对象很重要。它们是关于在外语习得方面的语言迁移理论,中文名词的“无数性(Transnummeralität),以及德语名词在何时应该变复数的理论和德语中名词表示种类和普遍性的用法的理论(Generizität) (后文也称“属类”用法)。在实践部分中将会介绍用来验证上述猜想的实验(数据和方法),报告实验结果和相关讨论。最后展示的是结论。
此论文对中国的德语教学法有意义。如果猜想被实验所证实,那中国的德语教师就应该在德语课中想办法处理这个以前未被注意的问题,德语学习者才能有意识地避免这种问题。如果假设被证伪,那这种变复数的错误的原因必须在别处寻找。
2. 理论部分
在理论部分首先多方面描述语言迁移现象,这是为了指出中国德语学习者的这种变复数错误可能是语言迁移现象。接着阐述了中文名词的“无数性”(Transnummeralität),这可以更进一步解释这种变复数的错误是语言迁移的可能性。在理论部分的最后作者展示了德语名词复数的规则和表示种类和普遍性的用法(Generizität),为的是为实验中的题目的选择提供标准以及更好地理解本论文的猜想。
2.1. 语言迁移
2.1.1. 定义
Gass、Selinker [1] 、Odlin [2] 等作者都已对语言迁移现象的定义做出了论述,继而Steinhauer [3] 建议以下复合定义:
“对广义的对语言迁移的理解是一种语言的互相影响,经常是以前学过的语言影响新的语言,不过也可以是外语反过来影响母语。语言迁移是一种既主动、有意识的旧语言的应用,语言学习者将其用作学习策略或者交流策略,也可以被看成是一种无意识的过程,语言学习者的语言行为不受控制。语言迁移经常出现在语言表现中,也可以影响语言能力的改变。它经常在形式层面出现。它的出现经常被标注性(Markiertheit)、不同语言中类型学上的相似之处、学习环境、外语的输入、语言结构的副属归属(Subsystemzugehörigkeit der Strukturen)、学习阶段、学习者的特点和外部情况共同决定。”
中国德语学习者趋向于德语名词不变复数,毫无疑问不是一种策略,因为每个德语学习者都知道德语的名词是有单复数之分的,在该变复数时不变复数是错误的。策略是积极的,不应该被主动用于生产一个错误,所以中国德语学习者这种不变复数的现象应该被作为一种过程来理解;同时也应该属于一种无意识的过程,因为一般情况下没有人故意生产错误;根据对一些德语初学者的观察,比如仅仅学了一个月德语的学习者,他们出现这种错误的频率比高级学习者的这种错误的频率要高,在这种情况下这种变复数的错误可以被看成是一种对德语学习者的能力的体现。
2.1.2. 易使语言迁移现象出现的诱因
“关于哪些因素影响语言迁移的出现的观点,在研究中各有各的观点,目前还尚未达到统一。” [3]
很多作者都统同意Kellerman [4] [5] 的观点:两个语言之间的距离和标记(Markiertheit)对语言迁移现象有很大影响。如果两种语言没有亲缘关系,但语言迁移现象仍旧出现,这种情况经常是无意识的 [3]。本论文的研究适合于这种情况:中文和德语不存在亲缘关系,但即使这样两种语言之间仍然有相同点和不同点可能诱发迁移现象。如果语言迁移现象仍旧发生,即,如果该变复数的名词不被变复数的话,那这种现象经常是无意识的。
第二个对语言迁移现象的出现的影响因素是年龄。他们是20到30岁之间的大学生、低龄成年人。他们已经具备了足够的外语言能力。
一个有趣的、但是在它的意义和实用性反面还有争议的概念是Grosjean [6] 的“语言模式”(Sprachmode)。
另外一个影响语言迁移的因素是外语输入的量和学习外语的方式 [3]。如果外语是在自然环境中习得,语言迁移现象会更不明显 [7]。
关于语言迁移现象出现的讨论包括原形理论(Prototypikalität) [2] [3] [4] [8] ;音响上的相近;更早时学习的与目标语言相近的语言 [2] ;学习阶段 [3] ;情感因素 [3]。这些因素对后续实验的设计有重要影响。
2.2. 中文名词的“数中立性”(Transnumeralität)
Gil [8] 定义“数中立性”为“unmarked with the respect to the mass/singular/plural distinction”。Rijkhoff [21] 认为,当名词不拥有名词专有的范畴,如“数”时,它们是“flexible nouns”,flexible nouns是数中立的。中文的名词就符合Gil和Rijkhoff的定义,也就是说,中文的名词是超越数(transnumeral)的。更有意思的是,中文中的名词在本体论上和语义上到底含义是什么。为了得到这个问题的一个初步的答案,我们可以参阅中国哲学家墨子(前468~前376)的著作《墨子∙经说上》。墨子在其中把名词分为两类:“名,达类,私。”。也就是说,出了专有名词如贝多芬、柏林墙之外,其他的名词都是表示种类的名称。“马”表示的是马这个物种,而不是一匹马。如果查阅现代中文的语法书,也可以找到相关的陈述如:“名词所代表之物,往往是一个通名。例如“马”字并非一匹马,而是泛指一切马。” [9]。
也有西方研究者认为中文的名词是一种群体名词(Massennomen),Lesi [10] ,Sharvy [11] 和Hansen [12] 是这种观点的代表者。Rullmann和You [13] 认为中文的名词是连续的(komulativ)。Quine [14] 对连续性(Komulativität)做了较详尽的阐述。Krifka认为,一个单独的中文名词指的是种类(Gattung),并且较详尽地论述了中文中名词的各种用法的含义都可以从种类的含义中推导出来 [15]。
2.3. 在德语中名词何时单数何时复数
因为“数”是德语名词的内在的一个性质,所以一个德语名词要么是单数要么是复数。不过并非所有德语名词都有复数,因为不是所有德语名词都可数,即,一个德语名词必须得是可数的,才可以以复数的形式出现。可数性是德语名词变复数的一个必要条件。在杜登语法 [16] 中有关于如何判断一个名词可数与否的判断方法,但未必对德语学习者有效。德语中还存在一些一般情况下只以单数形式存在的名词(Singualaretantum),其中包括物质名词(Stoffnamen),集合名词,某些抽象名词,专有名词,表示身体部分和衣服的名词 [17] ;还有一些只以复数形式出现的名词(Pluraletanrum),这类似在杜登语法中 [16] 有所论述。
在德语中另外一种涉及到单复数用法是“属(类)”的用法(Generizität)。Russell [18] 了确定的“属(类)”用法和非确定的“属(类)”用法。确定的“属(类)”用法((definite generische Verwendung))是一种“der/die/das…”的表达,非确定的“属(类)”用法是“ein…”形式的表达。 [19]。诸如das Fahrrad的定冠词表达既可以表达个体含义,也可以表达“属(类)”。Heyer [19] 总结了定冠词的“属(类)”用法在句法上的标准。在杜登语法中(Duden-Grammatik) [20] 也有关于“属(类)”用法的叙述。杜登语法将其称为“普遍化”(Generalisierung oder Verallgemeinerung)。在非确定“属(类)”用法(definite generische Verwendung)中涉及到的是不定冠词单数和零冠词的复数名词,因为除了单数定冠词,不定冠词单数也属于中文母语的德语学习者所犯的错误范围内(中文中不存在定冠词,定冠词单数和不定冠词单数这两种形式是德语中两种可以与中文中的“零冠词形式”比较的形式)。在实验的题目中零冠词的名词形式会经常以在“属(类)”含义的上下文中出现,所以为了识别出实验题目中的这种情况,阐述在“属(类)”含义范围内的零冠词的名词形式也是必要的。“如果选择单数不定冠词,人们眼前看到的是相关种类中的一个典型副本(exemplarische Generalisierung) [20]。在杜登语法中零冠词复数被作为一种不显著的普遍化理解。“显著”的普遍化的形式是名词与alle、jeder连用 [20]。
3. 实践部分
在实践部分中是一个语言学实验,其目的是检验本文的猜想是否得到验证。首先笔者阐述所选数据和实验方法和其理由,然后是实验过程和实验结果的描述,最后是关于实验结果的讨论。鉴于篇幅,实验题目可以与笔者通过电子邮件获得。
3.1. 实验方法和数据
3.1.1. 被试
为了验证以中文为母语的德语学习者总体上是否因为其母语而对该变复数却不变复数的错误更加宽容,必须在中文母语者之外再找一个对比组才行,对比组的被试的母语必须像德语一样存在“数”的区分。如果对比组的被试具有对这种错误更加不宽容,而以中文为母语的被试却更宽容(当然在排除其他干扰因素的情况下),那就可以得出结论:这个趋势确实是由于母语的不同所造成的,即中文母语者的变复数错误确实是一种语言迁移现象。如果两个组都对这种变复数错误比较宽容,那本文的猜想就未被确认:这种变复数错误与母语没有相关性,而是普遍的。对于本论文的实验,对比组由英语母语者构成,因为英语与德语相同,都是有“数”的语言,而且笔者对于英语的了解也优于对其他有“数”语言的了解。
另外几名德语母语者也参加了实验,因为他们的判断可以作为实验题目的“正确与否”的标准。根据他们的判断可以知道实验题目中的句子中的名词哪些是必须变成复数形式的。如果那些名词不必变成复数,那其他被试的判断也就不能被算到实验结果中。
3.1.2. 实验
实验中是德语句子,两组被试分别是中文母语者和英文母语者,他们必须直觉地决定给出的德语句子对于他们的直觉是否可以接受。有不同的接受程度,比如“−2”是绝对不接受,“+2”是完全接受,“−1”和“+1”是中间的接受程度。没有“0”,因为有些被试可能在做出判断时犹豫不决:他们不知道句子到底对于他们自己是否可以接受,或者有些懒惰的被试懒于做出判断,在类似这种情况中他们会选择“0”,然而这对于实验本身并没有任何帮助。如果不设置“0”选项的话,被试可以在某种程度上被“强迫”做出选择。毕竟根据题目的要求他们的判断仅仅是根据直觉,而不是严格的、有很好的理由的判断。
实验中的句子
为了验证以中文为母语的德语学习者是否对“属(类)”用法的抽象名词不变复数的错误更加宽容,是否对非“属(类)”用法的具体名词不变复数的错误更不宽容,在实验中题目被分为四类:1) 具体名词非“属(类)”;2) 具体名词“属(类)”;3) 抽象名词非“属(类)”;4) 抽象名词“属(类)”。
针对每个种类笔者在实验中设计了16个德语句子,就是说,在实验中一共有16个与猜想相关的德语句子,被试被要求从直觉上判断他们对这些句子的接受程度。除了这16个与论文主题有关的德语句子笔者还设计了与主题无关的干扰句子,为了对被试造成干扰,使他们更不容易知道这个实验是关于什么的,否则实验结果将没有说服力,因为被试可能有意识地针对他们解锁出的实验目的做出对句子的判断,而本实验要求他们从直觉上判断。干扰句包括随机的与主题无关的语法正确的句子;包括带有群体名词的句子,因为群体名词不涉及到变复数的问题;还包括带有其他错误类型的句子,为了让实验目的更好地隐藏,也包括“属(类)”用法的句子。句子的顺序是随机的,这样也能使被试更不容易发现实验目的。
另外必须提及的是,实验问卷被分为三个版本。在第一个版本中有8个与主题相关的句子,每个种类两个句子。在第二个版本中改变了第一个版本中的句子的顺序。在第三个版本中改变了基于第二个版本的句子的正确性。第二个版本的目的是验证,被试的判断是否被句子的顺序所影响,因为可能会出现这种情况:一个被试对同一个无论正确还是错误的句子的判断会不同,可能的原因是被试在实验末比在实验开始的时候更劳累。如果可以确定被试的判断不被句子的顺所干扰,那实验可以继续进行。第三个版本的目的是,更准确地验证被试的不同判断是否真的是因为句子中的复数变化。具体的进行方式如下:在这三个版本中的句子,无论是与主题有关的句子还是干扰句,在内容上都是相同的(三个版本的句子的总数是相同的,与主题相关的句子所属的种类是相同的:具体名词非“属(类)”;具体名词“属(类)”;抽象名词非“属(类)”;抽象名词“属(类)”)。在第一个版本中对于每个种类有两个与主题相关的句子,所以一共8个与主题相关的句子;在第三个版本中对于每个种类有不同的两个与主题相关的句子,所以一共也是8个。第一个版本的与主题相关的句子变成了第三个版本的干扰句(其正确性被更改);第三个版本的与主题相关的句子变成了第一个版本的干扰句(其正确性被更改)。为了更清晰地表述,在此举一个例子:
第一个版本的一个与主题相关的句子:
“Wahnsinn, dass du die Maßeinheiten in diesem mathematischen Lehrbuch gezählt hast!”
这个句子是正确的。以英语为母语的被试和一中文为母语的被试根据本论文的猜想应该倾向于都接受这个句子的舒服程度。当这个句子在第三个版本中出现是,它就变成:
“Wahnsinn, dass du die Maßeinheit in diesem mathematischen Lehrbuch gezählt hast!”
这个句子是错误的,因为“Maßeinheit”必须是复数形式。英语母语者应该更不接受这个句子,因为英文中的“Maßeinheit”是“unit of measurement”。“unit”在此句的情况下应当变成复数形式。中文母语者应该更能接受这个错误的句子,因为“die Maßeinheit”在中文中未必只是一个“Maßeinheit”,而是作为一个种类Maßeinheit。这里的“Maßeinheit”对于中文母语者来说是一个表示种类的名称。因为除了“Maßeinheit”的单复数问题在这个句子中的其他内容完全相同,如果被试对于这两个句子有明显不同的接受程度,那这种不同就是由于该名词的单复数区别造成的。如果英语母语者更接受第一个版本中的这个句子,而更不接受第三个版本的这个句子,同时如果中文母语者对第三个版本的这个句子更加接受的话,不同判断的原因就一定是不同母语的原因。如果这个趋势可以覆盖到整个实验的结果上,那本论文的猜想就被证实:以中文为母语的德语学习者的变复数错误确实是一种语言迁移现象。如果不能覆盖到整个实验结果,那这个猜想就是错误的。
题目中的干扰因素
1) 被考察的句子(名词的数被故意弄错的)中的被考察的名词应该被设置为单数,只有这样才有可能测验出被试是否觉得这种错误(本应该是复数的名词却被写成单数)足够舒服以至于接受这种错误。为了将其实现,被考察的名词必须有明显的单复数的词形变化,也就是说,单复数同形的名词是被排除在外的。在英语中和德语中还存在一种“分配读法”(distributive Lesart),这种读法也允许单数名词出现。比如,“Die Arbeiter haben ihr Arbeitskleid in den Schrank gegeben.”这里的Arbeitskleid不必是复数形式,因为按照分配读法,可以把这句话理解为,每个工人把他们相应的自己的工作服放进柜子。这种分配读法特别是在“具体非属类”的句子中是干扰因素。避免这种干扰因素的方式如下:在“具体非属类”的句子中有两种可以被接受的名词单数形式,即,“分配读法”和具有不同寻常的意思的语法正确的句子。在实验中只设置具有不同寻常的意思的语法正确的句子,因为英语中也存在于德语相同的“分配读法”,例如:They feel like grownups with their toothbrush and I do think it encourage them to brush longer and not wear out their toothbrush。 [22] 如果“Alle Besucher müssen vor Betreten der Bibliothek ihre Jacke ins Schließfach geben.”是题目中的句子的话,英语母语者很可能会认为这个句子是可以接受的,因为英语中也有“分配读法”;以中文为母语的被试会认为这个句子是可以接受的,根据猜想是因为他们认为“Jacke”可以不具有数的区分。如果中文母语被试认为这个句子不可以被接受,可能是因为他们没有学到关于“分配读法”的语法。如果两组被试都认为“ihre Jacke”不成问题的话,那也就不能检验出本论文的猜想是否正确。控制组的功能就在于此。(这与如下情况类似:找以越南语或者韩国语为母语的被试,虽然英语组和中文组的相同判断很可能是由于不同的原因。)归根结蒂,被考察的句子中的名词应该毫无疑问地是复数形式,所以“分配读法”的句子就得排除在试题之外。
如果诸如“Papa, warum hast du nur die Kirsche gekauft und nicht das Mehl.”作为被考察的句子的话,很可能英文被试和中文被试都认为这个句子不可接受,虽然这个句子的语法是正确的,因为这个句子所表达的意思很少见。这个句子奇怪,因为人们一般不只买一个樱桃,所以“Kirsche”最好是复数。如果句子本身语法正确,但是即使如此他们也认为这个句子奇怪,那就很明显,他们是从樱桃的“数”的角度看这个句子的意思了。如果被试不从“数”的角度审视这个句子,那这个句子就是正常的。所以这种带有不同寻常的意思的句子是可以被用作被考察的句子的,因为它可以直接测验出被试是否区分了“数”。事实上,在“抽象非属类”的句子中也存在这种带有非凡意思的句子,如:die Maßeinheit im Lehrbuch durchzählen,Meinung kombinieren。“抽象非属类”的数的问题貌似不是那么明显,可能是因为名词本身是抽象的。也有可能,中文被试马上就可以发现具有非凡语义的句子(具体非属类)中的非凡之处,以为这种情况下的错误本身比较明显。如果事实上不是这样,那猜想也可以被证实。
对于“具体非属类”的句子还有一个根本性的难题(这个难题其实也适用于“抽象非属类”的句子):在“具体非属类”和“抽象非属类”的句子中,被考察的名词必须毫无疑问地以复数形式出现,但在故意设置错误的句子中必须以单数形式出现,以此测出两组被试对“数”的不同理解。但是非属类用法的名词以单数形式出现是完全正常的!(一个逻辑上的问题。)所以,必须找到一些在正常情况下不以单数出现的名词。只有把这类名词设置成单数,才能说是“设置错误(Verfälschung)”。但这又是个问题,因为句子在语义上就变得非同寻常。测试被试是否认为区分“数”是否必要,其实也是在测试被试是否能发现这个问题,比如:Notiz machen,trotz Schwierigkeit,schönes Steinchen sammeln,Ausrede suchen...这些可以成为被考察的名词,因为“属类”的句子的特征就是,一个单数名词可以指代很多物体。在“非属类”的用法中,单数就是一个物体,复数就指代至少两件物体。如果在用一个具有“数”的区分的语言思考,那不同寻常的句子就是不同寻常的;如果用一个不具有“数”的区分的语言思考,,非同寻常的句子就不会造成非凡的感觉。所以,具有非同寻常的句意的句子的语法正确的句子适用于这个实验。
2) 要变成复数的名词不应与基数词一起出现,这样就不会给被试提示,这些词是可数名词,而只有可数名词才能变复数,与基数词在一起用。
3) 有一些限定词可以给被试提示,这些词是可数名词还是不可数名词,比如:alle,jede,einige,manche。这些词不允许在句子中出现。
4) 群体名词(Massennomen)可以脱离任何限定词作为“裸单数(Bloß-Singular)”独立出现,可数名词则一般不能单独出现(例外比如表示工作做的名词)。那些该变成复数,但是未被变成复数的名词不应该为了扮演不可数名词的角色以“裸单数”的形式出现,因为存在这种危险:英语母语被试不失出于“数”的原因而认为这些句子不舒服和不可接受:它们是错的,因为缺了定冠词。(例外情况是:当带定冠词的未被变成复数的名词无意义时。)一个例子:“ich habe Schere der Skorpione schon entfernt.”。英语母语被试应该会不太接受这样的句子,因为蝎子有两个钳子,而且蝎子在这里是复数。他们也可以认为这个句子不可接受,因为他们认为缺少定冠词的错误比不变成复数的错误更严重。这种判断不是基于对“数”的问题的判断,而是基于对定冠词的判断——言外之意他们不认为“数”的错误对他们造成了很大困扰。这是一个对于英语被试的干扰因素。所以,为了扮演不可数名词而故意省略定冠词的情况也应该被避免。
5) 名词在复数形式中应该是唯一正确的形式。因为存在这种情况,无论名词是在单数还是复数形式中句子在语法上还是在句意上都是正确的。比如:“Kannst du die Lampe im Zimmer anmachen? ”如果没有背景,灯可以是单数,因为存在屋子里只有一个灯的可能。也存在单数和复数都可以被接受的可能,即使没有特殊的背景:“Vorlesungen und Seminare sind die häufigsten Lehrformen an deutschen Unis.”对于这个句子德语母语者有不同的观点:一些人认为单数名词在此更好;另一些认为复数名词在此更好。这类意见不一的句子也不应在被考察的句子中出现。还有一种情况,即,当语言表述得模糊时,名词也可以不变成复数。比如:Der Winzer hat uns die Traube zum Nachtisch geschenkt。一般情况下和理论上一颗葡萄就是“一颗”葡萄。如果语言表达得精确的话,那葡萄必须是复数,因为没有人给他人只提供一颗葡萄作为饭后甜点。从句意上看,这句话很奇怪。但是如果语言表达得并非很精确,eine Traube可以被理解为ein Strauß Trauben或者ein Spieß Trauben。这种情况下单数的葡萄也是可以被接受的。这些特殊情况也应该在实验中被避免。
6) 如果名词与定冠词同时出现,名词的定冠词最好与复数名词的定冠词相同,这样变复数的错误就可以通过定冠词更好地隐藏起来。如果出现“der”、“den”、“das”,名词的“数”就会明显得多。比如:warum hast du nur den Apfel vom Aldi gekauft und kein Mehl?一般情况下人们不只买一个苹果,而是很多。所以习惯上苹果应该是复数。但是“den Apfel”以一种很明显的方式告诉无论英语母语被试还是中文母语被试,涉及到的是一个苹果,所以句中苹果的“数”就很明显地不合常理。如果这种提示很明显,那实验结果就会不严格,所以这种明显的提示因该尽可能地小。如果让名词的性与复数名词的性一致,“数”的问题被隐藏,被试还是能发现“数”的问题的话,那实验结果就更有说服力。比如:Papa,warum hast du nur die Kirsche gekauft und kein Mehl?“Kirsche”是阴性,与它的复数的性一致。
7) 应该被变复数的名词应该在宾语的位置上。如果被考察的名词是主语的话,那动词也必须与单数的名词相应地变位。这就给被试一种暗示,名词更应该是单数的(如果单数的主语也使句子有通常的含义的话。)如果名词是宾语,那这种干扰因素就会被避免。
8) 正如在理论部分已经阐述过的,两种语言中共有的或者类似的谚语和口语基于它们的典型特征不应该出现在实验的句子中。
在名词的“数”正确的句子中,上述标准可以忽略。
下列是所有句子的种类分类(数字是句子的序号):
版本1的句子:
具体非属类:7,23。具体属类:20,12。抽象非属类:16,34。抽象属类:26,30。
干扰句:1。单复数形式皆可(有争议的句子):1,17。随机正确的句子(版本2中所包含的):2,9,11,13,15,21,22,27,29,33。缺少定冠词的句子:3,32。具体属类句:4,10。错误的变格:6,14,18,28。带有不可数名词(Massennomen)的句子:8,5,19,24。时态:25。动词位置:31。
版本3的句子:
具体非属类:2,17。具体属类:32,9。抽象非属类:14,28。抽象属类:21,25。干扰句:2。单复数形式皆可(有争议的句子):6,16。随机正确的句子(版本1中所包含的):2,3,4,8,18,20,23,24,27,33。缺少定冠词的句子:13,19。正确的属类句:7,11。错误的变格:10,12,22,26。带有不可数名词(Massennomen)的句子:1,5,15,34。时态:30。动词位置:31。
实验中的其他干扰因素
除了对实验中的题目存在干扰因素之外,还有其他干扰因素。其他干扰因素可以部分地从理论部分中的理论引导出来,也可以是关于被试自身的干扰因素。
语言的相关性
基于中文和德语的不属于相同的语系而断定实验不会得到有趣的结果的想法应该站不住脚。中文属于汉藏语系,而德语属于印度–日耳曼语系。从外观上看,这两种语言非常不同,从内在的语法上看,两种语言也截然不同。两种语言的相关性很弱。根据相关理论,在亲缘关系不近的语言中语言迁移的发生概率很小。但这两种语言毕竟仍然有相通之处:两种语言在很大程度上是可以互译的,且以这两种语言为母语的人可以互相沟通理解,这说明,两种语言在语义上有相通之处,比如“Haus”可以被翻译成“房子”,“Kirsche”可以被翻译成樱桃。两种语言的的名词上的更深层次的区别是本体论上的区别。而就是两种语言的共性和区别有可能会导致语言迁移现象,而且是无意识的——中文母语的德语学习者可能会将自己母语的名词本体论也应用到德语名词上。
年龄
实验的被试均是20到30岁的成年人。他们的元语言能力(metalinguistische Kompetenz)已经成熟,所以可以保证更严格的实验结果。
阶段——德语知识的激活
在被试填写问卷的之前,实验操作者先与他们就日常主题进行会话,为了使他们的德语知识激活,原因是,“单语模式(monolinguistische Mode)”并不能代表一般情况。
语言水平
被试的德语水平均是从B1到C1的。被试的语言水平不应该太低,因为实验中的句子可能对他们过于困难,以至于德语初学者不能从变复数的正确与否的角度上判断句子的真确与否。初学者和C2水平的被试也不能代表大多数中国的德语学习者。
先前所学的语言
对于被试选择还应该提到的是,完全有可能他们之前学过其他的语言。这种情况对于中文被试显得特别严重,因为他们之前或多或少都学过英语,儿英语像德语一样也区分名词的“数”。这一点又导致一个更高的可能性:他们更少地受到母语的影响。这个干扰因素可以正如理论部分所讨论的那样,通过普遍化(Generalisierung)来回避:如果中文被试认为那些应该却未被变成复数的名词是可接受的,那原因就不可能是受到英语的影响。
被试的情感因素
在理论部分已经描述过,情感因素也可能影响到语言迁移的发生。如果被试被激怒,那语言迁移则更可能会发生。这种情感状态不能代表被试的正常状态,所以被试应该在实验前尽可能的被安抚。实验操作者可以与其进行关于平静的主题的对话。一个舒适的环境也对此有利。
3.2. 实验的进行
在填写问卷前:在实验设计者完成了三个版本的问卷之后,实验操作者进行了对符合标准的被试的寻找。被试被分为两组,一个英语组(作为对比组),一个中文组。每7个人完成一个版本的问卷:一共有21个英语母语者和21个中文母语者。
实验操作者在Oldenburg大学的Stud-IP上、和食堂的小黑板上、也在Facebook上贴出了广告,以此找到符合标准的英语被试。谁有兴趣参加这个研究,就可以与实验操作者联系,约定日期,完成实验。实验操作者的一个美国朋友也为寻找被试帮助了许多。
一些中文被试是实验操作者的朋友,有些是不莱梅中文基督教社团的朋友,其他的是实验操作者的以前的学德语的同学。
一些问卷是在线完成的。在填写问卷前,被试不被告知问卷的实际目的。至于问卷的介绍,只有问卷前的文字。在填写完问卷之后,被试重新将问卷通过网络寄回给实验操作者。
实验地点:一些中文和英文被试与实验操作者在奥尔登堡大学的图书馆和咖啡厅见面进行实验。实验被试与他们先用德语进行了日常会话,以便他们的德语知识被激活。实验操作者找了尽可能安静的位置和时间,以便他们的情感状态尽可能是平静的。在图书馆和咖啡厅的实验都是单独实验:每次实验都只有一人(最多两人)。与中文基督徒的实验是在一次晚饭后,在不莱梅的中文基督教社团里基于以上原则进行的。因为是多人实验,所以实验操作者也进行了欢迎词,为了使实验显得更正式,被试更严肃对待这次实验。无论中文被试还是英文被试在完成问卷之后都得到了巧克力或者糖果,作为答谢。
另外还应提到的是:在构建问卷期间,实验操作者还询问了8名德语母语者,被考察的句子中的关键名词是否应该或必须变成复数形式。问卷的最终版本是基于这8名德语母语者的反馈而成:那些句子中的关键名词必须变成复数,至少是应该(在那些语法正确但句意却很少出现的句子中)。
一些问卷是在线完成的。在填写问卷前,实验操作者与每个被试用德语进行视频或者语音通话,首先是互相自我介绍和简单的寒暄,然后表明实验操作者的这次问卷的意图,(被试并不被告知问卷的实际目的),这样还起到激活被试的德语语言模式的目的。至于问卷的介绍,只有问卷前的文字。在填写完问卷之后,被试重新将问卷通过网络寄回给实验操作者。
3.3. 实验结果的统计
3.3.1. 每个句子的结果
以下首先是单个句子的统计,然后是每个种类(Kategorien)的统计。为了保证视觉上的清晰性,英语被试和中文被试对三个版本的问卷中的被考察的句子的(kritische Items)判断被以表格的形式展示出来。“E.1” = 版本1的英语被试,“E.2” = 版本2的英语被试,“E.3” = 版本3的英语被试,“C.1” = 版本1的中文被试,“C.2” = 版本2的中文被试,“C.3” = 版本3的中文被试。X轴是选择相应接受程度的被试的数量,Y轴代表接受程度。比较所用的数学工具是Mann und-Whitney-U-Test (简称U-Test)。版本1和版本2的比较是双向的,版本1和版本3的比较是单向的。英语被试和中文被试的关于版本1的的判断也是用U-Test单向比较。
统计猜想:在只改变句子顺序的情况下,所有被试的统计结果应该不存在明显差异;英语被试对于正确句子和错误句子的判断应该展示显著的差异,即,他们应该对错误句子的判断应该是明显消极的;而中文被试对正确和错误的句子的判断不应该具有显著差异,即,他们倾向于接受错误的句子;英语被试和中文被试对于错误的句子的不同判断具有单向的显著差异:中文被试对错误句子的接受程度明显高于英文被试对错误句子的接受程度。
中文被试对“抽象属类”的错误句子的接受程度是最高的,而对于“具体非属类”的错误句子的接受程度是最低的。
A:具体非属类
1) 带有“Erdbeere(n)”的句子(如图1)。版本1中的序号:7。版本2和3中的序号3。
版本1和版本2的对比:
Mann-Whitney-U-Test表明,英语母语被试在版本1和版本2中的对“Erdbeere(n)”的句子的接受程度没有明显差异,即,句子的顺序不影响英语母语者的判断。(U(n1 = 7, n2 = 7) = 24, p < 0.05)。
Mann-Whitney-U-Test表明,中文母语被试在版本1和版本2中的对“Erdbeere(n)”的句子的接受程度没有明显差异,即,句子的顺序不影响中文母语者的判断。(U(n1 = 7, n2 = 7) = 22, p < 0.05)。继而可以对比版本1和版本3中的结果。版本1和版本3的结果对比:
Mann-Whitney-U-Test表明,英语母语被试在版本1和版本3中的对“Erdbeere(n)”的句子的接受程度具有明显差异,即,名词是否变复数确实影响英语母语者的判断。(U(n1 = 7, n2 = 7) = 0.5, p < 0.05)。
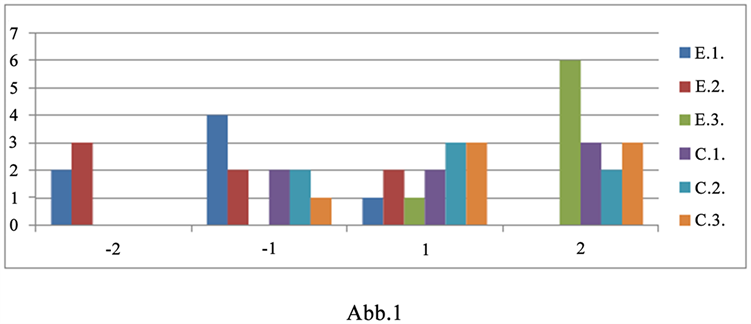
Figure 1. Acceptance level for the sentence with “Erdbeere(n)”
图1. 带有“Erdbeere(n)”的句子的接受程度
Mann-Whitney-U-Test表明,中文母语被试在版本1和版本3中对“Erdbeere(n)”的句子不具有明显差异,即,名词是否被变复数不明显影响中文母语被试的判断。(U(n1 = 7, n2 = 7) = 22.5, p < 0.05).
最后,在对比中文母语被试和英文母语被试对名词变复数错误的接受程度。
Mann-Whitney-U-Test表明,中文母语被试和英文母语被试对“Erdbeere(n)”的句子的接受程度具有明显差异,即,中文母语被试对此句的接受程度比英文母语被试对此句的接受程度明显更高一些。
关于实验中的其他关键句子(kritische Sätze)的对比结论也按照如上流程得出。下面列出各个关键句的具体数据:
2) 带有“Kirsche(n)”的句子(如图2)。版本1中的序号:23.版本2和3中的序号:18.
3) 带有“Schere(n)”的句子(如图3)。版本1中的序号:15。版本2和3中的序号:2。
这句话的对比结果显示,中文母语被试和英文母语被试在第一和第三版本中的判断没有显著差异,所以继续对比中文母语被试和英文母语被试的结果也没有意义。其原因将被后续讨论。
4) 带有“Klaviertaste(n)”的句子(如图4)。版本1中的序号:21。版本2和3中的序号:17.
B:具体属类
5) 带有“schöne(s) Steinchen”的句子(如图5)。版本1中的序号20。版本2和3中的序号:29。
6) 带有“Notiz(en)”的句子(如图6)。版本1中的序号:12。版本2和3中的序号:23。
7) 带有“teure Autos(teures Auto)”的句子(如图7)。版本1中的序号:29。版本2和3中的序号:9。
8) 带有“Mädchen, die(das)…”的句子(如图8)。版本1中的序号:22。版本2和3中的序号:32。
这句的对比结果表明,英文母语被试和中文母语被试对这句的接受程度不具有显著差别(U(n1 = 7, n2 = 7) = 22, p < 0.05),与本论文的猜想相悖。可能的原因将后续讨论。
C:抽象非属类
9) 带有“Regel(n)”的句子(如图9)。版本1中的序号:16。版本2和3中的序号:33。
这句的对比结果显示,英文母语被试在第一和第三版本中对“Regel”是否被变成复数的事实的判断不具有明显差异(U(n1 = 7, n2 = 7) = 17.5, p < 0.05)。所以后续的对比也没有意义。其原因将后续讨论。
10) 带有“Metapher(n)”的句子(如图10)。版本1中的序号:34。版本2和3中的序号:4。
此句的对比结果显示,英文母语被试对“Metapher”是否被变成复数在版本1和版本3中不具有显著差异(U(n1 = 7, n2 = 7) = 18, p < 0.05)。所以继续对比无意义。可能的原因将后续讨论。
11) 带有“Maßeinheit(en)”的句子(如图11)。版本1中的序号:2。版本2和3中的序号:14。
这句的对比结果表明,在版本3中英文母语被试和中文母语被试对“Maßeinheit”是否变复数的问题的接受程度不具有显著差异(U(n1 = 7, n2 = 7) = 16, p < 0.05),与本文猜想相悖,可能的原因将后续讨论。
12) 带有“Überlegung(en)”的句子(如图12)。版本1中的序号:13。版本2和3中的序号:28。
D:抽象属类
13) 带有“Voraussetzung(en)”的句子(如图13)。版本1中的序号:26。版本2和3中的序号:27。
14) 带有“Schwierigkeit(en)”的句子(如图14)。版本1中的序号:30。版本2和3中的序号:8。
15) 带有“Idee(n)”的句子(如图15)。版本1中的序号:11。版本2和3中的序号:21。
16) 带有“Aussage(n)”的句子(如图16)。版本1中的序号:27。版本2和3中的序号:25。
这句的对比结果显示,中文母语被试和英文母语被试在版本1中“Aussage”是否要变复数的问题的判断不具有显著差异(U(n1 = 7, n2 = 7) = 12, p < 0.05)。后续将讨论可能的原因。

Figure 2. Acceptance level for the sentence with “Kirsche(n)”
图2. 带有“Kirsche(n)”的句子的接受程度

Figure 3. Acceptance level for the sentence with “Schere(n)”
图3. 带有“Schere(n)”的句子的接受程度

Figure 4. Acceptance level for the sentence with “Klaviertaste(n)”
图4. 带有“Klaviertaste(n)”的句子的接受程度
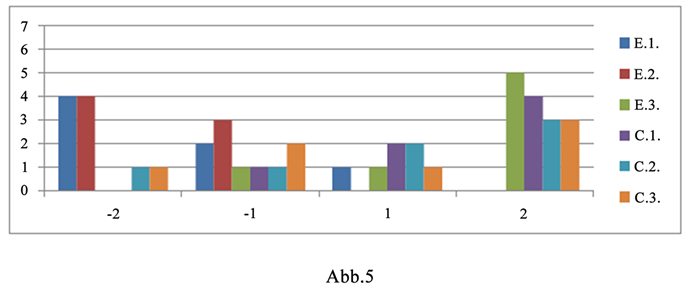
Figure 5. Acceptance level for the sentence with “schöne(s) Steinchen”
图5. 带有“schönes Steinchen”的句子的接受程度

Figure 6. Acceptance level for the sentence with “Notiz(en)”
图6. 带有“Notiz(en)”的句子的接受程度

Figure 7. Acceptance level for the sentence with “tuere Autos (teures Auto)”
图7. 带有“teure Autos (teures Auto)”的句子的接受程度

Figure 8. Acceptance level for the sentence with “Mädchen, die(das)”
图8. 带有“Mädchen,die(das)”的句子的接受程度

Figure 9. Acceptance level for the sentence with “Regel(n)”
图9. 带有“Regel(n)”的句子的接受程度

Figure 10. Acceptance level for the sentence with “Metapher(n)”
图10. 带有“Metapher(n)”的句子的接受程度

Figure 11. Acceptance level for the sentence with “Maßeinheit(en)”
图11. 带有“Maßeinheit(en)”的句子的接受程度
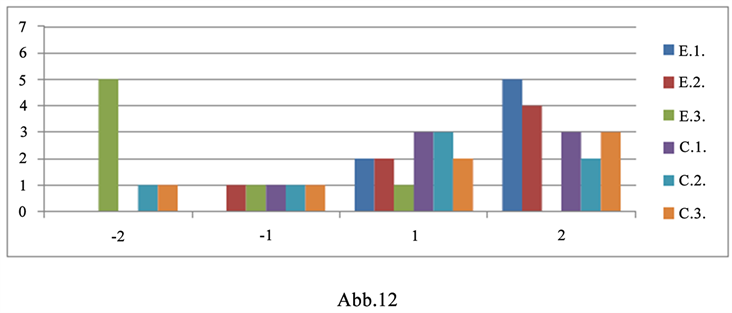
Figure 12. Acceptance level for the sentence with “Überlegung(en)”
图12. 带有“Überlegung(en)”的句子的接受程度
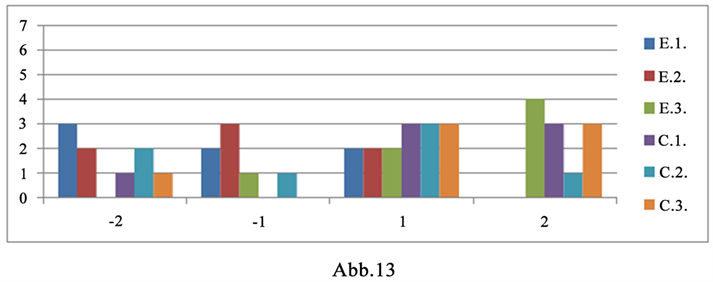
Figure 13. Acceptance level for the sentence with “Voraussetzung(en)”
图13. 带有“Voraussetzung(en)”的句子的接受程度

Figure 14. Acceptance level for the sentence with “Schwierigkeitg(en)”
图14. 带有“Schwierigkeit(en)”的句子的接受程度

Figure 15. Acceptance level for the sentence with “Idee(n)”
图15. 带有“Idee(n)”的句子的接受程度

Figure 16. Acceptance level for the sentence with “Aussage(n)”
图16. 带有“Aussage(n)”的句子的接受程度
3.3.2. 统计结果总结
在“具体非属类”的句子中有三句验证了猜想。在“具体属类”的句子中有三句验证了猜想。在“抽象非属类”的句子中有1句验证了猜想。在“抽象属类”的句子中有一句验证了猜想。
有一些关键句并没有验证猜想,但这不必然意味中文母语者对这种变复数的错误特别是在“抽象非属类”的情况下更不接受,因为还可能有一些潜在的原因导致与猜想的不一致。总体上看,统计结果偏向于更支持统计猜测,因为能验证猜想的句子占大多数。
为了知道中文母语者对于哪种类型的名词变复数错误最宽容和最不宽容,笔者计算了中文母语被试对于错误的关键句的接受程度的平均值。如果“抽象属类”的平均值最高,“具体非属类的”平均值最低,那就说明猜想被验证。
KN:
1:(−1) + (−1) + 1 + 1 + 2 + 2 + 2 = 6
2:1 + 2 + 2 + 2 + 2 + 2 + 2 = 13
3:(−2) + (−1) + 1 + 1 + 2 + 2 + 2 = 5
4:(−2) + (−1) + (−1) + 1 + 2 + 2 + 2 = 5
Summe = 29;Mittelwert = 29/4 = 7.25
KG:
1:(−1) + 1 + 1 + 2 + 2 + 2 + 2 = 9
2:(−1) (−2) + 1 + 1 + 2 + 2 = 4
3:(−2) + (−2) + (−1) + (1) + 1 + 2 + 2 = 1
4:(−1) + (−1) + 1 + 2 + 2 + 2 + 2 = 7
Summe = 21;Mittelwert = 21/4 = 5.25
AN:
1:(−2) + (−1) + (−1) + 1 + 1 + 2 + 2 = 3
2:(−2) + (−2) + (−2) + (−1) + (−1) + 1 + 1 = −6
3:(−2) + (−2) + (−1) + 1 + 1 + 2 + 2 = 2
4:(−2) + (−1) + 1 + 1 + 2 + 2 + 2 = 5
AG:
1:(−2) + 1 + 1 + 1 + 2 + 2 + 2 = 7
2:(−1) + 1 + 2 + 2 + 2 + 2 + 2 = 10
3:(−2) + 1 + 1 + 1 + 2 + 2 + 2 = 7
4:(−2) + 1 + 1 + 1 + 2 + 2 + 2 = 7
Summe = 31;Mittelwert = 31/4 = 7.75
结果是:AN < KG < KN < AG
这个结果不完全与统计猜想一致。这个统计猜想显示,母语是中文的被试关于“抽象非属类”的接受程度是最低的,这与论文的猜想不符。结果还显示,母语是中文的被试关于“抽象属类”的接受程度是最高的,这与猜想一致。如果仔细观察这种不一致现象,可以察觉到,“抽象非属类”的句子中有更多的潜在的具有“构造上的问题”的句子。而这会对结果带来消极影响,因为如果“抽象非属类”的句子中没有潜在的构造上的问题,那中文母语被试对于“具体属类”的接受程度就可能是最低的。更具体的论述见下一章。至此本论文的猜想的验证更倾向于积极。
3.4. 关于实验结果的讨论
3.4.1. 关于每一个有问题的句子的讨论
1) N带有“Schere(n)”的句子中的可能的问题
句子是:“ich muss die Schere(n) der Skorpione entfernen, sonst sind die Skorpione zu gefährlich.”英文被试版本1和版本3的判断没有显著的不同,即使变复数的错误是正确句子和错误句子中的唯一区别。一个可能的原因是,蝎子的钳子在英语中并不被称为“Scissors”,而是“moveble claw”或者“tarsus”。有可能英语被试认为“Schere”这个名称很奇怪,因为“moveble claw”或者“tarsus”与“scissors”没有关系。这可能是一个为什么有更多的英语母语被试在版本1的判断是倾向于不接受的原因,即使句子中的变复数情况是正确的。
2) 带有“Mädchen, die(das)…”的句子的可能的问题
句子是:“Toni mag nur Mädchen, die(das) über 170 cm gorß sind (ist).”母语是中文的被试和母语是英语的被试的判断不被句子的顺序显著影响。如果仔细观察图表,可以察觉到,英文被试对于正确的句子的接受程度是相当积极的。虽然以英文为母语的被试对于正确的和错误的句子的接受程度明显不同,他们对于错误句子的接受程度和中文母语被试对于错误句子的接受程度相比还是“相对积极”的。原因可能是,英语中的定语从句是通过“who”或者“that”来连接的,而这两个词不提供关于“数”的信息。这与德语中的可以通过关系代词提供关于“数”的信息的情况不同。基于这个英语和德语之间的不同,可以猜想,英语被试可能对关系代词是否提供“数”的信息这件事不太敏感,所以他们对于关系代词不提供“数”的信息的这种情况更宽容一些。
母语是中文的被试的积极判断和消极判断分布得很平均:有将近一半的中文被试认为错误的句子更不可接受。可能的原因是,从句末尾的“ist”是一个明显的关于“数”的指示:这里明显指的不是多个女孩。虽然在理论部分已经论述过被考察的名词应该尽可能不在主语位置出现,但这个从句确实是忽视了这条原则。
为什么即使有从句末尾的“ist”,英语被试还是更接受错误的句子呢?有可能是因为“ist”位于从句的末尾,如果整个句子的意思都应经被理解了,那一个小小的“ist”大概就不那么重要了,所以整个句子末尾的“ist”就很容易被忽视。
3) 带有“Regel(n)”的句子的可能的问题
句子是:“Ich habe die Regel(n) für die Verwendung der deutschen Artikel in diesem Grammatikbuch schon drei Mal gelesen.”英语被试对于正确的句子和错误的句子的判断没有显著的区别。希望的结果是,英语被试应该对这个单数的“Regel”倾向于不接受,因为试验设计者认为每个德语学习者都应该知道德语语法书中关于定冠词的用法的规则不仅仅只有一个。有更多的英语被试认为单数的“Regel”没有问题,可能是因为他们当时没有自己考虑过到底有多少个关于定冠词用法的规则。也有可能他们认为这里涉及到的就是一个特定的规则。实验设计者已经想到这种情况,他认为,把一本语法书中的某个定冠词用法的规则读三遍是一种奇怪的行为,与“Kirsche zum Nachtisch”的道理相同。另外一种可以解释英语被试的倾向于积极接受的原因是,他们对这种行为比较宽容,认为这种行为也是正常的。
4) 带有“Metapher(n)”的句子中的可能的问题
句子是:“Bitte arbeiten Sie die Metapher(n) im Gedicht von Schiller ‘An die Freude’ heraus!”。统计显示,较多的英语被试认为错误的句子是可以接受的。其原因也应该“regel(n)”句子的原因:英语被试可能认为句子里涉及到的只是《欢乐颂》中的一个比喻。而事实上实验设计者预想的是,作为一个给学生的题目的要求,只要求学生处理《欢乐颂》中的一个比喻是很少见的。一般情况下的题目要求应该是处理所有的比喻。如果只是一个比喻,那这个要求就显得比较奇怪,认为学生不知道具体要操作那个比喻(每个人也都应该知道诸如《欢乐颂》这样的诗里一般不仅仅只有一个比喻),可能英语被试没有想这么多。
值得注意的是,中文被试认为无论正确的句子还是错误的句子都偏向于不可接受。原因可能是,这两个句子中有“ausarbeiten”或者“Ausarbeitung”,但是中文中没有直接的这两个词的十分恰当的翻译,所以可以想象,中文被试觉得这两个句子并不是很舒服。
5) 带有“Maßeinheit(en)”的句子的可能的问题
句子是:“Wahnsinn, dass du die Maßeinheit(en) in diesem mathematischen Lehrbuch gezählt hast!”统计结果显示,英语被试和中文被试对于错误句子的判断的差别并非显著,在观察统计之后可以看出,英语被试中大于一半(7人中的5人)的人认为这个错误的句子是不可接受的,中文被试中大于一半(7人中的4人)的人认为这个错误的句子是不可接受的。中文被试中较宽容的趋势还是存在的,但是不显著。可能的原因是,这个句子的内容对于中文被试来说可能过于奇怪:问什么要数数学书中的数学单位呢?(虽然在句首已经写出“Wahnnsinn”。)
6) 带有“Aussage(n)”的句子中可能存在的问题
句子是:“Wir müsen Aussagen sammeln, die für die Untersuchung relevant sind.”中文被试和英文被试的判断的差异并非显著。但是较明显的趋势也是存在的:与中文被试相比有更多的英文被试认为错误的句子是不可接受的。有可能认为错误的句子是可以接受的句子的英文被试不知道“Aussage”有一个不同的复数形式。英语被试认为“Aussage”是可以接受的的这种情况倾向于不可能,因为这种情况违背了从前三个“属类句子”中得出来的原则:英语被试比较不接受“属类句子”中带有单数(本不该是单数)抽象名词的这种情况。如果这是真的,并且与中文被试的倾向接受的判断相联系,那结果也不与猜想冲突。
在观察上面的统计结果以后,可以注意到结果对于猜想的验证来说并不是十分理想。一个理想的统计结果应该是:英文被试和中文被试的判断都不受句子的顺序影响(这点已经被验证),英文被试都认为错误的句子是不可接受的,而中文被试都认为错误的句子是可以接受的。换句话说,两组被试对于错误的句子的判断应该具有单边显著差异。但并不是这样。一般的原因可能是:
1) 不是所有被试的水平都是绝对相同的,即使实验前已经确认过,所有被试都不是初学者水平。可能有些不太熟练的英语被试不知道某些单词有一个与单数形式不同的复数形式,一些中文被试的语感稍微好一些,所以他们更认为错误的句子是更不可接受的。这些因素可能会引起与本论文猜想的冲突。如果被试的水平被限制得更窄一些,比如都是B2或者C1,每个句子的结果可能会更显著一些。
2) 实验中的句子不是每一句都是最优化的句子,虽然在实验前就与若干德语母语者共同努力排除每个句子中的所有潜在的干扰因素。即使这样,被试的判断可能还是与猜想的期望不一致,因为还可能存在其他未被排除的干扰因素。
3) 有些被试可能略读(überlesen)了句中的错误,所以也存在被试判断并不完全反应被试的想法的可能性。
4) 同样的错误对于具有相同母语和相同外语水平的德语学习者的接受程度可能也存在差别,因为不同人对于相同事物的主观接受程度会不同。这也可以导致测量结果的某种程度上的不精确。
3.4.2. 结果的更广范围的意义
结果显示,中文被试由于其母语的原因对这种变复数的错误的接受程度确实更高一些。这可能导致一种语言迁移现象:以中文为母语的德语学习者在说或者写的时候会更明显地犯名词不变复数的错误,当相应的名词应该被变成复数的时候。以中文为母语的德语学习者的这种弱点为德语教师提出了一项任务:尽可能地区消除中文母语者的这种语言迁移(经常是无意识的)的的错误。对此的教学法应该被开发。中文母语的德语学习者应该意识到德语和中文的名词的本体论上的区别,以便于更好地避免这种错误。
4. 结论
本论文目的在于验证此猜想:以中文为母语的德语学习者总体上倾向于对应该被变成复数但却未被变成复数的名词的错误更宽容,以及这种确实是否是在“抽象属类”的句子中最强和在“具体非属类”的句子中最弱。结论是:以中文为母语的德语学习者果然对这种错误更趋向宽容;“抽象属类”句中的这种强的宽容确实已经被论文实验所验证,但“具体非属类”句中的弱宽容趋势未被验证。猜想中未被验证的部分的部分原因已经被讨论,至于已经验证的部分还需要更加严格的验证,因为毕竟由于客观条件有限,实验的样本数量没有理想得那么大,而且无论是中文被试还是英文被试,他们的德语水平也不是不可以怀疑,虽然根据被标准他们自己属于本文需要的被试。所以,类似主题的研究任然需要继续。
为了指明以中文为母语的德语学习者的对这种变复数错误的宽容符合语言迁移现象以及可能是一种语言迁移,在论文中笔者首先阐述了关于语言迁移现象的理论。接下来阐述了中文中的名词的含义:中文的名词其实是一种“集体名词(Massennomen)”,以及一个中文名词的含义是表示实体的种类,以此在理论上说明,以中文为母语的德语学习者的这种语言迁移现象很可能是存在的。然后论文中继续阐述在德语中名词何时该变成复数,以此可以了解以中文为母语的德语学习者更倾向于在何时犯这种变复数的错误。在理论部分的最后笔者阐述了关于“属类(Generizität)”理论,以对后续的实验提出部分理论上的标准。在实践部分笔者设计了一个为了验证论文假设的实验,继而对实验的数据、方法、操作过程、统计结果和实验中的问题和其更广泛的意义做了叙述和探讨。
正如论文中所呈现的,对于猜想的倾向于积极的验证为中国的德语教师提出了一项任务:尽可能地避免中国德语学习者的这种变复数的错误。相应的新的教学法对于未来的教学将会很有益处。同时也希望各位同行对本论文进行后续的指正和批评、进行更多相关的研究。