1. 引言
研究表明,牛奶体细胞种类和数量是牛乳质量评价和乳腺炎诊断的一项重要指标。当牛患有乳腺炎时,体细胞的数量会大大增加 [1] 。牛乳中的体细胞主要来自血液的白细胞,可分为中性粒细胞,淋巴细胞,巨噬细胞和乳腺组织脱落的上皮细胞 [2] 。奶牛乳腺炎是危害奶牛养殖的重要疾病。乳腺炎不仅使奶牛产奶量明显下降而造成严重经济损失,还可导致乳汁成分发生改变,使牛奶的营养价值和食用价值显著下降。据报道,我国每年因乳腺炎造成产奶量下降的损失,每头大约1200~3600元。每年因乳腺炎造成的经济损失在150~450亿元 [3] 。
目前国内外对牛奶体细胞的检测有多种方式,主要分为直接细胞计数法和间接细胞计数法。直接显微镜计数法 [4] [5] 是体细胞含量检测的标准方法,将牛奶的涂片经过脱脂、固定、染色后再进行镜检。但是这种方法操作繁琐,工作量大,容易因视觉疲惫而出错。常用的间接计数法为美国加州奶牛乳腺炎检测方法(CMT) [6] 、电导率检测法(EC) [7] 等。这种方法虽然操作简单、工作量小,但是检测的精度不高、容易出现误诊。
随着计算机技术的不断发展,图像处理在生物学和医学领域中得到了广泛地应用,在人体癌细胞 [8] 、人体白细胞 [9] 的分类识别中都的得到了较好的效果。文献 [10] 从灰度共生矩阵中提取出纹理特征,并结合形态特征,该方法对淋巴细胞和中心粒细胞分类效果不佳。文献 [11] 对12类红细胞进行识别,只提取了5类形态特征和2类纹理特征,对其部分红细胞分类效果不佳。本文提出了基于改进形态特征的牛乳体细胞分类识别算法,首先用K-means聚类算法将巨噬细胞、淋巴细胞、上皮细胞、中性粒细胞的细胞从背景中分割出来,并提取其形态特征、纹理特征,根据四类细胞之间的外形区别,改进了圆形度、矩形度表达式,实验结果表明,改进后的圆形度、矩形度表达式有效的提高分类识别率;运用随机森林分类器也能得到较为理想的分类结果。
2. 牛乳体细胞图像特征提取
特征是对细胞的定量描述,在对细胞的识别的过程中,特征是否恰当的提取和选用,是整个算法的关键之处,即:同类细胞的特征值差异越小越好,不同类细胞的类间间隔越大越好 [12] 。本文共提取了12个细胞图像特征,其中基于细胞核的形态特征8个,包括:周长、细胞与细胞核面积、细胞质的面积、核质比、伸长度、圆形度、综合矩形度;纹理特征4个,分别是四个方向的灰度共生矩阵中的能量、熵、对比度和相关性的平均值。
2.1. 形态特征
形态特征包含这很多重要的信息,很多细胞在形态、大小上有着很大的区别。特别是本文所研究的牛乳体细胞,从表1以及图1中可以看出,四类细胞的细胞核的大小、形状都有着很大的差别,其中淋巴细胞的细胞核大且圆;中性粒细胞的细胞核呈分叶状,哑铃形或椭圆形;巨噬细胞与上皮细胞的细胞核特征较为相似,均成圆形或椭圆形。因此形态特征的提取在本文中显得尤为重要。在提取这些参数之前需要确定图像中的关键点,例如细胞、细胞核的中心点、半径以及外接矩等。
2.1.1. 图像预处理
为了更有效的提取特征,需要从背景中把细胞和细胞核分割出来。本文采用的是K-means图像聚类分割算法。K-means主是基于划分的聚类方法 [13] 。该算法的基本思想是以空间中K个点为中心进行聚类,对靠近中心点的对象归类。通过迭代的方法,逐次更新每一个聚类中心的值,直到最好的聚类结果。假设要把图像D划分为k个不同类,k-means算法步骤描述如下:
1) 预先随机选择k个的归类中心;
2) 对于对象集中的任意一个对象,分别计算其到各个中心对象的距离,与距离最小的那个对象归为同类;
3)对于各个归类中心的值,计算每一个样本的均值,作为新的聚类中心;
4) 对于所有的归类中心,重复步骤2和3循环更新后,达到最大更新次数,则分割结束。
四类体细胞的灰度图像及通过K-means算法分割后的细胞核图像如图2、图3所示。

Table 1. Morphological property of milk somatic cell
表1. 牛乳体细胞形态特征

Figure 1. Original image of 4 different types of somatic cells
图1. 4种不同类型体细胞的原始图像

Figure 2. The segmentation results of 4 types of somatic cells
图2. 根据图1得到的4类体细胞分割结果图
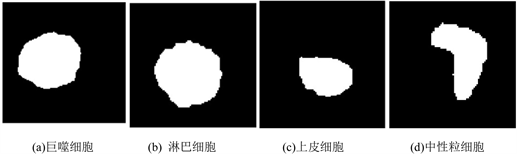
Figure 3. Nuclear segmentation results of four types of cells
图3. 四类细胞的细胞核分割结果
2.1.2. 形态特征提取
1) 面积
细胞面积是以区域面积特征来描述区域大小的。通常有两种方法进行提取,其一是对提取出来的目标像素进行计算,这种方法简单精确。其二是采用链码表,将目标物体看成是有很多条紧密相邻的水平线段组成。这样,区域内所有的水平线段的长度之和就是目标区域的面积,其公式为:
(1)
式中S为细胞面积;Xk1,Xk2分别为线段两端点的横坐标;k1、k2为线段的标示变量;m为线段的条数。
2) 细胞核周长
细胞周长由所包含区域的边界轮廓的周长来表示,其公式为:
(2)
式中P为细胞核区域的周长,Nl为细胞核边界上横、纵坐标相邻两点构成线条的条数;Nh为细胞边界上斜向相邻两点构成的线段的条数。
3) 核质比
不同类细胞的核质比有较大的差别,淋巴细胞核大浆少,核质比值就越趋近于1,巨噬细胞核小浆多,该比值就越小。
(3)
4) 伸长度
伸长度特征表示细胞核是否接近圆形。若该值为1,则细胞核区域为圆形,若该值越小,则细胞核区域呈纤细形。其公式为:
(4)
5) 矩形度
矩形度特征是描述一个物体形状的参数。当图像进行处理之后,即可求取细胞最小外接矩形。该值越接近1,则表示图像越接近矩形;反之,则表示图像是纤细或弯曲的。其公式为:
(5)
式中R为矩形度,SH为细胞核的面积,L、W是最小外接矩形的长和宽。
研究发现,上皮细胞的细胞核呈圆形或椭圆形,巨噬细胞的细胞核呈圆形、椭圆形、肾形,淋巴细胞的细胞核呈圆形或椭圆形单独计算细胞核或者整个细胞的矩形度,很容易把四类细胞混淆,为此本文改进了矩形度公式,提取了综合矩形度,其公式为:
(6)
式中,
为细胞核的矩形度,
为整个细胞的矩形度。
6) 圆形度
圆形度表示细胞核的复杂程度。面积不变时,周长越小,表示细胞核越接近圆;反之,周长越大,表示细胞核表面褶皱越多,形状越复杂。其公式为:
(7)
研究发现,上皮细胞、淋巴细胞的细胞核表面均为较为平滑的圆形、椭圆形。因此根据此圆形度公式所提取出的参数值较为相近,使这两类细胞分类效果不理想,为此,改进的圆形度的公式为:
(8)
(9)
式中,r为细胞核中心点(x0, y0)到细胞边缘最远点(xmax, ymax)的距离,将其作为外接圆的半径,即以细胞核自身面积与其外接圆面积的比值来表示圆形度。
2.2. 纹理特征
纹理特征的分析方法大致分为统计方法、结构方法和频谱法 [14] 。纹理特征是一种全局特征,它与物体本身的属性相关。该特征与颜色、灰度等图像特征不一样,它是通过像素以及周围空间领域的灰度分布来表现。本文主要采用统计方法中的灰度共生矩阵(Gray-Level Co-occurrence Matrix, GLCM)。
灰度共生矩阵是Harklick [15] 等人在1979年提出的一种特征提取算法,是用于描述图像全局纹理特征的早期算法之一。灰度共生矩阵展示的是包含一些特定空间位置关系的两个像素点的联合分布,是一种二阶统计量。与其他纹理特征不同,GLCM在提取得到特征后,一般不会直接用于后续的分类操作,而是在矩阵的基础上进行一些统计计算,将得到的统计量作为纹理识别的特征量。在提出灰度共生矩阵时就提出了14种统计量,后来 [16] 等人通过研究和实验发现,在14个基于灰度共生矩阵的统计量里,只有能量、熵、对比度和相关性四个是不相关的,这四个统计量不但便于计算,而且在分类时也能起到很好地效果。其中
表示归一化灰度共生矩阵。
1) 能量
又称为二阶矩,反映了图像灰度分布均匀性和规则性,是灰度共生矩阵里所有元素值的平方和,如公式所示。能量值越大表示该图像的纹理变化较为稳定。
(10)
2) 熵
是图像所具有的信息量的度量。如公式所示。熵值越接近0,表示该图像的灰度共生矩阵几乎为零阵,则该图像没有任何纹理特征。若熵值越大,表示该灰度共生矩阵中元素具有随机性且分散分布。
(11)
3) 对比度
是度量纹理清晰度和沟纹深浅程度的统计量,可以反映出纹理反差的程度,如公式所示。纹理沟纹越深,则对比度越大;沟纹越浅,对比度越低。从人类视觉的角度看,对比度越高的图像,其视觉效果更清晰。
(12)
4) 相关性
度量图像局部灰度相关性的统计量,可以反映出GLCM中元素在行或列上的相似程度。如公式所示。矩阵中元素的值均匀相等时,相关性值就大,矩阵中元素的值相差很大时,相关性值就小。
(13)
式中,
,
,
,
分别定义为:
(14)
(15)
(16)
(17)
本文主要采用灰度共生矩阵,为了保证特征参数的旋转不变性,分别在四个方向(0˚、45˚、90˚、135˚)上的矩阵中计算了以上四种统计量共16个特征参数值,并求出其平均值。串联后得到一个4维向量作为GLCM的纹理特征用于识别操作 [17] [18] 。
3. 分类器设计
3.1. 随机森林
随机森林(Random Forest)最早是由Leo Breiman和Adele Cutler提出,该算法结合Breimans 的“Bootstrap aggregating”想法和Ho的“random subspace method”。在机器学习中,随机森林是一种利用多棵决策树对样本进行训练并预测的分类器。这些决策树相互间独立,且在树的生长过程中和训练样本的选择上均采用随机的方法,降低了树结构分类器较高的方差 [19] 。每一个决策树之间是没有关联,是互相独立的。当有一个新的样本值输入时,随机森林里的每一棵树分别进行判断,选择越多就预测该样本为那一类。随机森林具有高效、多分类和对噪声不敏感等许多优良的自身固有的性质和理想的分类效果,使其在机器学习中使用频繁,效果显著 [20] 。
3.2. 交叉验证
交叉验证是比较常用的模型精度测量方法 [21] ,用来验证分类器性能的一种统计分析方法。在可用数据较少的情况下,通过对数据的有效重复利用,来测定模型的稳定性。交叉验证思想为 [22] 将原始数据进行分组,一部分作为训练集,另一部分作为测试集,用训练集对分类器进行训练,在利用测试集来测试训练得到的模型,以此来作为评价分类器的性能指标。
K折交叉验证是常见的交叉验证形式之一,它是将数据集平均分为K份,每次从样本集中取一份为测试集,余下的K − 1个为训练集,重复K次,依次取完所有K个子集作测试集,实验结果取这K个数据的平均值。
4. 实验结果与分析
实验主要验证基于不同特征值、改进后圆形度、矩形度的体细胞图像识别性能。实验数据包括120组样本,共四类细胞,每一类细胞样本30例。本文所有算法均由MATLAB R2011b实现,运行平台为Inter Core (TM) i3-3110M CPU @2.40 GHz,内存为2 G。
本文所提取的四类细胞形态特征平均值如表2所示,研究分析表2后发现,本文所提取的8种形态特征(其中圆形度及矩形度是改进后的参数值)差别均较大,能够充分表征这四类细胞及细胞核(如表1)的形态特点,淋巴细胞盒大质少,中心粒细胞的细胞核呈分叶状、哑铃形、椭圆形,巨噬细胞核上皮细胞外形虽较为相似,但上皮细胞的细胞核远小于巨噬细胞。表3是四类细胞纹理特征的平均值。
实验采用5折交叉验证对样本集进行分组训练并测试,5折交叉验证将数据分为5组,每组轮流作为测试集,剩余数据作为训练集。对每次分组得到的训练集和测试集用RF分类器进行训练和测试。一共是5次实验,实验结果取其平均值,排除单次实验结果不稳定性等因素。本次实验中RF分类器随机决策树的棵树设置为500。每一轮实验采用不同的特征属性。经过大量的实验测试,比较在同一分类器下不同特征的识别效果,实验结果见表4,从表2可以看出,颜色、形态和纹理特征的单独分类识别率较低,稳定性和可靠性差。
Table 2. The average of four cells morphology features
表2. 四类细胞的形态特征平均值
Table 3. The average of four cells texture features
表3. 四类细胞的纹理特征平均值
Table 4. The recognition rate under different characteristic parameters (5 cross-validation)
表4. 不同特征参数下的识别率(5次交叉验证)
表5是四类细胞改进前后圆形度、矩形度的平均值,分析可以发现,如果通过原始圆形度公式提取时,巨噬细胞
= 1.0847、上皮细胞
= 1.1968以及淋巴细胞
= 1.1698,这三类细胞在分类识别的过程中很容易混淆,分类总的准确率为88.68%。本文改进后的圆形度分别为巨噬细胞
= 0.6357、淋巴细胞
= 0.7858、中心粒细胞
= 0.4546和上皮细胞
= 0.7006,四类细胞的圆形度差别增大,类间间隔增大,更有利于准确分类总的识别率为95.29%,较原来的形态特征总识别率提高了6.61%。同时,仅仅通过提取细胞核的矩形度参数,巨噬细胞
= 0.7355、上皮细胞
= 0.7055以及淋巴细胞
= 0.7737,三类细胞差值较小,也容易使这三类细胞分类混淆,而本文改进后的矩形度巨噬细胞
= 0.6649、上皮细胞
= 0.7827以及淋巴细胞
= 0.7362、中心粒细胞
= 0.6217,综合矩形度参数融合了整个细胞矩形度特征后,更具有识别性,总的分类准确率为97.35%,较原来的形态特征识别率提高了8.67%。实验证明,改进的圆形度、矩形度参数明显地提高了分类的准确率。
从表6可以看出,随机森林分类器得到的识别结果最好,识别率达到了97.62%,其次是K近邻分类器,识别率为93.14%。在相同条件下,随机森林分类器优于传统的K近邻分类器和贝叶斯分类器。为了探究三种分类器的稳定性,本实验统计了100次交叉验证中每次的识别结果以及整体的标准差,其结果如图4及表7所示。
图4中横坐标表示第n次交叉验证,纵坐标表示该次验证得到的识别率。表7给出了三种分类器各自的标准差。可以看出,KNN分类器的标准差最大,识别结果比较不稳定。Bayes分类器和RF分类器标准差都较小且相差不大,但随机森林分类器的识别率远高于贝叶斯分类器。
Table 6. Comparison of different classifiers (100 cross-validation)
表6. 不同分类器的比较(100次交叉验证)
Table 7. Comparison of standard deviation of different classifier
表7. 不同的分类器标准差比较

Figure 4. Identification results of 100 cross
图4. 100次交叉验证识别结果
5. 结语
在进行牛乳体细胞的识别分类中,传统的分类方法主要依据研究人员的经验和知识,存在较多的主观性,容易出现漏诊、误诊的情况。通过对图像特征提取与分类识别方法的研究提取了形态、纹理特征。改进了圆形度、矩形度的表达式,然后将特征集输入到随机森林分类器中进行特征匹配。实验证明,改进的圆形度、矩形度表达式能明显提高分类效果,本算法识别率最高达到97.62%,有较高的准确性和可靠性。
基金项目
本研究获得国家自然科学基金项目(61461041)的资助。