1. 引言
信息化时代,人类社会每天产生的数据不断增多,达到了PB甚至EB的数量级。在海量数据中,相当大的一部分是以文本形式存在的半结构化或非结构化数据。为了提高处理海量文本信息时的效率,需要对这些文本信息进行必要的组织和管理。
文本分类技术是指根据文本内容自动将文本划分为一个或多个类别的技术,在自然语言处理领域的许多应用中发挥着关键作用 [1] 。目前文本分类方法中使用较为广泛的包括K-最近邻、朴素贝叶斯、决策树等。这些传统文本分类方法在中小规模的数据集上效果较好,但是由于文本分类过程涉及到大量的统计和计算,随着数据量的增大,传统的算法表现出很多不足,最主要的缺点就是分类耗时较高。如何在面对海量数据时快速高效地完成文本分类,对于文本信息的挖掘有着重要的意义。
Google先后发表的关于GFS [2] 、Map Reduce [3] 和Bigtable [4] 的三篇论文为大数据技术奠定了基础,随后Hadoop应运而生。Hadoop不仅提供了GFS和Map Reduce的开源实现,而且还发展成了包含存储、计算、资源管理等多功能的Hadoop生态圈 [5] 。Hadoop的Map Reduce计算框架出现较早,技术比较成熟,被广泛用于离线数据处理。自Hadoop出现至今,其核心组件之一的Map Reduce一直都是被广泛使用的并行计算框架,基于Map Reduce的文本分类并行化的研究也取得了一定的成果。Spark作为Hadoop生态圈中的新成员,是一个由加州大学伯克利分校推出的基于内存的大数据并行计算框架,它在执行多次迭代计算的任务时,不会将中间结果存储在硬盘上,而是放在内存中,极大地提高了后续过程的计算速度。在执行某些需要迭代计算的任务中,Spark的速度理论上可以达到Map Reduce的近百倍。
为了更直观地了解大规模文本分类在不同计算框架下的计算效率,论文基于Map Reduce和Spark两种不同的计算框架设计并实现了朴素贝叶斯分类算法,通过对照试验对单机环境以及两种分布式计算框架下的文本分类进行了效率对比。实验证明,基于Spark框架的朴素贝叶斯文本分类算法在应对大规模数据时效率较高。
2. 相关技术发展现状
2.1. 文本分类技术
文本分类是一个有监督的学习过程,分为训练过程和分类过程两部分。先对已知类别的训练语料进行学习,得到分类模型,然后利用分类模型对未分类的文本进行分类。
文本分类的过程可以用数学语言描述如下:
假设有一个类别已知的文本集合
(n集合中文本总数),一个文本类别集合
(m为类别的个数),在集合D和C之间有这样一种关系,用
表示为:
该式表示存在一个映射
把D中的每个文本
映射为C中的一个或几个类别。文本分类就是通过对训练集文本的学习,来建立这样一个与
近似的映射关系
,这个映射关系就是文本分类器,可以用于未知类别的文本集合的分类。
文本分类的一般流程可以用图1来表示。
早在1957年,H. P. Luhn [6] 发表的一篇有关信息检索的论文中提出了词频统计思想;在上世纪60到80年代,主要是根据专家提供的知识提炼出合适的规则建立分类器。1981年,侯汉清 [7] 教授向国内引入文本分类思想。基于机器学习的自动文本分类方法于90年代产生,并且逐渐发展成为主流的分类方法,这种方法是把一些重要的机器学习算法引入到文本分类中。90年代中期Joachims率先将支持向量机引用到文本分类领域,在有限样本的情况下取得了很好的效果。随后,Yiming Yang [8] 等人结合决策树算法完成了文本分类,也取得了不错的效果。2001年,庞剑锋等人 [9] 把VSM向量空间模型运用在中文文本分类;2013年,张志飞等人 [10] 采用了基于LDA主题模型的方法,对短文本进行分类;2017年,武建军等人 [11] 提出了基于互信息的加权朴素贝叶斯分类算法,具有良好的分类效果。
近年来随着计算机和信息技术的发展,数据规模不断扩大,此时单机环境的分类系统已经不能满足需求。面对单机无法处理的大规模数据,对于文本分类并行化的研究逐渐兴起。
江小平等人 [12] 在2011年实现了在Hadoop平台上对朴素贝叶斯算法的并行化来进行文本分类;2016年,长春工业大学的光顺利提出了三个因子改进卡方统计特征选择方法,并在Spark平台下实现了朴素贝叶斯分类方法。2017年,北京交通大学的宋福星 [13] 设计了Spark平台下的基于BP神经网络与在线分域特征选择算法(OFFS算法)相结合的OFFS-BP文本分类器。
2.2. 分布式计算框架
2.2.1. Hadoop Map Reduce计算框架
Hadoop Map Reduce是Apache基金会旗下顶级开源项目,属于应用较早、发展较为完善的一种分布式计算框架,现已广泛应用于搜索引擎、推荐系统、日志分析、信息检索等应用,能够有效的解决海量数据的存储、计算以及资源管理调度等问题。Hadoop Map Reduce可以使用户在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的资源进行高速运算和存储。
Map Reduce计算框架的核心思想是“分而治之”,就是把较大的任务分解成若干小任务,然后分发到集群的各个计算节点上分别进行计算,最后将结果汇总。整个过程可分为Map和Reduce两个阶段。在Map阶段会将待处理的原始数据按照一定原则分割成数据块,然后分发到各个计算节点上进行计算;Reduce阶段会把Map阶段得到的结果进行汇总,合并成最终的结果。
2.2.2. Spark计算框架
Spark是加州大学伯克利分校的AMP实验室所开发的类Hadoop Map Reduce通用并行计算框架。Spark既具有与Map Reduce相同的可扩展性、容错性、兼容性,同时与Map Reduce相比具有以下几点优势:
• 中间输出和结果存储在内存中,不再需要读写HDFS,极大地提高了任务的执行速度。
• 使用RDD (Resilient Distributed Datasets)作为分布式索引来对数据进行分区和处理,能够减少机器之间的数据混合(Data Shuffling)。
• Map Reduce在数据Shuffle时每次都花费大量时间来排序,而Spark任务在Shuffle中不是所有情况都需要排序。
因此,Spark能更好地适用于数据挖掘与机器学习领域许多需要迭代的算法。Spark的发展历程如表1所示。Spark的发展速度非常之迅速,目前,Spark已经成为代码活跃度最高的大数据处理框架。Spark官方维护运营公司Databricks已经组织并举办了从2013年到2017年的五次Spark Summit技术峰会。Spark的应用领域正在不断扩大,会逐渐应用到更多行业的各类应用场景中。
3. 文本分类算法流程
3.1. 文本预处理
文本预处理是在正式处理文本数据之前,对原始文本进行的一系列必要的操作,以方便后续的处理。对文本分类而言,任何算法都不能在一整篇文本上执行,必须要经过文本预处理,完成分词、去除停用词等步骤,才能将一整篇文本转化为一组特征项,输入到文本分类算法中去。

Table 1. Spark’s development course
表1. Spark的发展历程
3.1.1. 分词
英文文本的单词之间以空格分隔,在分词时可以直接按空格标点切分,难度相对较低;中文的词与词、短语与短语之间并不存在明确的分隔界限,难度相对较高。无论是中文还是英文,分词的结果精准与否,对文本后续的特征选择和模型训练过程有非常大的影响。因此,选择一种快速且精准的分词算法非常重要。
目前比较流行的分词工具有:IK Analyzer、Jieba、Ansj、Paoding Analyzer、NLPIR、盘古分词等。其中IK Analyzer实现相对简单,分词速度快,并且支持多语言分词,支持用户扩展词典。因此论文采用IK Analyzer实现文本的分词操作。
3.1.2. 去除停用词
停用词是指在文中大量出现,但几乎不携带任何信息的词,包括冠词、介词、代词等,如中文的“的”、“啊”,英文的“the”、“a”等。这些词的大量存在对文本分析用处极低,但却大大增加了计算量,因此要在预处理时将它们发现并删除。IK Analyzer分词工具支持在配置文件里配置自己的停词表,极大地降低了去停用词的计算量。
3.2. 文本特征选择
经过预处理后,原始文本中的长句被转换成一组组特征项。如果文档较长,必然会存在特征项的维度过高的情况,并且噪声项也可能会存在,这些都给后续的计算增加了难度 [14] 。为了提高分类速度和精度,应把在各个类别都比较常见的词语删除,只保留关键词语,这个过程称为文本特征选择。经过文本特征选择,筛选出针对每一类的特征项集合,大大降低特征项的维度,减少计算量。
3.3. 文本表示
文本表示是指将非结构化的文本表示成一种便于计算机理解和处理的数学模型,比如布尔模型、概率统计模型以及向量空间模型。目前比较常用的是向量空间模型VSM (Vector Space Model)。VSM可以将文本表示成特征向量的形式。这种特征向量的形式符合大多数机器学习算法的输入,为算法中的数学计算提供便利。但是VSM文档特征向量维数众多,在高维向量中每个特征项有不同的权重。因此,在表示文本时需要计算每个特征项的权重,并按权重来进行排序,选取权重较高的特征项作为最佳特征。
文本中的特征权重有多种计算方法,应用比较普遍的就是TF-IDF加权算法。其中的TF (Term Frequency)为特征项频率,即该特征项在某篇文本中出现的次数,反映特征项在文本内部的分布情况,计算方式如下:
其中
表示第j篇文本中的第i个特征项,
表示该特征项在文本
中出现的次数,
表示文本
中所有特征项出现次数之和。
IDF (Inverse Document Frequency)为特征项的逆向文本频率,反映了特征词在整个文本集合的分布情况。其定义如下:
其中M表示语料库中的文本总数,
表示包含词语的文本数目总和。
特征权重计算公式如下:
从TFIDF的经典公式中可以发现,如果一个特征项具有很高的词频TF,并且只是高频出现在一篇或几篇文章中,也就说明该特征项的IDF很高,那么该特征项的权重就会高于特征集中的其他项,具有很好的区分性和代表性,适合用来分类。
3.4. 分类方法选择
论文使用的文本分类方法是经典的朴素贝叶斯分类方法,它是由Maron和Huhns于1960年提出的一种基于概率模型的分类方法,后来被Lewis引入信息检索和文本分类领域。朴素贝叶斯算法以贝叶斯定理和特征条件独立假设为基础,先通过总结经验获得先验概率,然后根据贝叶斯公式计算相应的后验概率,得到该对象属于某一类别的概率,然后用最大后验概率的类别选为最终对象的类别。
朴素贝叶斯应用到文本分类时,基本描述如下:设有数据集D,类别数量为N,即D表示为
;数据集中的每个样本有n个属性,第i个属性是
。对于一个给定的待分类样本X和类别
,朴素贝叶斯分类算法使用最大的后验概率
来预测X所属的类别。
根据贝叶斯定理,文本X属于类别
的后验概率计算如下:
先验概率计算如下:
其中,
为属于类别
的训练样本的数量,N为训练样本的总数。基于特征条件独立假设,条件概率计算如下:
建立朴素贝叶斯分类器有两种方法,其一是多项式模型,另一个是多元伯努利模型。这两种模型的区别是对
的计算,而多项式模型要优于多元伯努利模型。因此论文在对条件概率进行贝叶斯估计时采用的是多项式模型,计算方法如下面公式所示。公式中分子和分母分别加1和加|V|进行拉普拉斯平滑。
4. 基于Spark的朴素贝叶斯算法设计与实现
朴素贝叶斯算法是一种基于统计的算法,基于特征条件独立假设,该算法具有较高的分类准确率 [15] 。但其传统串行的实现方式由于时间复杂度较高,只局限于中小规模的数据集,在处理海量数据时该算法的分类效率大大降低。为克服传统算法无法高效处理海量数据的缺点,论文研究了在Spark并行计算框架的基础上朴素贝叶斯算法的并行化实现,从而来提升海量数据的文本分类速度。
4.1. 数据预处理
实验将原始文本集存储在HDFS上,文本集中有若干分类目录,目录下包含属于此类的若干文档。在文本预处理阶段,先对文本进行格式化,将文本转化成统一的格式,然后再进行分词和去除停用词等操作。
预处理流程如下:
• 通过读取目录的方式将文本集读入,分别用不同的int型数值作为每一类的类标号label;
• 利用中文分词工具对文本集进行分词;
• 按照贝叶斯模型的输入要求转换输入格式:每个类别形成一个新文本,新文本中每行存放一篇文本,每篇文本的格式为
,即类别名和文档分词后的词组成的集合;
• 预处理完成后,会在新目录transformed Train下生成与类别数相同的多个文本,这些文本以类标号label命名,如0.txt~19.txt。将预处理过后的数据上传至HDFS中。
4.2. 文本向量化
原始数据在预处理之后,其形式还是文本,不能直接输入到分类器中,因此需要先通过文本特征抽取,将文本形式转换为向量形式。
常用的特征提取的方法有TF-IDF、Word2Vec以及Count Vectorizer等,论文使用的是TF-IDF算法,该算法原理和实现较为简单,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
假设用t表示词语,d表示文本,D表示语料库。词频TF(t, d)是词语t在文档d中出现的次数。文件频率DF(t, D)是包含词语t的文档的个数。IDF的计算公式如下:
其中,
是语料库中的文档总数,为了避免分母为0进行加1平滑。
TF-IDF度量值表示如下:
在Spark计算框架下,TF-IDF被分成TF和IDF两部分进行计算。
TF:将输入的文本转换成固定长度的特征向量,通过应用hash函数将原始特征映射到index,即index就是单词的哈希值,value是根据映射的index计算的单词频数。
IDF:作用于一个数据集并产生一个IDF模型,该IDF模型接收由上一步产生的特征向量,计算每个词在语料库中出现的文本数目。
文本向量化的流程如图2所示。
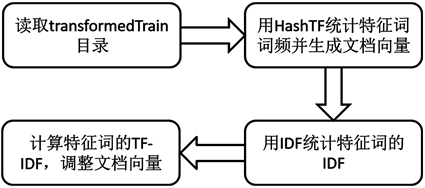
Figure 2. Flow chart of text Vectorization
图2. 文本向量化流程图
4.3. 模型训练
Spark MLlib模型训练的输入数据的格式是RDD(label,features)。训练完成后,生成朴素贝叶斯分类模型。具体步骤如下:
• 准备训练数据trainDataRdd,训练数据的格式是RDD(label,features);
• 调用类伴生对象NaiveBayes的静态train方法,根据输入参数,初始化NaiveBayes类,然后开始训练模型。训练完成后,生成一个贝叶斯分类模型。
5. 实验与分析
5.1. 实验环境
实验环境是由3台配置相同的计算机组成的集群,一台计算机作为Master节点,另外两台作为Slave节点,每台计算机的硬件配置均为内存8 GB,硬盘500 GB,操作系统采用ubuntu-14.04.1-server-amd64版本。软件采用的Hadoop版本为2.7.1,Java版本为1.8.0,Spark版本为2.1.0,Scala版本为2.11.7,使用的Spark开发环境是IntelliJ IDEA,Maven版本为3.3.9。
集群中各节点的IP地址如表2所示。
节点部署情况如图3所示。Master运行Namenode节点、Master进程和Worker进程,Slave运行DataNode和Worker进程。
Table 2. Host-IP address corresponding table
表2. 主机-IP地址对应表
5.2. 实验语料
论文使用复旦大学自然语言处理实验室的文本分类语料库作为实验数据集,其中训练语料共9804篇文档,包含教育、环境、军事、政治、体育等20个不同类别的文本集合,共计约133 MB;测试语料9833篇文档,共计约135 MB。论文在原始数据的基础上将测试语料分别复制到10倍,20倍,30倍的规模,用以测试不同计算框架在面对大规模数据时的运行效果。
5.3. 实验设计及结果分析
5.3.1. 实验一
为了对比不同计算框架运行文本分类程序的效率,论文中使用同一种分类算法,在单机、Map Reduce、Spark三种计算框架下对相同数据集进行分类效率的对比实验,分别记录运行时间和分类准确率。
• 单机环境
在单机环境下编写并调试了朴素贝叶斯算法。在使用训练语料进行模型训练过后,使用10倍规模(1350 MB)的测试数据的数据集为输入,进行了多次测试,记录运行时间和分类准确率。具体试验记录如表3所示。计算均值后得出平均运行时间是2,873,036 ms,准确率是89.29%。
• Map Reduce计算框架
在eclipse上把单机版朴素贝叶斯算法进行分布式改写,使其符合Map Reduce计算框架的运行模式,将原始数据集放至HDFS上作为输入,启动Hadoop集群运行程序,记录运行时间和分类准确率,如表4所示。由运行结果可以得知,相同的数据集在Map Reduce下的运行时间是141,912 ms,准确率是88.16%。
• Spark计算框架
在IDEA中编写并调试了朴素贝叶斯算法的Spark版本。对原始数据集在Spark平台上进行文本分类,将写好的程序打成jar包用spark-submit提交给集群运行,记录运行时间和分类准确率。由运行结果可以看到,相同的数据集在Spark上面的运行时间是69,583 ms,准确率是87.03% (表5)。
• 结果分析
基于Spark计算框架的朴素贝叶斯算法比单机上的速度快得多,大约是单机的35.7倍,是Map Reduce计算框架的2倍。很明显,在处理大规模数据集时,单机环境已经很难升任。实验数据充分显现了Spark并行计算框架相比单机环境和Map Reduce框架在处理速度上的优越性。
Table 3. Experimental results under single machine environment
表3. 单机环境下实验结果
Table 4. Experimental results in Hadoop map reduce environment
表4. Hadoop Map Reduce环境下实验结果
Table 5. Experimental results under spark environment
表5. Spark环境下实验结果
Spark计算框架和Hadoop Map Reduc计算框架相比,运行时间缩短大概一半。至于Spark的运行速度没有达到理论上那么高,可能存在以下几个原因:一是由于迭代计算过程各节点间的通讯占用了时间;二是实验所用数据量还不够大,不能充分发挥Spark计算框架的优势;三是Spark计算框架对硬件要求较高,当内存较小时也可能存在计算速度较慢的情况。
以上是基础性实验,通过对比一定规模的数据集在单机、Map Reduce框架和Spark框架下的运行速度,验证了Spark在提高文本分类速度上的优势。为了更显著地体现Spark的良好性能,在下面两组实验中采用控制变量法,以“数据量”和“计算节点数”为变量,分别在Spark计算框架下做了两组实验,并分析不同变量对于两种不同计算框架性能的影响。
5.3.2. 实验二
实验二在Spark平台上较大规模的数据集进行测试,Spark的计算节点数设置为3个。将原始数据的10倍规模、20倍规模和30倍规模记为数据集1、数据集2、数据集3。每个数据集分别在两种不同的计算框架进行三次试验,计算平均运行时间,并将结果用折线图的形式直观地表示,分析数据量的增大对运行速度的影响。三个数据集的平均运行时间表6所示。以数据集1的处理速度为基准,Spark在处理数据集2和数据集3时,运算速度分别提高了5%和18%。实验证明Spark在进行文本分类时,数据规模越大优势越明显。
5.3.3. 实验三
实验三使用相同的数据集在不同节点数量的Spark集群下运行,变量是集群中参与计算的节点数目,数据采用数据集3。分4组实验,第一组有1个master和1个worker,第二组是1个master和2个worker,第三组是1个master和3个worker,第三组是1个master和4个worker。分别记录每组的运行时间,并将结果转化为速度以折线图的形式表示,分析节点数增加对运行速度的影响。第一组速度假设为1,各组速度比较如图4所示。
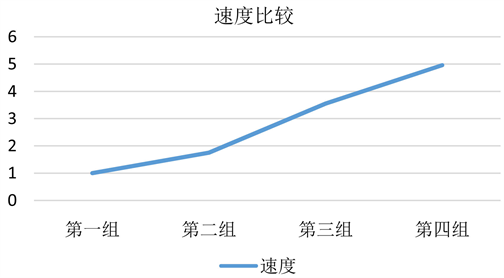
Figure 4. The influence of the number of calculated nodes on the speed of operation
图4. 不同计算节点数对运行速度的影响
Table 6. The average running time of the three groups of experiments
表6. 三组实验平均运行时间
从运行速度来看,相同的数据集进行测试,随着集群数量的增加,文本分类的运算速度呈增加趋势。而且通过速度增长的趋势可以看出,集群的加速比也在不断提高。从实验结果得出,Spark在处理朴素贝叶斯分类算法上具有良好的加速比,增加Spark上的worker节点数目能够明显加快文本分类并行化的速度。
6. 总结
针对当前日益增多的海量文本数据,论文在朴素贝叶斯分类算法的基础上,利用scala编程语言和Spark MLlib算法库,设计并实现了基于Spark的朴素贝叶斯文本分类器。在实验环节,用控制变量法对不同计算框架的运行速度进行比较,并对Spark平台下文本分类的效率进行测试。实验表明Spark能显著提高海量文本的处理效率和处理能力,并且具有良好的可扩展性。
虽然实验结果比较理想,但论文的研究仍然存在一些不足之处。比如实验数据量不够大,算法和试验的细节优化做得还不够好,在接下来的研究中会不断完善。