1. 引言
随着互联网与社交媒体的快速发展,每天会产生大量的信息。大多数人是从社交媒体接收信息和新闻,并且虚假的信息往往比真实的信息传播更快 [1] 。虚假新闻的广泛传播会误导大众,还可能引起社会恐慌,扰乱社会治安 [2] 。因此迫切需要采用自动虚假新闻检测方法,以避免造成严重的负面影响。
虚假新闻检测与文本分类都可以看成是将文章划分为某一类,但是存在差异,因为在很多情况下,虚假新闻检测任务可能在从未见过的各个领域中进行虚假新闻检测 [3] 。此外,现有的深度学习方法通常侧重于依赖新闻内容的语言语义特征和社交上下文信息,而不能有效利用外部知识帮助确定新闻的真假,当人们在判断一个新闻是否可信时,通常会根据新闻中引申出的背景知识进行对比,来判断新闻的真假。因此新闻中潜在的背景知识,是判定新闻真假的一个重要因素。而维基百科等包含大量高质量的结构化主体、谓词、对象三元组和非结构化实体描述 [4] ,作为检测虚假新闻的证据,且涉及历史、科学、文化等众多领域,可以作为新闻的背景知识,融合进新闻中,丰富新闻的表示。
因此本文提出利用异构图,融合新闻的背景知识,来建模新闻的表示。首先将新闻中的每个句子拆分成句子节点,并获得新闻句子中的实体。再将实体链接到维基百科获得非结构化的背景摘要信息,作为非结构化背景节点。接着利用实体搜索维基百科的结构化三元组数据库DBpedia,将获得的结构化的三元组信息构建成知识图谱,使用TransE [5] 模型训练三元组的特征向量表示,作为结构化的三元组节点。最后将这三种类型的节点为每一篇新闻构建一个异构图,即融合了有用的外部知识来丰富新闻的表示。利用基于语义距离的图卷积网络注意力模型DGAT,对建模后的新闻进行特征向量更新,以捕获融合了外部知识的新闻中的内容一致性。最终输入分类器中进行虚假新闻检测。
2. 虚假新闻检测相关研究
与虚假新闻检测相关的任务有很多,如谣言检测、事实核查等。总体的工作都是从新闻的内容及相关信息中提取特征判断新闻的真假,可以将现有的模型方法分为两类:基于社交上下文信息与基于新闻内容的虚假新闻检测。
2.1. 基于社交上下文信息的方法
社交上下文信息指的是新闻的发布者,新闻的传播网络,以及其他用户对新闻的评论和转发等信息。虚假新闻的发布者往往也会按照真实新闻的写法撰写虚假新闻,高可信度的用户发表的新闻内容更有可能是真实新闻,且社会学研究表明真实新闻和虚假新闻在社交网络的传播情况往往是不同的。因此利用社交上下文的信息对虚假新闻进行检测是一个有效的途径。
Lu [6] 提出GCAN模型构建用户图,将用户的简介作为图的初始化节点信息,并采用GCN模型学习用户的特征向量表示,最后利用得到的特征向量进行虚假新闻检测。Jiang [7] 用异构图建模了新闻的传播网络和用户的社交网络,并将新闻信息和用户信息拼接到一起进行虚假新闻检测。Khoo [8] 利用Transformer建模时间序列,将源新闻以及其他转发句子作为Transformer的输入,将Transformer输出的新闻嵌入向量输入分类器中,得到新闻分类结果。Bian [9] 提出将新闻的传播过程建模为两个同质图,利用GCN模型融合图中的节点信息,获得节点表示。最后将节点表示进行池化、拼接,输入分类器中,得到最终的分类结果。Kang [10] 提出了利用新闻与领域、新闻与转发贴子、新闻与发布者之间的关系构建新闻异质信息网络,并使用异质图卷积网络获得新闻节点的特征向量,输入分类器中,得到分类结果。
2.2. 基于新闻内容的方法
基于新闻内容的方法是利用文章中所包含的文本信息以及图片视频等多模态信息作为模型的输入,进行虚假新闻检测。
Ma [11] 首次将深度学习技术应用到虚假新闻检测中,将新闻的每个句子输入循环神经网络RNN,LSTM或者GRU中,利用循环神经网络的隐藏层向量表示新闻信息,将隐藏层信息输入分类器中,得到分类结果。R.Shah [12] 利用VGG19提取视觉信息,BERT提取文本信息,将视觉信息和文本信息拼接,输入分类器中,对新闻进行分类。Zhou [13] 提出利用新闻的图片信息与文本信息的相似度,区别新闻真伪。首先利用Image2text模型将视觉信息转化为文本信息,并通过全连接层将文本信息和视觉信息映射到同一向量空间中,并对比视觉信息和文本信息之间的相似度。如果相似度较高,为真实新闻,反之为虚假新闻。这些方法往往忽略利用隐藏在新闻内容中,可挖掘的新闻背景知识。本文提出了利用异构图融合新闻外部背景知识丰富新闻的表示,并利用改进的GCN模型进行虚假新闻检测。
3. 本文提出的虚假新闻检测方法
本节将详细介绍本文提出的虚假新闻检测方法,包含异构图的构建和改进GCN模型的思路。
3.1. 新闻异构图的构建
对于数据集中的每篇新闻,都建立一个无向的异构图G = (V, E)。其中V是节点的集合,E为边的集合。节点的集合是由三种类型的节点构成:句子类型节点S = {s1, s2, … , si},非结构化背景节点B = {b1, b2, … , sj},结构化三元组节点T = {t1, t2, … , tk},即
。对于数据集中的一篇新闻,按照句子将该篇新闻划分成若干个句子节点。
如图1(a)所示,取第一个句子节点“Trump came through… on the upcoming Republican convention and the position of Donald Trump”为例。识别出句子节点中有两个实体“Republican”和“Donald Trump”,利用TagMe工具 [14] 将两个实体链接到维基百科便可以获得这两个实体的背景描述摘要。DBpedia是维基百科的结构化三元组数据库,用实体“Republican”和“Donald Trump”搜索DBpedia,可获得大量关于该实体的相关三元组信息,再将三元组构成如图1(b)所示的知识图谱。为了对知识图谱进行特征向量的学习,本文选用高效的TransE模型,对于每个三元组实例(head, relation, tail),TransE模型是将relation看作为head到tail的翻译,通过调整它们的向量表示使得head + relation = tail。最后将参与知识图谱构建的实体学习到的特征表示作为结构化三元组节点参与新闻异构图的构建。
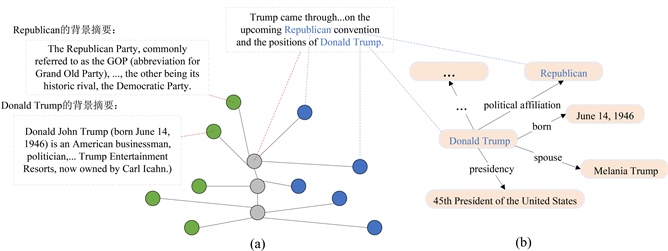
Figure 1. Diagram of news heterogeneous graph and knowledge graph
图1. 新闻异构图与知识图谱示意图
3.2. 异构图卷积模型DGAT
GCN模型 [15] 是一个可应用在同构图上的图神经网络模型,对于一个给定的图G = (V, E),其中V为图中节点的集合,用
表示图中节点的个数,E为图中边的集合。用矩阵
表示图中所有节点的特征向量,即矩阵X的第i行表示第i个节点的特征向量,
为初始特征向量的维度。再引入邻接矩阵
表示边的集合E,若Aij为1则表示第i个节点与第j个节点是邻居节点,也表示两个节点之间的权重值为1,若为0则表示两个节点不相邻。由于图中节点在学习中更新自身向量表示时,不仅利用到邻居节点的向量表示,也需要利用到自身的向量表示,因此加入单位矩阵I使得邻接矩阵的表示为(I + A)。由于这样会让有更多邻居的节点具有更大的特征,因此再引入度矩阵D,对邻接矩阵(I + A)的行和列进行归一化处理,且
为对角矩阵。这样每一个GCN层的输入为特征矩阵
,输出特征矩阵为
,可得不同GCN层间的传播规则如公式(1)所示:
(1)
其中,
为可学习的参数矩阵,
为激活函数,
。
本文构建的图模型为异构图,节点由几种不同类型的节点构成(句子节点、非结构化背景节点、结构化三元组节点),但GCN模型不适合直接应用在异构图上。为了将GCN模型适用于本文提出的异构图,首先将不同类型的节点投影到一个相同的公共的空间中,如图2所示。
在公共空间中能够保持语义上的相似性以及去除掉更多的冗余信息。对于节点集合V中的不同类型的节点,V = {vs, vb, vt},考虑到不同类型节点的差异性,采用给不同类型的节点乘以不同的变换矩阵,最终将不同类型的节点映射到相同的空间
上,如公式(2)所示:
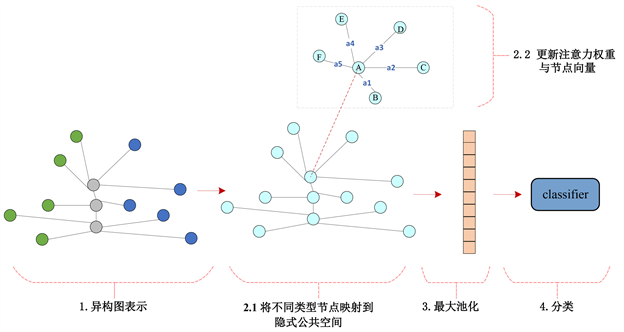
Figure 2. Diagram of news heterogeneous graph and knowledge graph
图2. DGAT模型的整体示意图
(2)
其中,Av是对应不同类型节点的选择矩阵,矩阵大小与
相同,Av的不同类型选择矩阵对应
所在位置的值为1,其它位置值为0,
。最终将异构图的不同类型节点映射到相同的公共空间。
对于异构图中的一个节点,不同的邻居节点对自身特征向量的更新会有不同的权重,因此引入注意力机制赋予不同类型邻居节点不同的权重。上文构建的异构图融入了非结构化的背景信息与结构化的三元组信息,为了能够在训练中学习到语义冲突或者相符的地方帮助进行虚假新闻检测,采取根据给定节点与邻居节点之间的距离(如余弦相似度距离)计算注意力的权重值。令距离矩阵为
,注意力权重矩阵为
,其中sij表示第i个节点与第j个节点之间的距离,
表示第i个节点与第j个节点之间的权重。
对于给定的第i个节点,利用余弦相似度计算节点之间的距离,即第i个节点与其他节点之间的距离表示为si = {si1, si2, … , sin},最后将距离输入Softmax函数,以获得对应的权重值
,如公式(3)所示:
(3)
对于异构图中的节点,不同的邻居信息会对自身的特征向量更新产生不同程度的影响。考虑语义相差较大的句子,在向量距离计算上,会有更远的距离。因此对于建模后的新闻异构图,在语义相差较大的地方,通过训练学习,赋予更加合理的权重,进行虚假新闻检测。使用最大池化作为分类前的最后一步操作。对于损失值的计算,采用交叉熵损失函数,如公式(4)所示:
(4)
其中,N为训练集中新闻的篇数,P为新闻标签的种类数,Y为新闻标签类别矩阵。
4. 实验
本节在数据集Labeled Unreliable News Dataset (LUN) [16] 上进行了大量实验。该数据集的标签有四种分类,分别为Trusted、Satire、Hoax、Propaganda。将数据集按照8:2的比例划分成LUN-train训练集与LUN-test测试集,具体统计信息如表1所示。

Table 1. LUN dataset statistics used in the experiment
表1. 实验中使用的LUN数据集统计信息
4.1. 基线模型
选用神经网络模型CNN [17] 、LSTM [18] 、BERT [19] ,以及图神经网络模型GCN [20] 和GAT [21] 作为基线模型与本文的DGAT模型进行对比,基线模型的介绍设置如下:
∙ CNN模型:使用一层CNN卷积层并将过滤器的尺寸设置为3,通过最大池化层获得每个新闻的向量表示,再将新闻的向量表示传递给一个全连接的投影层,最终获得预测分类。
∙ LSTM模型:使用一个LSTM层编码新闻的表示,并利用最后一个时间步的隐藏状态作为新闻特征向量,然后将其传递到一个全连接的投影层,最终获得预测分类。
∙ BERT模型:使用BERT获取新闻中每个句子的向量表示,并在句子嵌入上应用LSTM层,最后使用投影层完成对每篇新闻的分类。
∙ GCN模型:利用本文构建的新闻异构图,由于使用固定的邻接矩阵,在更新节点的向量表示时,利用的是邻居节点向量的加权求和。
∙ GAT模型:在GCN模型的基础上,区别在更新节点向量表示时,使用注意力机制计算每个节点对于邻居节点的重要性,并根据重要性加权求和邻居节点的特征,从而更新节点的特征表示。
4.2. 超参设置
对于超参设置,模型中使用的所有隐藏维度都设置为100,节点嵌入维数为32。对于GCN、GAT和本文的DGAT模型,设置激活函数为LeakyReLU,斜率为0.2,并使用学习率为0.001的Adam优化器。此外所有模型的池化操作都采用最大池化。
4.3. 实验结果
选用Micro-F1与Macro-F1衡量本文的DGAT模型与基线模型的结果,如表2所示。
Table 2. Test results on the dataset
表2. 在数据集上的测试结果
可以看出本文提出的DGAT模型在Micro-F1与Macro-F1指标上都明显优于基线模型。与最佳基线模型相比,DGAT模型将Micro-F1与Macro-F1都提高了近2%,还可以发现基于图卷积网络的模型GCN和GAT的性能都优于包括CNN、LSTM和BERT在内的深度神经网络模型。由于图神经网络模型可以利用图中的节点进行信息的交流传递,而这对于虚假新闻检测很重要。本文的DGAT模型,能够获取到建模后新闻的语义相关性,根据语义的距离赋予合适的权重进行信息传递,为虚假新闻检测提供了检测依据。
5. 结论
在本文中,提出的融合新闻潜在的背景知识构建包含新闻句子节点、非结构化背景节点、结构化三元组节点的异构图,能够很好地建模新闻的表示。并在此基础上改进的图卷积网络模型DGAT模型表明了在异构图上能够将不同类型的节点映射到相同公共空间的可行性。此外基于距离的注意力机制能够捕获图中新闻内容与背景信息的一致性,用于虚假新闻检测。在公开的数据集上的实验证明了本文提出的方法的有效性。
基金项目
北京印刷学院博士启动资金–基于深度学习的虚假新闻检测关键技术研究(27170123034);北京市教委科技计划一般项目(KM202110015003)。
NOTES
*通讯作者。