1. 引言
时间序列是复杂系统演化的记录,它蕴藏着系统内在的动力学特征。时间序列分析可以获取有意义的信息,比如捕捉系统的演化行为,提取系统中不同时空结构以及分析它们的相互作用。我们将时间序列视为一种信号,这个信号处理问题通常将数据分解为不同层面,从而将信号中的趋势与噪声解耦。过去的研究在建模和分析方面遇到了很多困难和挑战,高维和非线性特征使之在空间和时间上都表现出多尺度现象。尽管时间序列提供了丰富的可用数据,但构建准确的模型仍然是一项艰巨的工作。为了应对这种复杂性,本文提出了一种纯粹数据驱动的方法:动态模式分解(dynamic mode decomposition, DMD)。
DMD起源于计算流体动力学(CFD)领域,最初被设计为一种基于时空相干结构将复杂流体分解为低秩特征方法 [1] 。如今它被应用于广泛的领域,在计算机视觉中,DMD能够将视频稳健地分离为背景和前景 [2] 。在生物识别领域,它有助于检测样本的有效性 [3] 。在机器人技术和神经科学领域,DMD在估计人机交互中的扰动 [4] 和从大规模神经记录中提取一致模式 [5] 等方面发挥了关键作用。所有上述DMD应用都以数据矩阵作为输入,例如用DMD分析视频时,将输入数据转换为列矢量,每个列矢量表示一帧图像。
除了数据驱动性,DMD还有一些其他的特点。首先是优秀的降维效果。随着一项DMD应用于单变量时间序列的研究问世 [6] ,体现了DMD能够从单变量序列中提取内蕴模式的能力。本文将用DMD处理不同的单变量信号,以延迟坐标的形式把单变量时间序列嵌入至多维时间序列,我们通过类比DMD如何处理视频来分析DMD如何处理这个数据矩阵:每一列表示当前时间点包含的观测量(像素),每一行代表一个时间窗口(帧数),行数远大于列数。DMD作为降维算法,通过适当地投影,它从大量的观测量中提取到少数特征构成的模式。第二,DMD能够捕捉信号中主导的模式。模式的快慢程度主要受特征值控制,其中上升和下降趋势由特征值的实部体现,而周期性由特征值的虚部反映。DMD允许我们自由控制特征截断数r来得到不同快慢层面的特征,这样我们能够提取出一系列主要的模式,并进一步发掘隐藏在部分模式中的非线性关联。我们不对原始时间序列作任何预处理,一方面是因为DMD的数据驱动和无方程性质,不对源数据做任何适用条件和限制;另一方面是在剔除噪声的同时可能会导致原有的谐波结构丢失。与其他的滤波工具类似,DMD保持了信号中的各种谐波结构,这些结构作为模式的一部分,它们是不可分离的,共同构成了系统的一部分演化特征。本文的DMD框架把噪声视为不希望保留的分量,通过选取不同的r,我们就过滤了不同层级的噪声,提取了各种层面的模式。第三,DMD作为一种线性方法,它假设系统中存在一个不变的线性算子,详见方法中对DMD的数学推导部分。
我们的研究对象是实际的气候时间序列。气候作为典型的复杂系统,它受到各种不同环境因素的影响,可大致分为两个领域:自然效应和人类活动。碳排放已经成为人类活动的代表性驱动因素,它对地球气候产生了重大影响;然而气候与太阳的关系一直以来争论颇多,作为太阳活动最直接的体现,太阳黑子数量和气温的联系是过去研究的热点 [7] [8] 。越来越多的证据表明太阳黑子和气温之间的关系具有非线性特征 [9] [10] ,仅仅从线性的角度和方法难以捕捉到隐藏在各种模式之间的非线性关联。且过去的研究针对不同气候对象的两两关系,没有考虑到同一气候对象的内部模式之间的关联。事实上,内部的各种模式并不是相互独立的,通过研究内部模式的关联,我们能够更全面地理解某种气候对象自身的演化规律。不同模式或频段之间的性质差异十分显著,我们的研究将提取不同快慢程度的模式,更深入地揭示这些关联如何分布在各种模式中。
信息论方法在解释气候变量关联方面展现出很大的潜力 [11] ,已有一项基于转移熵的研究分析了包括太阳和碳排放在内的等很多环境因素对气温的影响,但这项研究直接对信号本身计算转移熵,未分解或提取任何时空结构 [12] 。转移熵(transfer entropy, TE)作为非线性因果关系的度量,它的优势在于因果关系的单向性。比如地球气温绝不会对太阳黑子有任何影响,即使气温和碳排放之间存在双向关系,因果强度也会存在差异,TE能提供更准确的结果。我们借助k近邻(kNN)估计的TE量化各种模式之间的关联 [13] [14] 。
我们的目标是分析因果关系如何分布在快慢模式中。技术方案包括三个步骤。第一,对本文的四串单变量时间序列分别用延迟坐标方法嵌入至多维时间序列。第二,分别确定最大特征截断数,用DMD提取一系列模式。第三,用TE分析各种模式之间的非线性关联。观察因果强度在不同模式之间的分布,评估因果关系发生的快慢层面。几个比较重要的结果是:关联集中于少数特征提取的慢模式;最大的主导模式作为因,它会对包含更多周期的其他主要模式产生重大影响;太阳黑子对气温在各种快慢层面上均有显著影响;碳排放主要影响气温的长期趋势;四个气候对象构建的因果框架显示,信息的流动基本平衡。
2. 方法
2.1. 数据来源
我们的数据包括地表温度(Global land surface temperature, LST),海面温度(sea surface temperature, SST),太阳黑子数量(sunspot)和碳排放(carbon)。LST和SST分别来自于Berkeley Earth [15] 和Met Office Hadley Centre [16] 。这里的温度指温度异常值(temperature anomalies),它表示偏离平均温度的值,平均温度来自于1961~1990。Met Office Hadley Centre不建议使用实际温度,因为温度记录是以经纬度划分的网格形式的,未覆盖整个地表比如高纬度地区;而温度异常值是对所有网格中异常值的平均,不确定性和系统性的误差都比实际温度小得多。太阳黑子数量来自于SILSO [17] 。碳排放来自于Global Carbon Budget 2022,包括化石燃料的燃烧和氧化,水泥和船用燃料的排放,单位为百万吨 [18] 。除了碳排放为年度时间序列,其他都为月度时间序列。当我们分析年度和月度序列之间关联时,把月度序列平均化以匹配年度序列。所有序列的时间跨度都为1850~2022,共173年。
2.2. 嵌入至多维时间序列
我们从四个单变量时间序列中任取一个长度为n的信号x,
由相空间重构理论,以延迟坐标的形式把相邻样本嵌入到一个足够大的窗口。令窗口长度为L,可以得到一个长度为
的多维时间序列XL。对于三个月度时间序列,我们取L = 144;对于年度的碳排放时间序列,取L = 3。
XL中的列称为滞后向量
。
窗口的个数即
的长度为n – L + 1,因此单变量时间序列x被分解为长度为L的n – L + 1个重叠窗口。水平堆叠
,XL可展开为矩阵的形式。
2.3. 动态模式分解
x中快照的采样间隔是固定的,相邻的滞后向量
也有着固定的时间间隔Δt。假设存在一个不变的线性算子A作用于
中。
A对任意的
都成立,我们可以把A作用前后的
和
拓宽成两个滑动矩阵X1和X2。A把X1映射到X2,捕获了XL所有的
。
我们可以通过X1的MP伪逆
来间接地计算出A。
对X1进行降阶奇异值分解(SVD)得到左右奇异矩阵和奇异值U,V,Σ,这三个矩阵的正交性使得我们可以直接得出
。
完整大小的A由X2和经过分解后的
得出
A由数个低秩矩阵得出,因此它的秩,或者说它代表的动力系统所蕴含的特征数量远低于它的实际尺寸。我们希望构造A的低秩近似,这不但可以降低计算成本,更重要的是我们希望从A中寻找低维底流形中的特征。U作为原始数据堆叠而成的滑动矩阵X1的左奇异向量,它可以对X1的行数进行压缩:
U把X1中远大于列数的行数(
)压缩到和列数一样的水平上,降维效果十分可观。两个低维的滑动矩阵之间也应存在一个低维的不变算子,
U对X2进行同样的投影,并利用
,U将A投影到低维L × L子空间,
通过保留前r个特征值与其对应的特征向量,我们就可以得到前r个最大的特征,A被投影到低维r × r子空间,我们现在可以改变r来调整特征的数量。
对Ar特征分解
,代入上式有
这样就得到了前r个特征Ar重构的A的特征向量
,我们在计算中应用它的对偶 [19]
作为特征向量。
2.4. 提取模式
DMD把离散时间动力系统
中的不变算子A推广至连续时间动力学A并等间隔Δt采样,得到一个连续时间的动力系统
我们用离散时间特征值
,特征向量
以及初始状态
对应的系数
写出这个系统的离散形式的解
它由L个特征解出,取前r个特征,将上式展开并用连续时间特征值
替代,得到由前r个特征值构成的向量
对某条滞后向量
提取的r阶模式
,如图1:
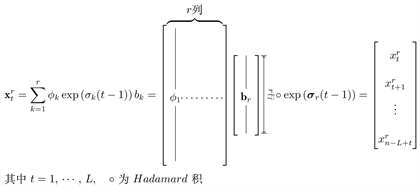
Figure 1. Mode extraction formula of a
图1. 对某条
的模式提取公式
作为从
提取的r阶模式,它的元素和r有关,但长度不受特征截断数r的控制,仅仅取决于窗口长度L.每一条
都有其对应的模式,我们可以得到由所有
构成的矩阵形式的模式
。其上下标r和L表示它是在一个特定的窗口长度下,由某个特征截断数生成的。
注意到XL是Hankel矩阵,它的每一条反对角线都对应同一个快照,那么
的每一条反对角线也应相等。事实上,滞后向量
张成了Krylov子空间:
这等价于利用滑动矩阵进行一次滑动
。X1和X2捕捉了所有的
,保证了不变算子 的准确性,但未保证
是Hankel的。我们对
中的每一条反对角线进行加权平均, [6] 得到最终的向量形式的模式
,形象化的展示见图2:
其中i,j为
的行和列,
为第k条
的反对角线,
为
中元素的数量。

Figure 2. Anti-diagonal weighted average method, where different over lines indicate that samples come from different
, not necessarily equal
图2. 反对角线加权平均法示意,不同的上划线表示这些样本来自不同的
,不一定相等
我们使用的DMD算法来自Kutz et al. [20] 主要步骤如表1。

Table 1. Dynamic mode decomposition (DMD) algorithm
表1. 动态模式分解(DMD)算法
我们希望从每种信号中提取出一系列模式,由于特征值的分布不是均匀的,所以需要遍历每一个r来提取模式,共R个模式,否则可能会遗漏合适的模式。确定模式的数量即最大的特征截断数R的方法是:对X1进行SVD,当前r个奇异值的平方和达到95%的总平方和时,取这个r作为最大的特征截断数R。表2为对各信号使用不同的最大特征截断数R来得到前r个特征值提取的模式。大于R的特征值,即后L − r个特征值表示对源信号的贡献小于5%的噪声,通过在r处截断,就剔除了这个r对应的贡献率以下的噪声,提取出相比原信号更慢的模式。碳排放是年度信号,其趋势非常平缓,我们只需提取其一个模式。
Table 2. Extract different numbers of modes for each signal
表2. 对各信号提取出不同数量的模式
每个信号提取的R种不同的模式构成了一个模式集XR,其上标R区别于由特定的特征截断数r得到的
。
2.5. 用转移熵计算模式间因果关系
对两个原始气候时间序列U,V依表2分别用DMD提取模式,得Ur和Vr。用TE计算其中模式的关联,得到一个由TE值组成的矩阵
。
其中
,
,
。
展开
,随着特征截断数r的增加,从左至右V的模式越来越快,从上至下U的模式越来越快。图3为展开
的示例:
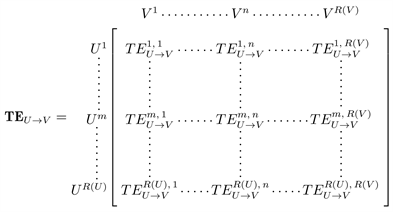
Figure 3. An example of constructing a transfer entropy matrix, each row or column is a specific mode, every element in the matrix is the transfer entropy value under this specific mode pair
图3. 构造转移熵矩阵的示例,任意一行或一列都是一个特定的模式,矩阵中任意元素都是在这对特定模式下的转移熵值
对于可能存在的12种因果关系(包括三种月度气候信号内部模式之间的关系,太阳黑子不作为果,因为地球上的信号显然不可能对其造成影响),我们可以构造一个
组成的集合TE。按LST,SST,太阳黑子和碳排放的顺序,可以将TE表示为一个4 × 4的分块矩阵:
每一对模式之间的转移熵值可以由Shannon熵H给出。
其中
,
。
我们以vt为例阐释基于kNN的计算概率密度的方法。设vt与其第k个最近的邻居之间的距离为Dt。vt的邻域即以它作为中心,Dt为直径的球中包含st个快照,则vt在此处的概率密度可理解为
为
的球形邻域的体积。
它是这个区域中概率出现st个观测量的直观表示。具体地,设pk(Dt)为某快照出现在vt邻域内的概率,p为其概率密度,则
{vt}共含N = n − 1个快照(不包括t = n时刻,同理{vt+1}不包括初始时刻),除vt自身外,剩余N − 1个快照中恰好有k个落在球内的概率可以由二项分布估计,
其中Pk(Dt)为vt与其第k个最近邻之间距离的分布,它是一个对Dt的估计。Pk(Dt)dDt等价于当球直径Dt增加一个很小的单位dDt时,恰好把k个快照包含在Dt范围内的概率。两边同时乘以logpk(Dt)并在(0, ∞)上积分,显然左边的概率密度Pk(Dt)归一了,留下logpk的期望 [21] :
上式第三步的估计由Beta函数导出:
,其中
为digamma函数,详见 [22] 。回顾概率的直观表示,pk即vt的邻域内包含的快照个数st,kNN假设它与邻域的大小Dt成正比,即vt的概率密度p与Dt无关,我们就得到了H(vt)所需的概率密度:
,
为无穷范数下的
的体积
对于我们的向量{vt},维数d = 1。综合以上两式,得
这样就得到了基于单变量最近邻距离Dt估计的H1(vt)
在实际的计算中,我们的最近邻距离
的计算统一来自于三变量(vt+1, ut, vt)构成的三维空间。令
,捕捉所有的zt,得到一个三维的时间序列Z。
寻找每个快照zt在Z中最近的邻居
,得到最近邻距离
接下来计算H(zt)的方法与前文中计算H1(vt)同理,它由联合概率密度导出。其中第三项分子上的3表示zt的维数d = 3
为计算H(vt),H(ut, vt)和H(vt+1, vt),需要分别对向量v和两个由Z分拆而来的矩阵Zuv,Zv'v进行分析,
设vt,(ut, vt),(vt+1, vt)在
内分别含
,
,
个快照,对任意k,zt构造的三维空间中的
都会大于边缘空间v,Zuv,Zv'v中邻居的距离,st相当于计算边缘概率密度所需的最近邻个数。
其中
为元素的数量,
。
H(vt),H(ut, vt)和H(vt+1, vt)如下,由边缘概率密度导出。后者通过H1(vt)中的二项分布方法,
,
,
作为最近邻个数来估计。
的平均需要乘以当前快照的维数d = 1或2。由于
,
,
只搜索除自身之外满足条件的快照,所以实际满足条件的快照数量需要各自加一。相比H(zt)中的
,它们用
在所有t上的均值来代替,这相当于在逐个快照中取st + 1个被包含在
球内的快照再平均化。
这样我们就完成了转移熵
的估计:
本文取k = 1计算TE值,转移熵算法来自Papana [13] 。表3为主要步骤。
Table 3. Transfer entropy (TE) algorithm
表3. 转移熵(TE)算法
图4是本文的方法流程:

Figure 4. Flow chart for analyzing causality between climate signals and internal modes based on DMD
图4. 基于DMD分析气候信号之间及内部模式关联强度的流程图
3. 结果
图5展示了三种月度信号分别嵌入至多维时间序列的奇异值与主要模式对应的特征值。第一列中的奇异值按降序排列,LST的奇异值随个数的增加,占所有奇异值之比相较SST与太阳黑子更为缓慢。LST的最大奇异值贡献了60%,太阳黑子的最大奇异值贡献了65%,而SST的最大奇异值贡献了85%,这体现了SST相比其它两个月度信号噪声更小的特点。太阳黑子的最大奇异值占比与LST相似,但前者与SST一样,随着奇异值个数的增加,前几个奇异值的贡献速度上升极快。LST的奇异值直到48个才达到85%。第二列显示前几个奇异值的衰减比指数更快,随后收敛。
第三列和第四列展示了DMD方法得到的线性算子A的特征值,它们反映了对应模式的时间演化。特征值虚部决定了模式的周期(快慢程度),实部决定了模式的趋势(衰减速度)。因此,较小虚部和正实部的特征值对应的模式体现了信号的宏观趋势;大虚部对应的模式捕捉了信号的微观行为或噪声,因为大虚部意味着快速振荡。显示了所有144个特征值(空心圆),其中若干种主要模式对应的特征值用叉号标记。特征值基本分布在单位圆上,有极少数几个例外,相对于虚轴是对称的。特征值的实部都不大于1,即系统是稳定的;且三种信号都存在一个特征值为1对应的模式,这个模式是一种稳定的状态,因其不包含任何衰减和振荡。前R个主要的模式具有较小或零的虚部和较大的实部,体现了信号宏观上的趋势变化。最后一列我们可以看到特征值的虚部在(−0.8, 0.8)中均匀分布,这些特征值对应的模式具有分布较广的周期,没有特征周期。我们的数据都是实数,因此虚部在虚轴两侧是对称的,特征值都为共轭对。

Figure 5. Distributions of singular values and eigenvalues of DMD linear operator from three monthly signals
图5. 三种月度信号的奇异值和DMD线性算子的特征值分布
Table 4. The eigenvalues and periods of major modes from three monthly signals
表4. 三种月度信号的主要模式的特征值和周期
三种月度信号的最大特征值虚部很小,且SST和太阳黑子的前少数几个最大的特征值具有较小的虚部,意味着前几个主导模式为慢模式,有着较大的周期。LST主要模式较多,表4展示了前13个特征值。贡献最大的一对共轭特征值体现了其显著的一年周期的特点:1/0.08 ≈ 12;第二对和第六对特征值的实部较小而虚部较大,反映了快速振荡占据LST很大一部分特征;第四和第七对特征值的虚部对应1年和2年左右的周期。SST的第一和第七对特征值反映了半年周期;第四和第五对特征值对应一年左右的周期;第六对特征值对应三个月左右周期。太阳黑子的前几对特征值反映了3~6个月的周期,贡献最大的特征值不包含虚部,体现了太阳黑子具有很强的趋势性。除了LST,前少数几个特征值都对应较长的周期和长期趋势,意味着当r很低时,提取出来的模式很慢;当r增大时,特征值的虚部会越来越大,意味着我们可以提取出更快的模式。图6展示了四个原始信号的几种典型的快模式和慢模式。当r接近1时,我们得到一个非常慢的模式,随着r增大,我们能够提取出包含多种尺度的模式。

Figure 6. Several typical fast and slow modes
图6. 几种典型的快慢模式
我们计算了各种模式之间的转移熵,它们代表着8种因果关系在不同模式之间的分布。为了确保计算出来的TE值是可信的,每种模式都被打乱并计算20次TE值,如果存在多于一个的打乱TE值大于原始顺序的TE值,则舍弃这个TE值,这等价于95%的可信度。我们在尝试中发现即使调整这个阈值或改变打乱次数,也不会对TE值在各种模式下的分布形状产生任何影响。即:不同的统计显著性不会改变TE值的分布,这体现了因果关系在不同模式之间的固有特征。图7展示了这些关联如何分布在各种模式中,表5为因果强度较大时对应的模式。总体上,关联集中于少数特征提取的慢模式,大部分模式之间不显著存在关联。由第一个特征值提取的主导模式作为因,它会对来自同一个气候对象中的其他较慢和稍快的模式产生显著影响,对其他气候对象的主导模式也有很大贡献,反过来则不成立。LST的最慢的模式约为一年周期,它对自身的一年和一两个月周期产生了显著影响,对SST的半年周期以及碳排放的长期趋势亦有很大贡献。注意到由前11~13个特征值提取的LST模式中包含了1~12个月和两年的周期,这些模式对自身的各种模式有强烈影响,但与内部其他模式和其他气候信号的模式之间关联极少,体现了LST中的快速振荡或噪声基本只影响自身的特点。SST模式中半年周期的驱动力极强,它对自身的三个月,半年,一年周期和长期趋势都有着显著影响;对LST的一年周期和碳排放亦有很大贡献。太阳黑子的最大主导模式,即长期趋势对SST的6个月以上周期有极大的贡献;前9个特征值下提取的模式仅包含长期趋势和3~4个月周期,这些模式的内部关联非常显著;其四个月周期和长期趋势对LST在一两个月和一年的尺度上有贡献,但偏弱;对碳排放的影响没有计算出任何有效的TE值。碳排放对SST的半年周期有强烈影响,对LST的一个月及一年周期有显著贡献,在其他尺度上的影响偏弱,气温对碳排放的影响也偏弱。

Figure 7. Causal intensity among different modes. The horizontal axis represents the cause, while the vertical axis represents the effect. From left to right, and top to bottom, they respectively represent LST, SST, sunspots, and carbon emissions. The color bar on the right indicates the magnitude of the TE values, where white regions in the plot indicate insignificant or zero TE values. The numbers on the horizontal and vertical axes represent the modes extracted by a certain number of eigenvalues for a specific climate variable
图7. 各种模式之间的关联强度。横轴代表因,纵轴代表果,从左到右,从上到下分别为LST,SST,太阳黑子和碳排放。右边颜色条为TE值的大小,图中白色区域表示TE值不显著或为零。横纵轴上的数字表示对某个气候对象由前若干个特征值提取的模式
Table 5. Modes corresponding to causal intensity around peak values
表5. 因果强度在峰值附近对应的模式
我们以各个模式之间最大的TE值作为因果强度的特征,并把它们作为信息的传递写在图8的因果信息框架中。若不考虑括号内的自关联,LST的净TE流入为0.08,SST的净TE流入为1.13,太阳黑子的净TE流出为0.66,碳排放的净TE流出为0.55。总体上净TE流入和流出相等,表示由四种气候对象建立的因果信息框架达到了一种平衡。
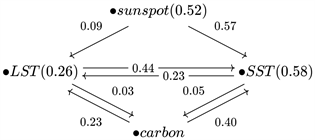
Figure 8. The causal information framework established by four climate variables, where the numbers on the arrows represent the maximum TE values between modes from different climate variables, and the numbers in parentheses represent the maximum TE values of modes within a particular climate variable
图8. 四种气候对象建立的因果信息框架,箭头上的数字为不同气候对象的模式之间的最大TE值,括号内的数字为某个气候对象内部的模式间的最大TE值
4. 结论
我们的方法得到了因果关系在各种模式下的分布。关联集中于少数特征提取的慢模式。最慢的模式作为因,它会对较慢和稍快的模式产生显著影响。太阳黑子内部模式之间的关联集中于长期趋势和3~4个月的周期,这些尺度对SST的各种周期和长期趋势的贡献极强,对LST在各种层面上的影响偏弱,我们推断SST对太阳黑子的响应比LST更大。碳排放对SST的半年周期具有很大影响,对LST的一年周期也有较大影响,但在更快尺度上的影响偏弱,气温反过来对碳排放的影响偏弱。LST的一年周期对SST的半年周期和碳排放有较大贡献,LST内部模式间的关联从快速振荡到长期趋势,包含多种尺度。SST的半年周期对自身,LST的一年周期和碳排放均有很大贡献。两种气温之间的关联也聚集在半年和一年周期,LST对SST的影响更大。LST,SST,太阳黑子和碳排放四个对象构成的因果框架展示了它们之间信息的传递,总体上看信息在这个框架中的流动是平衡的。在整个1850~2022的时间尺度上,SST比LST吸收了更多的信息,太阳黑子对气温的贡献略大于碳排放。
我们提出的DMD框架有着广阔的应用前景。第一,多分辨率的能力。本文将DMD应用于整体时间尺度,若切分成若干个时间段并用DMD分段处理,能够分析某一时间段上的关联,从而更深入地理解系统的演化特征。第二,多因子分析的能力。影响地球气候的其他因素如火山活动,气溶胶,其他温室气体乃至太阳系中其他的天体活动都会对气候产生不可忽视的影响 [12] [23] ,即使这些序列的记录较少,DMD仍然有着从中提取合适模式并分析因果关系的潜力。第三,多数据类型的适用性。气候或其他复杂系统不仅由时间序列反映演化行为,DMD可以应用于遥感影像等图像类型的数据 [24] 。第四,预测的潜力。通过配合控制或一些机器学习方法,DMD在最近的研究中也展现出其预测时间序列的潜力 [25] 。