1. 引言
印刷电路板(Printed Circuit Board)简称PCB,依靠其高度集成、轻量化、成本低和稳定性高等优势,广泛地应用于电子产品领域。然而,在制造过程中,由于各种因素的影响,如设备故障、操作失误、设计缺陷等,PCB电路板上可能存在各种各样的缺陷,例如短路、缺失孔、焊接不良、线路损伤等。这些缺陷如果未能及时检测和处理,会严重影响PCB电路板的性能、质量和安全。
因此,如何及时有效地对PCB电路板进行缺陷检测极为重要。早期的PCB缺陷检测主要依靠人工目测和在线仪器检测,但这些方法通常存在成本高、效率低、误检率高等缺点,且部分检测方法会接触到PCB电路板,容易造成二次损坏,使得目前检测难以满足现代PCB电路板生产效率高、性能好的检测要求 [1] 。随着计算机技术的发展,深度学习在缺陷检测领域被广泛应用且取得了显著的成果。
基于深度学习的目标检测算法在步骤上包括双阶段(two-stage)和单阶段(one-stage)两种目标检测框架 [2] 。在双阶段的检测算法中,R-CNN [3] 是一种基于区域的卷积神经网络,通过使用选择性搜索算法来对输入图像提取潜在的候选区域。然后,对每个候选区域进行特征提取,并使用支持向量机(SVM)进行分类。这样就将目标检测问题转化为一个候选区域分类的任务。而Faster R-CNN [4] 在R-CNN的基础上进行了改进,引入了区域建议网络(Region Proposal Network, RPN),使得整个目标检测系统实现端到端地进行训练。但由于候选区域生成过程可能存在一些限制,导致漏检或定位不准确。
而在单阶段算法中,SSD (Single Shot MultiBox Detector) [5] 采用了基于卷积神经网络(CNN)的特征提取器,并在多个不同尺度的特征图上进行目标检测。它通过在不同层级的特征图上应用不同大小的卷积核来检测不同尺寸的目标。这种多尺度的检测策略使得SSD能够有效地检测不同大小的目标。而YOLO (You Only Look Once) [6] 也是一种单阶段的目标检测算法。与SSD不同的是,YOLO是将目标检测问题转化为一个回归问题。它将输入图像分成一个固定大小的网格,并在每个网格单元中预测目标的边界框和类别。
YOLO算法凭借检测速度快,且只需要一次前向传播就可以得到所有目标的检测结果的特点,实现了对目标的实时检测。YOLO作为单阶段模型的代表之一,相较于更早提出的两阶段目标检测算法,不仅拥有更快的预测速度;对于背景图像(非物体)中的部分被包含在候选框的情况误检率更低,还拥有更好的算法通用性。以上这些特性,都使YOLO系列模型成为工业目标检测场景首选的算法。
YOLOv1-YOLOv7
在各种物体检测算法中,YOLO (You Only Look Once)框架因其在速度和准确性方面的显著平衡而脱颖而出,能够快速、可靠地识别图像中的物体。自成立以来,YOLO系列已经经历了多次迭代,见图1,每次都是在以前的版本基础上解决局限性并提高性能 [7] 。

Figure 1. History of the YOLO series
图1. YOLO系列发展历史
YOLOv1:YOLOv1采用全卷积神经网络结构,将目标检测问题转化为单次前向传播的回归问题。其核心思想就是将整张图片作为网络的输入(类似于Faster-RCNN),直接在输出层对BBox的位置和类别进行回归。
YOLOv2 [7] :在yolov1的基础上进行了改进,提出了一种检测与分类联合训练方法,这种方法使得模型可以检测超过9000种类别。
YOLOv3:它引入了三种不同尺度的检测,采用了三种不同尺寸的检测核。这种改进的架构在对小物体进行预测时,使用更加精细的边界框,提高预测效果。
YOLOv4:YOLOv4采用了一系列技术改进,包括使用更大和更深的模型Darknet-53,引入CSPDarknet53和PANet等结构来提高特征表示能力。同时引入了多尺度推理、Mosaic数据增强、CIOU损失函数等技术来提高检测性能。
YOLOv5 [8] :YOLOv5融入了Ultralytics的一种称为AutoAnchor的算法。该预训练工具检查并调整锚框,以使其适合于数据集和训练设置。它使用更加轻量级的网络结构作为主干网络,并使其更加易于训练,通过Pytorch进行开发以便在GPU和CPU上更快地运行。
YOLOv6:YOLOv6采用了高效的主干网络(使用RepVGG或CSPStackRep块)、PAN拓扑的neck和高效解耦头部,这些组件相互协作以实现更快、更准确的对象检测。
YOLOv7 [9] :YOLOv7在架构上使用了扩展高效层聚合网络(E-ELAN)策略,这种策略通过洗牌和合并不同组特征的cardinality,增强了网络的学习特征的能力,提高准确率。通过基于串联的模型缩放,减少硬件资源的使用,保持模型的最佳结构。
2. YOLOv8算法概述
Ultralytics于2023年发布了YOLOv8 [10] 算法,与之前的网络相比,YOLOv8在减少网络参数量的同时,提高了检测精度和实时性。根据官方文档,YOLOv8是一种(SOTA)模型,在原有的YOLO版本基础上,引入新的功能,改进网络结构,提升了模型的性能与灵活性。和YOLOv5一样,YOLOv8也基于缩放系数也供了n/s/m/l/x五种尺度的模型,不同模型大小用于满足不同场景需求。
YOLOv8的具体创新包括一个新的骨干网络、一个新的Ancher-Free检测头和一个新的损失函数。骨干网络和Neck部分借鉴了YOLOv7的E-ELAN策略,将YOLOv5中的C3结构替换为梯度流更丰富的C2f模块。增强特征的表达能力,可以更好地捕捉图像中的细节信息。Head部分相较于YOLOv5,耦合头换成了目前主流的解耦头结构,将分类和检测头分离,同时将Ancher-Base换成Ancher-Free。简化算法流程的同时提高检测效率。损失函数的计算方面,YOLOv8采用了TaskAlignedAssigner正样本分配策略,同时使用Distribution Focal Loss损失计算函数,以提高目标检测任务与分类任务时的性能表现,使模型更好地适应复杂的数据分布和类别不平衡的情况。
YOLOv8模型结构
YOLOv8模型结构主要由Backbone、Neck、Head三个部分组成,其主要网络结构见图2。
对于Backbone部分:其主体是CSPDarkNet结构,可以在计算效率与准确率之间取得良好的平衡。这个部分负责提取图像的特征信息。主要由Conv、C2f和SPPF三种层级组成。C2f是将卷积特征图转换为全连接特征向量的层,SPPF 则是空间金字塔池化网络。
对于Neck部分:指的是连接在骨干网络后面的部分,用于进一步提取特征和融合不同尺度的特征图。Neck部分是由一系列Upsample、Concat和C2f层组成的,主要作用是将不同层级的特征图进行上采样、拼接和进一步处理,以便Head部分更好地进行预测。
对于Head部分:主要功能则是对特征进行处理和预测,通过在不同层级上提取特征,提高模型预测的准确度。主要由Conv、Concat、C2f和Detect层组成。Conv层用于进一步提取特征信息,Concat层则用于将不同尺度的特征图进行拼接,以便更好地适应不同尺度的目标。C2f层将卷积特征图转换为全连接特征向量,并且可以通过Dropout操作来防止过拟合。Detect层是检测层,它在特征图上执行目标检测操作,并输出检测结果,包括目标的位置和类别等信息。
3. 基于YOLOv8-PCB的电路板缺陷检测算法
由于PCB电路板的检测目标尺寸较小,且数据集数量有限,因此在利用通用的YOLOv8模型进行缺陷检测时,需要根据样本数据的特征分布进行针对性的改进优化。为了尽可能减少模型复杂度,提高算法效率,本文以参数量最少的原始YOLOv8s模型作为基准模型,并在此基础上通过引入LSK注意力机制并调整模型结构等若干手段,最后能够有效地检测出PCB图像中的各种缺陷,包括短路、开路、伪铜等。下面对算法模型各部分进行详细说明。
3.1. LSKNet注意力机制
注意力机制(Attention Mechanism)源于对人类视觉的研究。而计算机视觉中的注意力机制是指在图像识别、目标检测、语义分割等任务中,通过对输入数据中的重要区域进行加权处理。通过引入注意力

Figure 2. Network structure of the YOLOv8 mode
图2. YOLOv8模型网络结构图
机制,对输入数据的不同部分赋予不同的权重,能有效地帮助网络模型对输入信息进行学习,使其能够更加关注重要的信息,从而提高模型的性能和准确率,同时也有助于避免过拟合的情况发生,提高模型的鲁棒性 [11] 。
本文在通用注意力机制模块的基础上,引入了一种叫LSK (Large Selective Kernel)的新型注意力结构 [12] ,构成了LSKNet注意力机制模块。见图3,LSKNet结构简单,但能够获得优异的检测性能,可以动态地调整其大空间感受野,从而更好地建模遥感场景中各种物体的测距的场景。该模块也能在遥感目标检测等领域探索大的、有选择性的卷积核机制,可以广泛应用于动态的上下文特征信息提取当中。

Figure 3. Illustration of the LSKNet Block
图3. LSKNet Block图示
LSKNet Block是主干网络中的一个可重复堆叠的模块,每个LSKNet Block包括两个残差子块,即大核选择子块(Large Kernel Selection, LK Selection)和前馈网络子块(Feed-forward Network, FFN),见图3。LK Selection子块根据需要动态地调整网络的感受野,FFN子块用于通道混合和特征细化,由一个全连接层、一个深度卷积、一个GELU激活和第二个全连接层组成。

Figure 4. Concept art of the LSK Module
图4. LSK Module模块概念图
LK Selection子模块中(见图4橙色块)嵌入了核心模块LSK Module,而LSK Module是由一个大核卷积序列(large kernel convolutions)和一个空间核选择机制(spatial kernel selection mechanism)组成(见图3)。
由于要对一系列的多个长期上下文信息进行模型的自适应选择。因此通过显式地分解一个大的核卷积并将其分解为一个大的深度卷积序列来构造一个更大的核卷积。具体来说,该序列中第i个深度卷积的核大小k、扩张率d和接受场RF的展开被细化如下:
(1)
(2)
以上公式中核的大小与扩张率的增加确保了感受野有足够快的扩展,为保证扩张卷积不会在特征图之间引入空隙,对扩张率设定了一个上限,这样的设计有两个主要优点:首先,它能够明确地生成具有不同大感受野的多个特征,从而更容易进行后续内核的选择;其次,与简单地应用一个较大的核相比,顺序分解技术更加高效和有效。最后,我们还采用了空间选择机制,以提高网络关注检测目标最相关的空间背景区域的能力。图4详细展示了LSK模块的概念,直观地展示了大选择核如何通过自适应地收集不同物体的相应大感受野而发挥作用,从而有效地将低了模型的参数量。
3.2. LOSS损失函数
损失函数的设计是目标检测算法的重要组成部分,本文设计的YOLOv8-PCB算法的损失函数同样由分类损失VFL和回归损失CIOU + DFL两部分的三个损失函数加权组合而成,从而对缺陷目标进行更好地比较筛选。
3.2.1. VFL
YOLOv5/v7均使用BCE (二元交叉熵)作为分类损失,每类别判断“是否为此类”,并输出置信度。
在YOLOv5中,由于存在对象损失,反向传播时只选择BCE分类输出的“置信度分数”中最大值作为置信度最高的类别,并直接输出。而在YOLOv8中,由于去除了对象损失,输出中也不再包含“对象置信度”,而是直接输出各个类别的“置信度分数”,然后从中选取最大值作为该锚框的“置信度”。这样的设计简化了模型输出的结构,并提高了算法的效率。具体计算如下所示:
(3)
q是label,正样本时候q为预测框和真实框的IoU,负样本时候q = 0,当预测结果为正样本时候没有采用FL,而是普通的BCE,只不过多了一个自适应IoU加权,用于突出主样本。而为负样本时候就是标准的FL了。可以明显发现其主要特点是正负样本非对称加权、突出正样本为主样本。
3.2.2. CIOU
边界框回归损失函数在目标检测中至关重要。通过学习预测边界框的位置,模型可以尽可能地接近真实的边界框,从而提供检测目标的精确定位和区域的关键信息。这一过程不仅有助于提高检测精度,而且还使得模型能够更好地应对各种目标形状和大小的变化。YOLOv8-PCB采用CIOU作为边界框回归损失函数,如下式(4)~(6)所示
(4)
(5)
(6)
其中IoU计算的是“预测的边框”和“真实的边框”的交叠率,即它们的交集和并集的比值。其中x,y为预测框的中心点坐标,xgt与ygt为真实框的预测框的中心点坐标,Wg和Hg是预测框与真实框构成的最小矩形框的宽高值,α为超参数,w和h分别为预测框的宽高值。
3.2.3. DFL
DFL是一种优化方法,能够使网络更快地聚焦于目标位置y附近的值,并增大它们的概率。该方法通过使用交叉熵形式的损失函数,对与标签y最接近的左右两个位置的概率进行优化。这样可以使网络更快地集中学习目标位置周围的分布情况。
(7)
换句话说,DFL的目标是让学习到的分布在理论上接近真实浮点坐标的附近,并以线性插值的方式获得距离左右整数坐标的权重。通过引入DFL,模型可以更加准确地定位目标,提高目标检测的性能和效率。
3.3. YOLOv8-PCB模型的结构设计
根据上述内容,本节将利用设计引入的LSK注意力机制模块,在原YOLOv8模型的Backbone、Neck以及Global全局不同位置处进行构造添加,探索性能最优的改造优化方式,最后利用3.2节的损失函数进行YOLOv8-PCB模型训练与预测输出。
3.3.1. YOLOv8 Backbone部分添加LSK模块
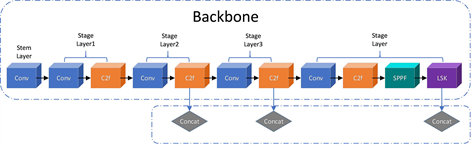
Figure 5. Backbone improved structure diagram
图5. Backbone改进结构图
主干网络(Backbone)通过一系列的卷积层和池化层对输入图像进行多次下采样操作,逐渐减小特征图的尺寸。这种逐渐降低特征图分辨率的操作有助于捕获不同尺度的目标信息,使模型具备多尺度感知能力。
在YOLOv8的Backbone中,SPPF模块可以对输入图像进行不同尺度的池化操作,得到多个尺度的特征图,这些特征图可以捕捉到不同大小的物体或缺陷。在SPPF模块后添加LSKNet Block (见图5,紫色模块)可以更好的利用提取到的特征,使网络更加关注缺陷部分,以便更加准确地检测PCB电路板缺陷。
3.3.2. YOLOv8 Neck部分添加LSK模块
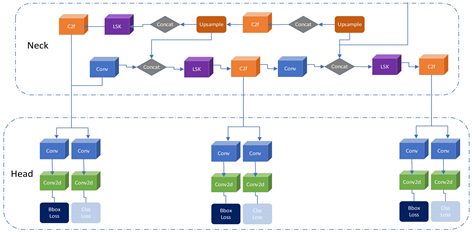
Figure 6. Neck improved the structure diagram
图6. Neck改进结构图
Neck部分位于YOLOv5的主干网络(Backbone)和检测头部(Head)之间。它的主要作用是在主干网络的基础上进行特征融合和降维操作,以提取更丰富的特征表示。具体来说,Neck通过引入额外的卷积层,将来自主干网络不同层级的特征图进行融合,从而捕获到不同尺度的目标信息。这有助于提高模型对不同大小目标的检测能力,并增强模型对目标的多尺度感知能力。
见图6,LSKNet Block被添加在检测任务最后一个上采样层与最终的检测层之间,用于增强特征图的表示能力。由于模块可以动态地调整其大的空间感受视野,模型可以更加准确地学习到目标物体的局部特征和全局特征,并提高对复杂背景下目标物体的检测精度。
3.3.3. YOLOv8多个位置(Global)添加LSK模块
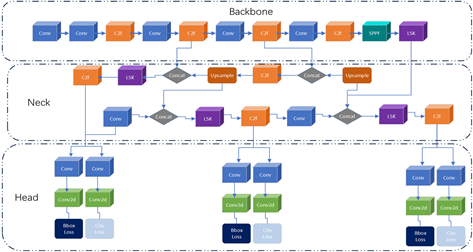
Figure 7. YOLOv8 network adds LSK modules in multiple locations
图7. YOLOv8网络多个位置添加LSK模块
YOLOv8模型中的Head部分包含了三个检测头,分别对应于不同的特征层级,如低层、中层和高层特征图。这样可以实现多尺度目标检测,通过不同层级的特征来检测不同尺度的目标。在提高感受视野的同时,减少误检率,提高模型的整体性能。
LSKNet Block会研究每个目标类别的感受野范围。这样可以使网络更加关注具有较高重要性的特征,而减弱对无关或冗余特征的关注,从而提高模型的表达能力和区分度。其中Rc为类别c的期望选择感受野的面积与地面边界框面积的比值:
(8)
(9)
为包含目标类别
的图像数量,
是输入图像i中所有LSKNet Block输出的空间选择激活的总和,d是LSKNet的Block数量,n是一个LSK module分解得到的卷积核数量,Bi是所有标注的地面真实目标框Ji的总像元面积。
通过在C2f前添加LSKNet Block模块,可以让模型更加关注重要的局部信息,从而提升目标的感知能力。
结合Backbone部分的改进,在三个检测头前的concat连接处(图7灰色部分)添加LSKNet Block,提高模型整体的缺陷检测性能,更加精确地检测PCB电路板的缺陷信息。
4. 实验
4.1. 数据集的准备
实验中用于模型训练和检测的图像数据集来自北京大学发布的PCB,其中包含六种(缺失孔,老鼠咬坏,开路,短路,杂散,伪铜)缺陷一共693张PCB图片。数据集示例见图8、图9。

Figure 9. Example of dataset defect information (missing holes)
图9. 数据集缺陷信息示例(缺失孔)
4.1.1. 数据集的划分
根据PCB缺陷电路板数据集的大小,将训练集、验证集、测试集划分比例设置为8:1:1。即554张图片设置为训练集,69张设置为验证集,70张设置为测试集。为保证实验的可靠性和公平性,在划分数据集的同时,通过随机打乱数据集,可以消除数据的顺序性和相关性,减少模型受到数据排列顺序的影响。
由于数据过少,对模型的训练有一定影响,这里使用SAHI(切片辅助超推理)的数据增强方法,通过将图像切分成若干区域,对各个区域分别进行预测,并结合整张图片的预测结果进行合并,最后使用NMS进行过滤,以提高小目标检测的准确性和效率。
4.1.2. 数据集的转换
由于YOLO数据集的格式是文本文件形式存储的,而PCB数据集中的标签文件采用了XML格式存储。因此,在使用YOLO模型训练前,先将XML格式的标签文件转换为YOLO所需的文本文件格式,以便模型能够正确读取和解析目标检测任务所需的信息。
4.2. 实验平台
4.2.1. 实验配置
本实验配置见表1。

Table 1. Configuration of the experimental environment
表1. 实验环境配置
4.2.2. 实验参数设置
对于本次实验,训练参数设置如下。总共训练轮数epoch设置为1500,批量大小batch_size设置为−1,即根据可用资源自动确定。初始学习率设置为0.01,训练设备为GPU,输入图像尺寸为640 × 640像素,数据加载器只使用主线程进行加载,即workers设置为0。随机种子值seed设置为249,不启用混合精度amp训练,即amp设置为True。
4.2.3. 实验评价指标
实验采用精确率(Precision)、召回率(Recall)、F1值(F1-score)、平均精度均值(mAP)作为评估指标。
精确率(Precision):在所有被分类为正例(正类别)的样本中,真正例(真实为正类别)的比例。它衡量了分类器将负例(负类别)错误地分类为正例的风险。精确率的计算公式为:精确率 = 真正例/(真正例 + 假正例)
(10)
公式中:TP (真正例):预测结果为正例,真实结果为正例,预测正确。TN (假正例):预测结果为正例,真实结果为负例,预测错误。
召回率(Recall):在所有真实为正例的样本中,被分类为正例的比例。它衡量了分类器正确地检测出正例的能力。召回率的计算公式为:召回率 = 真正例/(真正例 + 假反例)
(11)
公式中:FP (假负例):预测结果为负例,真实结果为正例,预测错误。FN (真负例):预测结果为负例,真实结果为负例,预测正确。
F1值(F1-score):F1值即精确率和召回率的调和平均数,将两个指标综合考虑在内,可以更全面地评估模型的分类性能。F1计算公式:2*(Precision*Recall)/(Precision + Recall)
(12)
平均精度均值(mAP):与F1值相比,mAP综合了所有类别的性能表现,更全面地评估了模型在目标检测任务上的准确性和召回率。
(13)
4.3. 实验结果
为验证添加LSK注意力机制的有效性,在原始模型YOLOv8s的不同位置增加模块进行消融实验。实验分组分别是:原始YOLOv8s模型、在原始YOLOv8s模型基础上Backbone部分添加LSK模块、在原始YOLOv8s模型基础上Neck部分添加LSK模块、在原始YOLOv8s模型基础上Global (Backbone + Neck)部分添加LSK模块。训练结果见表2。
注:Position为改进的位置。
对于原YOLOv8s的训练数据,在Backbone部分和Neck部分添加LSK模块,mAP平均精度分别提高0.08、0.04,精确率P分别提高0.08、0.36。说明该注意力机制可以提升模型的精度。但是对于召回率,对比元模型均有所下降,模型可能错过了一些真实的样本。同时也导致F1值对比原模型没有明显的提高。
全局引入LSK模块后,对比YOLOv8s原模型,精确率P明显提高至0.950,Recall提高至0.933,mAP提高至0.958,mAP-50提高至0.520,F1提高至0.941。可以看出,全局引入LSK模块改进后,模型在Recall、mAP、mAP-50和F1上都有明显提高。说明改进后的模型,在对于PCB缺陷检测的任务上,有着更好的分类检测能力。
为验证模型的泛化能力与模型的可靠性,现使用原模型YOLOv8s和添加LSK模块改进后的YOLOv8s模型,在测试集上进行验证。结果见表3。
Table 3. Comparison of test set results
表3. 测试集结果对比
通过对比表3与图10的结果,可以看出Yolov8s-PCB改进后的模型在多个指标上表现更好。
首先,在所有类别的测试结果中,改进后的模型在准确率P、召回率R、平均精度mAP50、F1分数等指标上都有明显提升。例如,准确率从0.958提高到了0.985,召回率从0.872提高到了0.952,mAP50从0.932提高到了0.952,F1分数从0.912979提高到了0.968219。这意味着改进后的模型在识别目标物体方面更加准确、全面。
其次,针对各个具体类别,改进后的模型在大部分类别的指标上也有提升。以missing_hole为例,准确率提高到了1,召回率提高到了0.996,mAP50提高到了0.995,F1分数提高到了0.997996。而open_circuit和spur等类别的指标也都有提升。
综上所述,改进后的Yolov8s-PCB模型在目标检测任务中表现更好的原因可能是LSKNet block模块新的技术或优化策略,使得模型在目标检测方面的性能得到了提升。通过这个注意力机制,模型在准确性、召回率、平均精度等指标上都取得了明显的提高,具备了更好的泛化能力和识别能力。
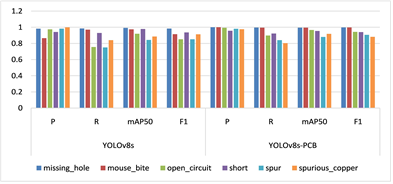
Figure 10. Comparison chart of test set metrics
图10. 测试集指标对比图
预测效果对比见图11~16,模型YOLOv8s-PCB的准确率也均要优于模型YOLOv8s的准确率。

 (a) YOLOv8s-PCB (b) YOLOv8s
(a) YOLOv8s-PCB (b) YOLOv8s
Figure 11. Comparison of the prediction effect of missing hole categories
图11. 缺失孔类别预测效果对比

 (a) YOLOv8s-PCB (b) YOLOv8s
(a) YOLOv8s-PCB (b) YOLOv8s
Figure 12. Comparison of the prediction effect of mouse bite categories
图12. 老鼠咬坏类别预测效果对比

 (a) YOLOv8s-PCB (b) YOLOv8s
(a) YOLOv8s-PCB (b) YOLOv8s
Figure 13. Comparison of the prediction effect of the open circuit category
图13. 开路类别预测效果对比

 (a) YOLOv8s-PCB (b) YOLOv8s
(a) YOLOv8s-PCB (b) YOLOv8s
Figure 14. Comparison of the prediction effect of short circuit categories
图14. 短路类别预测效果对比

 (a) YOLOv8s-PCB (b) YOLOv8s
(a) YOLOv8s-PCB (b) YOLOv8s
Figure 15. Comparison of spurious category prediction effects
图15. 杂散类别预测效果对比

 (a) YOLOv8s-PCB (b) YOLOv8s
(a) YOLOv8s-PCB (b) YOLOv8s
Figure 16. Comparison of the prediction effect of spurious copper categories
图16. 伪铜类别预测效果对比
5. 展望
本文提出了一种基于改进YOLOv8模型的PCB电路板缺陷检测算法YOLOv8-PCB,通过引入LSK注意力机制和调整网络模型结构,该模型可以快速准确地检测出PCB板上各种缺陷,大大提高PCB生产线的质量控制水平,节约人力物力成本,提高产品合格率。其次,YOLOv8-PCB模型具有更好的泛化能力和识别能力,可以适应不同PCB板的检测需求。由于PCB板类型繁多,每种PCB板的缺陷形状、大小、位置等都可能存在差异,因此需要一个具有很强泛化能力的模型来适应各种情况。改进后的模型可以更好地适应不同PCB板的检测需求,具备更广泛的应用场景。后续研究会进一步考虑优化算法模型的复杂度,涉及更加轻量化的检测算法模型,并针对更多类型的电路板数据集(如柔性FPCB等)进行算法微调,使其具有更好的鲁棒性与适应能力。
基金项目
重庆理工大学大学生创新创业训练计划项目;重庆理工大学本科教育教学改革研究项目(2023YB116);省级一流本科专业建设点–信息与计算科学(0101230246)。
NOTES
*第一作者。
#通讯作者。