1. 绪论
1.1. 研究背景和意义
股票是一种由股份有限公司签发用以证明股东所持股份的凭证,它表明股票的持有者对股份有限公司的部分资本拥有所有权。由于股票具有一定的经济利益,且可以上市流通转让,因此股票也是一种有价证券。
1.1.1. 股票价格研究背景
股票价格研究是对证券市场运行机理的深入探索,有助于揭示价格形成的驱动因素和市场行为的规律。通过分析股票价格的波动、走势以及相关变量之间的关系,研究者可以发现价格形成的内在逻辑,从而为进一步理解市场提供了基础。例如,股票价格研究可以探究市场信息的有效性、投资者行为的决策规律以及市场风险的传导机制等,这对于深化资本市场理论以及监管政策的制定都具有重要意义。
1.1.2. 股票价格研究意义
股票价格研究在现实中也有着广泛的应用价值。首先,它对于投资者的投资决策具有指导作用。投资者可以通过对股票价格的研究,了解股票的估值水平以及短期走势,为投资决策提供依据。股票价格研究包括技术分析和基本分析两种方法,技术分析主要关注价格走势的图表模式,而基本分析则从公司基本面入手,考察财务数据和行业环境等因素对股票价格的影响。通过合理运用这些研究方法,投资者可以更好地理解市场,选择适合自己风险偏好和投资目标的股票。其次,股票价格研究对于市场监管和风险控制也具有重要意义。证券市场的平稳运行需要监管部门能够及时发现市场异常、防范市场风险,而股票价格研究则可以提供监管机构和风险管理部门评估市场风险的依据。例如,基于对股票价格的研究,监管机构可以判断市场是否存在操纵行为、异常交易或者信息泄露等违法行为,及时采取措施维护市场秩序。此外,通过对市场涨跌幅、波动率等指标的研究,风险管理部门可以评估市场风险的程度,制定相应的风险管理措施,保护投资者的权益。
1.2. 国内外文献综述
时间序列分析是指对一系列依照时间顺序排列并连续观测得到的数据进行分析的统计方法。在实际生产和社会管理中,时间序列分析在经济、环境、医学、物流等多个领域都有着重要应用。时间序列模型方面,ARIMA模型仍然是时间序列分析中使用最广泛的模型之一。随着时间序列数据的不断增加,基于传统ARIMA [1] 模型的拟合效果逐渐降低,为了提高模型的准确性,人们提出了各种改进的时间序列模型,如ARCH/GARCH模型。此外,VAR模型在多种时间序列变量之间建立统一模型,能够捕捉它们之间的相互影响关系 [2] 。
多元时间序列分析方面,通过同时建立多个时间序列的联合模型,可以充分挖掘时间序列之间的相关性。传统的多元时间序列方法包括ARIMAX [3] 和VAR [4] [5] 等,近年来,越来越多的研究者使用基于深度学习的方法,如LSTM [6] 、GRU [7] 等,来解决多元时间序列的建模问题。
深度学习方法方面,LSTM是其中的代表之一。LSTM不仅能够通过记忆功能建模长期依赖性,还具有记忆稳定性,在时间序列预测任务中表现出色。随着神经网络的不断发展,2018年提出的Transformer [8] 网络也在时间序列领域得到了广泛应用,其在关键任务上表现优异,如股票预测、自然语言处理等。
应用领域方面,时间序列分析在很多领域涉及到决策制定,如金融风险管理、环境治理、医疗诊断等。近年来,随着物流、生产等领域的数字化转型,时间序列分析在预测订单量、库存管理等方面也得到广泛的应用。
总的来说,时间序列分析领域在方法和应用上都有不断的创新和发展。未来,随着大数据和深度学习技术的不断普及,时间序列分析将会更加有效地应用于实际生产和社会管理中的各个领域
2. 模型
本文在这一章主要介绍时间序列的相关概念以及模型,以便为一下个章节的顺利开展做一个铺垫。时间序列是指以时间顺序形态出现的一连串观测值集合,或更确切的说,对某动态系统随时间连续观察所产生有序的观测集合。
2.1. ARMA模型
ARMA模型的全称是自回归移动平均模型,它是目前最常用的拟合平稳序列的模型,它又可以细分为AR模型、MA模型和ARMA模型三大类。具有如下结构的模型称为自回归移动平均模型,简记为ARMA(p,q),

特别的,当
,称为中心化ARMA(p,q)模型。引进延迟算子,ARMA(p,q)模型简记为,
。式中
,为p阶自回归系数多项式
,为q阶移动平均系数多项式。
显然,当
时,ARMA(p,q)模型就退化成了MA(q)模型,当
时,ARMA(p,q)模型就退化成了AR(p)模型。所以,AR(p)模型和MA(q)模型实际上就是ARMA(p,q)的特例,它们都统称为ARMA模型。而ARMA(p,q)模型的统计性质也正是AR(p)模型和MA(q)模型统计性质的结合。
2.2. ARCH与GARCH模型
ARCH模型的全称是自回归条件异方差模型,有时简称为条件异方差模型。该模型的构造原里如下:假设在历史数据已知的情况下,零均值、纯随机残差序列具有异方差性,其完整结构为:
ARCH模型的实质是使用误差平方序列的q阶移动平均拟合当期异方差函数值。由于移动平均模型具有自相关q阶截尾性,所以ARCH模型实际上只适用于异方差函数短期自相关过程。
在实践中,有些残差序列的异方差是具有长期自相关性的,这时如果用ARCH模型拟合异方差函数,将会产生很高的移动平均阶数,这会增加参数估计的难度并最终影响模型的拟合精度。为了修正这个问题,Bollerslov在1985年提出了广义自回归条件异方差模型,它的结构如下:
GARCH模型实际上就是在ARCH的基础上,增加考虑了异方差函数的p阶自相关性而形成的;它可以有效地拟合具有长期记忆性的异方差函数。显然ARCH模型是GARCH模型的一个特例,ARCH(q)模型实际上就是
的GARCH(p,q)模型。
3. 基于时间序列的股票实例分析
3.1. 神州长城股票收盘价格建模
3.1.1. 数据预处理
图2是神州长城开盘价的自相关与偏自相关图,从中可以看出神州的开盘价序列其自相关函数衰减是非常缓慢的。从图1和图2可以判断神州长城的开盘价序列是一个非平稳时间序列。为了消除开盘价时间序列的非平稳性,可以对序列进行一阶差分。
从图3可以看出神州长城开盘价一阶差分序列基本上是围绕0值上下波动,初步判定其是一个平稳的时间序列,下面再通过自相关及偏自相关函数来进一步检验平稳性。
从图4可以判断,神州长城股价时间序列的一阶差分序列是一个平稳时间序列。通过一阶差分消除

Figure 1. Time series of opening price
图1. 收盘价时间序列图

Figure 2. Autocorrelation and partial autocorrelation
图2. 序列自相关图和偏自相关图
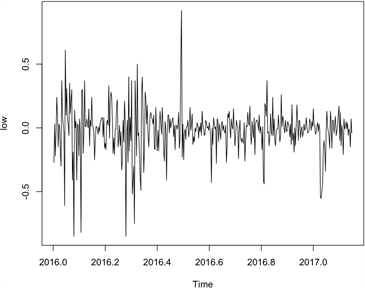
Figure 3. Close price: difference of first order
图3. 关盘价一阶差分图
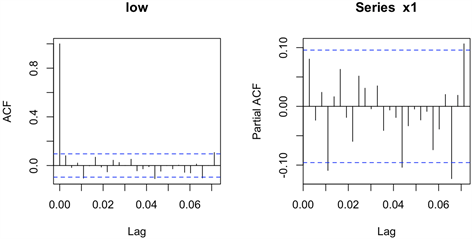
Figure 4. Autocorrelation and partial autocorrelation
图4. 自相关图和偏自相关图
了线性趋势,而且由图看出序列的自相关性不明显,根据平稳性判断准则,原始非平稳数据经过一阶差分能迅速转化为平稳序列,说明原始序列的非平稳性较弱。
3.1.2. 建立ARIMA模型
通过一阶差分消除了线性趋势后,由一阶差分序列的自相关图可知其自相关函数是一阶截尾的,所以我们可以先对原始收盘价序列建立ARIMA(0,1,1)模型,即对差分后的序列建立MA(1)模型。
表1为白噪声检验结果,由标中计算所得的p值可知该拟合模型的残差白噪声检验显示该模型显著成立,利用该拟合模型,还可以预测序列未来的水平,如图5。
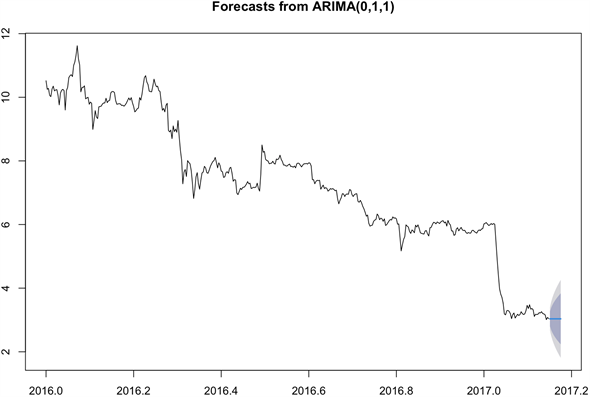
Figure 5. Time series prediction chart of the closing price
图5. 神州长城收盘价的序列预测图
虽然使用ARIMA模型能拟合出非平稳序列,但是其对残差序列有一个重要假定——残差序列
为零均值白噪声序列。我们用拟合的模型拟合出股票价格再计算出残差序列如图6。

Figure 6. Residual time series of ARMA model
图6. ARMA模型的残差序列图
残差序列要满足如下三个假定条件:1) 零均值,如图3~6残差序列的值基本上是围绕0值上下波动的。2) 纯随机,如表1该拟合模型的残差白噪声检验P值均显著大于显著水平
,所以该序列不能拒绝原假设,即残差为白噪声序列。3) 方差齐性,如图6我们可以看出残差序列方差一直再波动,不再是个常数,它会随着时间变化而变化。所以我们认为我们建立的ARIMA(0,1,1)模型存在异方差,接下来便使用GARCH模型提取异方差中蕴涵的相关信息。
3.1.3. 建立GARCH(1,1)模型
根据GARCH模型建立步骤,初步确定收盘价时间序列的基本形式,并对残差进行拉格朗日乘子检验,检验时间序列是否存在ARCH效应:如果符合,根据相关效应及GARCH模型一般形式,确立几GARCH模型。根据上述分析,可尝试采用AR-GARCH模型对原始序列进行拟合,结合自相关图我们已经初步确定对神州长城收盘价时间序列建立ARIMA(0,1,1)模型,如果ARIMA(0,1,1)模型存在ARCH效应,则对其残差建立GARCH(1,1)模型。

Table 2. Conditional heteroscedasticity test
表2. 条件异方差检验结果信息
再对ARIMA(0,1,1)进行LM检验得,
和p-value =
6.751e−10。由LM统计量所对应的P值小于显著性水平0.05时,拒绝原假设,认为该序列方差非齐性。所以波动信息的提取首先是考察ARIMA(0,1,1)模型的残差平方序列的异方差特征。Portmanteau Q检验也显示残差序列显著方差非齐,且具有长期相关性。所以构造GARCH(1,1)模型,并根据该模型的拟合绘制波动的95%置信区间图和方差齐性置信区间比较图。
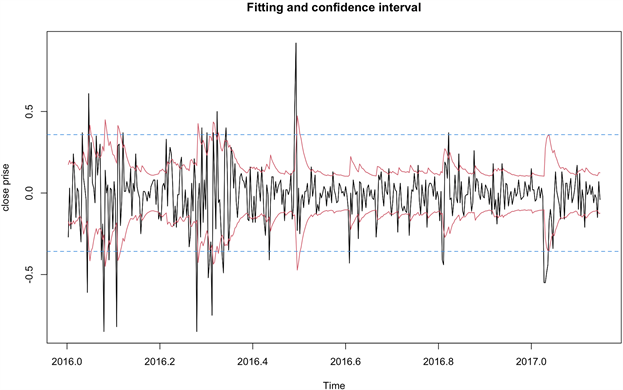
Figure 7. Fitting and confidence interval
图7. 拟合与置信区间
图7中间的波动曲线是一阶差分时序图,两条平行虚线是根据方差齐性得到的95%置信区间,两条波动实线为根据GARCH(1,1)模型拟合结果绘制波动95%的置信区间。综合水平模型和波动模型,我们得到的完整拟合模型为:
在GARCH模型中参数
,
,分别是前一期波动率的估计系数和估计残差的系数,单独看二者没多大的经济意义,主要看
这两个系数之和,系数越小,则说明该股票的波动相对平缓稳定一些,即GARCH(1,1)模型中的
都小于1,在模型满足平稳条件下,说明随机冲击对股市影响的持续时间是有限的,能够对其进行各项检验。而神州长城股票收盘价所建立的GARCH(1,1)模型的
的数值很大,非常接近于1,说明我国股票市场波动对冲击的反应是以一个相对较慢的速率衰减。随机冲击的影响还是具有相当程度的持续性。当证券收益率一旦受到冲击出现异常波动,则在短期内很难得以消除。
3.1.4. 模型拟合预测
再根据我们建立的GARCH模型拟合趋势并预测未来十天神州长城股票收盘价,ARIMA(0,1,1)模型包含了水平线性的趋势和GARCH(1,1)蕴含了误差的波动率,由对残差建立的GARCH模型我们可以得到未来十天预测的波动率,如表3。
由我们得到的完整拟合模型预测未来10天股票收盘价为表4。
Table 4. The closing price forecast for the next 10 days
表4. 未来10天收盘价格预测
图8中黑色的虚线为原始数据的时间序列,而红色的实线为根据我们建立的模型拟合的时间序列,可见拟合效果还是不错的。
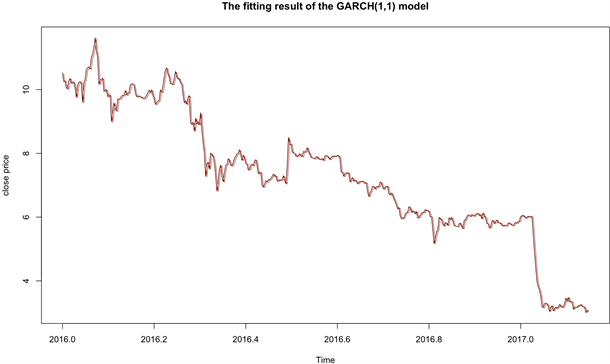
Figure 8. The fitting result of the GARCH (1,1) model
图8. GARCH(1,1)模型拟合图
3.2. 股票日成交量建模
股票成交量为买卖双方达成交易的数量。成交量是市场供需的表现,是判断市场走向的重要指标;当市场行情持续上涨,出现急剧增加的成交量,持续上涨之后,股价在高位大幅度震荡,卖压沉重,成交量减少,从而形成股价下降的趋势;股价急剧下降之后,又会形成大量的成交量。股价一般会随着成交量的上涨而上升,因此,研究股票的成交量对股市行情也有着重要的作用。
3.2.1. 序列特征初分析
首先,画出成交量的时序图,如图9所示。该序列无明显的趋势效应以及周期性变化,可近似看做平稳序列。进一步,对神州长城股票日成交量数据我们对其作纯随机性检验。根据假设检验,提出检验的原假设与备择假设:H0:
,
vs. H1:至少存在某个
,
,
。在400多个数据下,其近似为大样本数据,根据Box和Pierce提出的Q检验统计量,由观测数据我们得到了该序列延迟12期的样本自相关系数,如表5。
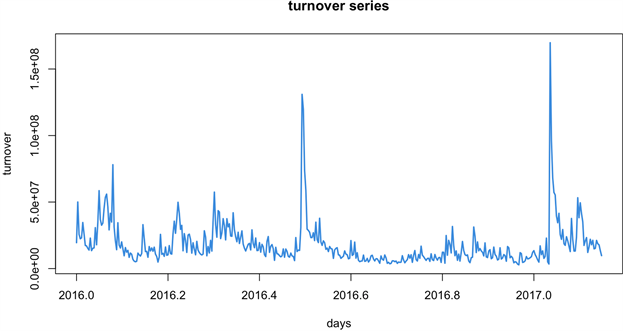
Figure 9. Time series chart of daily trading volume
图9. 日成交量时序图
Table 5. Stock daily trading volume sequence delay 12 self-correlation coefficient
表5. 股票日成交量序列延迟12自相关系数
根据上表,容易计算出表6的结果。表6中Q检验统计量结果显示,延迟期数为6期与12期时和在显著性水平
下,统计量的值均大于
分位点;则拒绝原假设,认为该序列为非白噪声序列。序列的白噪声检验通过之后,并进一步画出其自相关图与偏自相关图。
根据序列的自相关图与偏自相关图显示,我们认为该序列自相关系数拖尾,偏自相关系数3步截尾;故可初步采用自回归AR(3)模型来拟合该序列的发展趋势。
3.2.2. 建立AR(3)模型
Table 7. Calculation results of AR (3) model
表7. 模型相关计算结果汇总表
根据计算R语言运算结果,我们得到表7结果,于是我们得到初步的模型为:
,
或者等价写为:
延迟6期和延迟12期的p值约等于1,即模型的残差白噪声检验p值接近1,于是接受原假设,认为该拟合序列的残差为纯随机学咧;系数的显著性检验1、3均通过,第二个系数没有通过,模型有待优化。
3.2.3. 模型拟合及预测
根据上述模型,我们进行与原模型的拟合与18期预测,预测结果如表8。
Table 8. 18 period of forecast results
表8. 18期预测结果
为了能够给出预测值95%的置信区间,我们须计算出相应的Green函数值,由Green函数的递推关系式:
,
得到递推关系:
根据上述
时的递推关系,我们便能计算得到相应的Green函数值,再根据l步预测的方差公式
得到l步预测股票日成交量的95%置信区间为:
。
由上述分析,我们将序列后半部分的真实值、模型拟合值、模型预测值、拟合值的95%置信上下限以及预测值的95%置信上下限绘制于图10中(中间黑色曲线为模型观察值序列,中间绿色线条为模型拟合曲线,蓝色散点为95%的置信上下限,红色散点为预测值95%的上下限,蓝色曲线为预测值曲线)。
3.2.4. 模型优化
上述模型系数的显著性检验并没有全部通过,且预测值不太理想,模型有待优化,故进一步考虑对其进行差分处理,再考察其差分序列的平稳性。经一阶差分后,得到相应的时序图如图11,一阶差分后的序列较原序列显然更加平稳。
再根据差分后的自相关图和偏自相关图定阶,自相关系数呈2阶截尾,偏自相关呈拖尾,故可采用2阶移动平均MA(2)模型来拟合序列的发展趋势,相关结果如表9,且相比于上一个模型,系数显著性检验以及残差白噪声检验在置信水平为
的情况下,均通过了检验,从而得到模型,
,
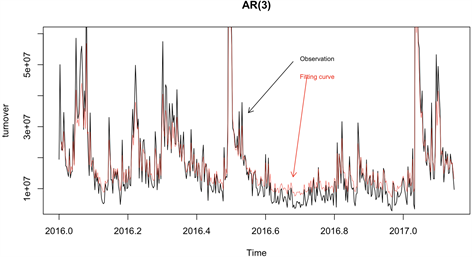
Figure 12. The fitting of AR (3) model and original sequence
图12. AR(3)模型与原序列的拟合图

Fitting 13. Diagram of the MA (2) model after first-order difference and the original sequence
图13. 一阶差分后MA(2)模型与原序列的拟合图
为了能够对比两个模型的优劣性,我们分别将两个模型与原序列拟合,观察两个模型拟合的效果,从拟合的效果对比来看如图12、图13,其中不同颜色的曲线分别代表观测值曲线和拟合曲线。显然MA(2)模型要优于AR(3)模型,于是我们得到了较优的最终模型为MA(2)模型。并利用此模型,预测未来五天的日交易量分别为:13,141,446、14,767,273、14,640,473、12,535,683、17,523,871。同时与真实未来五天的日交易量对比,我们预测值的平均误差仅在35,213.91左右,说明该模型不仅能够较好的拟合日交易量,并且预测也有较好的准确性。
4. 结论与启示
由于股价一般会随着成交量的变化而变化,因此本文对成交量进行分析,股票成交量的对象是神州长城的400多个股票成交量数据。首先我们先对数据进行纯随机性检验,判断其数据的平稳性。在400多个数据下,其近似为大样本数据,根据Box和Pierce提出的Q检验统计量,由观测数据,我们得到了该序列延迟12期的样本自相关系数,根据检验统计量的结果显示,可以认为该序列为非白噪声序列。序列的白噪声检验通过之后,我们根据该序列的时序图可以看出该序列无明显的趋势效应以及周期性变化,可近似看做平稳序列。接着根据序列的自相关图与偏自相关图,我们认为该序列自相关系数拖尾,偏自相关系数3步截尾;故可初步采用自回归AR(3)模型来拟合该序列的发展趋势。在模型的残差白噪声检验和系数的显著性检验中,模型的残差白噪声检验P值均接近于1,于是接受原假设,认为拟合序列的残差为纯随机序列;系数的显著性检验1、3均通过,第二个系数没有通过,模型有待优化。根据上述模型,我们还是可以进行对原模型的拟合与18期预测,计算出相应的Green函数值,于是得到步预测神州长城日成交量的95%置信区间。
由于上述模型系数的显著性检验并没有全部通过,我们的模型有待优化,故后续还可以进一步考虑对其进行差分处理,再考察其差分序列的平稳性。通过一阶差分后的序列较原序列显然更加平稳,其自相关系数呈现2阶截尾,偏自相关图拖尾,故可采用2阶移动平均MA(2)模型来拟合序列的发展趋势。而该模型也通过了残差白噪声检验以及系数的显著性检验。
随着机器学习的发展,神经网络在时间序列模型中的应用非常广泛,可以用于预测、分类和生成时间序列数据。RNN是最常用的时间序列模型之一,它被设计用于处理具有时间依赖性的数据。长短期记忆网络(LSTM):LSTM是RNN的一个变体,专门用于解决长时间依赖问题。LSTM在RNN的基础上增加了门控机制,能够更好地捕捉和记忆长期的依赖关系,这使得LSTM在处理长时间序列任务上表现出色。还有其他各种类型的神经网络可以根据实际情况选择使用,这也是我们后续的研究方向。
参考文献