1. 引言
人们总想着通过某些方式来记录生活中的美好瞬间。早在上世纪20年代,Buckminster Fuller就开始用剪贴簿来记录生活中的日常,到了上世纪90年代时,Steve Mann通过摄像机拍摄照片来记录自己的生活经历 [1] 。近年来,随着可穿戴设备和定位系统的发展,记录个人活动的方式发生了改变,人们开始用数据来记录生活中的细节。这些数据包含人的生活数据,健康数据,我们称这类数据为PBD (Personal Big Data) [2] 。PBD具有隐私性,lifelogging就是PBD的一个典型代表。
lifelogging数据是个人在日常生活中的生活经历和行为创建的个人数据,其中包括了位置 [3] 、行为 [4] 、音频 [5] 和图片 [6] 等。这些数据揭示了一个人在何时何地发生了哪些事情,通过对数据的进一步分析,我们还能够分析用户的日常行为 [7] [8] [9] 。过去几年间,lifelogging受到了研究人员和商业公司的广泛关注,lifelogging也逐渐成为了一个新兴的研究领域,一些关于lifelogging的社会应用也随着发展,如运动数据分析 [10] [11] 、数字医疗 [12] [13] 、智能家居 [14] [15] 等。
随着移动设备和传感器技术的进步,越来越多的数据被存储到时空数据库中。这些数据中隐藏着大量的信息,比如吃饭、上班和到公园游玩等 [16] 。如何从帮助用户管理海量的lifelogging数据是lifelog研究面临的重大挑战之一。对于少量的数据,用户可以逐个的查看这些lifelogging找到需要的内容。但是当数据量过多时,用户就需要一个合适的方法帮助他们管理这些数据。文献 [17] 提出了一种基于集群层次结构在图中排列数据的方法。Hwang等人 [18] 提出了一种基础机器学习管理数据的方式,Kim等人 [19] 提出了一种分层化数据记录方式。
来自“国立台湾大学”的学者颜安孜在2019年将lifelogging中的事件识别问题列为lifelog领域十大问题之一 [20] 。本文将在此基础上进行思考,我们是否可以将lifelogging划分为不同的事件,从而有效的管理数据。在本文中,我们提出了LE-PDA模型,该模型采用分层事件挖掘,分别对城市级数据和区域级数据进行挖掘。除此之外,我们还对每个事件进行了添加了标签,用户可以通过事件标签更好地管理自己的lifelogging数据。对于数据上传者来说,这是一项非常有意义的工作。
本文的章节总共分为6节,本节为绪论。第二节介绍了作者11年间收集的Liulifelog数据集,并引入了“域”的概念,同时说明了实验的目标。第三节阐述了如何使用LE-PDA模型找到用户数据中的生活事件。第四节对模型的实验结果进行性能对比和分类。第五节建立可视化系统,用以展示生活事件。最后一节对实验进行总结,并展望未来的研究方向。
2. 相关工作
2.1. LiuLifelog数据集
LiuLifelog数据集(http://www.lifelog.vip/)是Liu团队花费12年时间记录的数据。该数据集有以下优势:采样时间长,参与者人数众多,数据分布于全国各个城市且持续更新。每天有十几名用户分享他们的日常生活,使这个数据集成为生活日志数据的综合存储库。其中部分数据如表1所示。
我们的数据是非连续性的,每一条lifelogging包含GPS数据、文字描述、录音、图片或者视频文件等,并且在上传数据的时候对每一条lifelogging进行了行为分类标注,行为分类是事先定义好的,例如:讲课、吃饭、工作、旅行等15个类别。
2.2. 实验目标
在Lifelog中,生活事件可以划分为两种类型。第一种是独立的事件,它们通过单条数据记录表示。例如,“我去餐厅吃饭”或“准备去公司上班”等。第二种是连续的事件,它们由一系列数据记录共同构成。图1展示了一个连续的生活事件。
图1描绘了用户在公园游玩的场景,用户在这期间上传了6条lifelogging,这些数据一起组成了一个连续的生活事件。本文的主要目的就是识别用户数据中单独的和连续的生活事件,并为每个事件进行分类。通过这种分类,可以帮助用户更有效的组织自己的数据,以事件为线索来管理他们的数据。
2.3. 域的概念
在本文的实验中,我们将使用数据的地理位置属性。为此,我们提出了“域”的概念,该概念基于地理坐标,将空间位置相近的lifelogging分类到同一区域,这一过程的示意图如图2所示。
图2中,假设在某一个时间段内,总共采集了12个lifelogging数据,这些数据定义为
,其中
都是在沈阳建筑大学采集的,
是体育馆,
是某个饭店,我们给每一个位置分类定义为domain,比如
所在的位置可以定义为domain B。
3. 实验过程
本文提出了LE-PDA模型,该模型采用了分层的方法,分别对城市间和区域内的事件进行挖掘。在城市级别,主要挖掘的是城市间的活动,如出差和旅游等。在区域级别,主要挖掘的是日常生活中的事件,如看电影、用餐等。
3.1. 数据预处理
在实验之前,需要对数据进行预处理,具体步骤如下:
1、由于GPS定位时信号的问题会有一些噪音点和离群点。比如一些数据地点为空,有些数据的经纬度为0等。所以在进行实验之前,我们需要将这些噪音点和离群点去除。
2、数据集中存在一些冗余数据,当用户在较短时间内连续发布多条数据时,我们取其中一条数据作为有效数据。
经过预处理的后的lifelogging数量如图3所示:
在数据集中,我们选择了两位用户作为本次实验的对象。一位用户在12年间上传了11,032条数据,另一位用户在3年间上传了1558条数据。经过数据预处理后,我们将一些缺失数据和错误数据进行清除,保证了数据的鲁棒性和准确性。
3.2. 城市事件挖掘
挖掘城市事件时我们将城市作为域,同时需要设置起始域。文献 [21] 指出,人类的移动模式具有一定的规律性,通常在一段时间内会在一个或几个固定的区域中活动。在网络图中,度值越大的区域连通性越强。因此,我们选择度值较高的城市作为起始域。算法伪代码如下:
我们首先以城市为节点构建了一个网络图,并计算了各节点的度值,根据度值设定起始域。随后,我们引入了DTW算法,结合滑动窗口技术,来动态的计算相邻起始域之间的城市相似度。如果计算出的相似度小于设定的阈值F,我们将其视为两个不同的事件event和temp_event,同时将event加入事件列表E中。否则,我们则认为这两个事件相等,合并为一个事件,继续循环进行比较。
3.3. 区域事件挖掘
区域事件是指起始域中的事件。在挖掘lifelog中的事件时,发现数据间的语义关系的也被认为是一个有效方案。但是如果只使用语义关系可能会使一些事件不能被准确挖掘。在图1所示的数据中,如果按照语义关系的方式来挖掘生活事件,那么这些数据会被认为是多个不同的事件。实际上,这是一个在公园游玩的事件。于是,我们结合语义关系和地理位置来挖掘用户数据中区域事件,过程如图4所示。
在图4中,首先使用DBSCAN聚类算法,将数据划分为1142个不同的域,我们用十进制阿拉伯数字表示每一个域。接着进行文本处理,为了提高文本识别的精确度,实验使用en_core_web_sm和en_core_web_lg两种文本语言模型处理数据中的文本。然后对文本语言分别进行了停词筛选、语法识别、NER实体识别和句法分析等方法,提取出文本中的关键词。最后经过算法2后得出了数据中的事件。
算法2的伪代码如下所示:
对于通过语言模型找到的关键词D,我们对每一个关键词使用TF-IDF进行向量化。在时间间隔小于阈值T的情况下,算法主要包含两个步骤:对于TF-IDF余弦相似度大于阈值F的相邻数据,或者“域”相等且余弦相似度大于F的不相邻数据,我们将其视为一个连续的事件E = {L1, L2, …, Ln},其中Ln = {D1, D2, …, Dn}。否则我们将其视为单个的事件E = {L1, L2, …, Ln},其中Ln = {Dn}。
4. 实验结果和分类
4.1. 实验结果和性能对比
经过模型运算之后,我们得到了两位用户的lifelogging中所有的事件。我们提取每一个事件的域、文本和时间特征值,得到的结果如下表2、表3所示:
在表中可以看到,User1数据被划分为5215个事件,User2数据被划分1086个事件。接下来,我们对数据集中的事件进行人工标记。将本实验使用的LE-PDA模型和目前常用的事件挖掘TDT算法进行性能对比,如图5所示。
在图5中,LE-PDA模型识别事件的准确率达到了68%,而TDT算法识别事件的准确率是56%。可以发现,在结合了域的使用后,本文提出的LE-PDA模型在性能上明显优于TDT算法。
4.2. 行为分类
数据集中的每一条数据都有一个行为属性。在实验结果中,我们可以按照数据的行为属性对事件进行分类。我们首先统计事件数据中行为出现的频率。然后根据行为的频率,可以为它们分配权重。频率最高的行为权重最高,可以被认为是最重要的。经过分类后,事件的类别表4所示:
在表中可以看到User1的事件被划分成了15个不同的类别,User2的事件分为了11个类别。这个分类过程保证了每一个事件都得到了准确的分类,使得用户能够根据行为类别高效的管理事件数据。当用户想要查找某个事件时,比如在校吃饭,那么他就可以在“Meal at school”类别中来找到相应的事件。
4.3. 重要性分类
不同的事件对于用户的重要性是不一样的,当我们回想起某一年经历的事情时,首先想起的是一些重要的事情。因此,为事件添加重要性标签也是一种能够帮助用户管理数据的方法。
为此,我们采用了半监督机器学习方法来为事件自动标注重要性。我们首先随机选取了一些事件,并手动给它们标上了“不重要”、“一般”和“重要”的标签,以此作为半监督训练的基础。在此过程中,我们测试了三种不同的半监督学习模型,并记录了它们的性能表现。如下表5所示:

Table 5. Importance recognition performance
表5. 重要性识别性能表
在上表中我们可以发现,S3VM的性能明显优于另外两个模型,展现出较高的准确率。此外,我们还对比了在模型中加入域和行为标签前后的性能差异。结果表明,引入这些标签后,所有模型的性能均有所提升。其中,一些模型的准确率甚至提高了20%。这一结果证明了为事件添加域和行为标签的有效性。使用S3VM后两位用户事件重要性分类结果如下图6所示。
对于lifelogging数据,将其划分为不同的事件进行管理不仅提升了数据的可用性,也增强了用户体验。通过为事件添加标签类别,使得管理个人数据变得既简单又直观。这种方法为用户提供了明晰的数据管理方式,让用户能够快速的对数据进行整理和归类。
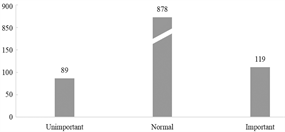
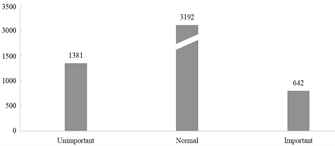 (a) User1重要性分类 (b) User2重要性分类
(a) User1重要性分类 (b) User2重要性分类
Figure 6. Importance classification chart
图6. 重要性分类图
5. 系统实现
Lifelog一个重要的功能就是回忆,通过查看lifelogging数据,用户能想起许多过去珍贵的记忆。McGookin [22] 用时间和地点的方式展示用户在多个区域的所拍摄的图片。文献 [23] 提出了基于web的应用程序检索lifelogging,用户可以根据需求检索想要回忆的内容。在本节中,我们尝试以事件为核心的方式呈现用户的数据,以帮助用户更好的回忆过去。为此,我们使用Java和Html建立了一个可视化系统。以User1为例,展示了该用户的城市级事件。系统的主页面如图7所示。
在此系统中,用户可以通过搜索城市或时间查找想要回忆的内容。当搜索北京市时,系统会显示所有关于北京市所发生的事件。当搜索某一天时,系统会将包含这一天的事件进行展示。例如当我们搜索2015年1月14号时,显示的事件如图8所示。
在此图中,我们可以知道用户在2015年1月14号出发,前往湘潭出差。途中经过了杭州,长沙。
第二天到达湘潭。在湘潭的Furong West Road休息,在Xiaotang Road做家务和吃饭,在Shuangyong South Road工作。第三天从湘潭离开,这次出差共持续了3天。
实验的结果已经公开,读者可以在网站(http://www.lifelog.vip/LifeEvent.html)进行查看。通过该系统,我们可以清晰直观的查看用户的过去的一些事情。对于数据上传者而言,这是非常有意义的,因为该系统可以帮助他们想起自己过去的记忆。
6. 总结与展望
在本文中,我们介绍了一种用事件帮助用户整理lifelogging数据的方法,并提出了LE-PDA模型。该模型通过分层挖掘将数据划分为城市级和区域级事件。同时我们对每个事件进行了分类,用户可以通过事件标签更有效的整理数据。此外,我们还以事件为中心建立了可视化系统,用以帮助用户更好的回忆过去。本实验的不足之处是,目前系统只展示了城市级事件。在未来,我们将更新系统,将区域级的事件也进行展示,从而提供一个更加全面的回忆体验。
基金项目
辽宁省教育厅自然基金项目(LJKZ0595)。