1. 引言
在复杂环境下,单个摄像机获得的图像信息是有限的。难以支持对象检测和语义分割等后续任务 [1] 。图像融合技术的出现解决了这个问题。其中,红外图像和可见光图像的融合是最常用的 [2] 。
在过去几十年中,人们使用统计方法设计了各种图像融合算法,包括基于多尺度分解的方法 [3] ,基于稀疏表示的方法 [4] 和基于显著性的方法 [5] 。这些方法都具有一个共同特点,它们将图像分解成多个层次,并为不同的层次设计不同的融合规则。融合结果受到分解方法的限制。为了实现良好的融合结果,必须设计极其复杂的分解方法,这对实时处理构成了挑战。此外,手动设计的分解方法没有良好的鲁棒性。近年来,随着深度学习的发展,提出了许多基于神经网络的图像融合算法。基于神经网络的融合算法可以分为基于卷积神经网络的方法 [6] [7] [8] 和基于对抗神经网络的方法 [9] [10] 。基于卷积神经网络的算法利用神经网络的特征提取能力提取特征,融合来自多个源图像的特征,并设计损失函数重建融合特征。基于对抗神经网络的方法使用生成器和判别器,通过两者之间的对抗学习获取融合图像。
2. 现存问题
目前,基于神经网络的图像融合算法可以取得良好的结果,但仍存在一些问题:
(1) 多源图像的特征提取网络彼此独立,导致自然融合结果较差。例如,在图1中的SDNet [11] 和FuionGAN [12] 的红框部分,两种模式的信息在特征提取过程中没有融合,导致融合结果中存在接缝感。
(2) 普通卷积可能会导致信息丢失。例如,图1中的FusionGAN使用普通卷积,导致模糊和对比度较差的融合结果。
(3) 没有考虑到照明信息,融合结果的亮度非常低。例如,图1中的三种方法都努力保持纹理和细节。然而,它们都没有考虑到融合过程中亮度的降低,我们可以在红框中清楚地看到这一点。GFF [13] 方法的天空部分更像是可见光和红外图像的平均值,而SDNet和FusionGAN错误地保留了红外的天空部分,而我们的方法成功地保留了更明亮的可见光图像的天空部分,而没有任何亮度降低。

Figure 1. Comparison of typical fusion results, these are the following: visible image, infrared image, GFF, SDNet, FusionGAN, Ours
图1. 典型融合结果对比:可见光图像、红外图像、GFF、SDNet、FusionGAN、Ours
3. 相关工作
3.1. 基于CNN的图像融合
随着深度学习的发展,图像融合领域出现了许多新的算法。最初,研究人员仅使用神经网络构建图像融合的权重图,而没有完全放弃传统方法。Li等人 [14] 使用目标函数最小化的方法将图像分为基础层和细节层,并使用平均方法对基础层进行融合。使用VGG网络提取细节层的特征,并对特征图进行归一化,获得细节层的权重图进行融合。这种应用并没有充分发挥神经网络的性能。随着研究的进展,出现了许多完全基于神经网络的融合算法,通过设计不同的特征提取网络和损失函数,获得了具有自身特点的结果。Li等人 [15] 设计了一个使用卷积神经网络的编码器和解码器来实现融合任务的方法,称为DenseFuse。该方法在编码器特征中对不同的卷积层进行了不同的处理,将每一层的输出与所有后续层连接起来,并设计了同时考虑结构和像素损失的损失函数,获得了相对较好的融合结果。这种方法中向后传递浅层特征的思想启发了本文中多级融合的设计。Ma等人 [16] 在融合网络的损失函数中进行了优化,并设计了STDFusion,将图像分为显著区域和背景区域,并分别计算融合图像的显著区域和背景区域的损失,获得了更好的融合结果,但该方法的有效性依赖于分解算法的性能。通过使用传统方法,一个强大的分解算法也可以产生良好的结果。Tang等人 [17] 使用类似的思路采用语义分割网络实现图像分割,为不同的区域构建不同的损失,并在特征提取网络中考虑多级特征的互补性,证明了多级特征融合的有效性。许多研究人员还尝试突破红外和可见光图像之间的障碍,进行更深层次的融合。Li等人 [18] 在DenseFuse之后增加了特征融合,并提出了一种新的网络结构。多源图像的四个尺度的不同特征由编码器获得,输入到RFN模块进行融合,然后将融合的特征输入到解码器进行解码。这种方法以多层次的方式创新地结合了多源图像,融合结果展示了多层次融合的有效性。Tang等人提出的PIAFusion [19] 也考虑了多源特征之间的关系,并设计了类似差分电路的CMDAF模块,用于逐步融合多源特征。融合中保留照明信息也是一个具有挑战性的问题,如何在照明过低和过高的极端条件下保持良好的照明水平需要解决。
此外,一些最新的工作利用语义信息进行图像融合,紧密联系了上游和下游任务。Xie等人 [20] 提出了一个融合网络,嵌入了语义信息,并将融合任务和对齐任务组合在一个网络中进行。这种方法非常创新,推动了工程应用中图像融合技术的发展。
3.2. 基于GAN的图像融合
这种GAN方法通过设计两个相互对抗的网络来创新地利用神经网络来学习融合结果。生成器经过专门训练以生成欺骗判别器的融合图像 [21] [22] 。Xu [23] 等人设计了一个双条件双判别器对抗神经网络,其中两个判别器的训练损失组合了可见光和红外光,其中一个判别器通过计算融合图像和可见光图像的梯度损失进行训练,另一个通过计算融合图像和红外图像的梯度损失进行训练。Ma等人 [24] 设计的DDcGAN网络具有类似的结构。Zhang等人 [25] 设计的GAN-FM采用了U-Net网络结构,在生成器的网络设计中尝试保留更多语义信息。Li等人 [26] 在网络中引入了注意机制,并设计了AttentionFGAN。Rao等人 [27] 提出了一种结合语义信息的融合网络:AT-GAN,通过强度维护模块在红外图像中保持热目标信息,并通过使用语义转换模块在可见光图像中滤除噪声,从而实现了良好的融合结果。这些GAN的框架相似,都由一个生成器和两个判别器组成。值得指出的是,这种框架也导致了这些融合网络的复杂训练。总之,一个好的融合网络应首先考虑多个源图像的多层特征之间的融合,其次,尽可能保留多个源图像的照明信息也尤为重要,最后,一个端到端的、易于训练的网络可以更容易和快速地应用于工程中。
4. 方法
本节对本文的方法进行了全面介绍。首先,详细描述了MLFFusion的模块结构,然后说明了网络的损失函数,最后给出了网络的结构。
4.1. 模块结构
首先,多源图像的融合需要将不同图像的优点融合到融合图像中。红外光包含丰富的目标信息,可见光包含精细的纹理信息,将两个图像在深层次上进行融合是需要解决的问题。其次,传统的卷积网络通过卷积获得特征时会存在冗余信息,更加注重有用信息可以提高网络特征提取的质量。最后,损失的设计不能仅关注融合图像的质量,尽可能保留亮度信息不仅可以提高融合图像的对比度,还可以提高融合算法在低光和其他恶劣环境下的鲁棒性。因此,本文设计了以下三个点来解决这些问题。
4.1.1. MLFF模块
MLFF (多级特征融合)模块旨在实现多级特征融合。卷积神经网络在网络深度加深时可以更详细地提取特征,但深层网络结构可能导致某些特征丢失,因此需要进行跨层特征补充。在图像融合任务中,仅在特征提取网络末端进行融合无法充分融合跨模态信息,因此在网络特征提取的图中进行渐进式融合也是必要的。因此,MLFF模块的定义如下:
MLFF模块包含4个输入。表示浅层红外特征和浅层可见特征,
和
表示更深的红外特征和更深的可见特征,
和
多源和多水平融合红外特征和可见光特征的表示。MLFF模块的结构如图2所示。
更具体地说,MLFF模块首先在两个浅层特征之间的通道上建立连接,以完成浅层多源特征的融合,定义如下:

Figure 2. MLFF module schematic, the top box indicates multi-layer information fusion, the middle box indicates the MLFF module schematic and the bottom figure indicates multi-source information fusion
图2. MLFF模块示意图,上框表示多层信息融合,中框表示MLFF模块示意图,下图表示多源信息融合
这个公式表示通道之间的逐通道连接,而1表示融合的浅层特征。该公式表示浅层多源信息的融合以获取融合的浅层特征。然而,此时获取的浅层融合特征与深层特征的比例不匹配,因此需要进行1 × 1卷积来调整浅层融合特征的比例,并且可以对调整后的融合浅层特征进行池化和激活,以获取权重向量来指导深层特征的融合。该过程的定义如下:
其中
表示1 × 1卷积操作以平衡浅层和深层特征的规模,
表示从融合的浅层特征中提取信息的全局平均池化,
表示一个sigmod函数,用于将特征映射的值限制在[0-1]和输出之间w表示得到的权重向量,可以将其与深层特征逐个元素相乘,以获得融合的深层特征。定义如下:
其中,
是逐通道乘法运算,
是逐通道求和,
和
是深层特征,并且
,
是从浅层特征中提取的深层互补信息,并且
和
是MLFF模块之后的多级、多源融合红外/可见光特征。此步骤类似于自注意力计算,其中浅层信息用于指导深度多模态信息融合。
神经网络可以通过堆叠卷积层不断提取特征,我们将靠近输入的特征定义为浅层特征,而靠近输出的特征定义为深层特征,见图3。具体而言,在MLFF (多级特征融合)模块中,有四个输入,分别是可见光浅层特征和红外光浅层特征(接近网络输入部分),以及红外深层特征和可见光深层特征(接近网络输出部分)。随着网络的不断加深,提取的特征特性也不同。例如,在图3中所示,浅层特征是靠近输入的特征,包含更多关于图像的详细信息;深层特征是靠近输出的特征,不再具有详细的特征,而是包含更抽象的语义特征。

Figure 3. Definition of shallow and deep features and their visualisation
图3. 浅层和深层的定义及其可视化
由于不同层次的特征具有不同的特点,我们需要融合多层特征,这就是为什么我们连接浅层和深层特征的原因。由于来自不同来源的特征之间存在巨大差异,我们需要分阶段融合特征。由于浅层特征包含更多的详细信息,全局池化后得到的向量的方差更大,估计的权重可以具有更大的方差分布,因此我们使用浅层特征来估计权重,这意味着我们可以将深层特征与浅层特征关联起来,并获得具有较大方差的权重用于融合,避免了“平均”情况下的融合。
4.1.2. SAconv模块
这个传统的卷积对每个通道都赋予了相同的重要性,这是不合理的。SENet [28] 提出了一种具有自我注意机制的网络,本文将这种方法应用于编码部分,并设计了编码部分的基本单元,即SAconv模块。图4显示了SAconv模块的结构,首先卷积输入张量,然后全局平均池化卷积结果以获得一个向量,然后对该向量进行激活,最后获得反映卷积后不同特征层重要性的向量,从而获得输出结果。
具体来说,首先对输入进行卷积以获得多个特征层,然后计算卷积结果上不同通道的不同权重:
其中x表示输入卷积的结果,
表示卷积核,
表示激励 [29] ,
表示sigmod函数和w表示权重矢量。

Figure 4. SAconv module structure diagram, where the input features are subjected to convolution and self-attention operations to obtain the enhanced features
图4. SAconv模块结构图SAconv模块结构图,输入特征经过卷积和自注意运算后得到增强特征
4.1.3. 区域照度模块
自然界中存在复杂的照明,在夜间等低光照条件下,图像的对比度通常较低。因此,如何在融合图像中保存光线是一个需要解决的问题。因此,本文使用二元分类网络来获取图像属于昼夜的概率。图5显示了二元分类网络的结构,表示为
。这样,对于每幅图像,可以得到它属于白天的概率和属于夜晚的概率,计算公式如下:
其中,
表示输入图像属于白天的概率,
表示输入图像属于夜晚的概率,并且input表示输入分类网络的图像。
对两个概率进行归一化,结果是图像的照明水平,计算如下,输出w是照明水平。
4.2. 损失函数
本节将详细介绍二元分类网络的损失函数和图像融合网络的损失函数,同时还会介绍光感知模块的应用。

Figure 5. Binary classification network structure. The first 4 layers are convolutional, the convolutional kernel size is 4, the post convolutional is ReLU activation function, GAP denotes global average pooling and FC denotes fully connected Layer
图5. 二元分类网络结构。前4层为卷积层,卷积核大小为4,后卷积层为 ReLU 激活函数,GAP表示全局平均池化,FC表示全连接层
4.2.1. 分类网络
图5中的网络结构是一个经典的二元分类网络,使用交叉熵损失作为网络的损失函数,定义如下。其中z表示输入图像的标签,0表示夜晚,1表示白天,以及y是网络输出的结果,
表示softmax函数。
4.2.2. 融合网络
融合图像需要保留多源图像中的显著区域,这些显著区域具有较大的梯度值。因此,保持融合图像中显著区域的任务可以被转化为获取多源图像的较大梯度的任务。我们可以定义显著损失如下:
其中,
表示图像的渐变,
表示红外图像,
表示可见图像和
表示融合图像,H,W表示图像的高度和宽度。该公式表示融合图像的每个区域选择多源图像中梯度值较大的部分。
其次,融合图像需要在多模态图像中包含一个平滑的背景区域,我们可以通过对像素值差异进行约束来保留这一区域,定义背景损失如下:
接下来,需要计算融合网络的光照损失。每个图像的不同区域具有不同的光照水平,对整个图像计算光照损失是不合理的。因此,图像被分割成块,并分别计算每个块的光照水平,定义如下:
其中,
表示通过分割获得的每个小图像块,n表示通过分割获得的小图像块的数量,并且
表示输入图像。
对于每个小块的图像分割,需要先获取小块的照明强度,然后再计算损失。可以通过二分类网络得到光强度序列:
在计算损失时,直接使用分类网络得到的概率进行损失计算显然是不合理的。照明依赖于图像中要呈现的像素的组合,因此,像素损失定义如下:
其中,
表示图像的像素损失a和图像b照度损失函数可以定义如下:
其中,
表示可见图像,
表示通过分割获得的可见图像序列。
表示红外图像,
表示通过分割得到的红外图像序列。
表示融合图像,
表示通过分割获得的融合图像序列。
表示从融合图像获得的照度矢量,w表示对应于每个融合图像块的照度值。
表示每个融合图像块和可见图像块的像素损失,以及
表示每个融合图像块和红外图像块的像素损失。值得注意的是,n图像块是原始图像大小相等的剪切。
最后,设置权重将三个损失联系起来。图像背景区域的照明损失和背景损失都保留,我们可以设置相同的权重,最终损失函数定义如下:
其中,
表示照明和背景损失的权重,以及
表示梯度损失的权重。
5. 实验配置
5.1. 数据集
MSRS [30] 数据集于2022年发布,包括1444对高质量红外和可见光图像。这些图像包括明亮的白天图像和不太明亮的夜间图像。因此,我们选择了MSRS数据集作为我们的训练数据集。
RoadScene有221个对齐的可见光和红外图像对,其中包含丰富的场景,如道路、车辆、行人等。这些图像是FLIR视频中极具代表性的场景。我们将之作为验证数据集。
5.2. 训练网络
融合网络使用MSRS数据集进行训练,该数据集包含1444个严格对齐的可见光和红外图像对。照明网络在处理后的MSRS数据集上进行训练。我们选取了50张光照良好的日间可见光图像和50张照明不佳的夜间可见光图像,共100张图像,然后通过裁剪将其扩展为6400张图像。我们将照明良好的白天图像标记为“白天”类别,将照明不佳的夜间图像标记为“夜间”类别,然后使用这6400张图像来训练我们的二元分类网络。值得注意的是,我们的二元分类网络的目的是结合损失函数保留融合图像的亮度信息,因此我们在训练图像的选择中避免了混淆“白天但低光”和“夜间但高亮度”的混淆。对于融合网络,我们使用从二元分类网络中选出的100张可见光图像和相应的红外图像,通过裁剪将这100对图像扩展为6400对图像,然后使用这6400对图像来训练融合网络。
代码是使用Pytorch-GPU实现的,二元分类网络首先使用交叉熵损失进行训练。然后使用本文提出的损耗对融合网络进行训练。对于二元分类网络,我们将训练会话的批量大小设置为128,学习率设置为0.01,训练周期设置为100。对于融合网络,我们将训练会话的批量大小设置为128,学习率设置为 0.001,训练周期设置为60,设置
为5和
为50。
5.3. 验证与评价
RoadScene数据集的场景亮度较高,因此本文提出的区域光照保留模块在该数据集中没有最大价值,但该方法在该数据集中仍有较好的性能。从表1中可以看出,本文中的算法在EN指标和Qabf指标上没有获得最佳结果,但它也排在前三名。Roadscreen数据集中图像的整体亮度较高,大部分是光照充足的白天场景,甚至数据集中的部分图像也存在曝光过度的问题。因此,它削弱了区域照度保持模块在本文中的作用,甚至对于一些曝光过度的图像,区域照度保持模块也会起到相反的作用。本文中的方法仍然具有良好的性能,证明了本文算法的鲁棒性。
本文中的算法在RoadScene数据集下所有5种评价指标中都获得了最高分。其中,AG、EN和SF是针对单独图像的三个评价指标,反映了融合图像的图像质量。表1中的信息表明,传统方法可以很好地执行,但程度不是非常高,并且FusionGAN方法是一种高度创新的特殊框架,但需要进一步优化网络以更好地执行融合任务。其他三种基于CNN的方法,DenseFuse,RFN-Nest和SDNet,给出了更好的融合结果。得益于区域照明信息保存模块,该方法在RoadScene数据集的评估指标中得分最高。Qabf、VIF、MI反映了融合图像中多源信息的集成程度,并且由于PIA中差分融合模块的设计获得了更好的结果。显然,本文中的MLFF模块具有更强的性能。

Table 1. Comparative analysis of eleven algorithms: mean performance metrics for six evaluation indicators on the RoadScene dataset
表1. 比较11种算法,RoadScene数据集下6个评估指标的性能平均值
为了证明该算法的有效性,从RoadScene数据集中选择了四组图像进行分析,如图6所示,传统方法在处理具有复杂亮度的环境时不能产生良好的融合效果。例如,在第一组图像的结果中,包括DLF方法在内的三种传统方法的融合结果对比度差,肉眼效果差,虽然GFF方法在清晰度方面表现不错,但在第四组图像中可以看出,这种清晰度是偶然的,并不健壮。

Figure 6. Visual comparison of our method with the 11 algorithms on the RoadScene dataset. For a clear comparison, we chose to highlight textured areas with red and green boxes
图6. 将我们的方法与RoadScene数据集上的11种算法进行可视化比较。为了进行清晰的比较,我们选择用红色和绿色框突出显示纹理区域
传统方法使用统计像素分布信息来生成融合图像,但在像素分布信息的每个部分都获得高分的复杂环境中,融合方法难以识别真正的“重要”区域,因此会产生对比度差的融合图像。
FusionGAN方法仍然无法摆脱融合图像亮度低和目标边缘模糊的问题,如第一张和第三图中的目标所证明的那样。DenseFuse和RFN-Nest在RoadScene数据集上不会表现优异。SDNet性能良好,获得了高清融合结果,但RoadScene数据集具有良好的照明度表现。PIA方法考虑了照明信息,但是是全局的,在光线充足的环境中,融合的图像太亮,这会影响视觉效果,反而会降低融合的质量。本文中的区域光照保持方法不存在这个问题,融合图像目标清晰,纹理细腻。
为了进一步说明,我们在RoadScene数据集上选择了20对图像来制作图像指标的变化曲线,如图7所示。曲线表明,本文中的算法在RoadScene数据集上效果斐然。
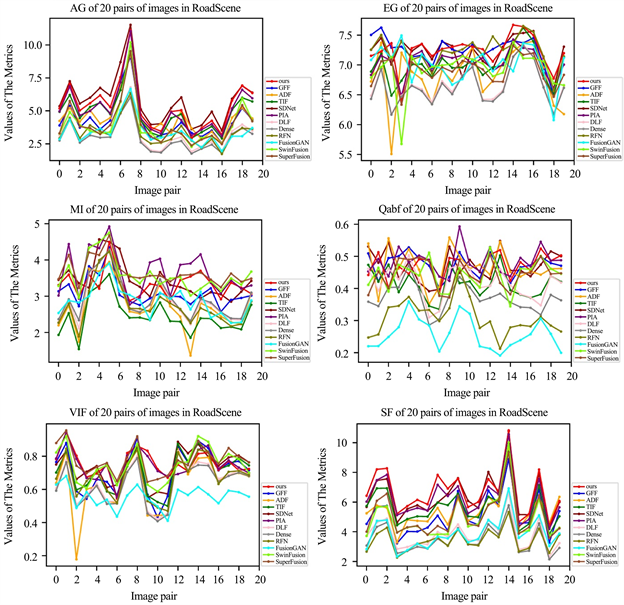 注:在RoadScreen数据集中使用EN,AG,Qabf,VIF,MI中的6个指标和11种高级算法选择了20个图像对。水平坐标是图像编号,垂直坐标是图像的评价指标值。
注:在RoadScreen数据集中使用EN,AG,Qabf,VIF,MI中的6个指标和11种高级算法选择了20个图像对。水平坐标是图像编号,垂直坐标是图像的评价指标值。
Figure 7. Quantitative comparison of six indicators
图7. 6个指标的定量比较
6. 结论
1) 在本文中,我们提出了一种具有区域照明保留的多级多模态特征融合网络,缩写为MLFFusion。首先,针对骨干网络设计SAconv模块,提高网络的特征提取能力。
2) 设计MLFF模块对不同层次、不同模式的信息进行整合,提高融合网络的信息集成能力。
3) 设计区域照度保持模块将结果与优良的照度信息融合,大大提高了融合算法在低照度地面恶劣环境下的鲁棒性。大量的实验证明了该算法的优越性。此外,该文算法在多模态目标检测任务中显示出巨大的潜力。