1. 引言
在当代信息时代,数据的快速增长和复杂性给决策过程带来了巨大挑战。面对庞大、多样化的数据集,基于粗糙集理论 [1] 的传统的经典决策系统可能无法满足需求。因此,不完备决策系统 [2] [3] 成为了处理复杂决策问题的有效工具。不完备决策系统基于一种基本假设,即我们所拥有的信息并不完整,因此需要从有限的信息中进行决策。通过考虑不完整性和不确定性,不完备决策系统能够在实践中更好地适应真实世界的复杂性。
不完备决策系统的发展已经取得了显著的进展。研究者们提出了许多创新的方法和算法,用于有效地处理缺失数据 [4] [5] 、模糊信息 [6] [7] 、优势关系 [8] [9] 等问题。这些方法和算法使得不完备决策系统能够更好地应对现实中的不确定性,并提供可靠的决策支持。此外,随着机器学习、人工智能等领域的快速发展,不完备决策系统正逐渐融合这些技术,为决策制定者提供更准确、可靠的决策建议。
通过深入研究和分析,利用不完备决策系统解决现实世界中的复杂决策问题,寻找对应确定性的规则是一个重要的目标。在不完备决策系统中寻找确定性的规则,必须通过相容类的计算,而相容类的效率问题一直阻碍者确定性规则的提取速度。本文通过不完备决策系统的中容差类的单调性以及对正域的分析,提出了一种在不完备系统下快速寻找正域(确定性规则)的算法,经过实验证明本文所提算法的有效性以及稳定性。
2. 基本概念
不完备决策系统
由于数据采集或数据损坏等原因导致决策系统部分信息缺失,则称此类决策系统为不完备决策系统,本节将主要介绍不完备决策系统下的粗糙集理论相关概念,包括不完备决策系统、相容关系、上近似集、下近似集、正域、边界域和负域等相关概念。
定义1 [10] 在给定信息系统
中,其中
表示非空有限对象的集合,称之为论域;AT表示属性的非空有限集合;
,其中
表示属性
的值域;
是信息函数,
表示对象
在属性
上的值,简称
。
在信息系统IS中,若
,则该信息系统被称为决策系统,记作
,其中C表示非空有限的条件属性的集合,D表示非空有限的决策属性的集合。
定义2 [10] 在决策系统
中,若存在
使得
含有缺失值,且缺失值使用
表示,则该决策系统被称为不完备决策系统,记作
,其中决策属性
的值域
中均不含有缺失值。
定义3 [10] 在不完备决策系统
下,对于
,存在相容关系:
(1)
设
,其中
表示通过条件属性集合
与样本x不可区分的对象的集合,
也被称为相容类。因此,可以导出论域U在属性子集
上的覆盖
。
性质 1不完备决策系统
中,对于
,有:
(2)
同时相容关系
满足:
1) 自反性:对
,有
。
2) 对称性:对
,若
,则
。
定义4 [11] 在不完备决策系统
中,对于
,
,对于X关于
的下、上近似定义如下:
(3)
(4)
且正域表示为
,边界域表示为
,负域为
。
定义5 [11] 在不完备决策系统
中,假设论域U对决策属性D上的划分为
,对于
,决策类集合U/D关于条件属性集合
的下、上近似
定义如下:
(5)
(6)
决策类集合U/D关于条件属性
的正域以及边界域定义为:
(7)
(8)
基于上述定理,表1给出不完备决策系统下的正域计算算法(Positive domain computational algorithms in incomplete decision systems, PDCA-IDS)。

Table 1. Positive domain computational algorithms in incomplete decision systems (PDCA-IDS)
表1. 不完备决策系统下的正域计算算法(PDCA-IDS)
上述传统的计算正域的时间复杂度为
,其中m为条件属性的个数(即
),n为样本对象的个数。时间复杂度较高,效率低下。
3. 基于不完备决策系统的正域快速算法
由于数据量的增大,数据的维度和规模都是对不完备信息数据进行相容类的划分时的一个考验。常规的容差类的划分时间复杂度高、效率低下,本小节主要介绍相容类的单调性、对正域的分析以及正域快速算法的构建。
3.1. 相容类的快速计算
定理1 [12] 给定一个不完备决策系统
,X1和X2是C的两个属性子集,其中
,对于
,
。
定理1说明在当属性子集越大时,对任意样本对象
来说所含有的与其保持一致的样本对象越少,即对于任意的样本对象
在较大的属性子集下的相容类可以通过较小的属性子集的相容类得出。
Table 2. Fast positive domain computing algorithms for incomplete decision systems (FPDCA-IDS)
表2. 不完备决策系统下快速正域计算算法(FPDCA-IDS)
3.2. 正域的快速计算
定理2 [13] 给定一个不完备决策系统
,X1和X2是C的两个属性子集,其中
,可以得到
。
定理3 [13] 给定一个不完备决策系统
,X1和X2是C的两个属性子集,其中
,对于
,
,那么
。
定理2和定理3表明在当任意一个对象属于较小属性子集的正域时,则必属于包含整个较小属性子集的较大属性子集的正域。
基于上述定理,表2给出不完备决策系统下快速正域计算算法(Fast Positive Domain Computing Algorithms inIncomplete Decision Systems, FPDCA-IDS)。
4. 实验分析
本实验选取八组UCI数据集进行求取正域效率对比,详细信息如表3所示。在验证算法有效性之前,使用WEKA3.8对数据集进行离散化预处理。本节进行的所有的实验都是在一台带有MacOS13.4 Ventura、8核、M1芯片和16GB内存的笔记本电脑上进行。算法在Pycharm2023开发工具是使用Python编写,实验图使用Python绘制。
4.1. 纬度效率验证
如图1所示为本文所提算法FPDCA-IDS与经典求取正域的算法PDCA-IDS在不完备决策系统下改变数据集的维度时(即改变属性个数的多少时)算法的执行时间曲线。红色球形折线为本文提出的算法FPDCA-IDS,蓝色三角折线为传统的计算正域的方法PDCA-IDS。横坐标为属性的个数,纵坐标为运行所需要的时间单位为秒。
从图1中可以看出,当数据集的属性个数都较少时算法的效率差别不大。当随着属性的个数逐渐增加时,两种算法的执行时间均有上升,但是FPDCA-IDS算法的折线始终保持在PDCA-IDS算法折线的下方,也就是FPDCA-IDS算法一直保持较好的效率。尤其是当属性的个数不断增加时,两种算法直接的差距更为明显,本文提出的算法优势更大。并且本文提出的算法随着属性个数的增加变化比较均匀,稳定性更好。因此,相对来说可以证明本文提出的算法更加适用于维度较高的数据集。
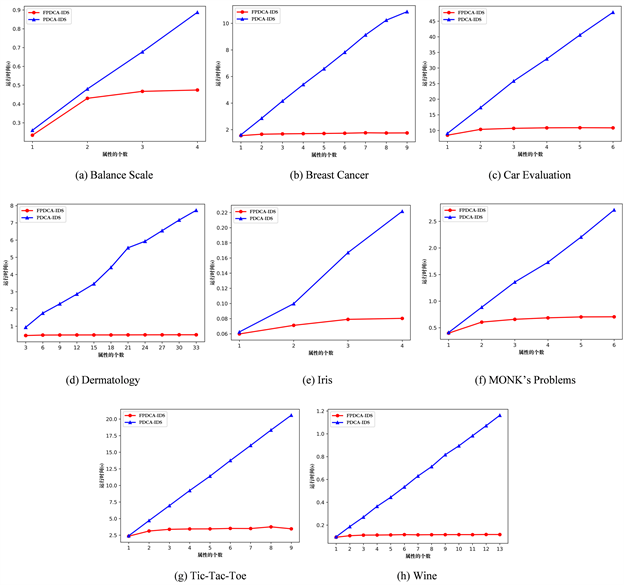
Figure 1. Comparison of efficiency in longitude
图1. 维度下的效率对比
4.2. 规模效率验证
如图2所示为本文所提算法FPDCA-IDS与经典求取正域的算法PDCA-IDS在不完备决策系统下改变数据集的规模时(即改变样本对象个数的时)算法的执行时间曲线。红色球形折线为本文提出的算法FPDCA-IDS,蓝色三角折线为传统的计算正域的方法PDCA-IDS。横坐标为样本对象的比例,纵坐标为运行所需要的时间单位为秒。
从图2中可以看出,当数据集的样本对象个数较少时算法的效率差别不大。当随着属性的个数逐渐增加时,两种算法的执行时间均有上升,但是本文提出的算法随着样本对象比例的增加变化比较均匀,稳定性更好。本文提出的FPDCA-IDS算法的折线始终保持在PDCA-IDS算法折线的下方,也就是FPDCA-IDS算法一直保持较好的效率。当样本对象比例较高时,两种算法直接的差距更为的明显,本文提出的算法优势更大。因此,相对来说可以证明本文提出的算法更加适用于大规模的数据集。
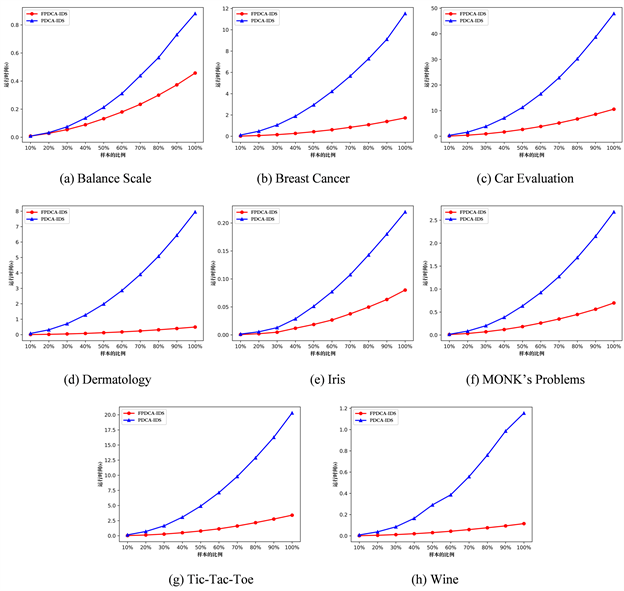
Figure 2. Comparison of efficiency in magnitude
图2. 规模下的效率对比
5. 结论
在本文中,首先通过分析相容类的单调性以及正域在属性集合下的规律,进一步提出了一种时间复杂度较低的计算相容类和正域的算法。本文所提算法FPDCA-IDS与传统的计算正域的算法PDCA-IDS思想相比,减少了多次迭代次数和属性值的比较次数,能够有效的避免了时间复杂度过高的问题,可以大幅度提高算法的计算效率。本文最后通过选取的八组UCI数据集上进行算法有效性验证。从实验结果可以看出,本文所提算法相比于传统的计算正域的算法效率较高并且更加的稳定,尤其是更适用于大规模数据集以及维度较高的数据集。
基金项目
本文受烟台市科技计划项目(编号:2022XDRH016)的资助。
参考文献