1. 引言
确定鲍鱼的年龄是一项繁杂又耗时的任务,要先通过锥体切掉其石灰质的外壳,然后进行染色,再利用显微镜观察,记录后计算环数,最后确定年龄。为了避免这样繁杂又耗时的任务,发展了一种更为简便且快速的确定年龄的方法,即通过物理测量来确定鲍鱼的年龄。本文正是基于物理测量的数据结果,建立合适的模型,从而预测鲍鱼的年龄。
2. 理论知识
2.1. 多元线性回归
2.1.1. 总体模型
随机变量y与变量
的线性回归模型 [1] 为:
(2.1)
其中,
是p + 1个未知参数,β0是回归常数,
是回归系数,均为待估参数,ε是随机误差,一般假定ε~N(0, σ2)。
2.1.2. 样本模型
若有n组观测数据
,则(2.1)式可以表示为:
(2.2)
写成矩阵的形式为:
(2.3)
其中,
(2.4)
其中,X是一个n × (p + 1)阶矩阵,称为回归设计矩阵或资料矩阵。
2.1.3. 参数估计
多元线性回归方程的待估参数
根据最小二乘法求得,即寻找参数
的估计值
,使离差平方和:
(2.5)
达到极小,亦即寻找
,使得:
(2.6)
根据(2.6)求出的
就是回归参数
的最小二乘估计。
2.2. 逻辑回归
2.2.1. 单变量模型
单变量X的逻辑回归模型 [2] 为:
(2.7)
也可以写成:
(2.8)
其中,β0、β1是两个未知参数,β0是逻辑回归常数,β1是逻辑回归系数,均为待估参数。
2.2.2. 多变量模型
多变量
的逻辑回归模型为:
(2.9)
也可以写成:
(2.10)
其中,
是p + 1个未知参数,β0是逻辑回归常数,
是逻辑回归系数,均为待估参数。
2.2.3. 参数估计
以单变量模型为例,若有n组观测数据
,待估参数β0、β1的对数似然函数为:
(2.11)
对β0、β1求偏导:
(2.12)
其中,β = (β0,β1),
,
,
。
再令(2.12)式等于0,则解得β的最大似然估计。
2.3. 岭回归
当变量间出现多重共线性问题时,普通最小二乘法效果明显变差,针对这种情形,霍尔在1962年首先提出了一种改进最小二乘估计的方法,即岭估计。
当自变量间存在多重共线性,即|X'X| ≈ 0时,设想给X'X加上一个正定矩阵ki (k > 0),那么X'X + kI接近奇异的程度就会比X'X接近奇异的程度小得多 [3] 。考虑到变量量纲不一的问题,将数据标准化,则β的岭回归估计为:
(2.13)
其中,k为岭系数。当k = 0时的岭回归估计β(0)就是普通最小二乘估计。β(k)作为β的估计比最小二乘估计β稳定。
2.4. LASSO回归
在原理上,LASSO回归与岭回归的思想相类似,但惩罚项不是系数的平方而是其绝对值 [4] ,即在约束条件
下,需要满足以下条件:
(2.14)
由于惩罚项取绝对值,LASSO回归不像岭回归那样压缩系数,而是将系数归为0,达到变量选择的功效。
2.5. 主成分分析
2.5.1. 总体模型
变量
的主成分为:
(2.15)
其中,
为载荷向量,Z为主成分的得分矩阵。
2.5.2. 样本模型
若有n组观测数据
,则(2.15)式可以表示为:
(2.16)
优化 [5] :
(2.17)
2.5.3. 方差贡献率
第k个主成分的方差贡献率为:
(2.18)
第m个主成分的累积方差贡献率为:
(2.19)
3. 实证分析
3.1. 数据说明与处理
3.1.1. 数据说明
本文选取的数据为UCI库的Abalone数据集 [6] ,共有4177个样本,9个变量(表1)。其中,通过锥体切壳、染色并利用显微镜观察,计算环数,从而确定鲍鱼的年龄。
3.1.2. 数据预处理
1) 变量转化
数据集中的Sex变量为定性变量,为便于后续建立模型,将其转化为虚拟变量(表2)。
2) 数据划分
将数据划分为训练集和测试集,前3133个样本为训练集,后1044个样本为测试集。
3.2. 描述分析
3.2.1. 数据概况
表3展示了数据中9个变量的基本情况,其中Sex变量为定性变量,表明鲍鱼的性别,由图1可知,鲍鱼中雄性占36.6%,雌性占31.3%,婴儿占32.1%;Rings变量为鲍鱼的环数,指代鲍鱼的年龄,由图2可知,鲍鱼环数从1到9的频数逐渐增加,至环数为9时最多,之后又逐渐减少;其余7个变量的最小值、最大值、均值与四分位数均列于表中。
3.2.2. 变量相关阵
由于Sex变量为定性变量,所以除去该变量后,再计算剩余8个变量的相关矩阵(表4),再绘制变量的相关矩阵图(图3)。

Table 4. Variable correlation matrix
表4. 变量相关阵
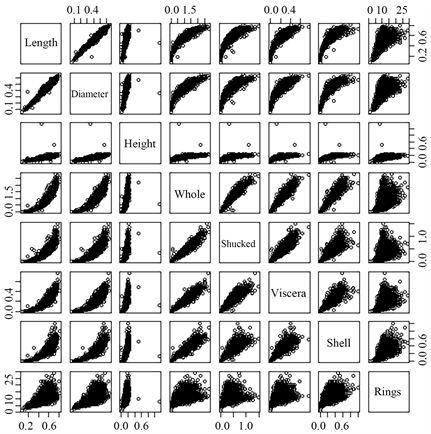
Figure 3. Plot of two-by-two variable correlation matrix
图3. 两两变量相关矩阵图
3.2.3. 箱线图
单独绘制Sex变量与其它8个变量的箱线图(图4)
3.3. 回归模型分析
将Sex变量转化为虚拟变量后,以Rings变量为响应变量,基于训练集数据分别进行线性回归、泊松回归、岭回归及LASSO回归,然后利用所建模型,基于测试集数据分别对Rings的值进行预测,最后计算各模型在预测方面的均方误差。
3.3.1. 线性回归
由表5可知,SexM变量与Length变量不显著,其余变量均在99.9%的置信水平下显著,表明鲍鱼的年龄受性别及其外壳长度的影响较低。模型的平均绝对误差MAE为1.5936,均方误差MSE为4.5215,对称平均绝对百分比误差SMAPE为0.1551,但可决系数为0.5429,较小,说明模型拟合程度并不理想。
Table 5. Regression coefficients for the four regression models
表5. 四个回归模型的回归系数
注:星号代表显著性水平,*、**、***分别代表在10%、5%、1%水平下显著。
3.3.2. 泊松回归
由表5可知,变量的显著性检验结果与线性回归的结果相差不大,除了Shell变量是在99%的置信水平下显著的。模型的平均绝对误差MAE为1.6242,均方误差MSE为4.7472,对称平均绝对百分比误差SMAPE为0.1582,但AIC值为14255,较大,说明模型拟合程度并不理想。
3.3.3. 岭回归
为了有效避免数据的过拟合问题,在建立岭回归模型时采用了十折交叉验证法。首先,通过十组子样本的交叉验证,绘制回归系数及模型均方误差随岭系数λ变化的系数变化图(图5左上)和均方误差变化图(图5右上)。其次,依据均方误差MSE最小原则,选择最优的岭系数λ,为0.2076。最后,采用最优岭系数进行预测,并计算出模型的平均绝对误差、均方误差、对称平均绝对百分比误差,分别为1.6324、4.8270、0.1586。
3.3.4. LASSO回归
与岭回归相似,也采用十折交叉验证法进行LASSO回归。首先,通过十组子样本的交叉验证,绘制回归系数及模型均方误差随惩罚因子λ变化的系数变化图(图5左下)和均方误差变化图(图5右下)。其次,依据均方误差MSE最小原则,选择最优的惩罚因子λ,为0.0018。最后,采用最优惩罚因子进行预测,并计算出模型的平均绝对误差、均方误差、对称平均绝对百分比误差,分别为1.5928、4.5194、0.1551。
3.3.5. 模型比较
由表6可知,LASSO回归模型的MAE、MSE和SMAPE最小,岭回归模型的MAE、MSE和SMAPE最大。再对比表5中岭回归与LASSO回归的系数,可以发现LASSO回归模型中有四个变量的系数为0,这是因为LASSO具有执行变量选择的功效,从而让模型变得更容易解释。所以,即使与岭回归一样,当最小二乘估计方差过高,可以减少以偏差小幅增加为代价的方差,LASSO回归的表现要比岭回归的表现更好。
3.4. 降维
由变量相关阵(表4)与相关矩阵图(图3)可知,变量间相关系数较高,可能存在多重共线性问题,所以考虑先对数据进行降维,再建立模型。本文采用偏最小二乘及主成分分析两种降维方法对模型进行优化。在建模前,先对数据进行标准化处理,避免模型结果受方差影响。
Table 6. MSE of the regression model
表6. 回归模型的MSE

Figure 5. Plot of coefficient changes and MSE changes of ridge regression and LASSO regression
图5. 岭回归、LASSO回归的系数变化与MSE变化图
3.4.1. 偏最小二乘回归
由表7可知,前三个主成分的累积方差贡献率有89.11%,但前两个主成分的累积方差贡献率已达79.36%,接近80%,所以可以考虑主成分个数为2或3两种情况 [7] [8] 。当采用2个主成分时,MSE为5.0441,而当采用3个主成分时,MSE为4.8048。所以,应选前三个主成分进行建模,系数如表8所示。
3.4.2. 主成分回归
由表9可知,前两个主成分的特征值都大于1,且其累积方差贡献率有88.4%,再根据碎石图(图6)可知,当主成分个数大于等于3时,线的走势变平缓,可以确定选取前两个主成分进行建模 [9] [10] ,系数如表8所示,MSE为6.4085。
Table 8. Regression coefficients of the model after dimensionality reduction
表8. 降维后模型的回归系数
Table 9. Principal component variance contribution ratio
表9. 主成分方差贡献率

Figure 7. Plot of MSEP, RMSEP and R2 changes for partial least squares regression
图7. 偏最小二乘回归的MSEP、RMSEP与R2变化图
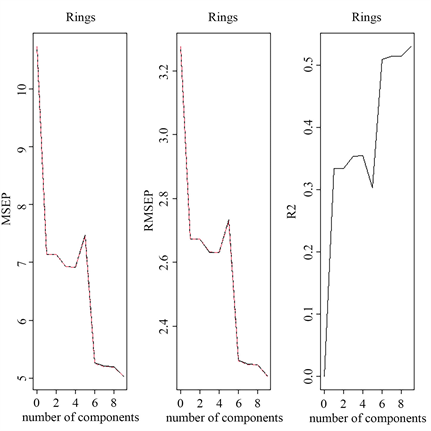
Figure 8. Plot of MSEP, RMSEP and R2 changes for principle component regression
图8. 主成分回归的MSEP、RMSEP与R2变化图
3.4.3. 模型比较
对比偏最小二乘回归模型与主成分回归模型的MSE,偏最小二乘回归模型的MSE更小,为4.8048,所以偏最小二乘法比主成分分析法表现更优。但是通过对比降维后与降维前模型的MSE,发现降维后模型的MSE要比降维前的更大,说明降维并没有显著优化模型,反而表现欠佳。有两点原因:一为降维后模型的可决系数(图7与图8)甚至不如线性回归模型的好;二为不论是偏最小二乘回归模型的载荷矩阵(表10),还是主成分回归的得分矩阵(表11),都难以解释 [11] 。
4. 结论
本文基于UCI库的Abalone数据集,共4177个样本,将其划分为3133个样本的训练集和1044个样本的测试集,利用训练集样本建立线性回归、逻辑回归、岭回归、LASSO回归模型,再利用测试集样本分别预测鲍鱼的年龄,最后通过模型评价指标平均绝对误差MAE、均方误差MSE和对称平均绝对百分比误差SMAPE来判断模型优劣,对应的值越小,模型越好。实证分析结果表明,LASSO回归模型的MAE、MSE和SMAPE最小,分别为1.5928、4.5194和0.1551,岭回归模型的MAE、MSE和SMAPE最大,分别为1.6324、4.8270和0.1586。原因是LASSO具有执行变量选择的功效,即使与岭回归一样,当最小二乘估计方差过高,可以减少以偏差小幅增加为代价的方差,LASSO回归的表现要比岭回归的表现更好。
结合变量相关阵及相关矩阵图,发现变量间相关性强,有多重共线性存在的可能,为了避免多重共线性对模型评价产生影响,本文采取了两种降维方法,即偏最小二乘法和主成分分析法,以期通过降维再进行回归来消除多重共线性对模型产生的影响。结果表明,即使比主成分回归模型表现更好的偏最小二乘回归模型的均方误差MSE都较大,为4.8048,而主成分回归模型的MSE甚至高达6.4085,两种方法都未达到预期效果。