1. 引言
图嵌入是一种处理社交网络 [1] 、软件网络 [2] 和PPI网络 [3] 等网络的方法,其目的是将图的每个节点或整个图(子图)映射到一个低维的向量空间,同时还能尽可能的保留图中重要的信息。图嵌入已被应用到节点分类 [4] 、链路预测 [5] 、图聚类 [6] 和社区检测 [7] 等下游任务中,并且已经取得了相对显著的效果。
典型的图嵌入模型有局部线性嵌入 [8] 、拉普拉斯嵌入 [9] 和柯西图嵌入 [10] 等,但是这些方法都是对矩阵进行因式分解,并不能很好的反映图中节点之间的局部性质。基于神经网络的方法 [11] [12] 通过应用神经网络聚合邻居节点的信息得到节点的向量表示。目前也存在许多基于随机游走的图嵌入模型,DeepWalk模型主要是借鉴了自然语言处理模型(NLP) [13] 的思想,使用特定的游走策略提取图的节点序列,然后利用Skip-Gram模型处理节点序列库。上述几种方法主要从单一角度考虑节点间的转移概率,精确性有待提高。
在图挖掘领域中,图中每个节点和边的信息都起着至关重要的作用。利用随机游走采样图中的节点序列可以帮助我们捕获图中节点和边之间的微小结构信息,通过迭代的方式可以捕获图中更多潜在的信息。在图1中,如果采用无偏随机游走策略,图G中每个节点到它的邻居节点的概率是相同的,意味着无法区分每个节点的邻居节点的重要程度。真实的图中各个节点之间的存在某些联系,如果忽略这些联系,会破坏原始图的结构信息,使得嵌入结果不佳。因此在进行图嵌入时,融合节点和边的信息的随机游走策略对于提高嵌入向量的精度具有十分重要的意义。
针对以上问题,本文提出了一种基于引力作用融合节点和边的信息的图嵌入模型(GRGE),以更好的捕获图的局部拓扑信息。具体而言,就是输入一个无向无权图,利用本文提出的度信息驱动的引力随机游走策略生成节点序列,输入Skip-Gram模型 [13] 生成节点表示向量。GRGE模型无缝融合了图的节点和边的信息,得到了较优的节点表示。
2. 相关工作
图嵌入技术受到越来越多的关注,同时也产生了许多基于随机游走的图嵌入模型。基于随机游走的图嵌入模型主要有DeepWalk [14] 、Node2Vec [15] 、WalkLets [16] 、HARP [17] 、HALK [18] 、GEBRWR [19] 和ProbWalk [20] 等。其中DeepWalk模型是基于Word2Vec模型 [13] 提出的学习图节点表示的方法,主要思想是利用随机游走算法生成图节点的语料库,通过Skip-Gram模型最大化节点序列中窗口范围内节点的共现概率,将节点映射到嵌入向量空间。Node2Vec模型针对DeepWalk模型的游走策略进行了改进,引入一个有偏的随机游走过程,综合考虑了深度优先搜索策略和广度优先搜索策略,在同质性和结构性之间权衡,最终提高了嵌入向量的精度。WalkLets模型设计了一种跳过图中部分节点的随机游走策略,利用该策略生成节点序列输入DeepWalk的模型中进行训练。HARP模型通过压缩原始图避免局部最优解。HALK模型通过在随机游走中删除一定比例的最不频繁节点,实现更远节点之间的随机游走。GEBRWR模型通过应用适当的图嵌入方法,获得节点信息的表示向量,利用余弦相似性构建了一种节点相似性指标,通过该指标重新构建节点概率转移矩阵,提高了GEBRWR模型的精度。针对加权图,ProbWalk模型将边的权重转化成节点间的转移概率,然后进行节点嵌入。
ProbWalk模型主要是将边的权重转换为节点间的转移概率,并没有考虑图中节点对于转移概率的影响,而DeepWalk模型和Node2Vec模型均是针对拓扑结构的改进。因此本文考虑利用万有引力融合图中节点和边的信息。从而可以更好的反映图中边和点的信息对于节点间转移概率的影响,重新定义节点间概率转移矩阵。
3. 预备知识
该部分,我们首先给出相关符号及其含义,如表1所示,详细格式请参考相关文献 [11] [21] [22] 。
定义1 (节点嵌入)已知图G,任意
,给定一个映射
,其中d1为嵌入向量空间的维数。该映射表示将集合V中任意一个节点映射到一个d1维向量空间,同时映射f能够保留图G中节点的局部与全局性质。如图2所示:
定义2 (引力有偏函数)给定图
,对于节点
和
,设
和
表示节点
和
的度,
是节点
和
之间的最短距离,则
(1)
为节点
和
之间的引力函数,其中k表示引力系数。
定义3 (随机游走)给定图
,规定游走的初始节点为
,游走者从节点
开始,随机选择图G中
的邻居节点
作为游走目标,到达
后再以
为起始节点,重新选择
的邻居节点
作为游走目标,依此类推。行走者所经过的节点集合构成了一个随机游走
。
4. GRGE模型
本节将详细介绍GRGE模型,模型的整体框架由生成节点序列、Skip-Gram算法嵌入两部分组成。模型的整体流程如下所示:a) 利用度信息驱动的引力随机游走策略生成节点序列;b) 将生成的节点序列输入Skip-Gram算法;c) 输出节点的表示向量。
4.1. 度信息驱动的引力随机游走策略
通过分析不难发现,DeepWalk算法采用无偏随机函数采样节点序列,虽然这种策略降低了随机游走采样节点序列的时间复杂度,但是由于图都是从现实世界中抽象出来的,所以图的节点之间往往存在某种倾向,这就意味着该算法并不能有效的反映图中节点之间的内在联系。如图3所示:
节点Valjean选择下一个节点的概率并不是随机的,它和节点Cosette之间的关系更为紧密。因此,采用随机函数采样节点序列会丢失相应的信息。因此,如果不考虑图中节点之间的倾向性,会破坏原始图的结构,得到的节点表示向量的精度也会不佳,并且会忽略节点本身所具有的信息,从而引入噪声的影响。因此,为了计算的方便,我们将节点间的“距离”的倒数视作节点之间的权重,权重越大,节点间“越短”,节点间作用越大。同时为了计算方便,我们将节点间的“距离”设置为1。于是,我们本节提出了一种新的度信息驱动的引力随机游走策略,该策略首先计算图中节点的度信息:在图的研究中,节点的度信息有重要的意义。一方面,它可以帮助我们理解图的结构和组织方式。例如,一些图具有幂律度分布,这意味着图中有许多节点具有相对较少的边,而少数节点具有大量的边。这种类型的图被称为“无标度网络”(Scale-Free Network)。另一方面,它还可以影响图中的动态行为,如信息传播、疾病传播或同步振荡等。在一个无向无权图中,节点的度信息可以简单地定义为与该节点相连接的边的数量。同样的,在随机游走采样策略中,节点的度信息也扮演着十分重要的作用,度信息越大的节点往往包含着更多重要的信息。如图4所示。
节点3的度为5,节点1的度为1,节点2和4的度为2,节点5和6的度为3。观察图4,我们会发现节点3在整个图中扮演着十分重要的角色,从除节点3以外的其他节点出发且长度为3的路径几乎都会经过节点3。同样的,删除节点3对于图G造成的影响也是最大的。
构建度信息驱动的引力随机游走策略:我们通过引力有偏函数定义了图中节点之间的引力作用公式则节点
和
之间的引力作用为
(2)
其中为了计算简便,我们将k值设为1。然后构建图中节点的引力作用矩阵。因此,图4中的图G中节点的引力作用矩阵为
如图5所示:采用度信息驱动的引力随机游走策略可以得到1-2-4-8、3-2-4-8和5-4-8-4等序列。
4.2. GRGE模型
GRGE模型主要包含两个部分,Biased-Walk算法和Skip-Gram算法。其中Biased-Walk算法用来计算节点间的引力作用值,Skip-Gram算法用来计算节点的表示向量。
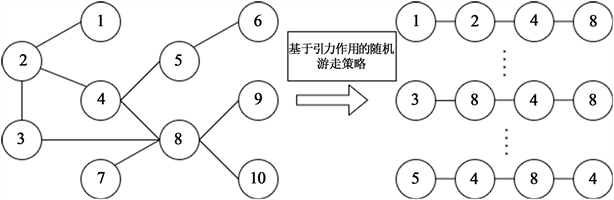
Figure 5. Schematic diagram of gravity random walk strategy driven by degree information
图5. 信息驱动的引力随机游走策略示意图
算法1描述:Biased-Walk算法针对的是图的一阶邻居,其中的for循环的意义是选取引力作用值最大的那个节点,算法1中的第5行表示输出引力作用值最大的节点的索引值。按照图论中的定义,该函数中的引力作用函数的分母(两个节点之间的距离)设定为1。
算法2描述:算法2使用哈夫曼算法改进自然语言处理的Skip-Gram算法的目标函数,利用随机梯度下降法对目标函数进行优化。该算法的细节如下所示:第3~8行:外层for循环表示遍历给定节点
的随机游动序列中的每个节点。内层for循环表示以随机游动序列的每个节点为目标,目标节点前后的
个节点与目标节点相结合。具体操作模式是使用随机梯度下降算法更新节点的初始向量矩阵。
算法3描述:第6步的作用:利用Biased-Walk算法筛选出随机游走序列,第7步我们采用自然语言处理模型中的Skip-Gram算法计算节点的向量表示。
5. 实验分析
我们使用Log-Linear算法中应用的One-Vs-Rest逻辑回归来为图中的节点做标记。然后选择任意百分比的标记节点作为训练数据,剩余百分比的节点作为测试数据。在本实验中,数据集的训练率分别设置为10%、20%、30%、40%、50%、60%、70%和80%,基准算法的节点表示向量的维度设置为60维。
5.1. 实验环境及参数
本次实验中,针对表3给定的五个数据集,采取10次重复实验结果的平均值,所有的实验结果均是在表2描述的实验环境及实验参数中计算所得。

Table 2. Experimental environment and experimental parameters
表2. 实验环境及参数
5.2. 基准算法
DeepWalk模型是最早提出的基于Word2vec的节点向量化模型。其主要思路,就是利用构造节点在网络上的随机游走路径,来模仿文本生成的过程,提供一个节点序列,然后用Skip-Gram和Hierarchical-SoftMax模型对随机游走序列中每个局部窗口内的节点对进行概率建模,最大化随机游走序列的似然概率,并使用最终随机梯度下降学习参数。
Struc2vec模型的主要思想是如果两个节点在一个网络中拥有更多相似的结构,它们应该具有更高的相似度。其基本思想可分为四个步骤:第一步,学习每对节点之间的结构相似性;第二步,构造加权多层网络;第三步,使用多层网络为每个节点生成一个节点序列;第四步,利用Skip-Gram模型学习节点的特征表示。
BRWW模型的主要内容是利用节点嵌入向量的余弦相似性构造有偏随机游走策略,并利用Skip-Gram模型输出节点表示向量。
5.3. 实验数据
本实验中,我们采用Dolphins1、Polbooks2、Brazil3、Europe4和PB5 (political blogs的最大连通子图)等5个数据集。其中Brazil、Europe和PB都是有向图,由于GRGE模型并不关注图中节点之间的方向性,于是在GRGE模型去除有向图的方向性,视作无向图处理。具体信息见表3所示。
为了验证GRGE模型的有效性,5.4节分别在节点分类任务上将GRGE模型与三种模型在表3中的五个数据集中进行比较。
5.4. 评价指标
为了评估GRGE模型在图中的效果,我们采用F1分数 [23] 评估节点分类任务。这些指标的定义如下:
在多标签分类任务中,
表示所有标签的F1分数。公式如下:
(3)
其中
表示标签i的分数,L表示标签的集合。
计算所有类别的总的精确度和召回率全局计算F1分数。其定义如下:
(4)
其中P和R分别是针对所有标签求得的精确度和召回率。
、
和
分别表示在基本真值或预测中与标签i相关联的实例中的真阳性、假阳性和假阴性的数量。
5.5. 实验结果分析
本次实验主要针对表3的5个数据集在节点分类任务进行对比实验。
多标签分类结果分析
在图6中,除个别训练比例,GRGE模型的Micro-F1值和Macro-F1值均优于DeepWalk模型、Struc2vec模型和BRWW模型。这说明GRGE模型的标签分类能力强于这三种算法。其原因可能是较高的平均度增加了GRGE模型的标签分类能力。
在图7和图8中,相比于DeepWalk模型和BRWW模型,虽然Europe数据集和PB数据集的节点集和边集的规模相对较大,但是GRGE模型的标签分类能力仍有微弱的提升。这可以说明相比于基准算法,GRGE模型在面对较大规模数据集时仍然可以保持一定的优势。
在图9中,我们发现GRGE模型对于数据集有较大的依赖性。但是GRGE模型的标签分类能力仍旧强于DeepWalk模型。
在图10中,随着训练比例的提升,由于Dolphins数据集的节点集和边集的数量较小,所以GRGE模型的标签分类能力强于DeepWalk模型和Struc2vec模型。而由于Dolphins数据集的直径相对较大,所以GRGE模型的标签分类能力弱于BRWW模型。

Figure 6. Experimental results of Brazil dataset
图6. Brazil数据集实验结果
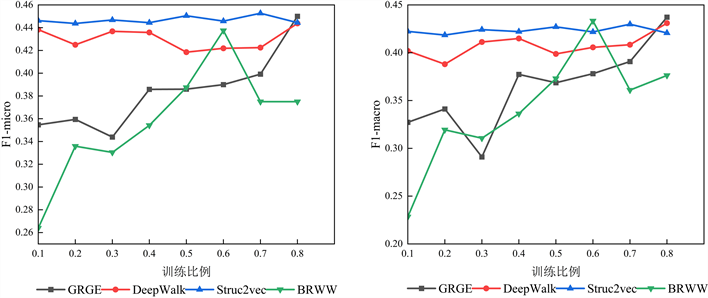
Figure 7. Experimental results of Europe dataset
图7. Europe数据集实验结果
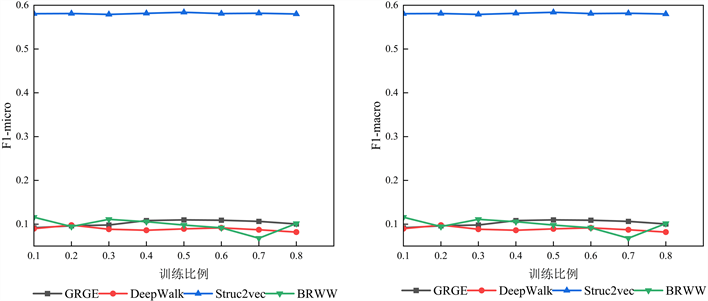
Figure 8. Experimental results of PB dataset
图8. PB数据集实验结果
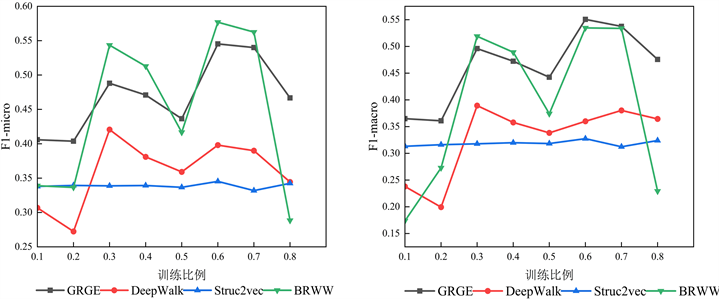
Figure 9. Experimental results of Polbooks dataset
图9. Polbooks数据集实验结果
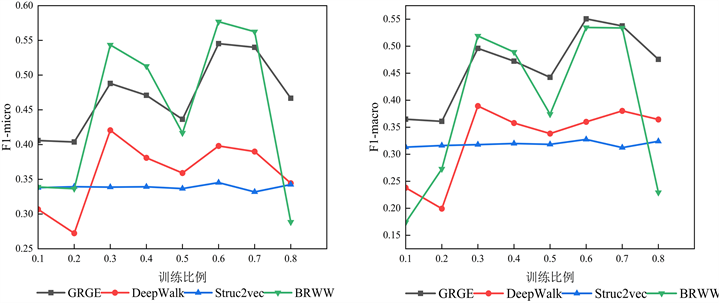
Figure 10. Experimental results of Dolphin dataset
图10. Dolphin数据集实验结果
GRGE模型旨在利用引力作用融合节点和边的信息改进随机游走策略来量化节点间的联系,从物理学的角度将图中节点联系在一起,从而提升节点嵌入向量的精度。GRGE模型的时间复杂度为“O(N
) + O(N) + O(Nlog(N))”。虽然GRGE模型的时间复杂度高于DeepWalk模型的时间复杂度,但是GRGE模型可以更好的反映节点间的关系,一定程度上可以弥补时间复杂度较高对于该模型的影响。
6. 结论
针对无向图,我们提出了一种新的随机游走策略,结合Skip-Gram算法得到GRGE模型。同时我们的方法量化了图中节点之间的倾向性,使得GRGE模型能更好的应用于现实世界中的图。在多个不同的数据集的实验表明了我们的模型在节点分类任务中的有效性。由于实验条件的限制,目前无法在超大型图上实验该模型。
由于现实世界的图中包含着丰富的属性信息和结构信息,因此未来的工作将针对属性图展开研究,侧重于融合节点间的互信息和属性信息到引力作用策略中,提高嵌入的精度,降低算法的时间复杂度。
NOTES
*通讯作者。
1http://www-personal.umich.edu/~mejn/netdata/。
2https://www.cc.gatech.edu/dimacs10/archive/clustering.shtml。
3http://www.anac.gov.br/。
4http://ec.europa.eu/。
5https://www.cc.gatech.edu/dimacs10/archive/clustering.shtml。