1. 引言
语义分割作为计算机视觉中的一个重要分支,通过为每个像素进行密集的预测推断标签来实现细粒度推理,从而实现图像像素级的分类。语义分割任务就是从低层语义向高层语义推理的过程。目前语义分割在现实生活,如自主驱动 [1] [2] [3] ,人机交互 [4] ,计算摄影 [5] ,图像搜索引擎 [6] 以及增强现实技术等 [7] 具有广泛的应用。
在图像处理的早期,传统图像分割方式包括基于阈值的图像分割方法、基于边缘的图像分割方法 [8] [9] [10] 、基于区域的图像分割方法 [11] [12] [13] 、基于聚类的图像分割方法 [14] [15] [16] 和基于图论的图像分割方法 [17] [18] [19] 。这些传统图像分割方法大多数是利用图像的表层信息进行分析处理,因此对于需要“处理”大量语义信息的图像分割任务并不适用。而基于小波变换的图像分割技术具有较强的抗噪声性能,并且能够有效地保留边缘信息,以达到分割的目的。
随着深度学习技术的不断发展,涌现出了大量基于深度学习的高效语义分割方法。其中Long等人首次将卷积神经网络(CNN)的全连接改为卷积操作,得到全卷积神经网络(FCN) [20] 。FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题,被称为深度学习用于语义分割的开创之作。随后SegNet网络 [21] ,UNet [22] ,PSPNet [23] ,DeepLab系列 [24] 等经典网络相继被提出。然而FCN和SegNet模型不够精细,没有充分利用上下文关系,UNet网络冗余太大,PSPNet网络得到的结果不够精细。Deeplab系列相比这些网络具有准确度高、速度快、参数量小和感受野大等优点。其中,DeepLabv3+利用空间金字塔模块和encoder-decoder来实现语义分割。为了增强分割结果,Xu等人提出加入通道注意力机制模块以增强分割结果的方法 [25] ;Zhen等人采用更密集的特征池化模块有效聚合多尺度特征,同时使用深度可分离卷积降低网络计算复杂度 [26] ;Ma等人提出了使用DeepLabv3+网络识别时频分布中故障特征的方法,对采集到的滚动轴承振动信号使用短时傅里叶变换得到时频分布 [27] ;Zhang等人提出了一种基于DeepLabv3架构的小波域DeepLabv3-MRF (Markov random field, MRF)算法,从而获得更为清晰的边缘细节信息 [28] 。
由于经典方法和深度学习方法不足,为了提高DeepLabv3+网络分割图像效果,本文提出一种基于改进DeepLabv3+模型的语义分割网络,将轻量级网络MobileNetV2 [29] 作为主干网络,利用不可分小波具有各向同性的特点,将加性小波加入模型中进行各个方向的特征提取。实验结果显示,相比于原模型,我们的模型在主观视觉分割效果以及客观指标上都取得了更好的结果。
2. 相关理论介绍
2.1. 二维不可分小波
Liu等人 [30] [31] 对不可分小波进行了广泛的研究,并成功地将其应用于图像处理的不同领域,如图像分割、图像融合和图像增强等。Chen等人以高维小波的多尺度分析为基础,提出了构造具有正交性和紧支撑的高维非张量积小波滤波器组 [32] ,其构造的高维低通滤波器频域形式如下:
(1)
对应的
个相应的正交共轭滤波器(CQF)的形式如下:
(2)
Liu等人在此基础上构建了二维四通道滤波器组 [30] ,假设小波变换的伸缩矩阵为[2, 0; 0, 2],则滤波器组的形式可构造为:
(3)
其中
,
,
以及
为正交阵,
为4 × 1向量,
。
2.2. 加性小波
近些年来小波分析迅速发展,在信号处理、图像识别、计算机视觉和数据压缩等方面具有广泛的应用。二维小波可以分为张量积小波和不可分小波,张量积小波并不具有多方向性,无法处理图像中多方向的信息。与张量积小波相比,不可分小波可以提取到图像各个方向的信息,具有良好的适应性。
加性小波是利用低通滤波器对图像进行atrous分解,具体过程如下:
(4)
其中
为小波平面,也就是对应图像的高频信息;
为低频分量,也就是对应图像的低频信息;
为残余图像。重构公式如下:
(5)
2.3. 注意力机制
CBAM [33] 是一种轻量级通用的模块,同时也是一个即插即用模块,可以嵌套在任何CNN架构中,它结合了空间与通道注意力机制模块。CBAM包含CAM和SAM两个子模块。输入特征
,再将通道注意力模块进行一维卷积
,然后将卷积结果与原图相乘,以CAM的输出结果作为输入,进行空间注意力模块的二维卷积
,再将输出结果与原图相乘,具体过程如下:
(6)
(7)
通道注意力机制类似于SENet [34] ,其主要思想是增加有效通道的权重,降低无效通道的权重。公式表示为:
(8)
其中
表示平均池特征,
表示最大池特征,
,
表示共享网络层的两层神经网络。在网络层
后面,使用函数ReLU作为激活函数,
表示Sigmoid函数。为了减少参数开销,隐藏的激活大小设置为
,其中r是压缩率,本文实验中r取值为16。
通道注意机制关注的是通道层面的哪些层具有更强的反馈能力,空间注意机制则是增强特定区域的特征。空间注意机制的表述如下:
(9)
使用平均池化和最大池化来评估信息,并使用卷积进行提取。最后,用sigmoid层进行归一化。通道注意机制和空间注意机制示意图见图1。

Figure 1. Channel attention and Spatial attention structure in CBAM
图1. CBAM中通道注意力和空间注意力结构
2.4. DeepLabv3+
DeepLabv3+是一个经典的语义分割模型,是经典的编码器–解码器结构,为了使得模型具有轻量级特点,且提高模型训练速度,这里我们选用MobileNetV2为主干网络。经过主干网络进行特征提取后,进入ASPP (空洞空间卷积池化金字塔),其中ASPP包括1*1卷积,空洞率分别为6、12、18的空洞卷积和全局平均池化 [35] 。然后将其进行堆叠,再经过1*1卷积从而实现降低特征图的通道数。在decoder部分,主干网络会将低级特征(Low-Level Features)经过1*1卷积后的特征与decoder部分得到的特征图进行4倍上采样,再进行拼接融合,融合得到的特征图进行3*3卷积后进行4倍上采样,最终得到语义分割后的图像。
3. 方法
3.1. 二维四通道不可分小波滤波器构造
在公式(3)的基础上,取k = 2,构造四通道6 × 6滤波器组:
取:
(10)
(11)
(12)
按照
构造
,
是中心对称矩阵。
取
,
,
,
,可得四通道不可分小波滤波器组的低通滤波器为:
(13)
3.2. 提取图像高频子图
根据我们所构造出的滤波器,基于加性小波的分解原理,我们将图像经过所构造的低通滤波器进行卷积提取到低频
,因为加性小波是完全无损的,保存边缘信息较好。因此我们将原图利用所构造的低通滤波器进行不可分小波分解,然后把源图像与上次分解的低频相减得到高频
,取到图像高频部分。提取到图像如图2(a)的低频及高频信息如图2(b),图2(c)所示。
 (a) 原图 (b) 低频 (c) 高频
(a) 原图 (b) 低频 (c) 高频
Figure 2. Low frequency and high frequency of image
图2. 图像的低频高频
3.3. 对DeepLabv3+模型进行修改
语义分割最终结果正是图像的轮廓信息,而图像的轮廓信息是由边缘信息所构成,因此提取图像中的高频信息对语义分割而言具有重要作用。不可分小波具有各向同性特征,可以提取到图像当中各个方向的信息,具有不丢失源图像信息的特点 [36] 。因此可以很好提取图像轮廓信息。基于此,我们利用加性小波的分解原理,将不可分小波的高频信息送入到网络中。
在模型的Decoder部分以及ASPP部分加入CBAM模块,注意力机制可以告知Feature Map关注的对象,提高了特征感兴趣的表现,提高了模型自适应细化特征。改进后的网络结构见图3。
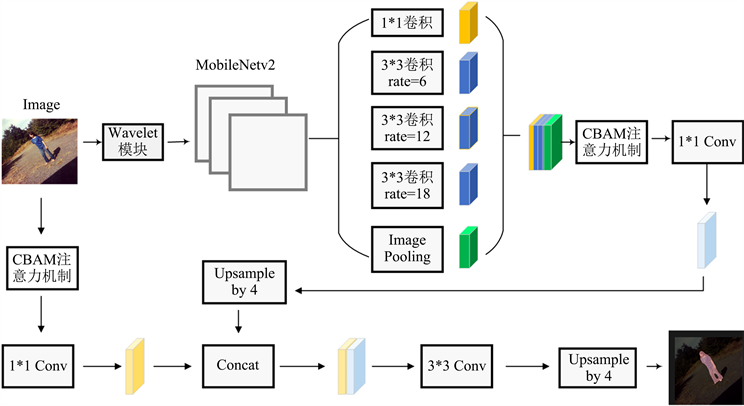
Figure 3. Overall framework of our model
图3. 本文模型框架
4. 结果
4.1. 数据集
我们采用PASCAL VOC以及BDD100K数据集,将数据集按照9:1划分训练集和测试集,VOC数据集以及BDD100K数据集均为语义分割领域中常用的数据集。其中VOC数据集包含20个类别以及一个背景类别,共有10828张图像作为训练集图像,共有7200张图像作为BDD100K训练集图像。
4.2. 实验环境
实验的系统环境在处理器为Intel(R) Xeon(R) Silver 4210 CPU@2.20GHz,运行内存为24G,显卡为NVIDIA Quadro RTX 5000的主机上进行的,程序是基于CUDA11.0以及CUDNN10.1的深度学习框架上实现的。训练分为两个阶段,利用迁移学习思想将模型分为冻结和解冻阶段。冻结阶段会将模型的主干部分冻结,特征提取网络不发生变化,占用的显存较小,仅仅只是对网络进行微调,提升速度的同时保留训练网络的参数。在解冻阶段,此时模型的主干不再被冻结,特征提取网络发生变化,模型的所有参数都会发生变化。冻结阶段将Epoch设置为50,Batch size设置为8,模型的最小学习率设置为0.00007;解冻阶段,Epoch设置为100,Batch size设置为4,学习率设置为0.00007。
4.3. 分析与评价
为了客观评价改进后的模型性能,本文选用MIoU (Mean Intersection over Union),MPA (Mean Pixel Accuracy,类别平均像素准确率),Accuracy (准确度)三个指标来评价语义分割算法的性能。
以VOC数据集为例,该数据集包含20个类以及一个背景类,k表示类别,因此共有k+1个类别,i表示真实值,j表示预测值,
表示将i预测为j。
1) MIoU即均交并比,计算所有类别交集和并集之比的平均值。某一个类别的MIoU计算公式如下:
2) MPA即计算每一类分类正确的像素点数和该类的所有像素点数的比例,然后求取平均值,计算公式如下:
3) Accuracy即全部预测正确的概率。计算公式如下:
其中:TP (True Positive真正例)指预测的结果为正例,并且预测正确。FN (False Negative假反例)表示实际为真,预测为假。FP (False Positive)指假正例,模型预测为正例,实际是反例。FN (False Negative)表示假反例,模型预测为反例,实际是正例。TN (True Negative)表示真反例,模型预测为反例,实际是反例。
4.4. 不同网络在VOC数据集上的测试结果
基于以上所提的评价指标,将本文所提出的新的模型与目前几种比较先进的语义分割模型在VOC数据集上进行对比,结果见表1。

Table 1. Comparison of objective indicators of different Classical semantic Segmentation methods on VOC datasets
表1. 不同经典语义分割方法在VOC数据集上客观指标比较
4.5. 不同网络在BDD100K数据集上的测试结果
将本文所提出的新的模型与目前几种比较先进的语义分割模型在BDD100K数据集上进行对比,结果见表2。
Table 2. Comparison of objective indicators of different Classical semantic Segmentation methods on BDD100K datasets
表2. 不同经典语义分割方法在BDD100K数据集上客观指标比较
4.6. Wavelet模块性能验证
为了进一步验证Wavelet模块的性能,我们将加入Wavelet模块的网络模型与原模型在VOC数据集上进行对比试验,实验结果见表3。加入Wavelet模块后,MIoU提高0.79%,MPA提高0.31%,Accuracy提高了0.11%。证明Wavelet模块对于分割任务有明显提升效果。
Table 3. Wavelet module performance
表3. Wavelet模块性能
4.7. 主观评价
原图如图4(a)所示。使用PSPNet处理后的结果如图4(b)所示,猫的耳朵没有完成分割;鹦鹉身体出现过分割;运动员分割完全但是自行车后轮仅仅只分割1/3。使用UNet模型处理后的结果如图4(c)所示,图像不包含猫的部分却仍然进行小部分分割;鸟的身体分割过度;自行车轮胎没有分割完全,仅仅只是将后部分车轮分割2/3。使用DeepLabv3+处理后的结果如图4(d)所示,很明显发现DeepLabv3+存在分割不清楚问题,猫的轮廓出现阴影;鹦鹉翅膀没有分割完全;运动员头部和前轮还有部分没有完成分割。
对比我们改进后的模型得到的分割图像如图4(e)所示,分割细节以及效果从主观角度看均有明显的提升。
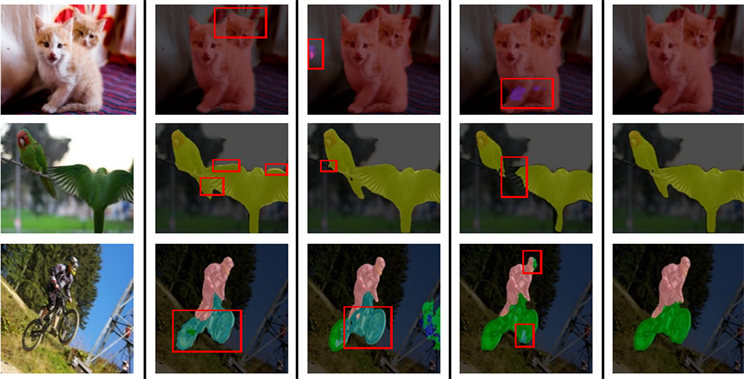 (a) 原图(b) PSPNet (c) UNet (d) Deeplabv3+ (e) Ours
(a) 原图(b) PSPNet (c) UNet (d) Deeplabv3+ (e) Ours
Figure 4. Comparison of Segmentation effects of different models
图4. 不同模型分割效果对比
5. 结论
本文提出了一种基于四通道加性小波与DeepLabv3+网络结合的语义分割模型,能够较好地提取图像的特征,使得分割对象具有更清楚的细节信息。实验结果表明,对比语义分割领域经典模型PSPNet,UNet以及DeepLabv3+模型,本文模型效果更好,明显提升了模型性能。将主干网络替换为MobileNetv2,减少了网络的参数,使得模型更轻量级;加入CBAM模块提高物体分割精度;加入小波变换后,明显提升网络的边缘学习效果,图像的高频是图像轮廓信息,我们将图像经过小波处理放入模型中提升了模型对于细节信息的捕获。无论是主观还是客观结果均显示出我们的模型优于原模型。
基金项目
国家自然科学基金面上项目(No. 61471160)。
参考文献