1. 引言
草原是全球分布最广的陆地植被之一,面积非常大,我国的草原面积量在全世界名列前茅。草原具有非常多的功能,最重要的是它的生态功能,比如它可以维护生物的多样性、净化空气、防止沙尘暴等等。但近年来存在着草原牧区不合理的放牧问题,对草原生态造成了较大的影响。不合理的放牧策略会加速土壤沙漠化,破坏了草原生态系统的正常运转 [1] 。
合理的放牧政策能够保障牧区牧民的生活,有效带动区域经济的良性发展。放牧策略优化问题的研究刻不容缓。在我国草原类型有很多,其中内蒙古锡林郭勒草原是我国最具代表性的草原之一,发挥着重要的生态功能。所以研究草原放牧策略优化问题可以以该草原为例,形成典型,为其他草原提供放牧策略指导。通常草原放牧策略包括放牧强度和放牧方式,放牧方式分为全年连续放牧、禁牧、选择划区轮牧、轻度放牧、生长季休牧;放牧强度分为四种:对照、轻度放牧、中度、重度。植物除了自身生长规律外,受环境影响较大,放牧和植物的生长密切相关。适度放牧能够有效提高土壤的质量,保护生物多样性 [2] 。
目前国家提倡可持续性发展战略,在保证生态环境不遭到破坏的情况下,寻求经济的高质量发展。而可持续性发展指的是经济增长没有超过生态环境的承受能力的高质量发展 [3] - [13] 。
本文就是基于相关政策法规和当前草原生态系统存在的问题进行的放牧策略问题的优化研究,为的就是给草原牧区的放牧策略的研究提供一定的帮助。开发草原放牧策略模型,建立不同年月土壤湿度和蒸发量降水量之间的关系,预测未来月份的湿度值;接着建立不同放牧策略对草原土壤化学性质影响的数学模型,并进行预测。
2. 模型建立
2.1. 土壤蒸发量以及降水量对不同深度土壤湿度的影响
不同年份的降水量,直接或间接的影响着不同深度土壤的适度变化,所以预测土壤蒸发量以及降水量对不同深度土壤适度的影响至关重要,可以为不同月份放牧策略提供参考。本文使用的实验数据主要为2021年和2022年不同月份的相关数据,考虑到本文数据具有时序性且数据量相对不多,采用传统的神经网络进行预测存在较大的局限性 [14] ,方法一利用简单的时序预测网络结构NAR,根据年月的不同深度的土壤湿度数据,直接预测2022年和2023年的不同深度的土壤湿度值,但是误差很大,预测效果很差。方法二采用了NAR先预测了2022年4月至2023年12月的土壤蒸发量的数值,预测结果较为良好,拟合优度R2在0.92以上,均方误差MSE的值也很小,预测出的土壤蒸发值较为合理。接着采用相同方法对降水量进行预测,经多次调参,训练效果依然很差,训练集的R值有0.85左右,但是测试集和验证集的R值却一直很低,导致预测的降水量数值误差很大。得到接下来21个月的蒸发量和降水量数据以后,可采用BP神经网络的方法来预测不同深度的土壤湿度数据。但是采用这个方法得到的结果的可靠性不高,多次神经网络引入的误差较大,且降水量的预测精度很差,所以最终预测得到的不同深度的湿度数据具有很大的问题。考虑到数据集的数据量相对较少,所以决定不采用常规传统的神经网络模型。
由于采集的数据具有明显的时序性,所以采用长短期记忆神经网络(LSTM)的方法来进行分析求解。这种方法相较于传统的神经网络优势更明显,能够有效地处理这种时序数据,同时能够高效地解决训练时可能存在的梯度消失和爆炸等问题。依据前两年的数据推测第三年的数据,以此类推。由于各月份影响因素差异较大,所以采用每个月份单独建模的方式,分别建立1至12月的LSTM模型,然后根据每个月份的模型来预测2022年和2023年相应月份的不同深度的土壤湿度值。图1直观地表达出了土壤蒸发量以及降水量对不同深度土壤湿度影响的模型建立思路。

Figure 1. Flow chart of modeling the effect of precipitation on soil moisture
图1. 降水量对土壤湿度影响建模思路流程图
LSTM是一种特殊的循环神经网络RNN-门限RNN,其提出的目的是解决RNN在长序列训练的过程中出现长期依赖、梯度消失或者梯度膨胀的问题,LSTM网络通过控制输入门、遗忘门、输出门来完成信息的传递,输入门决定当前时刻哪些数据需要被保存到单元状态,遗忘门对输入进来的数据进行选择性的记忆,把其中重要的信息保留下来,输出门则是控制当前需要输出的内容 [15] 。
LSTM的基本网络结构如下图2所示,该网络内部结构的计算公式为(1)所示。
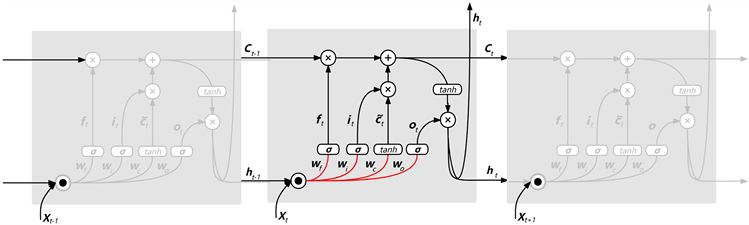
Figure 2. LSTM network structure diagram
图2. LSTM网络结构示意图
(1)
表示遗忘门,
表示输入门,
表示输出门,
表示前一时刻细胞状态,
表示当前细胞状态,
表示当前单元的输出,
表示前一时刻单元的输出,
表示当前层的输入,
表示为遗忘权重,
表示为输入权重、
表示为当前状态权重、
表示为输出权重
表示为遗忘偏置项、
表示为输入偏置项、
当前状态偏置项表示为、
输出偏置项。
采用长短期记忆神经网络(LSTM)的方法对相关数据来进行分析求解。依据前两年的数据推测第三年的数据,以此类推。由于每个月份的不同深度的土壤湿度差异较大,且受到的影响因素较多,所以采用每个月份单独建模的方式,分别建立1至12月的LSTM模型。这样得到的预测模型更加合理,准确性更高。
本文对数据进行剔除异常值,并归一化标准化处理。然后建立这12个月份的LSTM网络模型,加载数据样本,将样本分为70%的训练集,30%的验证测试集。反复进行测试训练,不断调整相关参数,找到较优的LSTM预测模型。对于训练出来的结果,通常用神经网络结果图中的相关度R值或均方误来判断神经网络模型的预测精度。MSE值越小代表预测精度越高,模型的泛化能力就越强。
均方误差(MSE)是预测值和真实值之差的平方和的平均值,其表达式为:
(2)
最终得到的12个月份的LSTM预测网络模型的预测评价指标如表1所示。

Table 1. LSTM predicted soil moderate evaluation index in different months
表1. LSTM预测不同月份土壤适度评价指标
从下图3来看,每个月份的LSTM网络模型训练预测得到的不同深度土壤湿度数值的整体趋势和真实值还是很接近的,较符合预期结果。从表1可以看出,均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)的值不是很大,总体表现还可以。只有个别月份的表现较差,可能是天气异常或者数据异常的原因。也有可能是数据样本量较少的原因,使得网络的训练效果没有那么完美。但是总体而言,这些LSTM预测模型还是具有很高的可靠性的。
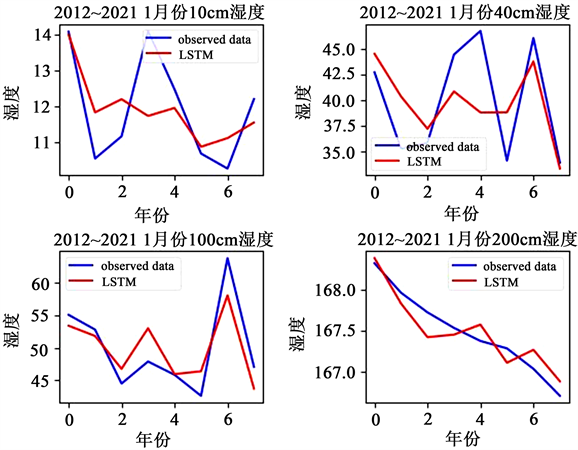
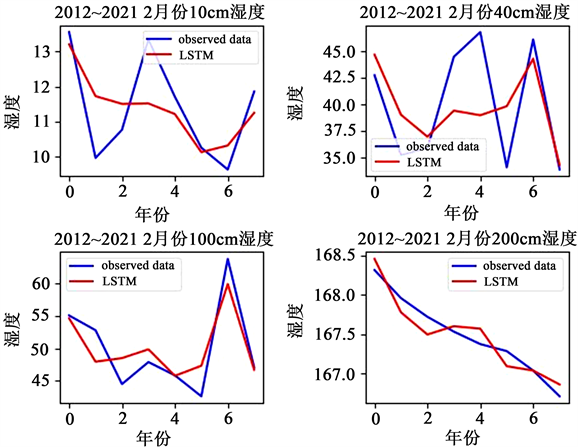
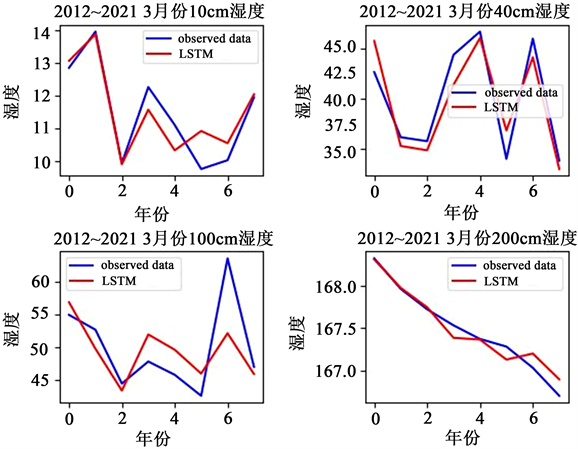
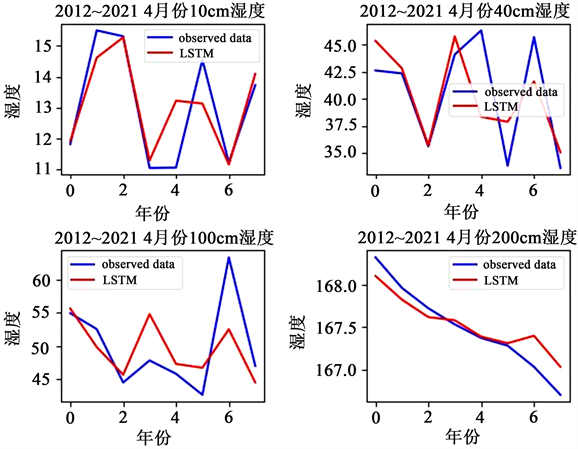
Figure 3. The real value of soil moisture and the predicted value of LSTM from January to April of 2012 to 2021
图3. 2012~2021年1~4月份土壤湿度真实值和LSTM预测值
采用上述确定的各个月份的不同深度的土壤湿度的LSTM预测模型来进行预测求解。在保持当前放牧策略不变的情况下,使用上述已经训练好的LSTM神经网络模型对2022年4月至2023年12月的不同深度的土壤湿度进行预测。将各个月份的LSTM预测模型的预测值填进表中,具体结果如表2所示。由于预测年份并没有实际的参考数据可供参考,所以表2得到的数据可以为未来数据提供参考信息。
Table 2. LSTM predicts soil moisture at different depths in different months
表2. LSTM预测不同月份不同深度土壤湿度
2.2. 放牧策略对草原土壤化学性质影响
针对不同放牧策略对草原土壤化学性质影响的数学模型。考虑到样本的数据量和特征量不多且每个牧场所采用的放牧强度不变的特性,所以采用机器学习中随机森林的方法来进行分析求解。建立不同放牧策略对草原土壤化学性质(SOC、SIC和STC)影响的随机森林回归预测模型,划分训练集验证集,反复调整参数得到最优的随机森林回归预测模型,然后预测2022年的土壤化学性质,再通过数学关系得出全碳N和土壤碳氮比C/N值。图4直观地表达出了放牧策略对草原土壤化学影响的建模思路。

Figure 4. Flow chart of modeling grassland soil chemical properties
图4. 草原土壤化学性质建模流程图
随机森林回归(RFR)是由多个二叉决策树(CART)打包组合而成的,在训练二叉决策树模型的时候需要考虑怎样选择切分变量(特征)、切分点以及怎样衡量一个切分变量、切分点的好坏。针对于切分变量和切分点的选择,一般是通过遍历每个特征和每个特征的所有取值,从中找出最好的切分变量和切分点。以切分后节点的不纯度来衡量,即各个子节点不纯度的加权和 [16] 。随机森林的基本结构图如下图5所示,对应的计算如公式3所示:
(3)
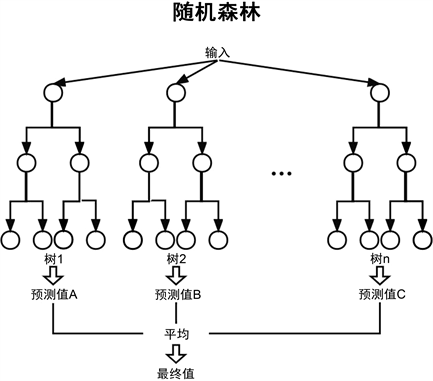
Figure 5. Schematic diagram of random forest structure
图5. 随机森林结构示意图
上式中,xi为某一个切分变量,vij为切分变量的一个切分值,nleft,nright,Ns分别为切分后左子节点的训练样本个数、右子节点的训练样本个数以及当前节点所有训练样本个数,Xleft,Xright分为左右子节点的训练样本集合,
为衡量节点不纯度的函数,分类和回归任务一般采用不同的不纯度函数。
该预测模型中模型的评价指标为MSE,RMSE,MAE,R值等。MSE、MAE越小,越接近于0,相关度R值越接近于1,代表该模型的预测效果越好。
绝对平均误差(MAE)函数公式如公式(4)所示:
(4)
为了研究不同放牧策略对草原土壤化学性质影响,采用机器学习中随机森林的方法来进行分析求解,依据前十年的数据对三个化学性质建立三个随机森林回归模型,然后根据建立好的随机森林模型预测2022年土壤同期有机碳、无机碳、全N的值,再通过计算得出全碳和土壤碳氮比。这样得到的预测模型更加合理,准确性更高。
在建立有机碳、无机碳、全N的随机森林回归预测模型过程中,将加载数据样本分为70%的训练集,30%的验证测试集,设置训练参数决策树数量、树的最大深度、叶子节点的最大数量、内部节点分裂的最小样本数、叶子节点的最小样本数,反复进行测试训练,不断调整相关参数,找到最优的随机森林回归预测模型,对训练出来的结果,采用MSE、RMSE、MAE、拟合优度R2等指标来判断随机森林回归预测模型的预测精度。
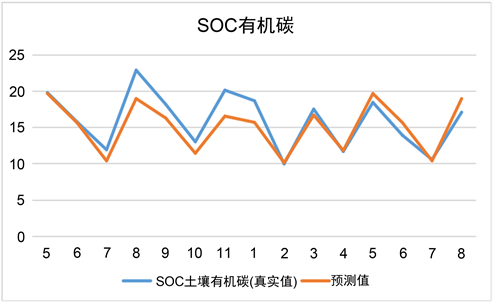
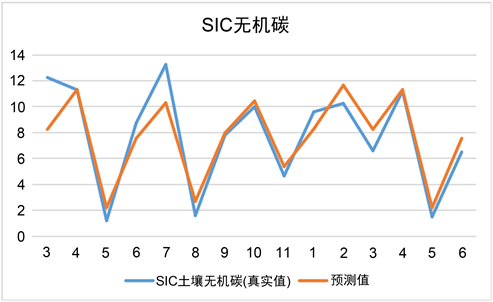
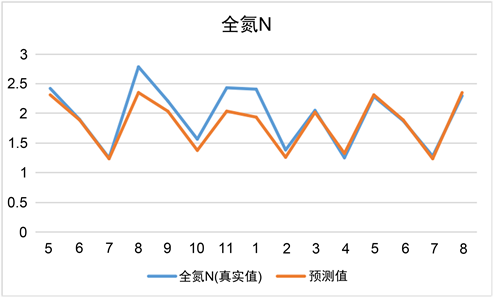
Figure 6. Comparison of actual and predicted values of SOC organic carbon, SIC inorganic carbon and total nitrogen N
图6. SOC有机碳、SIC无机碳、全氮N的实际值与预测值的比较
SOC有机碳、SIC无机碳、全氮N的随机森林回归预测模型的预测评价指标如表3、表4、表5所示。经过反复测试,随机森林回归模型参数决策树数量为100、树的最大深度为20、叶子节点的最大数量为50、内部节点分裂的最小样本数为2、叶子节点的最小样本数为1。
Table 3. Prediction and evaluation index of SOC soil organic carbon prediction model
表3. SOC土壤有机碳预测模型的预测评价指标
Table 4. Prediction and evaluation index of SIC soil inorganic carbon prediction model
表4. SOC土壤无机碳预测模型的预测评价指标
Table 5. Prediction evaluation index of total nitrogen N prediction model
表5. 全氮N预测模型的预测评价指标
从结果来看,这三个随机森林回归预测模型在相当有限的数据集中表现还是较为良好的。其中全氮N预测模型预测效果最好,它的MSE值非常小,而且拟合优度也是最优的,SOC土壤有机碳的模型预测效果次之,但是从拟合优度R2来看效果还是不错的,相关度R可以达到0.9,所以该模型还是比较良好的。SIC土壤无机碳的预测模型的效果相对较差,相关度R值在0.8左右,存在着一定误差。SOC有机碳、SIC无机碳、全氮N的实际值与预测值的比较如图6所示。从图5可以看到;在这30%的测试验证集上,训练得到的三个模型的预测值和实际值的总体趋势是相同的,而且误差不是很大,所以这三个随机森林回归预测模型是具有一定的可靠性的,能够用作本问题的模型,来预测求解在不同放牧强度下2022年土壤同期有机碳、无机碳、全N、土壤C/N比等值。
采用上述已经确定的有机碳,无机碳,全N的随机森林回归预测模型来预测求解。在保持每个牧场放牧强度不变的情况下,对2022年的有机碳,无机碳,全N土壤化学性质进行预测,可以求得有机碳、无机碳、全氮N的预测值。然后根据关系式计算出土壤C/N比和STC土壤全碳值。数学关系式为式(5)、(6)所示。
(5)
(6)
最终的结果如表6所示。
Table 6. In 2022, soil organic carbon, inorganic carbon, total N and soil C/N ratios were equivalent under different grazing intensities
表6. 不同放牧强度下2022年土壤同期有机碳、无机碳、全N、土壤C/N比等值
3. 结论与建议
本文采用了LSTM网络结构模型研究土壤蒸发量以及降水量对草原不同深度土壤湿度的影响,相较于传统的神经网络具有更大的优势,能够有效的处理时序数据信息。注意到不同月份不同深度土壤湿度的差异性,将每年相同的月份归为一组建立每个月份单独的LSTM预测网络模型,分别求解2022年和2023年对应月份的不同深度土壤湿度。极大的提高了模型的准确性可靠性,使得预测结果准确度更高。但是由于样本数据相对较少,对LSTM网络的训练测试存在一定的影响,如果数据样本数量更多些,可以进一步提升模型的预测精度。
针对放牧策略对草原土壤化学性质的影响,本文采用了随机森林回归预测模型。对有机碳、无机碳、全N分别建立随机森林回归预测模型,经过反复调参测试,最终确定了较优的模型,有效地提高了模型预测的准确度。并且通过数学关系直接计算出STC土壤全氮和土壤C/N比,减少了工作量。本文通过相关模型的训练调参,可以发现针对不同深度的土壤,不同的月份时间对其有着显著的影响,且不同深度的土壤湿度互相影响,浅层土壤深度随着月份的变化较小,但是深层的土壤深度随着月份的变化较大。针对不同的放牧策略对同让化学影响的研究,可以发现在不同的放牧策略下土壤的化学性质有着较大的差距,为了保持放牧的可持续,需良好的规划不同放牧时间采取正确的放牧策略,以保证土壤的良好化学性质。
参考文献