1. 引言
金融市场的发达程度决定了一个国家的经济发展水平,其中最为重要的市场之一便是股票市场,股票市场是不同的投资者以及企业等投资主体进行资产配置的途径。股票市场是由不同的上市公司所发行的代表自身权益的股票所组成的市场,股票的价格决定了公司目前在股票市场中处于什么样的位置,其中蕴藏着有关公司的大量信息。随着股票市场的蓬勃发展,如何保证在较低的风险之下获得较高的交易回报已经成为了现代金融领域所研究的热点问题之一,以往的金融交易往往依赖对于股票未来资产价格的准确预测并且通常针对单一资产。但是由于股票市场存在着非线性、非平稳以及高噪音等特性让股价通常难以预测并且投资于单一资产往往具有较高的不确定性,通常可以将资金分散于不同的资产上面来降低这种风险,这也被叫做投资组合管理。现目前已经有许多研究表明,正确的投资组合管理能够在一定程度上击败市场,在保证更低的风险的同时获取更多的收益。最新的投资组合管理问题往往都与强化学习技术相结合,强化学习是机器学习的一个分支,通过不断地让智能体和环境交互来让智能体学习到正确的策略,在许多领域都有着非常优秀的表现,甚至超过了人类专家,例如AlphaGo Zero [1] 。并且强化学习的目标设定灵活且直接,当与投资组合管理任务相结合时,可以同时考虑到交易风险和远期收益,以一种端到端的方式来训练智能体。而深度学习具有高阶特征抽取的能力,融合了深度学习的强化学习技术可以更好地进行投资组合管理任务。
在1952年,经济学家Markowitz便提出了均值方差模型 [2] ,首次将数学与统计知识引入投资组合管理领域,拉开了利用数学知识解决投资组合管理问题的序幕。之后Sharpe提出了资本资产定价模型 [3] ,探讨了风险和收益的关系,解释了市场价格的形成。有效市场假说指出,如果投资组合足够理性,那么就能在市场中对所有的信息做出准确的判断,但是在实际交易过程中,很多情况并不满足有效市场假说。传统意义上,要利用金融市场获取收益,需要首先对未来市场做出准确的预测,然后根据预测的结果进行资产权重的配置,对于股价的预测,彭等 [4] 使用LSTM网络对AAPL股票进行了预测,并且对股票数据进行了小波去噪来消除噪声,使用了不用的LSTM层数,证明了LSTM模型在股价预测任务上的优势。BAO等 [5] 使用小波变换对金融序列进行去噪,然后使用栈式自编码器学习金融序列的高阶特征并使用LSTM网络对不同金融市场的股票指数进行了预测,证实了提出的深度学习预测框架的效果。张等 [6] 引入EMD和CEEMDAN算法对原始股价序列进行了分解,并且引入了注意力机制结合GRU神经网络对不同的股票进行了预测,实验证实了提出的复合模型具有更高的拟合程度、更好的预测效果。
区别于利用不同的算法对股票价格进行预测之后再根据预测的结果进行交易,强化学习可以将预测和交易整个过程结合在一起,以一种端到端的方式来训练智能体,从而避免了在做出预测之后和根据预测结果进行交易之间所产生的误差。本质上来说,投资组合管理任务属于序贯决策过程,即根据不断变动的市场信息来改变投资权重,因此可以被建模为马尔可夫决策过程,因为马尔可夫决策过程是形式化序贯决策任务的一种框架,而强化学习是解决马尔可夫决策过程及其扩展形式的一种方法,所以可以使用强化学习技术来解决投资组合管理任务。强化学习通常可以分为Model-Based和Model-Free方法两类,投资组合管理任务通常应用Model-Free这一类强化学习方法,而Model-Free方法通常又可以分为基于值函数的方法、基于策略梯度的方法以及两者相结合的方法三类。在基于值函数的方法中,许等 [7] 利用CNN模块感知股票市场,抽取市场特征,利用LSTM模块学习时间序列规律,构建了CLDQN算法,并引入随机噪声和正则化来提升模型鲁棒性,实验证实提出的模型具有更好的表现。在基于策略梯度的方法中,智能体是通过对策略进行参数化然后进行求解来获得最优策略,常见的算法有REINFORCE算法、DPG算法、PPO算法等。Jiang等 [8] 使用了DPG算法对加密货币市场进行了研究,对投资组合管理任务利用数学公式进行了清晰的表述,然后提出了包括EIIE、PVM以及OSBL在内的模型,EIIE包括CNN、RNN以及LSTM三种网络结构,最后实验结果表明,所提出的模型在加密货币市场有优秀的表现。Liang等 [9] 比较了DDPG、PPO和REINFORCE算法的效果,并引入了对抗学习,其中REINFOECE算法的表现最好。Huang等 [10] 将对抗学习和抽样策略相结合,构建了包含DJIA成分股的五种资产组合,使用对抗学习来增强模型稳定性,实验证实相较于基准策略,夏普比率提高了6%~7%,利润增长了近45%。Wang等 [11] 提出了AlphaStock模型,构建了零投资组合的概念,要求做空和做多的资金一样多,使用了LSTM-HA网络来处理时序关系,CAAN网络来将不同的股票特征进行比较整合,产生上涨分数,然后筛选出做多和做空的股票,并使用softmax函数产生权重分配,然后使用夏普比率对模型的参数进行更新,实验证实该模型的优越表现。Wang等 [12] 提出了DeepTrader模型,该模型包括资产打分单元ASU和市场打分单元MSU,资产打分单元通过TCN结构抓取股票的时序特征,然后使用GCN图卷积网络SA空间注意力模块抓取股票之间的空间关系,市场打分单元使用了AlphaStock中的LSTM-HA架构,然后输出一个多仓比例来进行调仓,将两个部分结合起来共同放入损失函数进行策略更新,在ASU部分建模为离散动作空间,使用价格上涨率作为奖励函数,在MSU部分建模为连续动作空间,使用负的最大回撤率作为奖励函数,实验在DJIA、HSI和CSI数据集上进行,证明了提出的模型具有优越的表现。当然,也有一些将多智能体强化学习算法应用于投资组合管理任务的工作 [13] ,其预先假设是大公司通常有不同的投资经理能够分散风险。
综上,可以发现目前对于投资组合管理任务的研究,多数使用了基于策略梯度的方法,对于数据集中噪声的处理,部分使用了对抗学习来增强模型的鲁棒性。在股价预测任务中,已经出现了使用了信号分解一类的算法来对股价序列进行分解从而获得更好的表现。因此,本文的工作将针对股价序列中出现的噪声问题展开,使用EWT经验小波变换对股价序列进行分解,然后按照一定的阈值将噪音进行分离。对于去噪后的数据构成的科技指标,将使用TCN时间卷积网络提取时序特征,Multi-Head Attention多头注意力网络提取股票之间的空间特征,构建EWT-PG模型。
2. 问题设置
2.1. 投资组合管理问题
记在时间轴上以等长的间隔所划分的区间为持有期,在第t个持有期,持有期的开始可以记为时刻t−1,结尾可以记为时刻t,投资者要求在持有期t开始时,根据所观测到的市场状态,做出当前的交易权重
。记持有期t的开始以及结尾的价格向量为
,
,那么
和
可以分别表示为:
(1)
(2)
相对价格向量可以表示为
,那么:
(3)
(4)
通常投资组合管理问题的权重非负且和为1,为了进行做空交易,这里使用AlphaStock中的问题设定和框架,在每个时刻拥有空头和多头两个投资组合,并且两个投资组合的净资金的总和为0。在持有期t开始时,记总资金为
,然后将根据以下步骤进行交易:
1) 借来价值
资金的股票,使用
的资金进行做空,空头权重记为
,则借来的第 只股票的数量可以表示为:
(5)
2) 不考虑交易成本,将借来的股票卖掉,得到价值
的资金,然后根据多头权重
进行做多,则做多的第i个资产的数量可以表示为:
(6)
3) 经过持有期t之后,首先卖出股票获得现金,多头的价值随着价格变动会变化为
:
(7)
4) 然后买入股票对空头进行平仓,空头的价值会变化为
:
(8)
5) 在持有期t上所获得收益可以记为
:
(9)
其中TC为交易成本,取0.1%。
6) 那么时刻t的总资金可以记为
:
(10)
假设在n个持有期上进行交易,那么这n个持有期上的平均收益可以记为
,波动可以记为
,夏普比率可以记为
:
(11)
(12)
(13)
2.2. 强化学习
强化学习可以建模为一个MDP马尔可夫决策过程,通常而言,MDP过程可以用一个四元组
来表示,其中
代表状态空间,表示智能体能够观测到的所有状态,
代表动作空间,是智能体能够执行的所有动作,
代表奖励函数,
代表状态转移概率。
状态:在投资组合管理任务中,在时刻t智能体所观测到的所有股票的特征可以记为
,
包含了m只股票在时刻t及其之前的l个时刻上的k个特征:
(14)
(15)
动作:智能体在观察到状态
之后所做出的动作,
,
,这里建模为离散动作空间,即如果智能体对某只股票进行投资,那么
,否则为0。那么智能体对于某只股票进行投资的概率可以记为:
(16)
奖励:当智能体与环境进行交互之后,环境会返回一个关于智能体采取某个动作的奖励
,这里当智能体与环境交互之后再对其参数进行更新,记在n个持有期上的智能体所获得的奖励为
。
策略梯度算法:策略梯度算法可以被直观理解为,如果某个动作的出现可以让目标函数的值变高,那么就增大出现这个动作的概率,否则就降低这个动作的概率,并且策略梯度算法不需要对值函数进行估计。记策略的参数为
,策略为
,目标函数为
,那么智能体的目标就是不断地通过调整参数来调整策略从而让目标函数达到最大。目标函数可以表示为:
(17)
表示从开始到结束的一条完整轨迹,
代表智能体在该条轨迹上所获得的奖励,通常可以使用梯度上升法来让目标函数的奖励达到最大:
(18)
其中
代表学习率,
代表参数
的梯度,可以表示为:
(19)
(20)
(21)
(22)
那么最后可以将梯度
表示为:
(23)
2.3. 模型结构
1) TCN (Temporal Convolutional Network)时间卷积网络。针对时间序列建模任务,传统上是使用循环神经网络RNN、LSTM以及GRU一类的网络,但是该类网络一次只能够处理一个时间步,后一个时间步必须等前一个时间步处理完才能进行运算,这意味着该类网络计算密集。而时间卷积网络基于CNN架构,采用一维全卷积网络,能够进行并行处理,并使用了因果卷积,因果卷积意味着信息不会从未来泄露到过去。同时,也整合其他的架构进TCN网络,例如空洞卷积以及残差模块。这里使用TCN网络来建模股票的时序关系。TCN中的因果卷积、空洞卷积以及残差连接如图1所示:
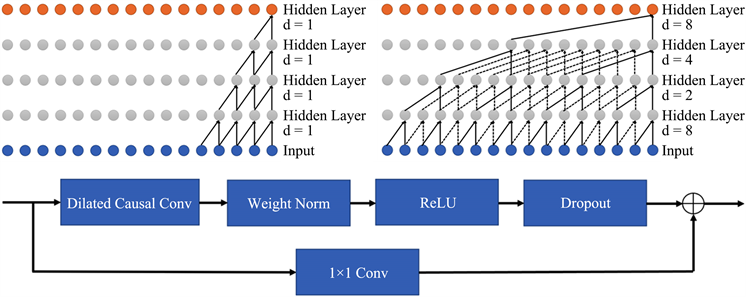
Figure 1. The structure of temporal convolution network
图1. TCN的网络结构
dilationrate指的是两个卷积核之间的间隔大小,上图分别为dilationrate率为1和按层数以2的指数次方增长的图,可以发现空洞卷积能够记忆更长的历史信息,增大了感受野,丰富了特征表达。输入
在经过TCN之后,变为
,之后输入到多头注意力网络中。
2) Multi-Head Attention多头注意力网络。注意力机制源于人类的视觉注意力机制,人类在观察当前的场景时,由于注意力有限,不会同时关注所有地方,而是对重要的地方投入更多的注意力,对不重要的地方投入更少的注意力,这样能够使人类在大量的信息之中筛选出重要的信息,提高处理效率和准确度。深度学习中的注意力机制和人类的注意力机制类似,在训练的过程之中学习出一个注意力权重,从而提高实验表现。自注意力机制的公式如下:
(24)
代表缩放参数,自注意力机制主要计算
在加权之后的表示,通过softmax函数来计算相似度得分。为了加强注意力机制的表达能力,提出了多头注意力机制,首先把
通过参数矩阵在每个head进行变换,然后再做注意力并拼接起来之后再经过线性变换得到最后的结果。由于不同股票之间的空间关系至关重要,这里使用多头注意力机制来提取出不同股票之间的空间关系。多头注意力机制的公式如下所示:
(25)
(26)
这样得到
,之后输入到全连接层之中并经过sigmoid函数来得到对于每只股票未来涨跌潜力的预测。
(27)
这里
,b代表要学习的权重和偏置。
3) 投资组合产生器。在得到了每只股票的预测得分之后,将股票按照得分进行降序排列,选取靠前的G只股票进行做多,这意味着这些股票价格将会上涨,选取排名靠后的G只股票进行做空,这意味着这些股票价格将会下降。分别记G只做多和做空的股票所构成的集合为
和
,那么
和
可以分别记为:
(28)
(29)
其中
代表每一只股票的预测涨跌,在得到权重之后,会计算在持有期t上智能体的收益,然后返回给智能体。可以使用一个向量
来统一表示权重,如果第i只股票不属于
和
,那么
为0,否则为对应的
或
的值。
3. 实验及结果分析
3.1. 获取数据并进行数据预处理
本文使用能够进行做空的股票数据集DJIA成分股、HSI成分股以及DAX成分股,所以不使用国内的股票成分股。这三种不同的成分股分别衡量了三种发展程度不同的市场,分别为美洲市场、亚洲市场以及欧洲市场。使用雅虎财经Yahoo Finance来获取股票,范围为2010.1.4~2022.12.30,其中获取的收盘价是调整后的收盘价,在获取了数据集之后,需要对数据集进行预处理,如果某只股票的缺失值数量大于整个数据集长度的一半,则删除该股票,然后针对剩下的股票里所含有的缺失值按照后一个非缺失值数据的方法进行填充。最后获得29只DJIA股票,48只HSI股票以及28只DAX股票。然后划分训练集和测试集,对于DJIA成分股,训练集为2010.1.4~2019.1.14,测试集为2019.1.15~2022.12.30,对于HSI成分股,训练集为2010.1.4~2019.3.26,测试集为2019.3.27~2022.12.30,对于DAX成分股,训练集为2010.1.4~2018.12.16,测试集为2018.12.17~2022.12.30。如表1所示:

Table 1. Training set and test set
表1. 训练集和测试集
在得到了投资组合数据集之后需要对其进行去噪,为了检验是否有必要去噪,下面将进行ADF检验,从DJIA数据集中选择AAPL、GS股票,从HSI数据集中选择0006.HK,0016.HK股票,从DAX数据集中选择MRK.DE和BMW.DE股票作为示例。如表2所示:
从中可以看出,所选择的股票的检验统计量都大于10%显著性水平,并且p值都大于0.05,所以股价序列具有非平稳的性质,里面含有大量的噪音,因此需要对金融序列进行去噪。这里使用EWT经验小波变换来对股价序列进行去噪,由于只需要使用到收盘价,因此只对收盘价进行去噪。下面以AAPL股票为例,展示经过EWT后不同的IMF的描述性统计结果。其中相关系数是该IMF和原始序列的相关系数,如表3所示:
Table 3. Descriptive statistical analysis of EWT decomposition of AAPL
表3. AAPL序列EWT分解描述性统计分析
AAPL股票收盘价序列和不同的本征模态分量图如图2所示:

Figure 2. AAPL closing price series and its IMFs
图2. AAPL收盘价序列和本征模态分量图
在对股价序列进行分解后,选择相关系数的阈值为0.05,将相关系数小于0.05的IMF视为噪音,对剩下的进行重构,得到去噪后信号。如果以AAPL股票为例就是选择IMF1、IMF2以及IMF3进行重构,得到去噪后信号。然后利用去噪后的收盘价序列来构造MACD指标、SMA指标、RSI指标以及对数收益率指标,和成交量指标一起经过Max-Min归一化之后输入到模型之中。
3.2. 模型参数
模型主要参数如表4所示:
Table 4. The parameters of the model
表4. 模型主要参数
3.3. 对比模型
Market:通常用UBAH (Uniform Buy And Hold)策略来衡量市场表现,UBAH策略是指在交易开始阶段等量买入资产同时不进行调仓直至交易结束。
EG:Exponentiated Gradient指数梯度策略,基于思想是追踪上一个时期表现得最好的股票并且保证新的投资组合权重不会发生较大的偏移。
PAMR:Passive Aggressive Mean Reversion策略,基本思想是用一个损失函数来反映均值反转特性,如果前一期相对价格的预期收益大于阈值,那么损失会线性增加,否则损失为0。
EIIE:EIIE (Ensemble of Identical Independent Evaluators)是一种强化学习智能体,使用独立评估器来对资产特征进行提取,最后汇入到softmax函数中得到投资组合权重,使用了DPG算法来更新策略,这里使用LSTM网络来实现。
AlphaStock:一种深度强化学习模型,使用了带有历史注意力机制的LSTM网络,即LSTM-HA网络来编码时序特征,使用CAAN网络来提取股票之间的相关关系,使用夏普比率来进行优化。
其中AlphaStock和本文的EWT-PG模型可以进行空头操作。
3.4. 衡量指标
投资组合管理的效果可以从多个不同的角度来衡量,对于不同的模型在测试集上的表现,通常可以采用三类不同的指标来进行评价,第一种指标是收益率指标,从投资组合收益的角度对模型的表现进行衡量,例如年化回报率。第二类指标是风险指标,从投资组合风险的角度对模型的表现进行衡量,例如年化波动率和最大回撤率。第三类指标是收益–风险指标,从投资组合的风险和收益相结合的角度来对模型的表现进行衡量,例如年化夏普比率、卡玛比率和索提诺比率,这三类指标分别从不同的方面对模型的表现进行衡量。有关以上指标的描述及计算公式如下所示 [11] [12] :
年化回报率ARR (Annualized Return of Rate):即每年的投资组合的回报率,公式如下:
(30)
式中y代表一年中持有期的个数,由于本文选择月度调仓,所以这里y取12。
的公式如式(11)所示。
年化波动率AVOL (Annualized Volatility):每年的投资组合的波动情况,用每年的投资组合回报的标准差来衡量,公式如下:
(31)
其中
的公式如式(12)所示。
最大回撤率MDD (Maximum Draw Down):是所有回撤率中的最大值,衡量了投资组合策略在历史中表现的最差情况,公式如下:
(32)
其中
代表在回测期第t个时刻上的总资金,公式如下所示:
(33)
其中
代表初始资金,这里取1,即所有模型的初始资金记为1。
年化夏普比率ASR (Annualized Sharpe Ratio):年化夏普比率是指经过年化波动率AVOL进行风险调整之后的年化回报率,公式如下所示:
(34)
卡玛比率CR (Calmar Ratio):卡玛比率是指经过最大回撤率所调整后的年化回报率,是每单位最大回撤率上的年化回报率,公式如下:
(35)
索提诺比率SOR (Sortino Ratio):索提诺比率是基于下行偏差风险所调整的年化回报率,定义为每单位下行偏差上的年化回报率,公式如下:
(36)
的公式如式(9)所示。在这些指标之中,只有风险指标应当越小越好,其余的指标应当越大越好。
3.5. 结果分析
下面将对本文构建的EWT-PG模型在三种不同的数据集上,在六种不同的评价指标下,与其余五种模型进行对比分析,包括三种基本的策略和两种强化学习智能体。范围为对应的数据集的测试集的范围。其中在不同评价指标下的最优模型用加粗黑体表示。
3.5.1. DJIA数据集
在DJIA数据集上的结果如表5所示:
Table 5. Results of different models on the DJIA dataset
表5. DJIA数据集上不同模型结果
上表是不同的模型在DJIA数据集上的回测结果。可以发现本文的模型在ARR、MDD、ASR、CR以及SOR上都达到了最好的表现,其中年化收益率ARR为22%,最大回撤率MDD为14.30%,年化夏普比率ASR为1.2157,卡玛比率CR为1.5384,索提诺比率SOR为6.37,均优于其他所有的模型,证明了在DJIA数据集上,对股价序列进行去噪,能够让模型有更好的表现。同时,在AVOL这一项指标上,不如AlphaStock模型,AVOL指标衡量了投资组合的上行波动和下行波动,而通常来说,投资者对于下行波动则更为关心。同时,能够看出强化学习模型要普遍优于传统的策略,证明了强化学习模型的学习能力,能够根据不同的市场环境做出最优决策,传统策略往往给定了预先假设,而实际的市场可能并不满足传统策略的假设。
3.5.2. HSI数据集
在HSI数据集上的结果如表6所示:
Table 6. Results of different models on the HSI dataset
表6. HSI数据集上不同模型结果
上表是不同的模型在HSI数据集上的表现结果,可以发现本文提出的EWT-PG模型在最大回撤率MDD和索提诺比率SOR这两个指标上要优于其余的模型,分别为15.08%和5.5737,证明了让模型学习去噪后的数据能够有效地提高模型的抗风险能力,增强鲁棒性。同时,在HSI数据集上市场表现不如DJIA数据集,说明该市场有着较大的风险。
3.5.3. DAX数据集
在DAX数据集上的结果如表7所示:
Table 7. Results of different models on the DAX dataset
表7. DAX数据集上不同模型结果
上表是不同的模型在DAX数据集上的表现,可以发现在ARR、ASR、CR以及SOR四个指标上,EWT-PG模型有着最好的表现,分别为26.31%的年化收益率,1.5096的年化夏普比率,1.6017的卡玛比率以及5.9568的索提诺比率,可以看出本文所提出的模型的优越性。同时,也可以发现AlphaStock模型有最低的年化波动率和最大回撤率。同时也能看出,在该数据集上强化学习模型的表现也要整体优于传统策略的表现,证明了其能够根据不同的市场风格做出正确决策的能力。
3.5.4. 对数据集去噪对实验的影响
为了探究是否去噪对模型效果的影响,下面将让智能体对去噪后数据和原始数据进行学习。这里原始数据即用未经过去噪后的收盘价构建的科技指标,科技指标和上面的一致。分别如表8、表9以及表10所示:
Table 8. The influence of original data and denoised data on DJIA dataset to the model
表8. DJIA数据集上原始数据与去噪数据对模型效果的影响
Table 9. The influence of original data and denoised data on HSI dataset to the model
表9. HSI数据集上原始数据与去噪数据对模型效果的影响
Table 10. The influence of original data and denoised data on DAX dataset to the model
表10. DAX数据集上原始数据与去噪数据对模型效果的影响
上面三表分别展示了在不同的数据集上,对构建的模型输入原始数据和去噪后数据对于模型最后表现结果的影响,从中可以看出,在DJIA数据集上,输入去噪后的数据来训练模型会让模型在除了AVOL指标上的所有指标都有更好地表现,在HSI数据集上,相较于原始数据,输入去噪后的数据能让模型有更好AVOL、MDD、CR和SOR,在DAX数据集上,输入去噪后的数据能让模型获得更好的ARR、ASR、CR以及SOR。上面的实验充分说明了使用去噪后的数据来训练智能体,能够让智能体获得更好的表现,说明了使用EWT来对数据进行去噪的有效性。
4. 结论
本文是要解决投资组合管理问题,针对该问题,使用了强化学习算法,具体使用了策略梯度方法,并沿用了AlphaStock的框架和建模方式。针对股价序列中存在着大量的噪声的问题,使用了属于信号处理算法一类的EWT经验小波变换来对股价序列进行去噪,选择相关系数0.05作为阈值,将分解出来的IMFs中与原始序列相关系数小于0.05的视为高频噪音,然后使用其余本征模态分量的进行重构。然后使用重构得到的收盘价序列构建科技指标,作为输入模型的特征。在网络结构上,使用TCN时间卷积网络来提取股票的时序特征,使用Multi-Attention多头注意力网络来提取股票的空间特征,然后经过全连接层和sigmoid函数获得每只股票的涨跌得分,之后输入softmax函数得到权重,然后让智能体根据权重进行交易。实验分别在DJIA、HSI以及DAX数据集上进行,对比模型选择了经典的交易策略以及强化学习智能体,使用了包含ARR、AVOL在内的六种指标对实验结果进行了评估。同时,也探究了输入原始数据和去噪后数据来训练智能体对于智能体最后表现结果的影响。实验证实了本文提出的EWT-PG模型的效果,能够有效应对风险,增强模型鲁棒性。
当然,对于股价序列也可以使用其他的信号处理算法,例如EMD、CEEMDAN算法来进行去噪。也可以重新给定投资组合管理问题的数学定义,使能够考虑更多的因素,例如交易对市场的影响,或是给出权重之后可能无法立即执行该动作的问题。也可以针对智能体所做出的动作进行解释,从而可以明白智能体为什么做出该决策。或者是采用其他的强化学习算法,重新设计网络结构,来提高投资组合管理任务的表现。