1. 引言
足球是世界第一大运动,有着广泛的收视群体,但一场足球比赛的时间较长,要从海量的视频数据中快速找到用户关注的内容,仅仅依靠传统的人工剪辑分类是十分困难的。早期的足球视频分类领域的研究主要是通过人工制定规则结合机器学习的方式来进行事件检测,此方法受制于人为设定的经验参数且不具备可扩展性。目前随着计算机视觉的发展,利用深度学习的方法处理足球视频问题已取得了重大进展。
在足球语义规则的处理上,传统的机器学习方法广泛应用于视频分类检测中,常见方法有支持向量机、贝叶斯网络、隐马尔可夫模型等,这些方法基于多种人工设定的特征进行场景分类,如图像特征、用颜色、纹理和形状等底层特征。此外,研究人员还常借助视频相关的文本、音频、回放镜头等多种信息形成多模态特征以实现事件的检测 [1] [2] [3]。Naveed等将混合特征用于模型训练,使用HOG、SIFT、LBP等作为训练系统的特征集 [4]。Pandya等提出一种基于精确边界预测的时序动作检测方法,以光流的变化来获取足球视频中的事件 [5]。
相较于传统的场景分类方法,深度学习能够通过一些简单模型将接收到的原始数据转化为更易于人类理解的语义特征,进而能够实现更有效的视频分类。针对深度学习在动作识别领域的研究,Ji等提出了一种在视频的时间和空间上卷积的三维卷积方式,将多个卷积层和下采样层串联构成动作识别网络 [6]。Song等结合视频帧序列和光流序列,利用I3D网络对视频单元进行分类,输出每个视频单元的预测概率值,在此基础上再利用分组方法将相邻的片段组合在一起以定位事件的边界 [7]。Cheng等采用3DCNN和CNN分别提取足球视频特征和音频特征,并进行多模态融合 [8]。文献 [9] [10] [11] [12] 针对动作检测问题分别提出新的CNN结构,使用CNN对动作类型进行识别,利用滑动窗口实现事件边界确定。
可见在足球视频处理中,CNN的卷积层能够很好地感知图像的局部特征,感知数据点与周围数据点之间的关系 [13]。但数据在CNN中只能单向流动且仅考虑每个时间步的当前输入,可能导致之前退化信息的丢失,而将CNN与RNN结合可以有效提取被CNN忽略的时序特征,提高特征提取的准确度。本文即是基于CNN-BiGRU网络训练了一个事件分类模型,实现足球赛事的视频片段分类。
2. 算法设计
视频事件类型识别以切分好的视频片段为研究对象,通过搭建不同神经网络(GoogleNet、ResNet50、VGG16)对准确率和召回率对比,最终选择VGG16对数据集中的视频片段的帧进行处理,提取出单帧的空间特征。使用双向循环神经网络BiGRU对特征序列提取动态信息,预测视频片段的事件类型,分类流程如图1所示。
图1中利用PySceneDetect检测切换镜头,然后将完整足球视频切分成片段,再根据预定义的事件类型将视频片段分类标记构建数据集,最后将数据集传入CNN-BiGRU网络训练事件分类模型。
2.1. 视频镜头切换检测
检测模型输入为足球视频片段,因此首先需要根据预先设定的事件类型将视频分割构建数据集,通过边界检测算法将视频中每个镜头的边界帧检测出来,然后再通过这些边界帧将完整的视频分割成一系列独立的镜头。
本文的边界检测利用改进的帧间插值法完成。算法将每个解码帧的颜色空间从RGB转换为HSV,根据前后两帧的视频数据,计算出它们不同的区域大小。如果区域尺寸大于某个预先设定的值,就认为场景已经切换。这里PySceneDetect工具利用了OpenCV中提供的阈值函数。帧间差分法流程如图2所示。
视频序列中第n帧和第n − 1帧图像记为fn和fn−1,两帧对应像素点的灰度值记为
和
,按照式(1)将两帧图像对应像素点的灰度值进行相减,并取其绝对值,得到差分图像Dn:
(1)
设定阈值T,按照式(2)逐个对像素点进行二值化处理,得到二值化图
,其中灰度值为255的点为镜头转换点,灰度值为0的点为非镜头转换点,对图像
进行连通性分析,最终可得到含有完整运动目标的图像Rn。
(2)
根据定义的事件类型通过人工的方法构建了一个包含射门、进球、点球、角球、黄牌、红牌的数据集,其中射门视频156个,进球视频64个,点球视频114个,角球视频129个,红/黄牌视频各107个。充足的数据集为事件分类模型做好准备。
2.2. CNN-BiGRU模型设计
事件类型识别以切分好的视频片段为研究对象,通过对视频单帧图像上空间特征的提取,以及对帧序列时间维度上动态信息的整合,完成视频片段的整体事件类型的识别。本文模型中单帧上空间特征的提取使用了CNN,特征序列动态信息的提取采用了基于LSTM的改进型循环神经网络BiGRU。
相比传统LSTM,GRU模型的门函数由3种减少为2种:更新门和重置门,虽然参数比LSTM更少,但却能够达到与LSTM相当的功能,且不存在LSTM中的细胞状态,可以显著提高训练效率。此外,由双向GRU (BiGRU)代替普通GRU,可以利用BiGRU的特有结构加强对时序序列的敏感程度,提高足球事件的预测准确率。CNN-BiGRU网络模型图如图3所示。
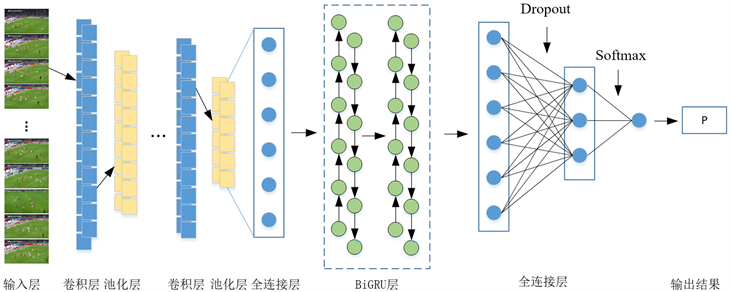
Figure 3. Network model graph of CNN-BiGRU
图3. CNN-BiGRU网络模型图
1) 输入层
在使用CNN-BiGRU网络训练时间分类模型的问题中,首先需要使用CNN提取单张图片特征信息,由于数据集中存储的均为已标记好的足球事件视频,因此需要对数据集进行预处理,对每个视频提取出视频帧序列,并存放在指定命名规则的文件夹中供后续训练模型使用。
2) CNN层
在特征提取网络的选择上,本文主要考虑了提取速度以及准确性两大因素,综合考虑了VGG、GoogleNet以及ResNet的优缺点。其中,VGG网络将多个较小的卷积核串联(卷积核中不插入池化层),以此关联与大卷集合相同面积的连接区域,如图4所示。由于大卷积层后只能使用一个非线性层,VGG将大卷积核拆分成多个小核卷积层,各个卷积层后能插入非线性层。通过增加整个网络的非线性处理单元,使得网络对特征的学习能力更强。此外,多个3 × 3的串联卷积层比一个大尺寸的卷积层拥有更少的网络参数。VGG共有A-E五种网络结构,每个网络都是由5个卷积组、2个4096维的全连接层和一个分类层组成,每段卷积组有2~3个卷积层。五个网络随着层数的增加识别准确率也逐渐增加,当深度达到16时效果有较大提升,因此本文中选VGG-16作为特征提取网络。
3) GRU层
GRU是循环神经网络RNN的一种。和LSTM一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的,其网络结构如图5所示。图中,GRU层的输出不仅和前一层的输入数据有关,而且还和上一时间步的输出有关,通过在同一层GRU单元之间建立有向连接赋予GRU对过去数据记忆能力。

Figure 4. Performance improvement principle of VGG
图4. VGG网络的性能提升原理
与GRU模型不同的是,BiGRU模型由前向GRU层和后向GRU层组成,因此可以在前向和后向两个方向上处理序列,两个方向均具有独立的隐藏层。BiGRU的网络结构如图6所示。
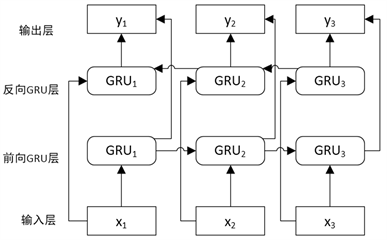
Figure 6. Network structure of BiGRU
图6. BiGRU的网络结构
这种结构可以使得每个GRU隐藏层在特定的时间步长内都可以同时捕获前向和后向的信息,因此可以提取出更加准确的足球特征信息,提升模型训练效果。
4) Dropout层
为了防止模型过拟合,本文引入了Dropout层。Dropout是神经网络最有效也最常用的正则化方法之一,它将深度神经网络模型作为一个集成的模型进行训练,然后将所有值取平均,而不只是训练单个模型。当一个神经元被丢弃时,无论输入以及相关参数是多少,它的输出值都会被设置0。
5) Flatten层
将最后的输出张量输入到一个密集连接分类器网络中,即Dense层的堆叠。由于分类器只可以处理1D向量,而当前的输出是3D张量,因此需要将3D输出展平为1D,然后在上面添加几个Dense层。Flatten层是用来对数组进行展平操作的,其作用是将多维的输入一维化,常用在卷积层到全连接层的过度。同时Flatten层不会影响batch_size的大小。
6) 损失函数
损失函数是反应模型在数据集上训练好坏的重要指标,其值与输出结果负相关。本文在架构中使用了交叉熵损失函数。
在训练BiGRU的过程中,使用softmax loss来对网络进行优化。对于一个输入事件样本片段
是该样本对应的事件类型标签,若该样本属于事件c,则yc = 1,否则yc = 0。网络在时刻t的损失计算如公式(3):
(3)
其中pt,c即为BiGRU在当前时刻t预测输入片段属于事件类型c的softmax概率。模型在每一个时刻t都进行反向传播,所以对于所有的训练样本
,总的损失为:
(4)
3. 实验分析
3.1. 实验环境
实验环境为Ubuntu17.0,处理器为Intel Core i9 12900k,运行内存16GB,GPU型号为Tesla V100,显存为16 GB。本文使用Keras框架来搭建模型,BiGRU结构的细节主要使用Keras工具箱实现,编程语言为Python。
3.2. 数据集
近些年来随着GPU算力的提高,有关动作以及体育视频类型的数据集越来越多,如规模较大的UCF101 [14] 包含13,320个视频,视频内容主要为单人事件。Sports-1M包含大约120万个视频,487种运动类型。此外文献 [15] 中NCAA提出了篮球数据集,包含了257个篮球视频,共分为11个篮球事件。目前在足球领域还没公开数据集,为此,本文从2018~2020赛季西甲、德甲、英超联赛收集数据并构建数据集,其中事件类型定义为5类,分别为射门、点球、角球、黄牌、红牌,其中射门视频156个,进球视频64个,点球视频114个,角球视频129个,红/黄牌视频各107个。训练集与验证集比例为7:3,数据来源如表1所示。
3.3. 训练过程
本文主要考虑了提取速度以及准确性两大因素,分别将VGG、BN-Inception、ResNet与BiGRU组建神经网络训练模型,并对比结果。训练时Batch样本数量设置为64,初始学习率为0.001,使用SGD更新网络参数,Epoch迭代周期为50,学习率每迭代完一个周期更新为当前的0.1。
由于本文构建的数据集有限,在采用BiGRU整合视频帧对应的特征序列并提取特征序列中包含的事件时,导致无法训练出能够泛化到新数据的模型,导致模型过拟合。为解决这一问题,首先在网络中进行数据增强,即是从现有的训练样本中生成更多的训练数据,利用多种能够生成可信图像的随机变换来增加样本,尽可能减少过拟合。为进一步降低过拟合,还需要向模型中添加一个Dropout层。
由于网络层数的增加会随着BiGRU层数的增加而增加,进而导致网络过拟合。因此dropout参数的设定以及BiGRU的层数对训练结果密切相关。BiGRU分别取1~3层,Dropout参数设置为0.1、0.2、0.3、0.4、0.5,共15种情况,实验结果如图7所示。
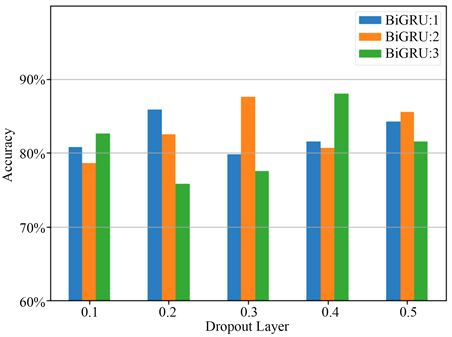
Figure 7. BiGRU layers and Dropout parameters
图7. BiGRU层数和Dropout参数
由图7可以看出,当Dropout参数和BiGRU层数分别设置为0.3,2和0.4,3的情况下模型的Accuracy最高,后者在数值上略高于前者;但随着BiGRU层数增多会增加训练成本,延长训练时间,因此BiGRU的层数设置为2,Dropout参数设置为0.3。模型的其他超参数设置如表2所示。

Table 2. Super parameters setting of CNN-BiGRU
表2. CNN-BiGRU模型超参数设置
3.4. 实验结论
在类型识别任务上,目前普遍使用的评测指标有查准率(Precision)、查全率率(Recall),如式(5)和式(6)。准确率和召回率的计算,一般需要先设定一个阈值,通过阈值对预测结果切分后计算准确率和召回率,不同的阈值对应的准确率和召回率不同。
(5)
(6)
本文主要考虑了提取速度以及准确性两大因素,分别将VGG、GooleNet、ResNet与BiGRU组建神经网络训练模型,并对比结果。在不同特征提取网络下的基于识别结果如表3所示。
可见在事件识别模型中,VGG-16的效果明显好于另外两个模型,因此选用VGG-16作为特征提取网络。
本文算法将足球视频事件定义为5类,从表3可以看出模型在对点球、角球、红/黄牌事件的准确率较高,这是因为角球及点球事件画面中有较为明显的球场边界特征区域,红/黄牌事件也有明显颜色卡片出现。表3也显示本文模型在比较复杂的进球视频的识别率上偏低,其主要原因是足球在视频帧图像中很小,且容易被球员遮挡,或者受制于拍摄角度当球门背景是场外的观众席时,白色的足球很容易跟背景混淆,难以判断球是否进门导致识别率偏低;其次,运动战进球和射门在感知上的差异仅仅在于球是否进入球门,不易做出判断;此外,VGG16在提取图片特征时产生的误差,后期可以通过完善训练样本和模型参数设计进一步提高识别率。
Table 3. Recognition results of event type
表3. 事件类型识别结果
4. 结语
对视频进行快速分类以满足不同观众的兴趣和爱好,是目前多媒体领域的研究重点。本文提出的足球视频场景分类算法,分别对视频的时间特征和空间特征进行了有效的提取,实现了比传统技术更好的精度和更快的速度,其中对点球以及红黄牌的识别率都达到了95%以上。由于GRU对不同长度的事件片段具有识别能力,下一步的工作计划是在事件类型识别模型的基础上,向BiGRU中加入边界确定模块,目的是当一段长视频传入模型时,模型具有独立判断事件边界并分类的功能。