1. 引言
人脸识别技术在国防安全、视频监控、逃犯追踪和身份认证等方面发挥着重要作用。近年来,“深度学习”一词蔓延到了众多领域,在人工智能领域(Artificial Intelligence, AI)中,我们理解的深度学习(Deep Learning, DL)是类似人脑结构的多层网络结构,其学习过程也高度模仿了人脑对事物认知的基本过程,通过某种指定方式的训练后,会像人脑一样对指定的事物进行计算、分辨判断和自我优化。深度学习在图像分类、目标检测和实例分割等任务中学习和优化 [1] ,在大量深度学习众多图片识别的网络架构里卷积神经网络 [2] (Convolutional Neural Network, CNN)是优选之一。在CNN架构中随着网络层的加深可以提取更多易于识别的特征信息,对普通网络(Plain Network)而言,随着CNN网络层数的加深,难以用优化的算法训练,并且其特有的网络性能也会逐步退化,其根本原因就是随网络层的加深,梯度也会逐步消失。为此,何凯明队在普通网络的基础上设计了残差网络 [3] (ResNets),在深层网络中加入残差设计,可以通过对残差块(Residual Block) [4] 做计算来优化网络性能,梯度消失问题得到了解决。
ResNets在过去几年是深度学习的首先网络,但是随着数据量的增加,ResNets也面临着通过加深网络层数来提高模型鲁棒性的挑战。近几年,随着自我注意力机制(Self-Attention) [5] 在自然语言处理(Natural Language Processing, NLP) [6] 领域中愈加火热,研究者们最终将Self-Attention的优势运用到计算机视觉(Computer Vision, CV) [7] ,研究出了远近交互性较强的一些网络模型(有:纯注意力模型的SANet [8] 和Axial-SASA [9] ,早期他们提出Self-Attention可以作为卷积模块的增强,以及另一种方向混合注意力模型的AA-ResNet [10] 和BotNet [11] 是将CNN与Self-attention结合在单个块内),本文提出了一个新观点也属于混合注意力网络模型(Hybrid Self-Attention Net, HSANet):用Self-Attention替换ResNet50 Blotteneck块的
,并将块内
放在了Identity连接上,再把Relu激活函数移到快外,重造了结构类似于Blotteneck块的混合型Self-Attention块。
2. 相关知识
2.1. CNN存在问题
适于监督学习的大多数CNN模型,面临着海量数据和捕获卷积长距离交互挑战,最初对于这些困难,CNNs是通过加深网络层数,来获得更细微的特征。CNNs做卷积操作时,卷积后的每个独立像素之间与其边围的像素存在着一定的关联度,用于卷积操作的过滤器(Filter)只能提取局部信息,通过更多层的层卷积操作后才能将图像各区域的特征关联起来。
2.2. 残差结构介绍
残差块(Residual Block)是加深残差网络层的关键,快捷连接(Shortcut Connections) [12] 和恒等映射(Identity Mapping) [13] 是残差块的灵魂,其中恒等映射是加深网络层的核心,残差结构至少由两个残差块堆叠而成。为节省计算复杂度,将原先残差结构,如图1的两个3 × 3的卷积层,用图2的
的卷积层替换,其中两个
分别完成维度压缩和还原维度的工作,因而避免了梯度的消失,让深层网络的性能得到了质的飞跃。如图2所示的结构,称其为瓶颈(Bottleneck)结构,这种残差结构实现了通道数的先减少再增加。
恒等映射最终目标是尽量让输出与输入相近 [14] ,即公式(1)所示是恒等映射工作原理,公式(2)的3个分式所示是对恒等映射的最终目标的分步解释。
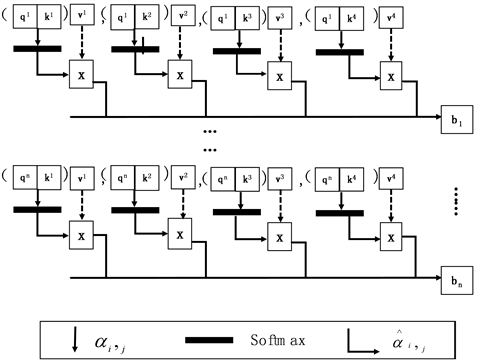
Figure 3. Self-attention mechanism workflow summary
图3. 自我注意力机制工作流程概括
(1)
(2-1)
(2-2)
(2-3)
在上式(1),(2-1)至(2-3)中x表示输入,
表示经过卷积操作后的输出也是下一个卷积的输入,
是最终的输出,上文提过恒等映射是恒是
,实际上我们只能逼近恒等映射,在学习过程参数量会有所消耗,因此最终目的不是让
,而让其逼近零。
2.3. 注意力机制
相比CNNs的短距离捕获信息,模拟人类注意力的注意力机制模型,可以更高效的捕捉长距离信息之间的关联度 [15] 。在深度学习里,注意力机制旨在从全局信息中筛选更具特色的信息,从而过滤无用信息。如公式(3)~(8)是自我注意力机制得主要工作原理。如图3所示是自我注意力机制工作流程概括。
(3)
(4)
(5)
(6-1)
(6-2)
(6-3)
(7)
(8)
Self-Attention是基于查询向量Query (可用Q或q表示)、键向量Key (可用K或k表示)和值Value向量(可用V或v表示)三个变量计算像素间的关联度。公式(3)是输入向量
与变换矩阵
相乘得到
,(4)和(5)与式(3)同理。通过公式(6)计算和之间点乘计算相关性
,并除以
来平衡梯度(
是缩放因子),经过公式(7) Softmax归一化操作后的
最终与v点乘,得到加权和的表示,依次累计操作得到公式(8)的作为位置关联度的
。
3. 实验
3.1. 数据准备
用python对内娱网进行合法爬虫,批量下载明星图片(共26位明星,其中男12人,女14人,每人有10多张,共283张,还有一些在整容网上已公开的人脸图片共378张)。设置尺寸为224 px × 224 px,确保每张人脸图像是彩色(通道为RGB)的,对收集好的图片进行数据清洗,每个类以人名命名,最终生成较干净的数据集。因该实验数据集较小,将生成的数据集图片按8:2划分为训练集和测验集,通过训练得到的特征信息保存至Log文件里。
超参设置:使用交叉熵损失函数,让学习率衰减方式初始为lr = 0.005,alpha = 0.25,expansion = 4,并以batch_size为4训练50个epoch。通过数据增强对数据集图片进行随机裁剪、随机左右翻转和通过对图片进行遮挡,降低特征间的关联度,加强微整容特征变化程度。以防模型过拟合。
针对小样本微整容数据集的块内混合注意力模型HSANet受Bottleneck Transformer启发,从以下两方面做出了改进:1) 将ResNet50 Bottleneck中的3 × 3卷积替换成Self-Attention;2) Identity连接上的x替换成3 × 3卷积。如图4所示的是改进后的混合型自注意力单元块工作原理。
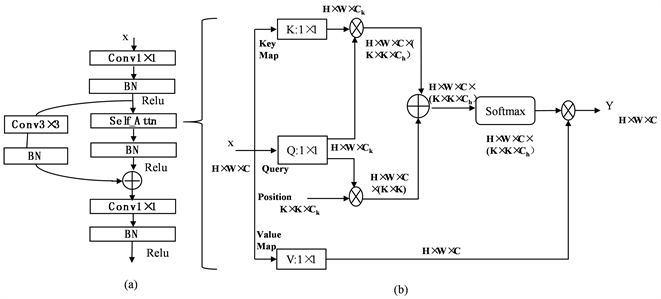
Figure 4. Working principle of hybrid self-attention block
图4. 混合型自注意力单元块工作原理
首先在图4左半(a)部分,输入在线性块内
后,其输出进入Self-Attention中,同时
后的输出进入Identity连接的
,Identity连接跨Self-Attention层后,与线性残差块内Self-Attention的输出进行和操作后,结果再输送到
卷积,对最后的输出进行Relu激活函数。如图4右半(b)部分,其原理和图4所述相差无几。经过线性块内
后得输出特征图x:
,
是卷积后压缩得到的图,C是通道,x进入Self-Attention机制,将k与q相乘可得局部相关矩阵
记为
,
为头部编号,每个
网格的相对位置Position(P)与q矩阵相乘结果是每个像素的位置信息,接下来
与每个像素的位置信息进行和操作后,在每个
通道维度上进行 Softmax 操作得注意力矩阵A,是重塑每个像素的空间信息为
个局部注意力矩阵,A与V聚合后最终得Y。在CV中Self-Attention关注像素位置之间的关联性。
在Identity连接上设置
的优势在于,Identity连接上
与BN可以维Bottleneck块结构。用Self-Attention替换线性网络中残差块内
,等同于用一个向量组完成多个一维向量的工作,降低对低关联特征的关注,因此会提高对高关联度信息的注意。
该实验模型通过改进ResNet50直筒网络的残差块差块和连接,在残差块内用自我注意力块替换
的Identity连接,得到新的混合型自我注意力块为HSANet。
3.2. 实验结果
为了验证混合型自我注意力方法在小样本微整容数据集上的识别效果,使用现有网络模型ResNet50和改进后的网络模型HSANet(x)以及HSANet (3 × 3) (两种对比混合模型Identity连接上的参数设置分别是x和
) 3种网络模型进行了对比,用于训练3种网络的超参数设置一致且训练过程相同。如图5~8所示小样本微整容数据集上分别在ResNet50、HSANet(x)和HSANet (3 × 3)上的识别效果。

Figure 5. Loss comparison diagram of training set
图5. 训练集的损失对比图
图5中纵坐标tr-loss表示训练集损失,横坐标epoch,图中曲线R-tr-loss表示ResNet50的训练损失,Mx-tr-loss表示Identity连接是x的自我注意力混合模型的训练损失,M-tr-loss表示Identity连接是3 × 3的自我注意力混合模型的训练损失。从图6中的前20个epoch可以看到M-tr-loss曲线的损失下降快,后30个epoch中M-tr-loss的损失存在较小的梯度。
图6中纵坐标tr-acc表示训练集正确识别率,横坐标是epoch,图中曲线R-tr-acc表示ResNet50的正确识别率,Mx-tr-acc表示Identity连接是x的自我注意力混合模型训练正确识别率,M-tr-acc表示Identity连接是3 × 3的自我注意力混合模型训练正确识别率。在图中前20个epoch可以发现混合模型HSANet (3 × 3)和HSANet (x)正确识别率(acc)上升速度快并且正确识别率高,其中M-tr-acc (即Identity连接是3 × 3的自我注意力混合模型)的正确识别率稳居最高。三个网络模型的平均正确识别率(Avg acc)和最高正确识别率分(Max acc)为:R-tr-acc的Avg acc是89.0350%,Max acc是98.1418% ,Mx-tr-acc的Avg acc是91.7801%,Max acc是98.7654%,M-tr-acc Avg acc是94.4301%,Max acc是98.7757%。
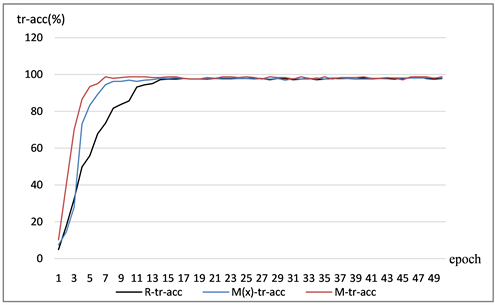
Figure 6. Comparison graph of correct recognition rate of training set
图6. 训练集正确识别率对比图

Figure 7. Loss function comparison diagram of verification set
图7. 验证集的损失函数对比图
图7中纵坐标是val-loss表示验证集损失,横坐标是epoch,在其前20个epoch可以发现混合模型(Mx-val-loss和M-val-loss的混合型自我注意力模型)损失函数下降速度快,在后10个epoch中相对于其他2个损失函数,M-val-loss (即Identity连接是3 × 3的自我注意力混合模型)损失是最低的。
图8中纵坐标是val-acc表示验证集正确识别率,横坐标是epoch,其前12个epoch可以发现混合模型(Mx-val-loss和M-val-loss的混合型自我注意力模型)正确识别率(acc)上升速度快并且正确识别率高,其中M-val-loss (即Identity连接是3 × 3的自我注意力混合模型)的正确识别率上升速度最快且最高。R-val-acc的Avg acc是66.8275%,Max acc是87.0270%,M-val-acc 的Avg acc是72.1407%,Max acc是88.6486%,Mx-val-acc的Avg acc是76.0003%,Max acc是89.7011%。从图6~8,可以发现HSANet (3 × 3)的损失和正确识别率是3种网络中最理想的。
用模型评估指标f1-score、macor avg和weight avg,在小样本微整容图片数据集上进行经多次对照实验,对比3种网络模型模型训练的结果。试验结果表明在此数据集上,HSANet (3 × 3)的各项指标较高,如表1是在微整容数据集上对比三种网络性能。

Figure 8. Verification set correct recognition rate comparison graph
图8. 验证集正确识别率对比图

Table 1. Three kinds of network performance
表1. 三种网络的性能
为了说明该实验为何在Identity连接上用3 × 3卷积,先用改进得到得混合型自注意力块HSANet (x)做对比,在该实验数据集上HSANet (3 × 3)网络性能优于HSANet (x),选用现有的ResNet50和改进后的HSANet (x)进行对照,在表1中f1-score为f1分数是衡量二分类模型精确度的一种指标 [16] ,即模型精确率和召回率的一种加权平均,macor avg为宏平均是所有类的平均精准;weight avg为加权平均对宏平均的一种改进,考虑每个类别样本数量在总样本中占比精准加权,评估模型性能的值越高表示网络模型性能越好 [17] ,3种网络模型里HSANet (3 × 3)的3项指标都明显高于其他2种网络模型。
可以发现,在ResNet50的Bottleneck中加入Self-Attention的时候,表现出更好的效果。2组对照实验中,HSANet (3 × 3)内存及参数量相比ResNet50和HSANet (x)多。如表2是三种网络模型在微整容数据集上的基准方法。
Table 2. Benchmark methods of the three networks
表2. 三种网络的基准方法
4. 总结
针对微整容导致影响身份识别的问题,本文自制了微整容小样本图片数据集,本文创新点如下两点:
1) 制作26类微整容人脸图片数据集。
2) 构建HSANet (3 × 3)混合型自我注意力网络模型。
HSANet (3 × 3)是受Bottleneck Transformer启发,在ResNet50的Bottleneck改进的混合型自我注意力块。HSANet (3 × 3)模型在Bottleneck块中将卷积与Self-Attention结合,并将Identity连接上的1 × 1改为3 × 3的卷积,为了与此作比较保留了HSANet (x) Identity连接的默认值(即1 × 1卷积),在Identity连接上设置
与BN可以将输出连接至线性网络中的Bottleneck块,实现了块内自我注意力输出的高联特征,与连接捕获的局部特征的结合,提高模型对局部和全局信息的捕获能力。
虽然本文提出的混合型自我注意力模型,对微整容小样本图片数据集具有较高的识别能力,也有较好的特征捕获和识别能力,同时为之付出了相应的内存。为此,接下来微整容人脸识别工作的主要任务是在稳定提高正确识别率的前提下,减少模型空间成本,进一步提升网络性能。
基金项目
国家自然科学基金项目(62141206);新疆自然科学基金项目(2019D01C337);伊犁师范大学'学实高层次人才岗位(YSXSJS22002);伊犁师范大学博士科研启动项(2020YSBS005)。
参考文献
NOTES
*通讯作者。