1. 引言
挥发性有机物(Volatile organic compounds, VOCs)作为工业迅速发展的副产品,危害环境空气健康,降低人类生活质量 [1] 。VOCs是指常态下易挥发的有机化合物,主要包括非甲烷烃类,含氧有机物,含氮有机物,含硫有机物等,具体有烷烃、烯烃、芳香烃、卤代烃、醇、酮、醛、醚、酯、硫化物及杂环等 [2] 。VOCs涉及行业众多,如机动车制造于维修、涂料生产、家具、家用电器、金属制品加工、彩钢板、集装箱、造船、电器设备印刷等 [3] 。VOCs检测存在易挥发、难定量、不易监督的问题,众多工厂为降低成本,违规排放。土壤中VOCs的主要来源是人类活动,如石化、化工、交通、燃烧、居民生活等 [4] 。土壤复杂的三相共存体系和VOCs的吸附性导致VOCs更易隐藏,不能被及时发现 [5] 。目前,VOCs治理难问题主要体现在以下几方面:VOCs来源广,大至工厂排放,小至办公用品等都是元凶;范围大,仅仅化工企业关闭搬迁造成的废弃地面积远超50万公顷;危害多,生态环境危害和人体健康损伤。VOCs常用的采样方法有袋采样,罐采样,吸附剂采样和固相萃取技术等 [6] 。常规的挥发性有机物检测方法有:气相色谱法,液相色谱法等 [7] 。
太赫兹(Terahertz, THz)指位于0.1~10 THz范围内的电磁波,介于微波和红外之间,具有光子能量低、波长短、穿透性好等特点,同时依靠氢键和范德华力等分子内和分子间振动可以激发分子对太赫兹波的吸收,传递丰富的信息 [8] 。太赫兹检测成为检测的新型“武器”,引起了众多领域研究者的关注。然而,如果样品的厚度远小于太赫兹的波长时,光与物质相互作用将会很弱,导致不同VOC液体之间的太赫兹光谱特性差别不大,这也意味着三种挥发性有机物(含氧、含氮及含硫)溶液之间的太赫兹吸收差异不再显著。此外,由于极性液体吸收较强,挥发性有机物之间的吸收系数差异并不显著。增强光–物质相互作用需要增强光与物质的耦合作用。目前,增强光–物质的耦合作用依靠超材料传感器,如吸收器,石墨烯,谐振环等方法 [9] [10] [11] 。也就是说,通过对电磁场的强限制来增强太赫兹区域内的光–物质相互作用的技术是非常可取的。
在本文中,我们通过研究三种在土壤中的挥发性有机物:异丙醇(isopropanol, IPA)、乙酸乙酯(ethyl acetate, EA)和乙苯(ethyl benzene, EB),探讨了太赫兹超表面芯片在腔体中的应用。超表面结构由带缺口的圆环构成,电场主要集中在开口间隙,Fano共振处的大强度表面电流有助于增强所提超表面中开口间隙处的电场限制,从而增强光与物质之间的相互作用,同时提高了超表面的灵敏度。腔体结构达到密封条件,超材料进行环境检测,二者相互辅助实现对土壤中三种挥发性物质异丙醇、乙酸乙酯、乙苯含量的检测。分析三种物质不同含量时太赫兹透射光谱的变化,再结合数据分析拟合与支持向量机(Support Vector Machine, SVM)分类算法96.7%的分类效果。基于主成分分析的高斯混合模型(Gaussian Mixture Model based on Principal Component Analysis, PCA-GMM)算法对三种物质达到95%的置信度,而且可由等高线判断各样点在区域内出现的概率。本工作对扩大太赫兹检测器件的在污染物检测应用领域,有效鉴别挥发性有机物种类和排放含量,对工业区排放标准不达标的工厂及时进行溯源及责任追究,减少有机物排放对土壤的损伤有一定帮助。
2. 实验方法与进程
2.1. 化学试剂选购及样品制备
实验所用的化学试剂乙醇(货号E111977)、异丙醇(货号I292350)、乙酸乙酯(货号E116138)、乙苯(货号E117365)购置于阿拉丁公司,按照药品使用说明妥善保存。具体的实验样本制备方式如下:从校园教学楼前的花坛获取实验中的土壤;在烘干箱(博迅BG2-30)以100℃烘两小时,干燥土壤,并排除土壤中微生物对实验的影响;将烘干后的土壤放入玛瑙岩体中研磨成小粉末,筛出小于60目的土壤颗粒;制作的分析样品分为三大组,每组有60个,每组分为6小组,每个小组有10个,共180个分析样品。每个分析样品含有10 g土壤颗粒,每小组中的分析样品用滴定管分别加入1、2、3、4、5、6 μL的异丙醇、乙酸乙酯、乙苯,用凡士林和聚四氟乙烯膜封口,减少挥发,放置24小时。根据相似相溶原理,加入乙醇提取液,加热水浴振荡6小时,将土壤中的三种有机物溶解在乙醇中。处理完毕后,通过离心机,在30,000 r/min的离心速度下离心10 min实现固液分离。静置后取出上清液放置在试管中,依旧用凡士林和聚四氟乙烯膜封口,防止挥发。
2.2. 实验装置与操作
如图1(a)所示,实验检测装置为日本爱德万(ADVANTEST)测试公司的TAS7500SU系统(Tera- hertz Spectroscopic System 7500SU)。该装置是一台桌面太赫兹脉冲波光谱测量与分析系统,采用Cherenkov太赫兹源,有效光谱范围为0.5~7 THz。它不仅可以测量固体和液体样本,而且可以更换模块选择透射、反射、衰减全反射三种测量模式,空气净化和去除水蒸气干扰能力强,动态范围约为50 dB。
实验中所用样品均为易挥发物质,选用腔体结构作为容器,有效避免有机物挥发对实验结果造成影响。该腔体结构由介电常数1.88的聚四氟乙烯制成,设置高50 μm的中空结构放置超表面芯片和添加待测液体,如图1(b)和图1(c)所示。
在采样时间为8 ms,分辨率为7.9 GHz的情况下,对1024个采样点累计平均得到测量结果。实验操作过程对每个分析样品进行测试,用乙醇清洗超表面芯片和腔体结构后,去离子水超声波震荡,取出后用无尘布擦干,避免上次测量残留物影响实验效果。实验在室温下进行,为避免水汽干扰,环境湿度控超表面芯片表面不添加任何物质,测得的时域信号经过傅里叶变换,可表示为公式(1)
(1)

Figure 1. Main apparatus in the experiment. (a) TAS7500SU; (b) (c) Cavity structure
图1. 主要实验装置图。(a) TAS7500SU;(b) (c) 谐振腔
当超表面芯片表面添加待测物质时,测得的时域信号经过傅里叶变换,可表示为公式(2)
(2)
这里,
是参考信号电场,
是参考信号幅值强度,
是样本信号电场,
是参考信号幅值,t是时间,
是相位,
是频率。
由于异丙醇、乙酸乙酯、乙苯在太赫兹波段没有明显的吸收峰,超表面芯片在太赫兹光谱下形成的两个吸收峰是本文的主要着眼点,将添加两个待测物峰值点的频率偏移量记为
,和
,强度变化量表示为
和
。
3. 实验结果分析
利用Matlab2016编写程序对180组数据的两个频点峰值和强度进行批量提取,并求出异丙醇,乙酸乙酯,乙苯三种物质同一物质的量测量的十组数据频率偏移量
和
,强度变化量
和
,分别平均后得到的平均值作为这一物质的量下的有效值,减少实验过程中可能存在的误差对实验结果的影响。最后,三种物质的频率偏移量
,和
和强度变化量
和
与其物质的量分别采用适宜的拟合方式拟合,并标出误差条。此后,利用Classification Learner计算出多种常用分类算法的准确率,混淆矩阵以及ROC和AUC值,评估最佳算法后进行进一步优化,实现物质的定性分析,并结合前期的拟合结果,实现对物质的定量求解。
3.1. 超材料芯片
采用CST STUDIODU SUITE (2017版)电磁仿真软件设计了一种基于狄拉克半金属薄膜的Fano响应的超表面设计,单元结构示意图如图2所示。超表面结构由两部分组成:1) 聚酰亚胺衬底,介电常数为3.5 + 0.0027i,厚度h = 25 μm;2)表面不对称开口谐振环,材质为铝,电导率为3.56 × 107 S/m,厚度为t = 200 nm。具体的结构参数:单元结构长Px/2 = 70 μm,宽Py/2 = 70 μm,圆环外环半径R = 30 μm,内环半径r = 24 μm,圆环宽度G = 3 μm,开口中心距圆心距离,即不对称参数d = 13 μm。

Figure 2. Schematic of Fano super-surface structure. (a) Stereogram; (b) Plan; (c) Optical microscopy 500×
图2. 超表面芯片结构。(a) 示意图;(b) 平面图;(c) 光学显微镜500×放大图
3.2. 单变量分析结果
为定量测定18个样品(1~6 μL/10g土壤)中的微量有机物(IPA、EA、EB),分析了不同含量有机物对Fano超表面芯片传感器的光谱频移∆f和吸收强度变化(∆M),结果如图3(a)~(c)所示。随着VOC含量的增加,频率发生红移,幅值也明显变化,建立光谱的单变量回归模型。IPA的频移采用ExpGro2 Fit方式拟合,拟合情况如图3(d)所示:在0.885 THz,R2 = 0.963,∆f位于0.05~0.10 THz;在1.778 THz,R2 = 0.963,∆f位于0.07~0.18 THz。EA的频移采用Asymptotic1 Fit方式拟合,拟合情况如图3(e)所示:在0.885 THz,R2 = 0.927,∆f位于0.04~0.10 THz,在1.778 THz,R2 = 0.974,∆f位于0.06~0.16 THz。EB的频移采用Polynomial Fit方式拟合,拟合情况如图3(f)所示:在0.885 THz,R2 = 0.920,∆f位于0.08~0.10 THz;在1.778 THz,R2 = 0.865,∆f位于0.13~0.18 THz。IPA的幅值变化采用ExpGro2 Fit方式拟合,拟合情况如图3(g)所示:在0.885THz,R2 = 0.982,∆M位于0.10~0.18 (a.u.);在1.778 THz,R2 = 0.983,∆M位于0.08~0.16 (a.u.)。EA的幅值变化采用Asymptotic1 Fit方式拟合,拟合情况如图3(h)所示:在0.885 THz时,R2 = 0.950,∆M位于0.12~0.18 (a.u.);在1.778 THz时,R2 = 0.944,∆M位于0.08~0.14 THz。EA的幅值变化采用Linear Fit方式拟合,拟合情况如图3(h)所示:在0.885 THz时,R2 = 0.973,∆M位于0.06~0.14 (a.u.);在1.778 THz时,R2 = 0.869,∆M位于0.04~0.10 (a.u.)。
综合IPA,EA,EB的∆f拟合曲线和∆M拟合曲线发现,当土壤中添加较少VOC时,土壤中残留的VOC占添加总量的比例较大,更易对实验结果造成影响,导致误差条偏大。但是∆f和∆M的拟合度极高,而IPA、EA、EB的拟合方式不同,所以有希望通过∆f和∆M拟合关系构建IPA、EA和EB特定的“后天指纹”,并通过“后天指纹”进行不同物质的定性鉴别。
3.3. 算法筛选
算法性能好坏需要量化的数据进行评估,本节选用混淆矩阵,准确率,ROC和AUC,混淆矩阵是将分类预测模型的预测结果集中记录并展现的表格,因此常用作机器学习的辅助工具。多分类任务的混淆矩阵可用公式(3)描述
(3)
即假设有n类物质,可分别用
,
表示实际与预测相符的样本量,而
表示预测时将实际属于
的归为
的样本量。

Figure 3. Univariate fit results. (a)~(c) The THz Spectra, (d)~(f) frequency shift response and (g)~(i) amplitude shift response corresponding to 6 VOC concentration used for the detection of IPA, EA, EB, respectively
图3. 单变量拟合的结果:(a)~(c)分别用于检测IPA、EA、EB的6个VOC浓度对应的THz光谱;(d)~(f) 频移响应和(g)~(i)振幅位移响应
混淆矩阵中,实际数值分为positive和negative,预测结果也分为positive和negative,得到四个基础指标:True Positive (TP)、False Negative (FN)、False Positive (FP)、True Negative (TN)。TP表示正确检测的样品数;FP表示错误但检测正确的样品数;FN表示错误检测为错误的样品数;TN表示错误检测为正确的样品数。
准确率被正确分类的结果占比概率,可以用公式(4)描述:
(4)
检测率(True Positive Rate)表示可识别的TP与正实例的比例,可以用公式(5)描述:
(5)
误检率(False Positive Rate)表示识别的FP与负实例的比例,可以用公式(6)描述:
(6)
Receiver operating characteristic curve (ROC)是验证概率模型质量的重要手段,ROC曲线上的点代表这不同阈值下的分类效果,横坐标表示FPR,纵坐标表示TPR,而the area under the curve (AUC)是指ROC曲线与x轴所围的面积,在分类器的性能评估中起主导作用,AUC的值位于0~1之间,且AUC越接近于1,分类器的性能越好。首先,选择频域信号中的共振峰1的频点和强度值,共振峰2的频点的和强度值,土壤中EB、IPA、EA的含量五个变量作为原始自变量,物质分类作为因变量,构成一个180 × 6的矩阵X。

Table 1. ACC comparison of kinds of classification
表1. 各种分类器的比较
分类预测算法分为非监督学习和监督学习,本文中先采用Matlab2016中的Classification Learner App对180组数据进行监督学习预测,初步筛选效果较好的算法进行优化。监督学习的过程中给180组数据按照5:1的比例分配到测试集和验证集,即测试集为150组,验证集30组,采用五折交叉验证,具体涉及的监督学习方法有决策树(Decision Tree, DC)、判别分析(Discriminant Analysis, DA)、支持向量机(Support Vector Machines, SVM)、K最邻近算法(K-Nearest Neighbor, KNN)、集成算法(Ensemble)五大类,共计22个小分类。将ACC罗列在表1,预测准确率最高的分类算法为Cubic SVM (Model 1.8)、Fine Gaussian SVM (Model 1.9)和Fine KNN (Model 1.12),最高预测准确率为91.7%,预测准确率最低的分类算法为Linear Discriminant (Model 1.4)和Linear SVM (Model 1.6),最低预测准确率为60%。
混淆矩阵是评估分类器优劣的较可信的指标,选择准确度较高的六种分类模型绘制出混淆矩阵进行综合评估,如图4所示:混淆矩阵表中,1代表乙苯,2代表异丙醇,3代表乙酸乙酯。图4(a)中Complex Tree (Model 1.1)第一行中出现准确度和为101%的情况,是由于再计算准确率的时候四舍五入造成的,每一个三维混淆矩阵中对角线位置处代表某一类物质的预测正确率,对比六个模型的混淆矩阵发现,只有图4(c)中Cubic SVM (Model 1.8)对三种物质的预测正确率都在90%以上,而图4(e)中Fine KNN(Model 1.12)虽然对乙苯的预测正确率高达100%,但是对异丙醇的预测正确率只有83%。图4(b)中Quadratic Discriminant (Model 1.5)可信度极低,Cubic SVM (Model 1.8)较高且稳定的正确率在六个模型中崭露头角。

Figure 4. Confusion matrix of better classifiers
图4. 较优分类器的混淆算法
六种模型的AUC值均在0.90以上,图5(b)中Quadratic Discriminant (Model 1.5)的表现最差,仅有0.90,图5(d) Fine Gaussian SVM (Model 1.9)和图5(f) Bagged Trees Ensemble (Model 1.19)表现最好,高达1.00,接近完美,其余三种模型均为0.99,除了Quadratic Discriminant (Model 1.5)外,其他模型的AUC值不相上下,且均呈现出较高的可靠性。
综合模型的准确率、混淆矩阵和ROC曲线,可以明显地比较出Cubic SVM (Model 1.8)在多方面的表现都很优异,准确率91.7%,对IPA、EA和EB的预测正确率分别为90%、93%和92%,非线性SVM模型确定为针对本分类问题的最优算法,加以改进,以得到更优越的表现。
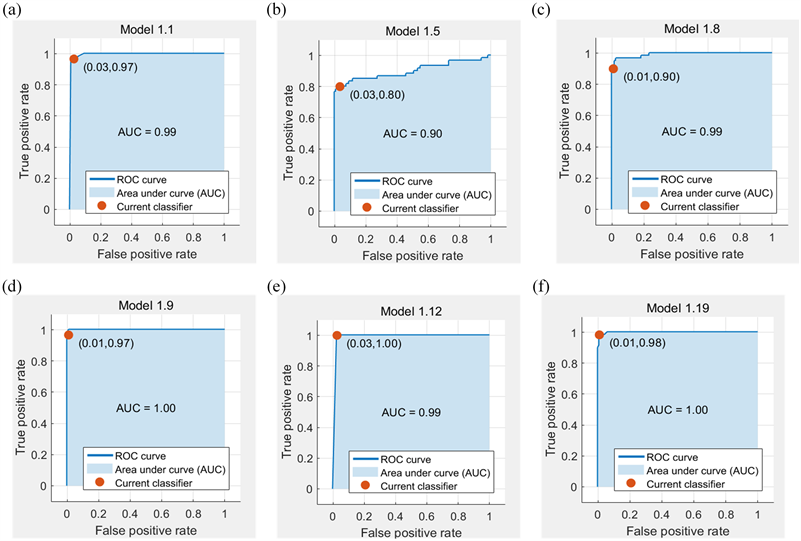
Figure 5. ROC and AUC of better classifiers
图5. 较优分类器的ROC和AUC值
SVM是在统计方法的基础上寻找分离两类的最优超平面 [12] 。假设初始因素变量为
,分类变量(EB, IPA, EA)为
,可用公式(6)表示:
(7)
c为超平面原点的偏移量,n为影响分类结果的因素量,
是正实数,
为核函数,核函数可替换目标函数与分类决策函数中实例间的内积,得到非线性支持向量机,使SVM可应用高维特征空间,核函数类型如表2所示。
核函数使用最广泛的是多项式核和高斯核,其中的d为多项式阶数,
是高斯核宽度的预定义参数。经过探索将SVM的设置为多分类C-SVC模式,核函数采用RBF,在五折交叉验证中,如图6所示,AUC值达到0.99,预测结果仅出现一例IPA预测为 EA的情况,预测正确率达到96.7%。
PCA是数理统计中常用的降低数据维度的方法 [13] ,将降低维度后的结果用作协变量,可减少各原始变量的之间的关联造成的假阳性,同时可通过置信区间判断各种类之间的相似性。
如图7所示,通过PCA算法,将5个原始变量转化为两个主要影响变量PC1和PC2,PC1占比54.5%,PC2占比28.0%,两者的和为82.2%,可有效代替原始变量。图中圆圈内的区域代表不同种类在95%的置信区间时的分布,可见EB与IPA和EA的相似性相对较低,更易区分,而IPA和EA的分布高度重合,在实际分类时容易犯错,仅仅依靠PCA无法有效分类,可能原因是对于小分子有机物,碳链结构和苯环对吸收系数的影响大于官能团对吸收系数的影响。
Table 2. The common Kernel function
表2. 常见的核函数

Figure 6. SVM predict results: (a) ROC; (b) Actual and predict difference; (c) Confusion matrix
图6. SVM预测结果:(a) ROC;(b) 实际与预测结果图;(c) 混淆矩阵
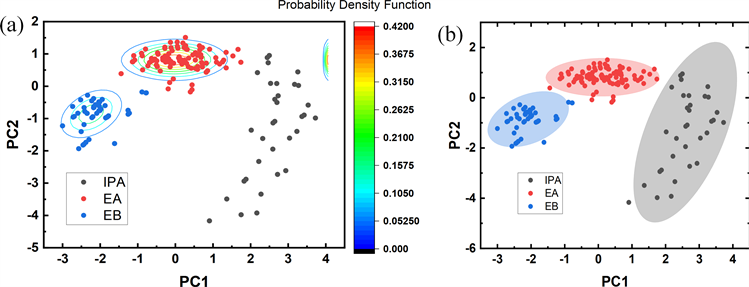
Figure 8. PCA-GMM (a) Contour map; (b) Confidence Interval
图8. PCA-GMM (a) 等高线图;(b) 置信区间
高斯混合模型(Gaussian Mixture Model, GMM)通过迭代求出模型中高斯分布的似然函数收敛,判断某个点属于某个类的概率大小进行聚类 [14] 。EM算法可有效求解存在隐含变量优化的问题。采用PCA降低数据维度后,结合EM方法拟合高斯混合模型,通过EA将似然函数取得最大值的参数值用作参数估计,代入GMM的极大似然函数,计算概率密度函数以及按后验概率对测试数据进行分类,并通过BIC找到最佳模型,绘制出等值线图和置信区间。分类结果如图8(a)所示,EA和EB实现了有效分离,在95%的置信区间内绘制的概率密度函数等高线图中,置信区间由内而外可观察到各分类的出现概率逐步降低,而IPA等高线虽然并不明显,图8(b)的置信区间图中也实现了有效分离,可视化效果更佳。
4. 结论
本文针对VOC物质在土壤中含量少、检测难的问题,采用Fano超表面设计的共振峰频移和强度变化进行拟合,构建了太赫兹波段IPA、EA和EB的“后天指纹”。在“后天指纹”的构造过程中,采用classification Learner对分类方法进行与选择,考虑到准确度、ROC曲线和AUC值,以及混淆矩阵三方面的表现,从22个常用算法中选择非线性SVM作为分类方式,参数寻优后达到96.7%的预测正确率。同时,还选用PCA-GMM的方式,对IPA、EA和EB的分类情况精准描绘,运用等高线辅助判断样点出现概率,为VOCs物质检测方式提供了新的思路。
NOTES
*通讯作者。