1. 引言
目前,传统垃圾焚烧和回收主要操作是通过垃圾回收站的操作工人对垃圾进行手动分拣及垃圾抓取至待焚烧区域。这样不仅增加了劳动成本,同时操作工人需要凭借经验判断,不利于垃圾充分燃烧,因此,本文采用一种基于深度学习目标检测的YOLOv7算法解决了传统垃圾检测存在的问题。
目标检测(Object Detection)作为计算机视觉领域的核心问题之一,其任务是在图像或图像序列中对目标进行精确定位和分类。但目标检测任务中存在各类干扰因素,如目标物体本身的纹理、形态等,以及成像时的光照强弱、遮挡和模糊等。基于上述因素,目标检测性能成为计算机视觉领域亟待解决的问题,针对这些因素,众多学者对目标检测算法进行了研究与改进。One-Stage目标检测算法不单独选取候选区域,省略了候选区域生成步骤,将特征提取、目标分类和位置回归整合到一个阶段进行操作,代表算法有YOLO系列、SSD系列、RetinaNet、CornerNet、EfficientDet等 [1] ,下面将分别进行介绍和分析。Two-Stage目标检测算法先对图像进行选取候选区域操作,再对候选区域进行分类和位置定位,使检测过程划分为两个阶段,代表算法有R-CNN (Regions Convolutional Neural Network)、Fast R-CNN、Faster R-CNN、Cascade R-CNN等,下面将分别进行介绍和分析。
针对以上问题,本文提出了一种基于YOLOv7的目标检测算法,针对实时垃圾检测及抓取算法。具体工作包括如下:1) 自建一个关于实时垃圾及吊车夹爪数据集;2) 基于YOLOv7算法对垃圾和夹爪进行实时检测。
2. YOLOv7的网络结构
2.1. 扩展的高效层聚合网络
在大多数关于设计高效架构的文献中,主要考虑的因素不外乎是参数的数量、计算量和计算密度。Bello等人 [2] 从内存访问成本的特点出发,分析了输入/输出通道比、架构的分支数和元素的操作对网络的影响、架构的分支数量以及对网络推理速度的逐元操作。Bochkovskiy等人 [3] 在进行模型扩展时,还考虑了激活问题,即更多地考虑卷积层输出张量中的元素数量。CSPVoVNet的设计图1中的CSPVoVNet [4] 的设计是VoVNet [5] 的一个变体。VoVNet [4] 的变化,除了考虑前述的基本设计问题、基本的设计关注点外,CSPVoVNet的架构 [6] 还分析了梯度路径,以使不同层的权重来学习更多不同的特征。上述的梯度分析方法使推断更快、更准确。图1中的ELAN [7] ,考虑了以下设计策略——“如何设计一个高效的网络?”。他们得出了一个结论:通过控制最短的最长梯度路径,一个更深的网络可以有效地学习和收敛。在本文中,我们提出了基于ELAN的扩展ELAN (E-ELAN),其主要结构如图1所示。
无论梯度路径长度和堆积大规模ELAN中计算块的数量,它都达到了一个稳定的状态。如果更多的计算块被无限制地堆叠,这种稳定状态可能会被破坏,参数的利用率也会下降。所提出的E-ELAN通过使用扩展、移动、合并基数实现了在不破坏原始梯度路径的情况下不断提高网络的学习能力。我们的策略是利用群卷积来扩展计算块的通道和基数。在结构方面,E-ELAN只改变了计算块的结构,而过渡层的结构完全没有改变。我们的策略是使用组卷积来扩展计算块的通道和基数,同时应用相同的组参数和信道倍增器用于计算层的所有计算块。此时,每一组特征图中的通道数将与原始体系结构中的通道数相同。然后,将每个计算块计算出的特征图根据设置的组参数g整分为g组,然后将它们连接在一起。最后,我们添加了g组特征映射来执行合并基数。除了维护原始的ELAN设计架构外,E-ELAN还可以指导不同的计算块组来学习更多样化的特性。
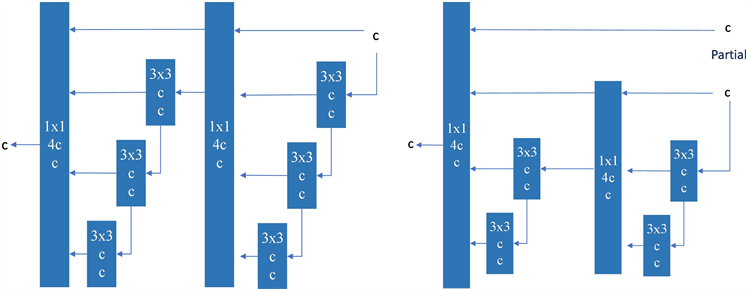 (a) VoVNet (b) CSPVoVNet [4]
(a) VoVNet (b) CSPVoVNet [4]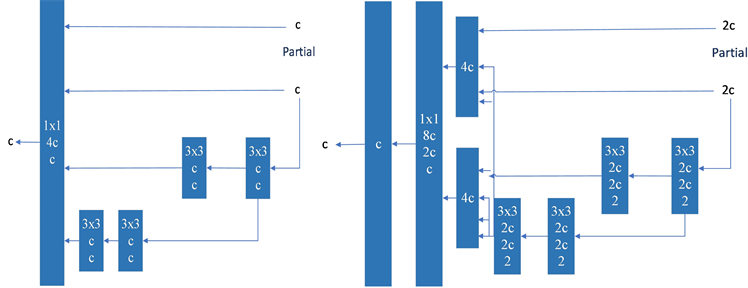 (c) ELAN [7] (d) E-ELAN
(c) ELAN [7] (d) E-ELAN
Figure 1. Extended efficient layer aggregation network. The proposed Extended ELAN (E-ELAN) does not change the gradient transfer path of the original architecture at all, but uses group convolution to increase the cardinality of the added features, and combines the characteristics of different groups in a way of shuffling and merging cards. This way of operation can be enhanced by different feature maps and improve the use of parameters and computations
图1. 扩展的高效层聚合网络。所提出的扩展ELAN (E-ELAN)完全不改变原始架构的梯度传输路径,而是使用组卷积来增加所增加的特征的cardinality,并将不同组的特征以洗牌和合并卡度的方式进行组合。这种操作方式可以增强由不同的特征图,并改善参数和计算的使用
2.2. 基于串联的模型缩放
模型缩放的主要目的是调整模型的一些属性,生成不同尺度的模型以满足不同推理速度的需要。例如,EfficientNet网络 [8] 的缩放模型考虑了宽度、深度和分辨率。至于规模化的YOLOv4,其缩放模型是调整阶段的数量。在 [3] 中,Bochkovskiy等人分析了原始卷积和组卷积对进行宽度和深度缩放时的参数和计算量的影响,并设计了相应的模型尺度方法,用它来设计相应的模型缩放方法。
上述方法主要用于诸如PlainNet或ResNet等架构中。当这些架构在执行放大或缩小过程时,每一层的内度和出度都不会发生变化,因此,我们可以独立分析每个缩放因子对参数量和计算量的影响。然而,如果这些方法应用于基于连接的架构,我们会发现当扩大或缩小执行深度,基于连接的翻译层的计算块将减少或增加,如图2所示。
从上述现象可以推断,我们不能对基于连接的模型分别分析不同的比例因子,而必须一起考虑。以放大深度为例,这样的动作会导致过渡层的输入通道和输出通道之间的比率变化,从而导致模型的硬件使用量的减少。因此,我们必须为一个基于连接的模型提出相应的复合模型缩放方法。当我们缩放一个计算块的深度因子时,我们还必须计算该块的输出通道的变化。然后,我们将对过渡层以相同的变化量进行宽度因子缩放,结果如图2。所示我们提出的复合尺度方法可以保持模型在初始设计时的特性,并保持最优结构。

Figure 2. Model scaling for connection-based models. We observe that the output width of the computational block also increases when depth scaling is performed on the connection-based model. This phenomenon causes the input width of subsequent transport layers to increase. Therefore, we propose that when model scaling is performed on a connection-based model, it is only necessary to adjust the depth in the computation block and perform corresponding width scaling on the remaining transport layers
图2. 基于连接的模型的模型缩放。我们观察到,当在基于连接的模型上进行深度缩放时,计算块的输出宽度也会增加。这种现象会导致后续传输层的输入宽度增加。因此,我们提出了在基于连接的模型上进行模型缩放时,只需要调整计算块中的深度,并对剩余的传输层进行相应的宽度缩放
3. 训练技巧
3.1. 重新设计模型参数化
尽管RepConv [9] 在VGG [10] 上取得了优异的性能,但当我们已将它直接应用于ResNet [11] 、DenseNet [8] 和其他架构时,它的精度将显著降低。我们使用梯度流传播路径来分析重新参数化的卷积应该如何与不同的网络相结合,还相应地设计了计划中的重新参数化的卷积。RepConv实际上结合了3 × 3卷积、1 × 1卷积和在一个卷积层中的身份连接。通过分析RepConv与不同架构的组合及其性能,我们发现,RepConv中的身份连接破坏了ResNet中的残差和DenseNet中的连接,为不同的特征图提供了更多的梯度多样性。基于上述原因,我们使用没有身份连接的RepConv (RepConvN)来设计计划中的重新参数化卷积的体系结构。在我们的思维中,当具有残余或连接的卷积层被重新参数化的卷积所取代时,不应该存在身份连接。图3显示了我们在PlainNet和ResNet中使用的“计划重新参数化卷积”的一个示例。对于基于残差的模型和基于连接的模型中完整计划的再参数化卷积实验,它将在消融研究环节中提出。
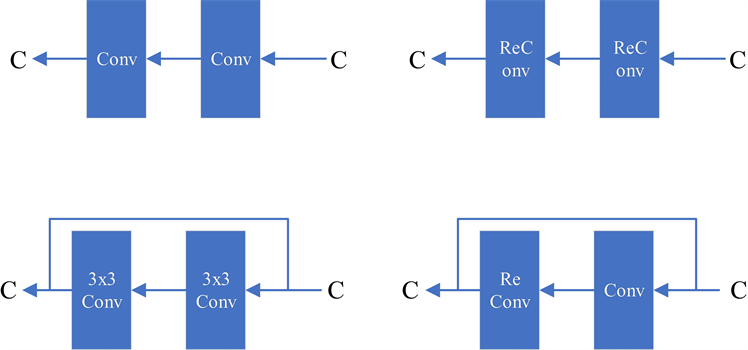
Figure 3. The planned reparameterized model. In the proposed planned reparameterization model, we find that a layer with residual or connected connections, its RepConv should not have identity connections. In these cases, it can be replaced by a RepConvN that does not contain an identity connection
图3. 计划中的重新参数化模型。在提出的计划再参数化模型中,我们发现一个具有残余或连接连接的层,它的RepConv不应该具有身份连接。在这些情况下,它可以被不包含身份连接的RepConvN替换
3.2. 粗标签用于辅助头、细标签用于引导头
深度监督 [10] 是一种常用于训练深度网络的技术。其主要概念是在网络的中间层增加额外的辅助磁头,以及以辅助损失为导向的浅层网络权值。即使对于像ResNet [11] 和DenseNet [1] 这样通常收敛得很好的体系结构,深度监督仍然可以显著提高模型在许多任务上的性能。图4分别显示了“没有”和“有”深度监督的目标检测器架构。在本文中,我们将负责最终输出的头称为引导头,将用于辅助训练的头称为辅助头。
接下来,我们想讨论一下标签分配的问题。过去,在深度网络的训练中,标签分配通常直接指地面真相,并根据给定的规则生成硬标签。然而,近年来,如果我们以目标检测为例,研究者经常利用网络预测输出的质量和分布,然后结合地面真相考虑,使用一些计算和优化方法来生成可靠的软标签。例如,YOLO [12] 使用边界盒回归预测和地面真实的IoU作为客观性的软标签。在本文中,我们将将网络预测结果与地面真相一起考虑,然后将软标签分配为“标签分配者”的机制。
无论辅助头或领导头的情况如何,都需要对目标进行深度监督培训。在软标签分配人相关技术的开发过程中,我们偶然发现了一个新的衍生问题,即“如何将软标签分配给辅助头和铅头?”,据我们所知,相关文献迄今尚未对这一问题进行探讨。目前最常用的方法的结果如图4所示,即将辅助头和铅头分离,然后利用它们自己的预测结果去执行标签分配。本文提出的方法是一种新的标签分配方法,通过铅头预测来引导辅助头和铅头。换句话说,我们使用铅头预测作为指导,生成从粗到细的层次标签,分别用于辅助头和铅头的学习。所提出的两种深度监督标签分配策略分别如图4所示。
铅头引导标签分配器主要根据铅头的预测结果和地面真实值进行计算,并通过优化过程生成软标签。这组软标签将作为辅助头和铅头的目标训练模型。这样做的原因是铅头具有相对较强的学习能力,因此,由此产生的软标签应该更能代表源数据与目标之间的分布和相关性。此外,我们还可以将这种学习看作是一种广义剩余学习。通过让较浅的辅助头直接学习铅头已经学习到的信息,铅头将更能专注于学习尚未学习到的残余信息。
从粗到细的铅头引导标签分配人也使用铅头的预测结果和地面真相来生成软标签。然而,在此过程中,我们生成了两组不同的软标签,即粗标签和细标签,其中,细标签与铅头引导标签分配者生成的软标签相同,粗标签是通过允许更多的网格被视为积极样本分配过程的约束而生成的。原因是一个辅助头的学习能力不是那么强大的领导头,为了避免丢失需要学习的信息,我们将专注于优化召回辅助头的目标检测任务。对于铅头的输出,我们可以从高查全率结果中过滤高精度结果作为最终输出。然而,我们必须注意到,如果粗标签的额外重量接近于对于精细标签,它可能在最终预测时产生不良的先验。因此,为了使这些超粗的正网格的影响更小,我们在解码器中进行了限制,从而使超粗的正网格不能完美地产生软标签。上述机制允许在学习过程中动态调整细标签和粗标签的重要性,并使细标签的可优化上界始终高于粗标签。
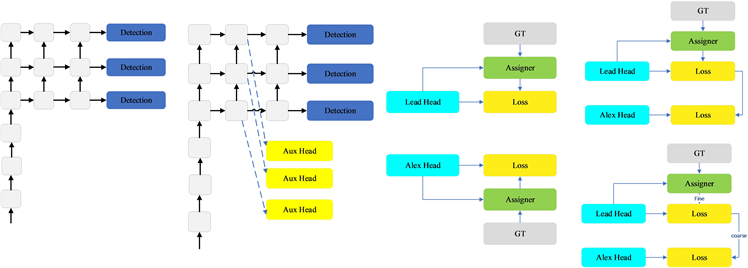
Figure 4. Auxiliary equipment is rough, lead-head label dispenser equipment is fine. Compared to the normal model, the schema in this figure has auxiliary headers. Different from the usual independent label assigners, we propose lead-guided label assigners and lead-guided label assigners from coarse to fine. With lead prediction and ground truth, the proposed label assigner is optimized, and the labels for both the training lead and the auxiliary head are obtained. The detailed coarse-to-fine implementation method and constraint design details will be elaborated in the attached appendix
图4. 辅助设备设备粗糙,铅头标签分配器设备精细。与普通模型相比,此图中的图式有辅助头。与通常的独立标签分配人不同,我们提出了铅头引导标签分配人和从粗到细的铅头引导标签分配人。通过铅头预测和地面真相,对所提出的标签分配人进行优化,同时得到训练铅头和辅助头的标签。详细的从粗到细的实现方法和约束设计细节将在附件附录中详细阐述
3.3. 其他免费训练包
在本节中,我们将列出一些可训练的包。这些免费赠品是我们在训练中使用的一些技巧,但最初的概念并不是由我们提出的。这些免费赠品的训练细节将在附录中详细阐述,包括1) conv-bn激活拓扑中的批处理归一化:这部分主要将批处理归一化层直接连接到卷积层。其目的是将推理阶段批量归一化的均值和方差整合到卷积层的偏差和权重中。2) YOLOR [12] 中的隐式知识结合卷积特征映射和乘法方式:YOLOR中的隐式知识可以通过推理阶段的预计算简化为向量。这个向量可以与之前或后续卷积层的偏差和权重相结合。3) EMA模型:EMA是在平均策略 [5] 中使用的一种技术,在我们的系统中,我们纯粹使用EMA模型作为最终的推理模型。
4. YOLOv7的垃圾检测算法
4.1. 数据集的构建
1) 数据获取
根据中国节能环保集团有限责任公司垃圾池区域操作工的反馈,垃圾池区域主要的目标物包括垃圾及吊车夹爪2种,以往需要工人手动操作抓取垃圾将其放入待烧区域,该工作不仅耗费人力、财力,同时,操作工人无法准确判断待烧区域的垃圾量。为了可以实现垃圾自动检测及实时抓取操作,本章节选取2种目标物进行检测,通过对垃圾池的监控摄像视频数据按照不同时间、不同区域、不同料口进行分帧截取,具体情况如图5所示。共计图片数据2662张,图像分辨率为1920 × 1280。




Figure 5. Schematic diagram of the garbage to be burned and the crane gripper
图5. 待烧垃圾及吊车夹爪示意图
2) 数据标注
模型训练时输出预测值和真实值的误差通过损失函数表征,经过反向传播不断更新权重参数,寻找最优解,因此,在实验之前,需要进行数据标注工作,来获得真实标签。本文使用LableImg工具对所有图片按VOC2007数据集标准格式进行标注,得到xml格式的标签文件,标注界面如图6所示。总共标注2种目标物:垃圾(waste)、夹爪(gripper)。
3) 数据划分
将数据集按照9:1的比例划分为训练集和验证集,其中,训练集2136张,验证集526张,具体数据集划分情况如表1所示。模型在训练时所有训练集和验证集全部输入给网络,模型测试时在测试集上对垃圾及夹爪进行分别评估。
4.2. 实验环境及评价准则
1) 实验环境
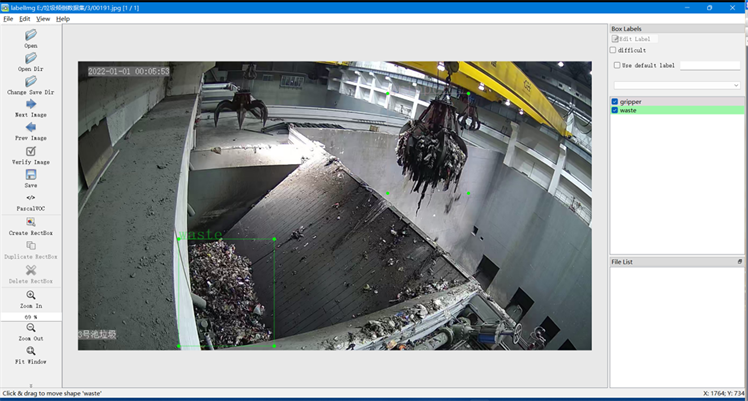
Figure 6. Schematic diagram of data annotation
图6. 数据标注示意图

Table 1. Data set division details
表1. 数据集划分详情
本文全部实验的软硬件环境及相关版本参数为Ubuntu 16.04.4 LTS系统下,采用Pytorch深度学习框架搭建。计算机硬件配置包括NVIDIA GeForce RTX 3090 24GB GPU、AMD Ryzen 9 5950X 16-Core CPU和16 GB内存。
2) 评价准则
本文主要采用平均精度AP (Average Precision)、平均精度均值mAP (Mean Average Precision)和FPS (Frame Per Second)作为评价指标来衡量算法性能。FPS是衡量检测速度的最直观指标,指的是算法每秒可检测的图像帧数,在实际应用中,实时检测的标准通常为FPS ≥ 30。平均精度AP的计算涉及到精确率(Precision)和召回率(Recall)的概念,计算公式如下:
(1)
(2)
其中,TP表示模型预测为正类实际为正类的样本数,FP表示模型预测为正类实际为负类的样本数,FN表示模型预测为负类实际为正类的样本数,如公式(1)、(2)所示。
(3)
(4)
分别以不同召回率下的最高精确率作为横纵坐标得到一条P-R曲线,由公式(3)可知,对P-R曲线求积分即为平均精度值AP。C为目标类别数,因此由公式(4)可知mAP为所有类别的AP均值。
4.3. 实验结果及分析
在3.3.2模型训练参数优化的基础上训练YOLOv7,输入图像分辨率为640 × 640,初始学习率设为1e−4,最低学习率设为1e−6,迭代轮次(epoch)为100,每次迭代的训练批次(batchsize)为8。训练曲线如图7所示,从图中可以看出,在迭代75次之后损失值振荡减小并逐渐趋于收敛,选择收敛阶段的最优模型进行测试。
YOLOv7在实时监控下的部分检测效果如图8所示,从图中可以看出,YOLOv7算法在都能够准确的识别和定位垃圾和夹爪2种杂物。
以上实验分析表明,对于实时检测垃圾和夹爪而言,YOLOv7在检测精度方面满足检测需求,可有效检测出2种目标物,但其模型复杂度较高,实际推理速度在低配计算平台上未达到实时检测要求。因此,下一步需要对其进行进,在保持高精度的同时,进一步降低模型复杂度,提高模型推理速度,达到实时检测的要求,从而更好地实现算法检测精度与检测速度的平衡。
从图9中我们可以看出,在YOLOv7的检测结果中,其Precision曲线的值在confidence为0.4~0.6之间,逐渐趋向1。除此之外,其Recall曲线的值在0.4~0.8之间有所下滑,最终逐渐趋向为1。从整体上来看,它们的PR曲线和Precision曲线、Recall曲线随置信度变化的曲线基本上一致。Precision-Recall曲线得到waste类的PR值为0.988,gripper类的PR为0.655,所有类别整体的mAP0.5的值为0.877。
5. 结论
本文首先介绍YOLOv7算法的基本组成结构,阐述每一组成部分的原理。然后,构建了杂物数据集,通过LableImg工具完成标签制作工作,为避免训练模型时出现过拟合或泛化性不足的问题,提出用离线数据增强方法扩充数据量,并用K-means算法对标签文件重聚类,得到适用于杂物数据集的先验框,有利于模型收敛,采用余弦退火算法优化学习率衰减策略,避免模型陷入局部最优。最后,在训练集上,训练YOLOv7模型,实验结果表明,该算法在精度方面满足要求,可以满足实时工业垃圾处理。