1. 引言
近年来,随着人工智能技术的不断发展,人们的生活方式发生了极大改变,各种关于人脸的深度学习技术运用到生活的方方面面,如人脸识别 [1] [2] [3] ,人脸美化 [4] [5] [6] 以及人脸属性编辑 [7] [8] [9] 等等。当下各类短视频软件是比较火爆的娱乐方式之一,其内部强大的美颜效果以及各种滤镜都受到用户的追捧,其中关于人脸图像性别转移的滤镜一经发布都能引起社交网络传播热潮,在国内外都受到用户的广泛关注。
人脸图像性别转移就是将男(女)性的人脸在保持原本身份的前提下转换成为女(男)性的人脸,如下图1所示,一般通过生成对抗网络(Generative Adversarial Networks, GAN) [10] 实现。人脸图像性别转移任务可以视为风格迁移问题的一种特殊情况。Zhu等人 [11] 引入循环一致性损失,将图像从源域转移到目标域,可以在不配对的数据集中间进行图像风格转换,但该方法生成的结果会产生粗糙的纹理,并且内容被过度保留,生成的图像质量不够精细。在CycleGAN模型问世后,有许多相关研究人员基于GAN网络对风格迁移做了进一步的开发应用。Chen等人 [12] 在2018年提出对抗性门控网络(Gated GAN),通过门控转换器使输入图像完成不同风格的迁移工作。Sanakoyeu等人 [13] 通过对抗判别器对输入图像进行编码解码,风格化图像集合整体迁移,并利用编码器完成重建损失。陈等人 [14] 提出将每个风格集中到StyleBank部分,在转换新风格图像时只需要重新训练StyleBank就能完成风格迁移。Liu等人 [15] 通过感知损失以及保留图像对象,提高训练效率,并提出新的目标函数,增加了输出图像的风格多样性。Ma等人 [16] 将图像分为内容特征与风格特征,且两者可以完全分离,利用对偶一致性损失来实现语义相关的风格迁移。Huang等 [17] 在2018年提出多模态无监督图像转换网络(MUNIT),它将图像的隐藏编码进一步细化为图像内容编码和图像风格编码,通过改变编码的方式来完成图像的风格交换,但对于特定人脸图像性别转换问题,其图像生成结果仍存在人脸图像模糊,背景图像扭曲,面部身份保留效果不好等缺点。
针对上述问题,本文在基于改进的MUNIT人脸图像性别转换模型的基础上,提出一种具有鲁棒性质的人脸图像性别转移模型,并通过实验验证了其有效性。
本文的主要贡献如下:
1) 将输入模型的人脸图像进行Face Parsing [18] 操作,将具体的人脸部分准确输入到模型中进行训练学习,可以有效避免无关背景域对于模型训练学习的影响,同时完好地保留了图像背景部分。
2) 设计人脸肤色损失函数,将模型结果生成前后的人脸部分做基于颜色的Histogram Matching [19] ,以此可以保留人脸原本的肤色,从而提高了性别转换的图像效果。
3) 在训练策略上,对CeleBA数据集的人脸图像根据属性进行简单的筛选,减少遮挡,眼镜等影响模型生成结果的因素,从而提高图像的生成质量。
本文将具有鲁棒性质的人脸图像性别转移模型在数据集CeleBA上进行实验,通过主观视觉评价,以及基于内容准确率和结构相似度的客观评价指标,表明了所提方法的先进性。
2. 相关知识
2.1. MUNIT模型
MUNIT模型脱胎于Liu等人提出的非监督图像翻译模型(UNIT) [20] ,作者认为风格编码s与内容编码c为相互独立的图像信息空间。在不同的域之间,内容编码空间是共享的。内容空间中包含一些图像内物体像素级属性,例如边缘信息、相对位置、朝向等信息,而风格编码则蕴含一些风格特征信息例如颜色、纹理等等。假设两个不同的域X1和X2的风格编码空间分别为s1和s2,图像共享的内容编码空间为c1,图像的风格迁移过程如下式所示:
(1)
其中,G2为图像风格空间s2的风格迁移生成器。编码器通过参数学习分别将风格编码空间s2和内容编码空间c1从不同的图像域X2和X1中提取出来。作者假设前两者的分布相互独立,解码器就可以通过参数学习和损失函数的指导,学习到风格分布
和内容分布
的联合分布
。而学习到的联合分布就是将风格s2融合到内容c1的风格迁移图像结果。MUNIT方法可以通过改变不同的风格编码进行多次风格迁移。
MUNIT网络的风格解码过程如图2所示。网络结构与CycleGAN [10] 的循环对称结构类似。图像经过解码器E后生成对应的内容编码c和风格编码s。将不同风格图像的风格编码s交换之后,利用生成器G还原成图像,完成一次单向的风格迁移过程。通过两个相同且对称的风格迁移过程,风格图像x1和x2分别变为x1 → 2和x2 → 1。如图2中(a)过程所示,图像需要经过重建损失,即将图像x通过编码器生成其对应风格内容编码后再次重新组合,确保生成器的图像生成能力准确,避免出现模式崩塌的情况。
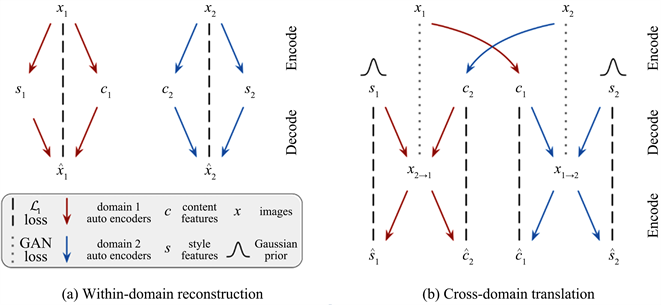
Figure 2. MUNIT style encoding and decoding process (from literature [17] )
图2. MUNIT风格编解码过程(摘自文献 [17] )
2.2. MUNIT模型损失函数
MUNIT模型的整体网络结构如图3所示,我们集合编码器,解码器,鉴别器的loss,当作最后优化的目标,其为对抗性损失和双向重建损失项的加权和,如下:
(2)
这里的
是控制每项loss的权重参数。(2)式中前两项为对抗损失,使用GANs来匹配翻译后图像的分布和目标数据的分布。
(3)
这里
是鉴别生成的图像是否符合域
的分布,鉴别器
以及
有类似定义。(2)式中第三项为图像的重建损失,给定一个从数据分布中采样的图像,我们能够在编码和解码后重建它。
(4)
(2)式中第四、五项为图像的内容风格损失,给出一个来自于latent distribution的latent code (style或者content),我们能够在编码和解码后重构它。
(5)
(6)
这里的
表示先验分布
,
是由
和
给出。

Figure 3. MUNIT model overall network structure
图3. MUNIT模型整体网络结构
2.3. 人脸图像风格迁移
关于人脸图像的风格迁移任务最大的难点就是难以得到配对的数据集,因此需要无监督的风格迁移模型来进行训练,一般采用循环生成对抗网络CycleGAN或者无监督样式迁移网络MUNIT完成迁移任务。Kim等 [21] 提出UGATIT模型,将辅助分类器得到的特征图输入到注意力模块,以便于更好区分源域和目标域,使模型迁移效果更加优秀,但容易改变图像无关背景。石达等 [22] 提出来基于改进CycleGAN的人脸性别伪造图像生成模型,通过在循环生成对抗网络CycleGAN的生成器后加入混合注意力和自适应残差块,结合相对损失函数得到了不错的人脸图像性别转换效果,但仍无法解决无关背景域的影响。Liu等 [23] 在多模态无监督图像翻译网络(MUNIT)的基础上引入新的人脸性别概率性掩膜,促进实现性别转移和身份保留的目标,同时通过人脸稀疏特征学习到关于人脸性别的决定性因素,最终获得了较好的性别转换效果,但对于人脸面部颜色,细节的部分仍有改进的空间。由于人脸图像性别转移没有配对数据集的特殊性,本文将基于无监督样式迁移MUNIT模型的基础上进行研究。
3. 人脸图像性别转移鲁棒模型
3.1. 总体网络结构
本文方法脱胎于MUNIT模型,并在基于改进的MUNIT人脸图像性别转换模型的基础上再次做出优化。改进的MUNIT模型在生成器部分加入了混合注意力机制CBAM [24] 以及动态实例归一化DIN [25] ,对模型结果背景扭曲现象有了一定的缓解,但是还未完全解决此现象,同时未考虑到人脸图像性别转换前后肤色随机变化的问题,为此我们提出具有鲁棒性质的人脸图像性别转移模型。
完整的改进MUNIT网络模型如图4所示,网络首先将输入模型的人脸图像进行人脸解析,得到人脸解析图以及存放解析信息的特征图,然后将图像中的人脸部分包括面部五官以及脖子部分输入到模型当中,通过内容编码器和风格编码器分别提取并交换图像的内容特征和风格特征,最终完成人脸图像性别转换过程。其中,风格编码器由下采样部分(Down-sampling)、全局池化层(Global Pooling)和全连接层(Fully Connected, FC)组成;内容编码器由下采样部分,动态实例归一化(DIN)残差模块(Residual Blocks)和混合注意力模块组成。而解码器则是由多层感知机(Multilayer Perceptron)、残差模块和上采样部分(Up-Sampling)构成。
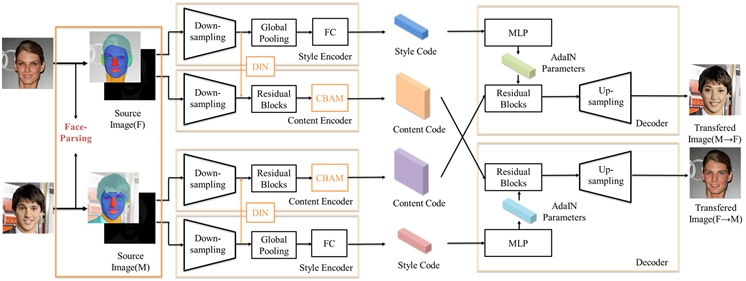
Figure 4. Network structure of robust model of gender transfer in face image
图4. 人脸图像性别转移鲁棒模型网络结构图
3.2. 人脸解析
人脸解析,是将人的头部包含人脸五官构成进行分解,得到头发、面部皮肤、眼睛、眉毛、鼻子、嘴、耳朵等区域,在深度学习当中可以作为分类任务实现。图像分类任务在深度学习领域的研究已经比较成熟,Yu等人 [26] 在2018年提出双分支语义分割网络BiSeNet,采用小步长的Spatial Path以及快速下采样的Context Path,同时引入新的特征融合模块Feature Fusion Module来对特征进行合理的融合,最终得到更高速率以及更高准确率的语义分割结果,我们将采用训练好的BiSeNet模型完成本文的人脸解析任务。

Figure 5. Face parsing by BiSeNet
图5. 基于BiSeNet的人脸解析图
如上图5所示,第一列是输入模型的人脸原图,第二列是经过解析的人脸各部分分布图,第三列是记录各部分标签的空间位置图。通过人脸解析图我们可以将图像中的人脸部分进行精准选择,将人脸部分准确输入到风格迁移模型中进行训练学习,从而避免了无关背景图像对训练的影响,同时可以完美保留图像的背景域。从三组人脸图像解析图可以看出第一行无遮挡的正脸图像分解的效果最为准确,第二三行因为有眼镜,鲜花的遮挡导致部分人脸分析出现错漏,因此输入到改进MUNIT模型的人脸数据集最好为正脸无遮挡的人脸图像,才能有最好的人脸图像性别转换效果。
3.3. 人脸肤色损失函数
无监督样式迁移模型MUNIT可以对图像做多风格的样式迁移,但对于人脸图像性别迁移任务,该方法无法使模型生成前后的人脸肤色保持一致,因此我们设计了新的损失函数以解决这个问题。若要使模型生成前后的人脸肤色保持一致,我们采用直方图匹配的方法。
直方图匹配,又称直方图规定化,即变换原图的直方图为规定的某种形式的直方图,从而使两幅图像具有类似的色调和反差。我们对模型生成前后的人脸图像做人脸解析,将除去眼睛,眉毛,嘴巴以外的人脸部分提取出来,做基于颜色的直方图匹配,得到具有相同颜色分布的人脸,从而保留了原人脸图像的肤色。
(7)
(8)
(9)
其中,公式(7)表示人脸肤色损失函数,
表示经过迁移的人脸图像,
表示对y域A与域B进行直方图匹配,
表示原图像与解析得到的人脸mask相乘提取图像中的人脸区域。公式(8),(9)表示对
迁移图像,
原图像进行FP (Face Parsing)人脸解析。
最后我们将人脸肤色损失函数加入到模型的总损失函数当中,如下公式(10)所示。
(10)
4. 实验与分析
4.1. 数据集
本文在综合考虑后,选用公开数据集CelebFaces Attributes Dataset (CelebA)。CeleBA数据集是一个大规模的人脸属性数据集,包括10,177个身份,202,599张人脸图像,且每张照片都有特征标注信息,包含性别以及各种人脸特征等40多项信息。将CeleBA数据集的训练集输入模型进行训练,验证集和测试集输入模型进行测试。为减少无关背景因素对于图像生成结果的影响,我们对数据集的标注信息进行预处理,选取年轻人并对图像做合适的裁剪,将图片大小调整为256*256。最后男性人脸训练集和测试集数量分别是46,372和4564,女性人脸训练集和测试集的数量分别是90,016和10,014。
4.2. 实验细节
本文实验的服务器配置如表1所示,模型训练的部分参数设置如表2所示。

Table 1. Experimental server configuration
表1. 实验服务器配置
Table 2. Some parameters of the experiment
表2. 实验的部分参数设置
将预先处理好的CeleBA数据集输入到模型进行训练。在实验中,模型训练次数max_iter为1,000,000,batchsize设为1,初始学习率
设置为0.0001,将式(4)中的图像重建损失权重
设置为10,图像风格及内容的重建损失权重
,
均设置为1,人脸面部mask的直方图匹配损失权重
设置为1,每次学习率衰减的大小gamma设置为0.5。在模型的训练过程中,使用Adam [27] 优化器对梯度下降进行优化。
4.3. 评价指标
图像风格迁移结果主观性非常大,因计算机很难对转移前后的图像风格变化给出定性的评价结果。因此,本文将结合主观视觉评价与客观指标评价对模型结果进行解析。主观视觉评价将本文模型生成结果与同等条件下其他模型生成结果随机采样,依靠不同用户的评价选出人脸性别转换效果最优的模型。客观评价指标结合内容准确率和结构相似度进行综合评判。
1) 内容准确率。内容准确率即模型生成的伪造数据通过判别器的概率,也就代表了模型生成结果的有效性。本文使用InceptionV3网络 [28] 作为分类模型。将分类模型在CeleBA数据集中进行预训练得到基准的内容准确率,然后将本文模型生成的伪造图像输入到预训练后的分类模型中,如果伪造的图像足够真实可以通过分类模型,将其计入正确样本,最后将正确样本与输入样本数相除即可得到最后的内容准确率,准确率越高代表模型生成效果越好。
2) 结构相似度。本文基于FID (Fréchet Inception Distance)指标来计算男女面部特征之间的相似度。FID代表了真实人脸图像与模型伪造的人脸图像的特征向量之间距离的一种度量。这种视觉特征是使用 Inception v3图像分类模型提取特征并计算得到的。FID在最佳情况下的得分为0.0,表示两组图像相同。分数越低代表两组图像越相似,或者说二者的统计量越相似。FID计算式如式(11)所示:
(11)
其中,
和
为输入的人脸数据集的均值和协方差矩阵,
和
为模型生成数据集的均值和协方差矩阵,
表示矩阵对角线上元素的总和。
4.4. 效果评估
4.4.1
. 主观视觉评价
本文将预处理过的CeleBA数据集输入到改进的MUNIT模型,原始MUNIT模型以及CycleGAN模型中进行训练和测试,横向对比每种方法的生成结果。本文所做实验均采用经过1,000,000次迭代的生成模型,且同一种实验采用相同的测试数据,只保留生成方法和训练数据的不同。实验结果如图6、图7所示。
图6,图7从左到右每列分别为原图像,CycleGAN生成的性转图像,原MUNIT生成的性转图像,加入CBAM和DIN的IMUNIT模型以及本文模型生成的性转图像。从图6男性到女性的性别转换结果可以看出,本文方法在能够完好的保留原图像的背景区域以及模型生成前后的人脸肤色,并且生成更加优秀的性转图像效果。显然,图6,图7中不难看出本文方法优秀的背景域及人脸肤色的保留效果,相比于其他经典风格迁移方法,本文所提方法有显著优势;在人脸部分,本文结果与IMUNIT模型的结果基本保持一致,但从整体上看,本文方法的生成效果更为优秀。
我们随机选取10张人脸图像,男女各5张,输入到CycleGAN,MUNIT,IMUNIT和本文方法生成的结果组合成问卷,交由259名用户进行评选,选取性别转换后效果最好的图像(模型)。所得结果如图8所示,显然,本文所提方法在人脸图像性别转换上表现的最好。
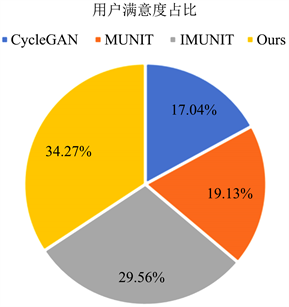
Figure 8. User satisfaction survey pie chart
图8. 用户满意度调查饼状图
4.4.2
. 客观指标评价
1) 消融实验
本文在IMUNIT的基础上逐步增加Face Parsing和人脸肤色损失函数L-Face,下面将分别计算在不同改进策略下的内容准率和FID得分。
如表3所列,添加Face Parsing操作后生成模型对人脸部分进行准确迁移,在CeleBA数据集上,伪造女性和伪造男性的内容准确率分别提高了0.011和0.026;继续添加损失函数L-face,使模型保持人脸肤色一致,内容准确率再提高了0.021和0.031。模型中添加Face Parsing后,在CeleBA数据集上,伪造女性和伪造男性的FID得分分别降低了7.86和4.77;继续增加损失函数L-Face后,FID再降低了4.14和3.33。从表3和表4可以看出,本文在IMUNIT模型上进行的改进是行之有效的。
Table 3. Content accuracy under different conditions on the CeleBA dataset
表3. CeleBA数据集上不同条件下的内容准确率
Table 4. FID scores under different conditions on the CeleBA dataset
表4. CeleBA数据集上不同条件下的FID得分
2) 与其他方法对比
本文方法与其他方法的内容准确率和FID得分的对比结果如表5、表6所列。本文方法在男女性别转换的实验中内容准确率相较于其他方法都更加优秀,说明基于本文方法生成的人脸图像更加真实。基于本文模型的男转女FID得分低于IMUNIT模型以及原始的MUNIT模型,高于CycleGAN模型,说明本文方法在身份保留方面还有进步的空间,需要继续改进;在男转女的FID的得分结果在几种方法中最低,说明本文方法具有更好的模型性能,使模型的人脸生成结果更真实,效果更好。
Table 5. Content accuracy of each model on CeleBA dataset
表5. CeleBA数据集上各模型的内容准确率
Table 6. FID scores of each model on the CeleBA dataset
表6. CeleBA数据集上各模型的FID得分
5. 结束语
本文在无监督样式迁移MUNIT的基础上完成人脸图像性别迁移任务,为解决模型性转结果图像背景区域扭曲模糊以及人脸肤色随机改变的缺点,本文提出具有鲁棒性质的人脸图像性别转移模型。首先对输入模型的人脸图像进行Face Parsing,直接提取人脸部分进行训练学习,可以完好保留图像背景域,同时减少了无关区域对模型训练的影响,从而提高了图像生成质量;构建新的人脸肤色损失函数,将模型生成前后的人脸部分进行Histogram Matching,以此可以保持性转前后的人脸肤色保持一致。通过最后的实验结果可得,本文所述方法可以更好地保留图像背景区域,解决了模型生成前后肤色不一致的问题,产生了更高质量的性别转换图像。同时,我们可以看到本文方法仅仅关注于人脸部分区域的性别转换,没有照顾到头发等其他关于性别的显著特征,未来可以考虑与人脸3D结合,将3D头发与2D人脸进行组合,以生成更加信服的人脸性别转换结果。
基金项目
北京市教育委员会科学研究计划项目资助(KM202110016001, KM202210016002)。北京建筑大学科学研究基金(KYJJ2017017, PG2021094);住房和城乡建设部科学技术计划北京建筑大学北京未来城市设计高精尖创新中心开放课题(NO. UDC2019033324, UDC201703332);北京建筑大学课程建设重点培育项目“高等数学ZDXX202008”。