1. 引言
由于互联网,人工智能,在线视频等的发展,教育行业衍生出了的各种新生产物,现在的教育形式产生了翻天覆地的变化 [1]。构建Java领域的知识图谱,能把零散的知识汇集成一个完整的知识网络体系,把Java相关的知识点转换成模块化、结构化、可视化的知识图谱 [2]。命名实体识别又是构建Java领域知识图谱中,不可或缺的一部分。在面向通用领域中,识别人名、地名和机构名等方面的命名实体识别方法的性能有着较大幅度的提升 [3]。并且近几年国内在军事文本、医疗、司法等领域实体识别方面也取得了较大的进展 [4]。但对于Java学习领域的相关研究就很少,Java相关知识点繁冗复杂 [5],相关扩展知识、不断更新发展的技术栈也很繁杂,实体往往中英文掺杂,并普遍存在简写缩写现象。因此针对此领域的命名实体识别的研究还处于起步阶段。单纯地基于规则的命名实体识别 [6],准确率很高,但是人工成本很高。随着统计机器学习算法的发展,隐马尔可夫模型 [7] (Hidden Markov Model, HMM)和条件随机场 [8] (Conditional Random Field, CRF)、支持向量机 [9] (Support Vector Machines, SVM)渐渐被人们所关注。但其缺点在于需要构建大规模的标注语料库,费时费力。近几年。深度学习在各领域都取得了不错的成果,其优点在于可以深度学习语义知识并且缓解数据稀疏的问题 [10]。
尽管近几年提出了许多新的模型来解决实体识别相关问题,但在Java学科领域的实体识别仍然面临着很多的挑战,具体体现在:
1) 此领域没有公开数据集,由于缺乏有标注的文本资源,且自主构建数据集费事费力,因此导致此领域研究发展滞后。
2) Java学科领域的知识点繁杂,中英文混杂,并且实体含有特有的内部特征。现有的实体识别方法难以对其进行准确地识别。
3) 现有大多数命名实体识别模型是基于字的划分粒度的,因此不能充分利用词相关信息,丢失了词边界,不能准确区分出词边界。导致识别较长实体名时,准确率并不高。
针对以上问题,本文首先构建了Java学科领域数据集,数据来源于计算机权威学习网站菜鸟教程和C语言中文网,知识点齐全,构建的数据集共包含46,316句文本信息。此外,本文针对Java实体专有特点,融入了词性信息和相关规则,以提高识别词边界信息、长实体名的准确率。并且提出了多模融合的方法提高模型的泛化性和实体识别的准确性。
2. 相关工作
2013年,Marrero等人 [11] 从应用方面,提出了命名实体识别的标准。1997年,Hochreiter等人 [12] 提出来LSTM模型,解决了长距离依赖问题。2003年,Hammerton等人 [13] 首次把长短期记忆网络(Long Short Term, LSTM)使用在命名实体领域。2014年,Bahdanau等人 [14] 首次将注意力机制引入自然语言处理领域,有效提高了命名实体识别模型性能。2016年,Peng [15] 在分词的基础上,使用了双向长短词记忆模型 (Bi-directional Long Short Term Memory, BiLSTM)-CRF模型。2017年,Strubell等人 [16] 提出了空洞卷积 (Iterated Dilated Convolutional Neural Network, IDCNN)-CRF模型,加快了模型的训练速度。2018年,Zhang等人 [17] 提出了不需要分词的Lattice LSTM模型,引入外部词典以充分利用词序信息,解决了分词错误带来的误差传递问题。2018年,谷歌公司提出了BERT模型 [18],在多个领域中取得了不多的结果。2020年,Yiming Cui等人 [19] 考虑到中文分词,提出来BERT-www模型。在不同领域的命名识别任务中,2020年,Li等人 [20] 在医学领域中,使用未标记的数据,使用BERT对电子简历进行预训练,并引入了字典和部首特征以提高模型识别准确率。2020年,Wang等人 [21] 在司法领域中,利用注意力机制提取句子信息,提出来了Attention-BiLSTM-CRF模型。2021年,Liu等人 [22] 在历史领域中引入了BERT-BiLSTM-CRF模型,从非结构数据中提取实体信息。
综合上述情况,本文得到启发提出了基于Java领域的命名实体识别方案。
本文主要的贡献如下:
1) 本文自主构建并标注Java专有领域中文数据集。
2) 提出了针对Java专有领域的实体识别单模模型,融入了词性信息和Java领域实体识别规则,以提高识别实体边界的准确率。
3) 提出对多个异构单模的结果进行融合互补的方法,以提高最终预测结果的准确性和模型的泛化能力。
3. 模型
本文提出的融入词性信息和Java专有领域实体识别规则的单模模型,以更好地识别实体边界,单模结构分为三层:嵌入层,编码层,解码层。单模验证成功后,对多个异构单模预测结果进行加权融合,输出最终的预测结果。单模结构如图1所示。
3.1. 嵌入层
嵌入层,主要作用是对文本信息的特征进行提取。本层模型在BERT的基础上进行了改进,将嵌入层增添至四部分,boundary embeeding,token embeeding,segment embeeding,position embeeding。将输入信息映射为字向量,词边界信息映射为边界向量,随后字向量和边界向量进行了融合,再加入句向量和位置向量,四者融合作为了最终的输出向量。
本文研究的Java领域命名实体识别任务,字与字之间有相互作用的关系,并且实体名称长度较长。且中文与英文不同,中文没有天然的词边界信息 [23],若仅对字编码就缺少了词的边界信息,因此本文提出了边界嵌入。
(一) boundary embeeding,边界嵌入,若缺少词的边界信息,实体识别的准确率就会降低,因此融合边界信息,以更准确地识别词边界。边界嵌入主要由两个模块组成,词性信息和规则设置。
词性信息,用来辨别字所属的词性,为名词,动词等。实体一般由名词组成,且后续针对Java专有领域实体规则也需要利用词性信息,因此选择融入词性信息,为下一步制定规则做准备,用来更准确地判断的词的边界信息。
制定规则。针对Java专有领域实体特点制定特有的识别规则。Java领域主要有以下两种特有表示结构:
1) Java专有名词特点为:英文字符 + 名词的结构。例如:“Java虚拟机”、“Date类”、“final变量”等实体,常被识别为[Java、虚拟机],[Date、类],[final、变量]。
2) Java专有名词特点为:名词+名词的结构。例如:“条件运算符”、“时间模式字符串”、“时间复杂度”等实体,常被现有模型识别为[条件,运算符],[时间模式、字符串],[时间、复杂度]。此规则的作用就是选择长度更长的实体作为标注的候选答案。
针对上述特点,融入词性信息,并且制定出适合Java领域的特有实体识别规则,可以更好的解决实体边界问题,从而增加实体识别的准确率。
(二) token embeeding,字的嵌入信息,是通过训练得到的。一个句子的开头用CLS,结束用SEP表示。此嵌入层只负责融入字的信息。
(三) segment embeeding,句子嵌入,是通过训练得到的,是为了区分不同句子的向量。若输入的是两个句子,则用EA和EB区分这个字属于句子A还是句子B。若只输入一个句子,就使用EA。
(四) position embeeding,位置嵌入,为了区分字在句子中的位置信息。相同的字出现在文本的不同位置,所拥有的语义信息存在差异。因此对不同位置的字标记一个不同的向量,进行区分。
如公式(1)所示,将四个向量相加作为编码层的输出
(1)
表示字嵌入向量,
为句子嵌入向量,
为位置嵌入的边界信息向量,
为位置嵌入向量。
为最终融合输出的向量。
上述4个分量都可以用其独热码与嵌入系数矩阵W相乘的形式,如公式(2)所示:
(2)
是根据输入的当前字符在字典中位置下标构造的独热码表示。
是根据输入字符所属句子下标构造的独热码表示,
是根据词性信息和规则信息,判断的词边界信息编码。
是根据输入字符在整个句子中位置信息,构造的独热码表示。H是嵌入维度,
是序列个数,
是词性边界数量,
是最大位置数。
本文预训练模型基于BERT模型的基础上,根据Java领域实体独有的特点,加入了边界嵌入信息,引入了词性信息和相关提取规则信息。
3.2. 编码层
本层的目的是更好的让模型理解文本的上下文关系,所用模型为BiLSTM和IDCNN。
BiLSTM [24]:由于序列过长,RNN等模型存在梯度消失的问题。LSTM模型由于其特殊的门结构能很好的保存上下文信息,从而解决这一问题。BiLSTM由前向LSTM和后向LSTM组成,捕捉两个方向的上下文信息。由嵌入层输出的向量序列信息作为BiLSTM的输入,让每个序列通过一个前向LSTM和一个后向LSTM,通过计算,得到两个不同的向量表示,将这两个向量进行拼接作为输出,如公式(3~5)所示:
(3)
(4)
(5)
和
表示i位置的前向LSTM和后向LSTM输出表示,
表示前一时刻隐藏层输入状态。
表示整合信息。进过双向LSTM编码处理得到的向量序列,再使用softmax预测出每个字对应的标注概率。
双向LSTM结构如图2所示。
为了缓解过拟合问题,本文在模型训练时使用了dropout,其思想是按一定概率,随机选取神经层的一些神经元进行隐藏,下次训练时,又隐藏另外选取的神经元。Dropout的值对训练结果影响较大。
IDCNN [16]:作用于BiLSTM类似,用来捕捉长序列文本的上下文信息。IDCNN是对卷积神经网络(CNN)的改进,在局部信息丢失的情况下,利用空洞来捕捉文本上下文特征。IDCNN优势就是时间复杂度低,可以提高模型的运行效率,即使在并行情况下,处理长度为N的句子,处理的时间复杂度只需O(N),可以缩短模型预测时间。
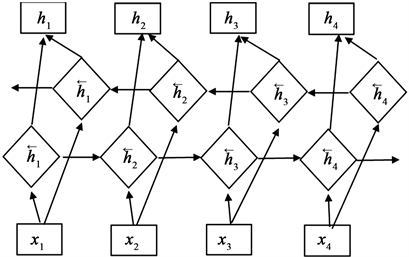
Figure 2. Bidirectional LSTM structure
图2. 双向LSTM结构
3.3. 解码层
本层主要学习标签之间的约束关系,以提高标签预测的准确率,进行全局最优提取。本文主要识别三类实体:Java基础类(BAS)、Java扩展类(EXT)、实例类(SPE)。文本采用的是BIO标注方法,例如:“修饰符”的标注应为[B-BAS, I-BAS, I-BAS],但模型预测结果若为[B-BAS, I-EXT, I-BAS],明显不符合常理。因此解码层的作用,主要是为了修正上述标签之间约束关系问题。此模型解码层使用的是CRF。
CRF模型本身就是一个非常优秀的序列标注模型,在多项任务中表现出色 [25]。CRF模型适用于整个句子,而不是单个字的位置。假设输入为
,BiLSTM预测的标签序列为
(n为句子长度),
就表示每个字的标签。计算序列概率如公式(6):
(6)
若f为打分函数,
代表相邻位置的转移矩阵,代表标签从n − 1位置转移到n位置的可能性。h是CRF层从BiLSTM处得到的预测每个字的标签概率的发射矩阵。计算打分方法如公式(7):
(7)
为归一化因子,若我们考虑g和X无关,序列概率如公式(8):
(8)
BiLSTM-CRF模型,通过BiLSTM层学习上下文信息,使用CRF层学习标签于标签间的相关性,得到标注信息,计算得分进行反向传播,最后得到最优的标注信息。
3.4. 多模融合
由于单个模型的局限性,其命名实体识别的准确性受限。本文提出基于集成学习的对多个异构单模的结果进行融合互补的思路,以提高最终识别结果的准确性和泛化能力。
主要思路:
1) 针对解决同一个问题,构建出多个异构单模。
2) 设置融合模型个数,设置阈值过滤概率得分极低的模型,防止成为噪音。因为模型相对于其他模型效果太差时,该模型会成为噪音。根据模型的评估得分来设置模型加权系数。
3) 对多个单模进行软投票,输出预测准确率与预测标签。
整个模型的处理流程如图3所示:
4. 实验
4.1. 数据集
本文所使用的数据集是自主构建的,文本数据来源为两部分:Java基础知识部分来自菜鸟教程网站1。Java扩展知识部分来自C语言中文网2,包括Java设计模型、Spring、SpringBoot、Maven等方面。这些数据资料知识点全面、内容丰富,并且网页数据编排合理,在计算机领域影响力较强。数据集全文共包含46316句文本信息,划分为80%的训练集和20%测试集,并对训练数据集进行五折交叉验证分割。按照BIO规则进行信息标注,B代表实体的开始,I代表实体的中间及边界,O代表其他,即非实体的部分。根据Java知识体系结构,很容易对实体进行分类,本文识别任务分为三类:Java基础类(BAS)、Java扩展类(EXT)、实例类(SPE),三类实体和一个非实体标签共计7个标签,即B-BAS,I-BAS,B-EXT,I-EXT,B-SPE,I-SPE,O。标签具体设置如表1所示:
Table 1. Label settings
表1. 标签设置
4.2. 实验环境
硬件环境配置如表2:

Table 2. Hardware environment configuration
表2. 硬件环境配置
软件环境配置如表3:
Table 3. Software environment configuration
表3. 软件环境配置
4.3. 参数设置
模型参数设置如表4:
4.4. 评估标准
本文采用三种评估方式 [26],分别为准确率P (Precison)、召回率R (Recall)和F1,具体如公式(9~11):
(9)
(10)
(11)
其中,
表示识别正确的实体数量,
表示识别错误的实体数量,
表示未正确识别出的实体数量。P代表在所有实体中准确识别出来的百分比,其也被称为查准率。R代表在所有的样本中,被正确识别出的实体的占比,也被称为查全率。但P、R两个指标有时会发生矛盾的情况,因此引入了F1值,其是综合P和R两者的评估指标,用来反映整体的综合情况。
4.5. 实验结果和分析
改进的模型和其他主流模型进行对比,实验结果如表5:
Table 5. Single mode comparison experiment
表5. 单模对比实验
单模不同类别的F1值如图4所示:
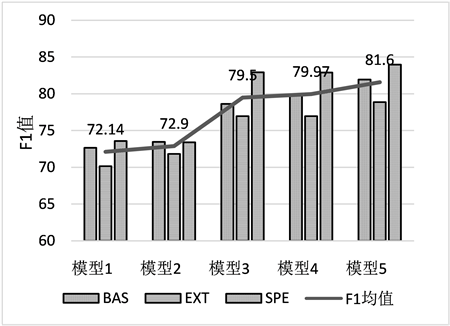
Figure 4. Comparison results of single-mode F1
图4. 单模F1对比结果
通过实验可以看出来,模型1和模型2的结果不太理想,加入预训练模型Bert后,效果得到显著的提升。从编码层模型的选择来看,BiLSTM和IDCNN区别也不是很明显。加上融入边界信息的本模型,单模效果比现有主流模型3和4的F1值提升了约两个百分点,从实验结果看效果还是可以的。
从实体识别的类别来看,实例名预测的准确率最高,其原因可能在于相比另外两种实体,实例名特征最为明显,容易被识别出来。Java扩展实体类预测的准确率偏低,其原因可能在于Java的扩展领域知识点冗杂,并且普遍存在简写缩写名称,模型难以进行准确地预测。融入边界信息后的模型对扩展类识别准确率提升很大。
多个异构单模的多模融合结果如表6所示:
Table 6. Multi-mode comparison experiment
表6. 多模对比实验
多模不同类别的F1值如图5所示:
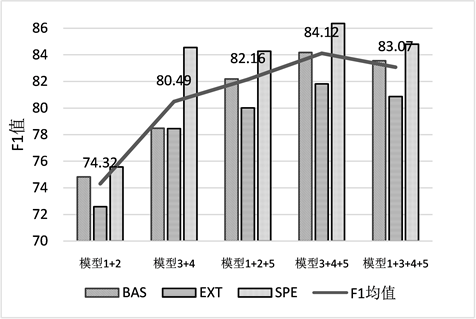
Figure 5. Comparison results of multi-mode F1
图5. 多模F1对比结果
通过图5的实验结果可以看出来,并不是融合的模型个数越多效果就越好,模型1 + 3 + 4 + 5这4个模型相融合的结果还不如模型3 + 4 + 5这3个模型的融合结果好,原因可能在于模型1的预测结果比较差,拉低了整个模型的准确率。
从实体识别的类别来看,多模融合在扩展类提升并不是很大,原因可能在于本来单模效识别效果不是很好,两者识别是错误的,那么融合结果可能也是错误的。但融合之后在实例类、基础类实体识别的准确率有所提升,单模准确率高,融合之后识别结果会更接近正确预测。
5. 结论
由于Java领域缺少开放的数据集,本文进行了相关数据爬取,人工标注了4万多句标签信息。本文针对Java领域实体识别独有特点,提出了融入词性信息和相关规则的模型,以提高Java领域实体边界识别的准确率,通过实验结果证明了改进后模型的有效性。
考虑到单个模型具有局限性,本文将多个异构单模结果进行加权融合,以提高模型的泛化能力和识别准确性。从整体的实验结果中可以看出Java领域的实体识别准确率还有提升的空间,未来我们可以考虑加上图神经网络融入更多的文本信息,并且对模型进行剪枝、蒸馏等操作,进一步降低模型的时间复杂度和空间复杂度。
基金项目
辽宁省教育厅基金(lnqn202015),面向生物大数据的局部近似匹配技术研究。
NOTES
1菜鸟教程网址:https://www.runoob.com/。
2C语言中文网址:http://c.biancheng.net/sitemap/。