1. 引言
近年来,由于生产工艺的快速发展,文物交易市场充斥着大规模数量的仿造品,仿造品的出现不仅严重破坏了文物交易市场的秩序,也在很大程度上破坏了文物的传承与保留 [1]。文物鉴定作为一门专业性极强的学科,目前学者对文物鉴定具体方法的研究大多停留在理论方法阶段,这种主观判断方式使得一些非法鉴定机构有机可乘,故建立科学的文物识别模型对文物收藏及考古研究都具有重要意义。唐迎菲(2015)提出分类鉴定法与综合考察法来对文物样品进行鉴定,并探讨了现代科学技术在文物鉴定中的应用 [2]。王迪(2019)提出了利用微信等新媒体在书画文物鉴定中的应用,使文物鉴定活动不再受限于某一特定场景,以期提高书画文物鉴定的水平 [3]。李擎(2019)指出三维成像技术和激光与光电透视技术这类现代技术对于文物鉴定效率的提高具有极大意义 [4]。段继霞(2020)认为可以将图像识别技术与AR技术相结合,利用边缘检测法来提取文物主题图像,为用户展示更生动的文物信息 [5]。郭美玉(2021)提出文物鉴定方法应紧跟时代步伐,同时应重视新技术科技在该领域的应用 [6]。
纵观以上文献,不难发现文物识别方式逐渐由理论识别到科学技术识别转变。本文在此基础上将理论知识、科学技术与数学分析相结合,以玻璃为例,选取玻璃文物制品进行化学成分分析,构建了基于主成分分析-BP神经网络的玻璃文物识别模型,为玻璃文物样品的鉴定提供了科学的数学依据。玻璃作为古代文化交流的物证,其象征着中西方文化交流史上的一颗明珠,对未知玻璃化学成分体系的确定以及类型识别是中国玻璃研究中极为重要的一个领域 [7]。研究玻璃文物类型的鉴定不仅可以对中国玻璃文化有更深入的见解,同时也可以应用数学理论来探索文物背后的经济价值与文化底蕴,以期为文物交易市场的规范化与标准化发展提供参考。
2. 文物识别模型准备
2.1. 数据选取
本文选取了一批我国古代玻璃制品的相关数据,共计68个样本,其类型主要分为高钾玻璃和铅钡玻璃两种,其中部分样本由于表面风化而受损,后续将对该部分数据进行修复。各个样本的主要成分与对应所占比例已知,共计14种化学成分,将依据这些数据进行数学分析。
2.2. 数据预处理
查阅文献得知,玻璃文物样品检测的各成分累加之和应介于85%~105%之间,不在该范围内的样品不符合研究条件,故需要对样本数据进行筛选。最终剔除了两个样本数据,编号为15和17,剔除不符合要求的数据后,共计66条有效样本数据。
2.3. 数据修正
加权平均预测模型
考虑到受埋藏环境的影响,部分玻璃文物表面受损(出现风化),导致其化学成分比例发生变化,造成文物样品中部分受损玻璃的化学成分比例出现误差,影响了对玻璃类别的准确判断,故需要对受损玻璃文物化学成分比例数据进行修正。本文采取加权平均对受损玻璃受损前的化学成分进行预测,以得出更为准确的判断结果。
首先利用SPSSPRO软件对高钾类和铅钡类文物数据进行整合。接着,对高钾玻璃文化与铅钡玻璃文化风化前后的化学成分进行频率分析,使用Matlab求解,得到的结果如图1所示:

Figure 1. Histogram of frequency distribution of chemical composition of different types of glass before and after damage
图1. 不同玻璃类型分化前后化学成分分析的频率分布直方图
在上图频率直方图的基础上进一步分析,发现部分样品化学成分未被检测到,即含量为“0”值,这些数据对我们进行预测会造成一定阻碍,因此在这里对数据进行加权平均值处理,并使用标准正态分布函数对其进行权重的分配 [8],标准正态分布曲线函数公式如下:
(1)
其中x为连续型随机变量。具体计算过程如下:
按顺序定义风化之前二氧化硅(SiO2)、(氧化纳)(Na2O)、氧化钾(K2O)……二氧化硫(SO2)等共14个变量分别为
,定义其权重为
,同理将风化后化学成分定义为
,权重为
。接着将化学成分的数据与标准正态分布函数相乘,计算其加权平均值如下:
(2)
再定义其风化前后每个化学成分的加权占比指标为
,则:
(3)
利用该方法对受损后文物样品受损前的化学成分进行分析,以此得到更为准确的文物化学成分含量,提高后续文物识别模型的精度。
2.4. 化学成分相关数据分析
斯皮尔曼相关系数
对于相关系数的选择,由于本文所研究的化学成分变量不满足正态分布与线性关系,故采用斯皮尔曼相关系数进行相关性分析 [9],具体定义如下:对任意两个化学成分变量进行分析,对应列向量记为Y、X;将各个列向量对应的元素
与
转换为对应列向量的排序,记为
和
;列向量的长度记为N。利用公式分别计算列向量Y列向量
对应元素
和
之间的差异并分别求和,得到化学成分等级之间的差值
:
(4)
依据下面公式计算各化学成分之间的相关性
;
(5)
3. 主成分-BP神经网络识别模型的构建
3.1. 主成分分析数学模型
当前对玻璃类别的划分依据主要依据文物样品的化学成分,本文采用主成分分析法分别提取不同类别文物样品化学成分中的主成分。用
分别表示已知文物样品中的各类化学成分,用
分别表示文物编号,第i种文物
的取值记作[
],构造矩阵
,具体步骤如下:
Step 1:对玻璃文物的数据进行标准化处理,将各指标值
换成标准化指标
;
(6)
其中
;
,
为第j个指标的样本标准差和样本均值。
(7)
(8)
相应的称
为标准化指标变量。
(9)
Step 2:对相关性矩阵进行计算。相关性矩阵
,其中:
,
,
为第i个指标与第j个指标的相关系数。
(10)
Step 3:对特征值和特征向量进行计算。求出相关性矩阵
的特征值
及对应的标准化特征向量
,其中
,由特征向量组成14个新的指标变量,其中
代表第i个主成分。
(11)
Step 4:选择前5个主成分来计算评价的综合值。计算特征值
的信息贡献率和累积贡献率 [10],主成分
的信息贡献率为:
(12)
的累积贡献率为:
(13)
当
接近1时,则选择前p个指标变量
作为p个主成分,代替原来的14个指标变量,从而可对p个主成分进行综合分析。并计算综合得分:
(14)
式中:
为第j个主成分的信息贡献率,根据综合得分值就可进行评价。利用matlab软件求得相关性矩阵前5个特征值与贡献率,结果如表1所示:

Table 1. Principal component analysis results
表1. 主成分分析结果
由表1可知,前5个特征根的累积贡献率在74%左右,可初步认为这些主成分能充分表达样本数据所包含的信息。后续将选取这5个主成分进入BP神经网络进行学习。同时得出了主成分系数得分矩阵,便于后续权重分析,具体数值如表2所示:
Table 2. Component score coefficient matrix
表2. 成分得分系数矩阵
由此可得5个主成分分别为:
(15)
3.2. BP神经网络基本原理
BP神经网络是依据误差反向传播算法的多层前馈神经网络,其运作的基本原理是信号前向传递,误差反向传播 [11]。大体上可以分为3层,其中输入层各神经元的输入输出关系大多为线性函数,隐层的大多为非线性函数。其运作的具体步骤是输入i个学习样本
,在对应输出层样本类别已知的前提下,利用BP学习算法,通过梯度下降法不断调整输入层与隐含层,隐含层与输出层之间的连接权值,使其沿着目标函数的负梯度方向转变,以达到输出层误差平方和最小的目的。
3.3. BP神经网络算法训练
依据上述原理,结合上述主成分分析结果,向BP神经网络输入主成分[
]设置5个输入层结点,从输入层经由隐层可得输出数据
。BP神经网络有两个关键函数,激活函数与误差函数,其中激活函数一般使用S型函数,即
(16)
误差函数的公式为:
(17)
具体字母定义如表3:
Step 1:初始化。对每个连接权值赋值,赋值区间为(−1, 1)内任意随机数,误差函数设定为e,最大学习次数为M,计算精度值为
;
Step 2:任意输入m个样本,得到相应的期望输出;
(18)
(19)
Step 3:对给每个神经元输入值和输出值进行计算;
(20)
(21)
其中
;
。
Step 4:分析实际值与期望值的偏差,得到输出层各神经元误差函数的偏导数
;
(22)
(23)
(24)
Step 5:借助隐含层与输出层的连接权值与输出层的
得出隐含层各神经元误差函数的偏导数
;
(25)
(26)
(27)
(28)
Step 6:反向传播,借助输出层误差函数修正连接权值
;
(29)
(30)
Step 7:借助隐含层的误差函数修正连接权值;
(31)
(32)
Step 8:对全局误差进行计算;
(33)
Step 9:直至计算误差小于实际误差后停止训练。
4. 模型的检验
4.1. 模型检验的步骤
利用上述已经建立好的PCA-BP神经网络识别模型,采用PCA原理对BP神经网络的输入层进行主成分分析,在主成分累计贡献率达74.206%的情况下对玻璃文物化学成分样本空间进行重构,提高了模型识别的精度。对于未知类别的玻璃文物数据,可将主成分值以及归一化原始样本作为检验样本输入已经训练好的PCA-BP神经网络文物识别模型,具体步骤如下:
Step 1:首先利用主成分分析法提取出前5个主成分的得分S1;
Step 2:以S作为学习样本,进入BP神经网络进行学习,构建PCA-BP识别模型;
Step 3:取表单3样本数据,按照步骤1的方法计算出主成分的得分S2;
Step 4:在已构建好的PCA-BP识别模型输入主成分S2,即可输出文物样品的类别;
将输出文物的类别与文物真实类别进行对比,结果一致。
4.2. 模型结果分析
由下图可以分析出,训练数据的R方值接近于99.5%,说明利用该模型所得的拟合优度非常高,模型具有较高的合理性,具体分类规律见图2。
5. 结语
本文利用主成分分析与BP神经网络相结合,建立了玻璃文物样品类别识别模型。该方法可用于对未知玻璃文物的类别的样品进行有效鉴别。主成分分析作为一种常见的多元统计分析方法,其通过对指标降维,达到化繁为简的目的。BP神经网络是一种能解决复杂的非线性关系的数据分析预测和性能优化问题的模型,在主成分分析与BP神经网络相结合的条件下对玻璃文物进行鉴定,通过BP算法来对误差
进行调整,
,此时
,即当误差对权值的偏导数小于零时,权值调整量为正,使得实际
输出与期望输出的差减少,反之亦然,由此提升鉴定的准确性。但由于BP算法是以局部改善进行权值调整的,故容易陷入局部最小化问题,同时对神经元与隐藏层个数的选择不同可能会对模型识别结果产生影响,未来可通过改进学习率参数的调节方式来优化模型,以期达到更好的识别效果。
 (a)
(a) 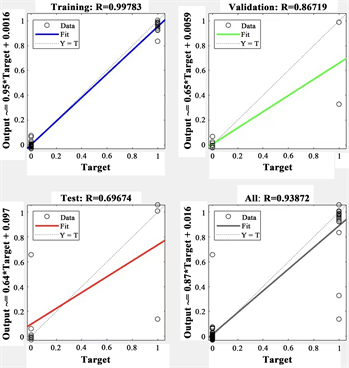 (b)
(b)
Figure 2. Fitting results after neural network training
图2. 神经网络训练后的拟合效果
另外本文所建立的主成分分析-BP网络识别模型可以推广到很多实际问题中,如对煤岩表面化学成分的识别,未来也可拓展到军事上、考古文学上、股价预测上等,具有很高的应用价值。