1. 引言
在全球范围内,肝癌以往一直是让医学界非常棘手的癌症,根据世界卫生组织国际癌症研究机构(IARC)发布的2020年全球癌症发病情况分析报告中指出肝癌的发病率在全球第六位,而其死亡率则高达第三。尽管在科技日益发达的今天,我们也丝毫不能小觑肝癌对人类健康的影响。目前肝癌新发病例的发生率为每年每100,000名男女9.5例。死亡率为每年每100,000名男女6.6人。
肝癌是指原发于肝脏组织细胞的恶性肿瘤。由于肝脏里有肝细胞、胆管细胞、间质细胞等等,所以其实肝癌可以细分为好几种 [1]。主要有两种:一种是来源于肝细胞的肝细胞癌,占到80%以上;另一个就是来源于胆管细胞的肝内胆管细胞癌(因此本质上是胆道肿瘤),占到10%~15%。近30年肝内胆管癌(ICC)的发病率在全世界范围内呈明显上升趋势。肝内胆管癌发病隐匿,极易侵犯肝脏周围器官、组织和神经,发生淋巴结和肝外远处转移,大部分病人确诊时通常已处于晚期,缺乏有效治疗方法。对于部分早期肝内胆管癌病人,肝切除治疗已获得广泛肯定。然而,即使行根治性切除术,肝内胆管癌术后仍然极易复发和转移,病人术后5年总体生存率为25%~40%,预后远差于肝细胞癌 [2]。
通常来说,诊断时的癌症阶段也就是体内癌症的程度,决定了治疗方案,并对生存期的长短有很大的影响。一般来说,如果癌症只在它开始的身体部位被发现,它就会被定位(有时称为第一阶段)。如果它已经扩散到身体的不同部位,则该阶段是区域性的或远处的。肝内胆管癌越早被发现,一个人在被诊断出5年后存活的机会就越大。对于肝内胆管癌,43.9%在局部分期时被诊断出来。而局限性肝内胆管癌的年相对生存率为36.1%。这也是相比其他癌症阶段最高的生存率了。
随着医学技术的进步,肝癌现有的治疗方法日新月异。目前肝内胆管癌的治疗方法主要包括:手术治疗、肝移植、消融治疗、放射治疗、化学疗法、靶向疗法、免疫疗法 [3]。根据病人的病情选择不同的治疗方法能最大化有益于患者的身体健康,所以如何选择最合适的疗法显得尤为关键。
当得知了患者所处的癌症阶段后,通过病情以及患者信息判断得出最有效的治疗方法显得尤为重要。鉴于上述内容,本文选取了2538例来自于SEER数据库中的肝内胆管癌患者信息进行生存分析研究,通过建立预测模型基于患者不同的病情等信息对患者生存时间和生存状态进行预测。
2. 数据与方法
2.1. 数据来源
本文的数据是来自于SEER即美国国家癌症研究所监测,流行病学和最终结果数据库(https://seer.cancer.gov),这个数据库主要包括了人口统计数据、患者的个人临床信息、肿瘤种类、治疗方式以及生存状态等。本文通过SEER*Stat软件来获取相关所需数据模块,在案例表格板块(Case Listing Session)下载2005年至2014十年间诊断的所有肝内胆管癌病例,共计2538例患者信息。其中,患者纳入选择的标准如下:1) 患者确诊年份在2005年至2014年之间;2) 根据国际疾病分类肿瘤学专辑第三版(ICD-O-3)原发部位选择肝内胆管;3) 镜下证实的原发性肝内胆管癌;4) AJCC的T分期从T1到TX;5) 年龄大于20岁。最终本文数据纳入的变量包括:性别、种族、年龄、美国癌症联合委员会(AJCC) T、N、M分期、肿瘤大小、区域淋巴结数量、切除的淋巴结总数、淋巴结转移数目、总体转移数目、肿瘤总数、生存时间、生存状态。
2.2. 数据说明与预处理
本文一共选取了14个变量,其中生存时间和生存状态作为本次模型预测对象,另外12个变量均为自变量,上述变量选择都基于常用的临床病理参数。由于下载的年龄数据被细分为5年一个阶段,经过初步数据分析,大部分患者年龄在50岁以上,其中70岁以上的患者也占多数,于是将年龄分为3个阶段:20~49岁,50~69岁,70岁以上。具体变量说明如表1所示。

Table 1. Variable description and assignment representation
表1. 变量说明及赋值表示
在整理数据的过程中存在一些缺失值或者空值,考虑到数据较多的变量,则用其他数据的平均值或者0代替填入,对于丢失数据较少的变量,则直接删除掉该病人的所有信息。另外,对于生存结局变量,令死亡 = 2,存活 = 1。为了测试模型精度,将数据集70%划分为训练集,30%为测试集。
2.3. 模型选择
Cox模型全称比例风险回归模型,以生存结局和生存时间为因变量,它可同时分析多个因素对生存时间的影响,分析存在部分信息缺失的资料且不要求资料的分布类型。因为我们将进行的是对肝内胆管癌预后的多因素分析,所以毫无疑问Cox模型是一个不错的选择。
事实上,目前为止Cox模型已经广泛应用于生存分析中,尽管有不错的效果,但随着计算机辅助智能诊疗技术的飞速发展,机器学习方法可以通过从大量、丰富的医疗数据中学习,不依赖固定的、简易的建模规则,并在多种临床情境下展现出巨大优势。但是由于多数机器学习算法的内部结构并不透明,在可解释性方面远差于传统的回归模型即这里谈到的Cox模型,因此机器学习方法并不易于被临床医师理解与接受,更不用说应用了。梯度提升机(GBM)是机器学习分析中常用的方法,该算法由大量简单的决策树集合而成,具有较高的可解释性。因此,本文将在使用Cox模型的基础上,完成对梯度提升机模型的构建,旨在对比模型效果,为优化肝内胆管癌预后评估提供新思路与新方法。
同时,我们提到由于机器学习方法的可解释性受到质疑,所以本文在应用可解释性较高的梯度提升机的同时想到了建立另一可解释性不高的机器学习模型加以对比,即B-P神经网络模型。
3. 模型预测结果实证分析
本章主要是对选取的癌症病人数据进行生存分析,在利用Cox比例风险回归模型做预测的基础上,通过对机器学习方法的探索,采用梯度提升机以及神经网络模型对病人的生存时间和生存状态进行预测,同时分析了不同因素对其生存概率的影响。
3.1. Cox比例风险回归模型
3.1.1. K-M生存曲线
1) 不同性别的生存特征
不同性别的患者的生存概率是具有差异性的(p < 0.05),如图1。可以看出其中女性的生存概率总体上是高于男性的,这也是一个可以值得研究的点。在生存时间少于5个月的患者中生存概率一样即性别差异是不明显的,同样当生存时间超过120个月时性别也不具有差异了。男性的生存时间中位数为5个月,而女性生存时间中位数为6个月,这也说明男性平均生存时间要短于女性。

Figure 1. K-M survival curves of different genders
图1. 不同性别的K-M生存曲线
2) 同种族的生存特征
人种方面主要分为白种人和黑种人以及其他种族。由图2的生存曲线可以看出白种人的生存概率是明显高于黑种人和其他种族的,尤其是在生存时间在0至60个月区间的时候。但同时也应关注到另一事实就是,虽然白种人生存概率高,但是患病人数远远高于黑种人和其他种族,在抽取的样本中,白种人患病数是其他种族的4倍,这也与美国本地种族比例有密切关系。另外,白种人生存概率高的同时意味着黑种人的死亡风险比率过高。
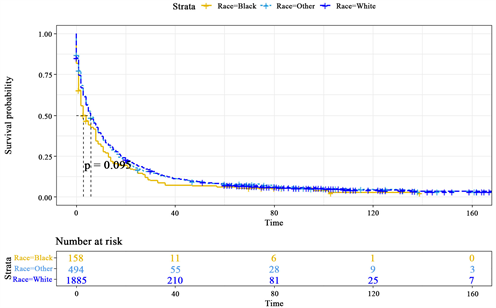
Figure 2. K-M survival curves of different races
图2. 不同种族的K-M生存曲线
3) 同年龄的生存特征
对于不同年龄段的患者,如图3,本文根据样本数据量大小将年龄分为3个段:20~49岁,50~69岁,70岁以上。经过年龄段划分,明显看出3个年龄段的生存概率截然不同,首先年龄从小到大,其每个时期的生存概率均呈现从大到小,其次生存时间中位数方面,老年人的生存时间明显大打折扣,仅为3个月左右,远低于年轻人的预后表现。再者老年人的生存概率在60个月后基本为0。

Figure 3. K-M survival curves of different ages
图3. 不同年龄的K-M生存曲线
4) 同T分期的生存特征
TNM分期系统是目前国际上最为通用的肿瘤分期系统,也是临床上进行恶性肿瘤分期的标准方法。图4中由于T0分期的患者数过少不予考虑,其余生存率最高的是T1分期的患者,其次是T2分期、T3分期、T4分期生存率从高到低,这与其肿瘤分期大小也息息相关。另外,TX分期的患者肿瘤情况未知,但生存率是最低的,某种程度上说明其肿瘤程度相对严重以至于死亡率高于其他T分期患者。

Figure 4. K-M survival curves of different T stages
图4. 不同T分期的K-M生存曲线
5) 同N分期的生存特征
本次选取的数据量中N分期的患者只有3种类型,如图5,其中N0表示没有区域淋巴结转移的患者,所以明显看到处于N0分期的患者生存率是最高的,而N1分期的患者生存率较N0分期的患者大幅度下降,在40个月后生存概率基本为0。NX分期表示区域淋巴结未知状况,同T分期一样,生存率远低于另外两分期状态。也说明未知状况下的淋巴结转移状态是更差的。
6) 同M分期的生存特征
M分期表示的是远端转移的情况,图6中M0分期表示无远处转移,显而易见,其生存概率明显高于处于其他分期的患者,M1分期的患者表示有远端转移的迹象,生存概率也大打折扣,与位于MX分期即未知远端转移情况的患者生存概率不相上下,在40个月后其死亡率也基本接近100%。
3.1.2. 单因素与多因素分析
本节对数据进行单因素和多因素分析,分析的变量与分析生存曲线的变量相同,由于这里主要是对分类变量进行分析,故并未将区域淋巴结数量、切除的淋巴结总数等数值变量纳入Cox风险模型的构建中。此处的因变量则是生存时间和生存状态。
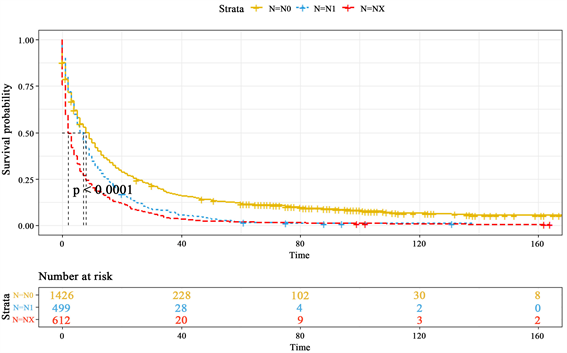
Figure 5. K-M survival curves of different N stages
图5. 不同N分期的K-M生存曲线
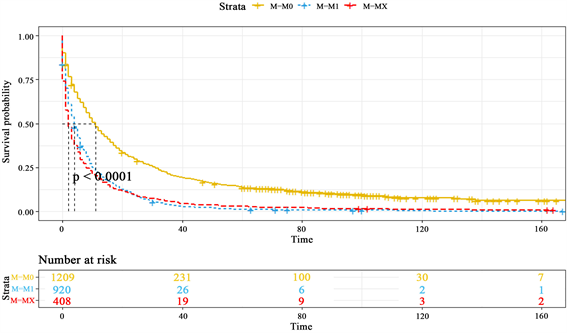
Figure 6. K-M survival curves of different M stages
图6. 不同M分期的K-M生存曲线
从单因素分析表2中可以看出,年龄、性别、种族、N分期、M分期以及肿瘤总数6个变量均通过了显著性检验,只有T分期中所有变量均为通过显著性检验(p > 0.05)。首先观察年龄变量,得出年龄越大,其死亡风险越高,并且其变化率是迅速增长的,大于70岁的老人的死亡风险比20~49岁的年轻人高了一倍不止(HR = 2.099)。性别方面男性确实比女性死亡风险大,但是差异不是特别明显。对于种族来说,白种人总体死亡风险明显小于黑种人以及其他种族,这也说明白种人的预后是更好的。T分期中表示肿瘤大小与死亡风险之间没有较强联系,这也许与肝内胆管癌的特殊性有关,在本文中不加以讨论。N分期和M分期都是关于肿瘤转移的信息,其中处于N1分期的患者死亡风险是N0分期患者的1.37倍(HR = 1.37),而处于NX分期的患者是N0患者的1.95倍(HR = 1.95)。对于M分期而言,处于M1和MX分期的患者的死亡风险较M0患者而言均高达2倍左右。
在多因素分析表中,与单因素分析中变量影响基本一致,除了T分期没有通过显著性检验之外,其他变量均通过了显著性检验。总体来看,年龄越大死亡风险越高,并且不同年龄段的死亡风险有显著差异,对比单因素,死亡风险均有提升。而同时,其他多个变量的死亡风险较单因素都有不同程度的下降。
Table 2. Univariate and multivariate analysis tables
表2. 单因素与多因素分析表
3.1.3. 预测模型的构建
根据多因素分析可以完成对Cox预测模型的构建,将未通过显著性检验的变量即T分期变量移除掉(p > 0.05),纳入变量为:性别、年龄、种族、N分期、M分期以及原发或恶性肿瘤总数。确定的模型如下:
其中
表示原发或恶性肿瘤总数,
表示T分期的五个阶段,
表示N分期的两个阶段,
表示M分期的两个阶段,
表示种族,
表示年龄,
表示性别中的男性。
基于上述模型,对其进行显著性检验,模型的显著性检验结果如下表3。可以看到三种检验方式的p值都远低于0.05,这说明模型通过了显著性检验,而且模型整体效果不错,表示这6个变量能够相对合理的对因变量即生存时间或生存状态完成预测。
接下来基于上述模型我们可以完成列线图的绘制。由于患者生存时间有限,我们希望知道患者能存活到某个时间点之后的概率,于是本文完成了对患者诊断后生存6个月、18个月和36个月的生存概率的预测。这里生存截止时间点是基于本次论文的数据生存时间分布来选择的,其中有50%以上的人生存时间不足6个月,70%以上的人生存时间不足18个月,90%的人生存时间不足36个月。
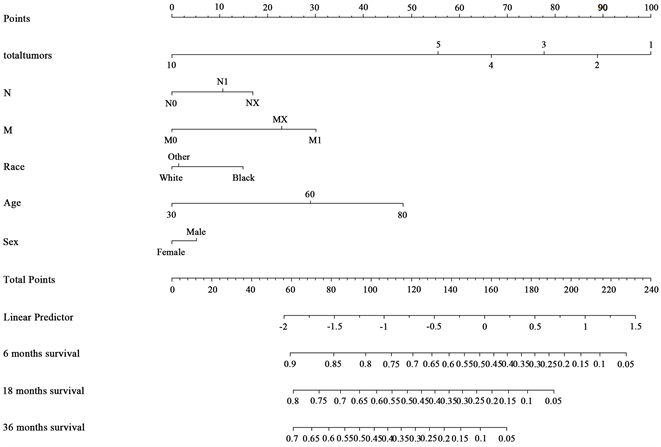
Figure 7. Patient survival prediction nomogram
图7. 患者生存率预测列线图
图7给出了患者不同特征信息对应的不同生存时间的生存概率,上图表示每个患者不同的特征信息对应第一行的分数刻度,每一个预测变量都有对应的分数,然后将所有预测变量的分数相加,根据总分数可以得到对应不同生存时间的概率。举个例子:一个60岁的女性患者,她是白种人,处于N1分期和M1分期,一共有5个肿瘤。那么他的分数为:30 + 0 + 0 + 10 + 30 + 55 = 125分,那么可以得到她6个月的生存概率为0.65,18个月的生存概率为0.4,36个月的生存概率为0.25。
3.1.4. 预测模型的验证
1) ROC曲线
图8中左右两图分别是此次预测模型关于训练集和预测集的ROC曲线图。训练集的ROC曲线图对应的6个月、18个月、36个月AUC为0.447、0.458、0.458,而测试集对应的6个月、18个月、36个月AUC为0.363、0.274、0.274,整体预测效果差于训练集。两者的值都偏低,训练集与测试集表明模型预测效果不佳,总体预测效果较差。
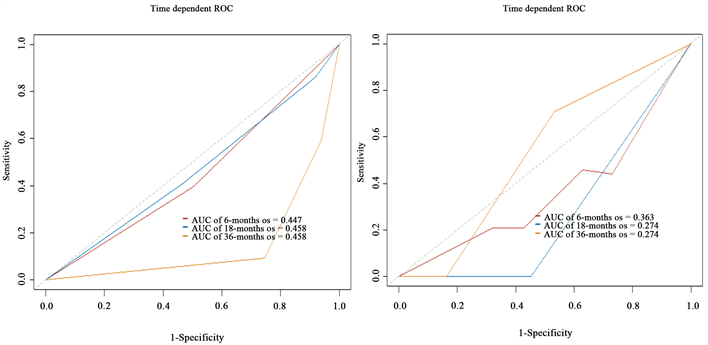
Figure 8. Cox training set and test set patient ROC curve
图8. Cox训练集与测试集患者ROC曲线图
2) 校准曲线
图9~11分别描述的是患者生存时间分别为6个月、18个月、36个月的校准曲线图。比较明显的是患者6个月的校准曲线图较大程度上偏离了对角线,预测效果不佳,虽然预测结果波动不大,但是预测生存概率总体偏低太多。对于患者18个月的校准曲线可以看到,预测生存概率相对贴合,但预测总体生存概率仍然偏低。相反的是患者36个月的校准曲线图,整体预测概率偏高。
综上可以看出,不论是短期预测还是长期预测效果都不会太好,尽管长期预测效果看上去还过得去,但总体也比较一般。考虑到本次数据选取量并不大,并且偶然性较大,后续模型将仅对患者生存36个月时间进行长期预测。
3.2. 梯度提升机模型
3.2.1. GBM模型构建与验证
本节将基于训练集患者的数据对患者生存结局进行总体预测,共12个临床病理特征纳入GBM模型分析。通过顺序后向搜索法,GBM算法从中筛选出5个重要特征:年龄、原发或恶性肿瘤数目、肿瘤大小、区域淋巴结数量、切除的淋巴结总数(图12)。
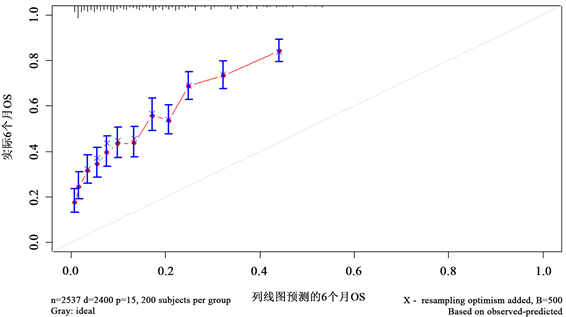
Figure 9. 6-month calibration curve graph for the patient
图9. 患者6个月的校准曲线图

Figure 10. 18-month calibration curve graph for the patient
图10. 患者18个月的校准曲线图
基于上述变量构成的模型计算后可以得到最佳迭代次数,由图13可以看出迭代到第839次时,模型表现不再有进一步的提升,因此最佳迭代次数为839。
3.2.2. GBM模型评价
图14左右两图分别表示患者生存36个月的训练集以及测试集模型预测ROC曲线图。训练集的模型拟合效果要优于测试集,但总体差距不大,AUC均超过0.7,表明模型预测效果较好,整体区分度不错,与Cox风险回归模型相比,尽管只预测了36个月的生存数据,效果也明显好于前者,梯度提升法是一个更优选择在模型拟合方面。

Figure 11. 36-month calibration curve graph for the patient
图11. 患者36个月的校准曲线图

Figure 14. GBM training set and test set patient ROC curve
图14. GBM训练集与测试集患者ROC曲线图
3.3. 基于B-P算法的神经网络模型
与前两节的模型构建不同的是,神经网络模型的变量选择方面比较灵活,这里考虑的变量选择重点是在临床病理特征上,新纳入了肿瘤大小、区域淋巴结数量、切除的淋巴结总数、淋巴结转移数目、总体转移数目多个变量,在之前的多因素分析中,由于年龄也属于一个较强的影响因子,这里同样将其纳入预测变量中。因变量则是患者的生存状态:死亡或者存活。
3.3.1. 神经网络模型构建
图15中,可以清楚看到,本次模型一共有7个预测变量,这里的模型一共有两个隐藏层,其中一个隐藏层有5个节点,另一个有3个节点。图中的数字表示每个节点的权重,用以预测最终36个月的生存结局。
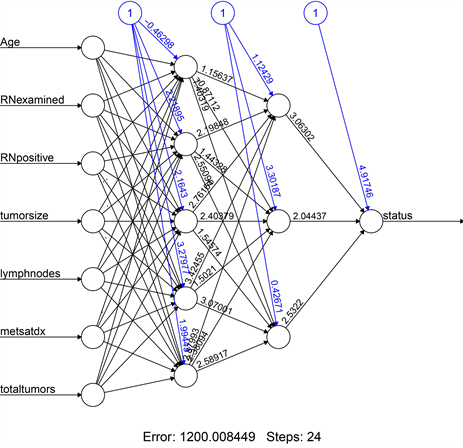
Figure 15. A neural network model for predicting patient survival at 36 months
图15. 患者36个月的生存率预测神经网络模型
3.3.2. 神经网络模型评价
图16左右两图分别表示对患者生存36个月的训练集以及测试集模型预测ROC曲线图。在训练集方面,神经网络模型的预测表现很好,AUC值为0.841。测试集AUC的值为0.816,略高于训练集的值,但是也足以说明模型的拟合效果不错,整体预测精度也较Cox风险回归模型和梯度提升模型大幅上升。
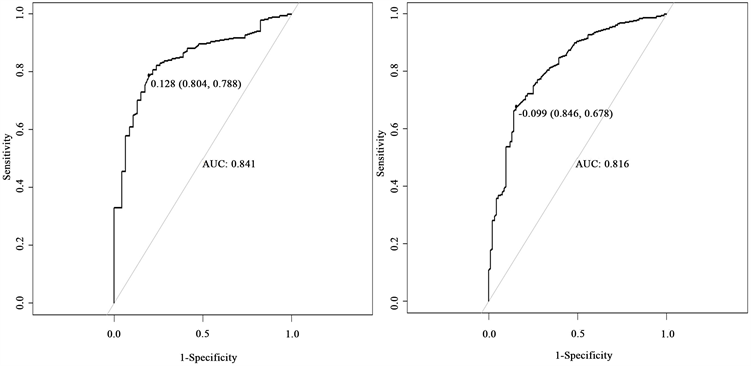
Figure 16. Neural network training set and test set patient ROC curve
图16. 神经网络训练集与测试集患者ROC曲线图
3.4. 模型对比
本节一共运用了3个预测模型对患者的生存时间以及生存状态进行预测,Cox风险回归模型中使用的大多数变量都是分类变量,例如性别、年龄、种族等,通过单因素与多因素分析以及K-M生存曲线分析每个变量不同类别的独立性差异,筛选出对模型影响最多的预测变量构建模型。最后得到的Cox风险回归模型ROC曲线以及对应的校准曲线表明,ROC曲线下的AUC值实在偏低,远没有达到预期的预测目的,而校准曲线方面也说明离正确值偏离较多,模型整体还有待改进。
梯度提升法模型在变量选择的过程中将12个变量均纳入其中,模型筛选出了5个最重要的预测因子,并且给出了最佳迭代次数。由于考虑到进行短期预测效果并不会很好,所以只对36个月患者生存时间的生存概率进行了预测,跟预想的效果一样,对长期生存时间的预测是比较准的,相应ROC曲线的AUC达到了0.7以上,相较Cox风险回归模型而言,整体预测效果大幅提升,但是也考虑到这里的变量选择并不是十分令人满意,接着又利用神经网络模型完成了患者生存时间长期预测。
对于神经网络模型而言,变量的选择方面比较简单,由于其模型本身对变量不做过多限制,本文主要采用了临床上比较重要的几个病理特征作为变量,例如肿瘤大小,区域淋巴结数目等等,打包一起代入模型中进行预测。比较直观的效果就是对应的ROC曲线下AUC的值在训练集甚至达到了0.8以上,其拟合效果是毋庸置疑的,精度方面也是3个模型最高的。但是同时也应注意到神经网络模型在变量解释方面较Cox模型完整度上差了不少。
4. 总结与展望
4.1. 基于预测模型的讨论
精准预测预后对肝内胆管癌(ICC)病人的治疗决策具有重要意义。尽管诸多学者通过探索全新的基因或分子标记物用于改善预后评估和治疗选择,但因检测方法费时费力、价格昂贵且缺乏统一检测手段,因此该技术离临床广泛运用尚存一定距离。事实上,基于现有的临床数据构建一个简单的评分系统来实现精准的预后预测,仍是临床肿瘤学个体化治疗的首选参考工具。例如,临床医生已经开始使用简易的模型来评估胆囊癌病人接受辅助放化疗的获益程度。
本篇文章基于最常见的临床病理参数以及SEER数据库内2538例ICC病人的数据,构建并验证了全新的预后预测模型,结果显示:传统的Cox风险回归模型并不能满足现阶段部分预测需求,既往研究所构建的ICC预后预测模型多基于Cox回归建模策略。Cox模型其假设协变量之间的相互作用是均匀的,不同协变量在风险函数中是独立的,但事实上ICC预后相关的因素之间存在复杂的交互关系。同时,Cox回归分析必须在病人临床信息完整的情况下进行,因部分变量缺失而将病人除外后续分析会产生巨大的选择偏倚,这些都导致了本文章中Cox模型拟合效果不好。
此时,机器学习算法便大有可为。随着机器学习算法在临床研究中的不断深入,模型的可解释性以及对缺失数据的处理能力成为了机器学习研究中关注的重点。基于决策树的方法是机器学习算法中的一个大家族,可依据预测因子之间复杂的非线性关系来区分预后亚组。分类与回归树算法因其简洁和直观的模型结构,已被用于区分不同ICC病人的手术预后,但该算法的预测效能有限。梯度提升算法(GBM)是一种包含大量决策树的集成学习算法,即将若干个独立的分类与回归树整合成一个强分类器来实现精确和稳定的预测。因此GBM模型的内在结构是可拆解的,也便于临床医师理解GBM算法是如何实现高效预测的。此外,GBM算法存在处理缺失值的内置功能,通过利用队列中的数据进行分类,而无须对缺失数据进行插补。这大大拓宽了可用于建模的数据集,减少了因删除存在缺失值的病人所导致的选择偏倚。本文的GBM模型拟合整体效果是很不错的,可以作为后续预测研究的一个较好选择。GBM模型能够准确预测ICC病人的预后。因此,本研究构建的GBM模型可为ICC病人临床决策提供重要参考。
BP神经网络模型也作为非常经典有用的一个机器学习算法,其具有逼近效果好,计算速度快,不需要建立数学模型,精度高以及理论依据坚实,推导过程严谨,所得公式对称优美,具有强非线性拟合能力等优点。本文中神经网络模型考虑了更多临床上的重要病理特征,也突出了其精度更高,模型拟合效果更好的优点,一样能为ICC病人临床决策提供重要参考。
4.2. 建议
1) 做好医疗宣传,对肝内胆管癌的隐秘性多加描述,针对肝内胆管癌疾病的特殊性即诊断时多为晚期。发病人群多为老年人,考虑到年龄较大,其预后是极差的,一定要定期体检,早日查出病情,尽早就医能有效延长患者的生存时间。
2) 截止目前,肝内胆管癌的成因依旧是医学界的一大疑问。所以关于ICC的预防应主要集中于对其密切相关的疾病及癌前病变的早期治疗。无创伤性检查B超应作为该系疾病普查的基本手段。
a) 一级预防:肝内胆管癌病因尚不清楚,与胆结石症的关系也不如胆囊癌密切。因此,胆管癌的一级预防缺乏有效的方法。主要是对肝胆管结石的防治以及定期的系统的健康检查。
b) 二级预防:二级预防是本病预防的重点。阻塞性黄疸患者,在排除胆石症、肝炎、肝硬化等疾病,应高度警惕胆管癌的可能。在详细询问病史、全面体格检查的基础上,应尽早做B超、CT、PTC及ERCP检查,以便早期发现、早期诊断、早期治疗。
综上所述,肝内胆管癌是恶性程度较高,治疗较困难,预后较差的一种类型。目前,仅肝切除术对可切除肝内胆管癌病人具有明确延长生存时间作用。肝内胆管癌的治疗方法也会随着技术手段的创新与突破逐渐体现出个体化与选择性。有些仍有争议的细节,还需要大量依据以进一步研究。无论哪种治疗方法均是为了提高患者的生活质量,延长生存期,在不同的情况下要采取不同方法来达到最佳治疗效果。
4.3. 研究展望
本文基于三种预测模型对ICC病人预后进行预测,在传统Cox风险回归模型进行预测的基础上考虑了加入机器学习算法建立更多模型对比。结果表明基于机器学习的梯度提升法和神经网络模型都能完成精度更高的预测。但由于诸多条件因素的限制以及时间的紧迫性,本项研究存在以下局限性:
1) 本研究为基于SEER数据库的回顾性分析,因此本研究建立的模型仍需在外部的大样本、多中心数据集以及前瞻性研究中进一步证实其临床应用价值。尽管如此,此次预测模型中的主要特征,如肿瘤大小、肿瘤数目和区域淋巴结转移数目,均为公认的影响ICC预后的因素,体现了本研究建立模型的可靠性。
2) 由于本研究纳入分析的病人和肿瘤特征有限,虽然本研究构建的模型所涵盖的一些协变量极易从临床资料中获得,证明了该模型的简洁性与可行性。但是在缺少其他复杂协变量的情况下,本研究建立的模型并不能够提供较准确的预后预测。
3) 本研究建立的多个模型能够明确一些患者的预后,但无法为具体辅助治疗方案的选择提供依据。
综上所述,本研究构建的模型仍然能为ICC病人临床决策提供重要参考。要想更好预测病人的预后,在往后的研究过程中,要充分利用真实病人的数据,改进现有模型算法。另外,机器学习等智能化的手段将逐步取代传统算法,期待其在大数据时代将发挥重要的临床价值。