1. 引言
天气与人们的日常生活息息相关,随着社会的进步、科技、经济的发展,其对生活中多个方面都产生了巨大的影响,特别是高温、低温、大风、暴雨、冰雹和暴雪等极端天气对农业、交通、航空、建筑等行业带来严重的经济损失,甚至对人们的生命也会产生威胁,这就对天气预报准确性有更高的要求。此外,天气预报的重要特点之一就是时效性,人们需要提前预知天气情况,并根据不同的天气做出合理的应对措施。因此,预测未来天气是气象领域的关键任务之一。
由于传输气象数据设备的不断完善、升级,其收集的数据越来越多 [1],这给预测天气技术带来了新的机遇和挑战。原始的预测方法不仅不能满足公众对天气要素预测准确率的需求,而且无法充分利用目前已收集到的气象数据。因此,面对这些挑战,许多研究者提出了新的预测方法、技术,如物理预测法 [2] [3]、基于统计学的方法 [4] [5] [6] [7] [8]、综合预测方法 [9]。其中,基于统计学的方法是采用数据统计分析方法,统计某一预测对象在某个时间内出现的频率,从而推算出未来时间段内,在相似环境条件下该对象出现的概率。
时间序列预测方法也是统计学方法中的一种。时间序列是根据时间排序的一组随机数据,时间序列预测是根据历史数据来对未来预测 [10] [11]。差分整合移动平均自回归模型(Autoregressive Integrated Moving Average model, ARIMA)是一个经典的时间序列预测模型 [12],该模型较为简单、灵活,在预测股票走势 [13] [14] [15] [16]、人口增长数量、区域经济GDP增量 [17]、交通流量和气象要素等各个方面具有重要的意义。例如、Kwong等人 [5] [6] 利用人工神经网络(ANN)方法对风速进行了预测评估。郭 [18] 等使用自回归模型来预测季节的降雨量。其次,灰色预测模型(GM) [19] 也是常用的预测模型之一,它可对即含有已知信息又含有不确定信息的系统进行预测。其优点就是所需历史数据少,预测越近期的数据越有效,解决了大量的生产、生活和科学研究等方面的预测问题 [20] [21]。此外,为了获得更加准确的预测结果,许多学者利用ARIMA和GM的组合模型来进行预测。Wang等 [22] 利用ARIMA-GM组合模型来预测美国页岩油产量。文献 [23]、 [24] 利用ARIMA-GM组合模型分别对湖北省电力需求、PM2.5浓度做了预测分析。ARIMA-GM组合相对于单一的ARIMA、GM预测模型的最大优势,把两个单一模型组合起来来降低单个模型的敏感度,从而提高预测准确率 [24]。
基于以上的分析和对日常气象服务内容的总结,本文主要利用ARIMA模型、GM模型及ARIMA-GM组合模型来预测夏季日最高温。我们收集了某市2019~2021年6~8月的每日最高温数据来生成时间序列数据集,并分别分析了ARIMA、GM及ARIMA-GM模型在该数据集上的预测效果。实验发现,GM、ARIMA-GM具有较好的预测结果,但ARIMA-GM的预测结果更加稳定。
2. ARIMA模型
2.1. ARIMA模型组成
ARIMA模型主要包含四部分:自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)和差分模型。其中ARMA模型是AR和MA模型的组合。
AR模型表示为:
(1)
其中,p是自回归阶数,表示当前值与前p个历史值相关,
为误差,
为自相关系数。
MA模型表示为:
(2)
其中,q为移动平均阶数。
因此,ARMA模型可表示为:
(3)
是常数项。
2.2. 差分模型
AR模型需要历史时间序列数据具有平稳性,而现实生活中获得的数据分布是复杂且多样的,但预测未来数据需要时间序列数据具有惯性,这就要求数据具有平稳性。平稳的时间序列数据集满足其均值、协方差和方差不随时间变化而发生明显变化。为了让一个非平稳的时间序列数据呈现出平稳性,本文利
用差分模型实现。给定时间序列数据
,差分后的时间序列
满足:
,且
,该方法称为差分法。
若做一次差分,数据集仍不具备平稳性,可做多次差分,直至数据平稳。做一次差分称为一阶差分,d次差分称作d阶差分。因此ARIMA模型可表示为ARIMA(p,d,q),p,d,q分别为AR模型、差分模型、MA模型中的参数。
2.3. ARIMA模型过程
本小节详细描述了ARIMA预测方法的过程,如算法1所示。
算法1:ARIMA方法
Input:Historical dataset Y0,forecast days ;
Output:predicted value for n days
1) ini(Y0)←preprocessing dataset Y0
2) d-difference method for Y0
3) p、q←calculateACF、PACF
4) Build ARIMA(p,d,q) model
5) Setp←ARIMA(p,d,q)
6) return Setp
首先,剔除时间序列数据集Y0中的空值、异常值,然后对Y0做差分操作,使其具有平稳性(如1)、2)所示)。然后,通过采用自相关函数(ACF)和偏自相关函数(PACF)来获得AR、MA模型中参数p、q值(如3)所示)。最后,构建ARIMA(p,d,q)模型,并输出预测值集合Setp (如4)~6)所示)。
3. GM模型
一阶灰色模型GM(1,1)是一阶的,且包含一个变量的灰色模型。建模步骤如下:
1) 将历史时间序列数据
做1次累加求和处理,获得
,其中
,
(4)
2) 对获得的
建立微分方程:
(5)
式中a、u为未确定参数。
3) 确定参数a、u,令:
,
利用最小二乘法估计a、u值:
(6)
根据公式(6)获得参数a、u值,a是控制模型发展态势,称为发展系数;u的数值大小反应数据变化的关系,称作灰色作用量。
4) 通过解微分方程(5),可得GM(1,1)预测模型为:
(7)
(8)
式(8)中,
,且令
。根据式(8)获得最终的预测值
。
接下来,给出了GM预测方法的伪代码,如算法2所示。
算法2:GM方法
Input:Historical dataset Y0,forecast days n;
Output:predicted value for n days
1) ini(Y0)←preprocessing dataset Y0
2) Y1←accumulate(Y0)
3) creatDiffEquation(Y1)
4) a、u←obtain by the ordinary least squares
5) SetpreGM←CalDiffEquation(Y0,Y1)
6) return SetpreGM
首先预处理数据集Y0,并对处理后的Y0中每个数据对象按照公式(4)做累加处理(1)、2)所示)。其次,创建微分方程并利用最小二乘法估计获得微分方程中的参数值a、u(3)、4)所示)。最后,把a、u值代入微分方程,据公式(7) (8)获得预测值(5)、6)所示)。
4. ARIMA-GM模型
ARIMA和GM组合模型是按照不同权重,对两者进行组合,表示为:
其中,
为预测值,
、
分别为ARIMA、GM模型权重,
、
分别为ARIMA、GM的预测值。
本文通过利用差分倒数法来确定权重
、
值,即
,
为第i个模型的误差平方
和,k为模型个数。
本文因为关注于预测夏季(6、7、8月)的日最高温度,且每个月份的日最高温数据差异比较大,因此本文在预测过程中,针对每个月份分别求出一组权重值,来确保预测的数据结果更加准确。下面给出ARIMA-GM模型的详细过程:
算法3:ARIMA-GM预测模型
Input:Historical dataset Y0,forecast days n;
Output:predicted value for n days
1) ini(Y0)←preprocessing dataset Y0
2) SetpreA←predictby ARIMA(p,d,q) model
3) SetpreGM←predictby GM(1,1) model
4) w1、w2←obtain by thereciprocal variance method
5)
6) return Setpre
首先,预处理数据集Y0,并分别利用ARIMA(p,d,q)、GM(1,1)进行预测(如1)~3)所示)。然后,利用差分倒数法获得ARIMA(p,d,q)、GM(1,1)的预测权重,根据所得权重分别对ARIMA、GM预测结果进行加权计算,获得最终的预测结果(4)~6)所示)。
5. 实验评估
本文主要采集了某市2019~2021年6、7、8月的日最高气温作为实验数据集。本文利用每个月份70%的数据作为训练数据,30%的数据作为验证数据来评估所用模型的有效性。
预测有效性评估
本小节主要利用平均绝对误差(Mean Absolute Error, MAE)来评估ARIMA模型、GM模型和ARIMA-GM模型的预测有效性。
平均绝对误差(Mean Absolute Error, MAE)表示为:
(9)
其中,
是真实值,
为预测值,n为预测天数。MAE值越小,表示预测值与真实值越相近,误差越小。相反,MAE值越大,表示预测值与真实值相差越大,误差越大。

Table 1. The mean of the mean absolute errors of the different forecasting models
表1. 不同预测模型的平均绝对误差均值
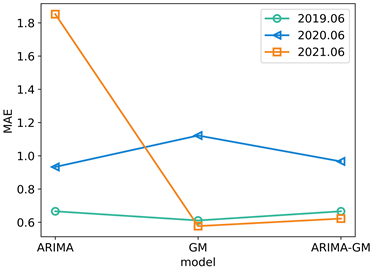
图1展示了ARIMA、GM、ARIMA-GM模型预测2019~2021年6、7、8月日最高温的绝对误差值。表1展示了ARIMA、GM、ARIMA-GM模型预测这三年(2019~2021年) 6、7、8月,每月的绝对误差值和的均值。通过图1和表1可知,ARIMA的绝对误差最大,预测效果最不佳,最低平均误差为0.869。而GM、ARIMA-GM误差值相近,但是从表1可知,ARIMA-GM预测2019~2021年6月的平均绝对误差和的均值小于GM预测2019~2021年6月的平均绝对误差和的均值。同样,ARIMA-GM预测2019~2021年7、8月的平均绝对误差和的均值也小于GM预测2019~2021年7、8月的平均绝对误差和的均值。因此,ARIMA-GM的预测效果比GM的预测效果更加稳定。
 (a) 2019~2021年06月
(a) 2019~2021年06月 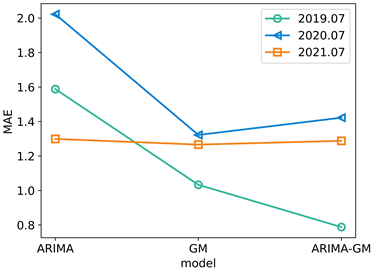 (b) 2019~2021年07月
(b) 2019~2021年07月 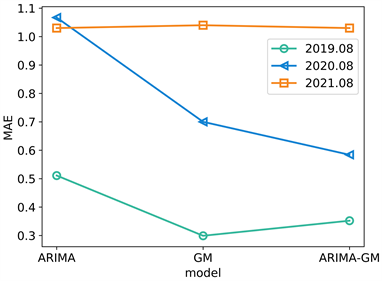 (c) 2019~2021年08月
(c) 2019~2021年08月
Figure 1. Mean absolute errors of ARIMA, GM, ARIMA-GM models
图1. ARIMA、GM、ARIMA-GM模型平均绝对误差值
6. 总结
本文利用ARIMA、GM、ARIMA-GM模型对某市2019~2021年6~8月日最高温进行了预测、分析。实验表明,ARIMA模型预测的平均绝对误差比GM、ARIMA-GM模型的大,而GM和ARIMA-GM模型的误差值比较接近,且相对较小,但ARIMA-GM组合模型具有更加稳定的预测效果。因此,在实际生活中,可以采用GM或ARIMA-GM组合模型来对夏季每日的最高温提前预测,从而减少甚至避免因为高温对公众、各部门造成的损失。
基金项目
淄博市气象局气象科研项目(2022zbqx07)。