1. 引言
在股票市场中,尽早地了解股票涨跌模式有助于股民进行明智地风险投资。对于投资者而言,股票满足了不同的投资意愿和投资需求,扩大了投资选择的范围,拓宽了投资渠道,在一定程度上满足了投资者获得相应收益的可能性,也在一定程度上增强了资金的灵活性和流动性 [1]。股票市场的客观风险在给投资者带来收益的同时,也可能造成经济损失,也可能对参股公司的经营状况产生负面影响,甚至给国民经济建设带来副作用。这些问题在所难免,因此股票走势预测成为各方高度关注的问题 [2]。股票走势预测的研究也成为了金融大数据的一个应用研究方向,许多学者采用深度神经网络的方法来预测股票走势,成为当前学术领域的热门研究问题之一。近年来,随着计算机技术的飞速发展,深度神经网络应用在金融信息领域 [3] [4] [5] [6] 成为当今重点研究对象。股票价格在金融领域是一个高度波动的时间序列数据,股票价格受利率、汇率、通货膨胀、货币政策、投资者情绪等多种因素的影响。对股票价格与这些因素之间的关系进行建模并预测股票价格趋势对于研究人员来说是一项具有挑战性的任务。
目前,越来越多的研究人员开始转向使用机器学习技术来分析股票数据并创建性能良好的方法模型来预测未来的股票走势 [7] [8] [9]。股市预测模型是通过从历史价格数据中学习来预测未来价格而建立的 [10]。但是,由于从股价中挖掘出的基础市场信息太少,大部分方法通常假设时间序列是从线性过程中生成的,无法从固定长度时间序列特征中提取有用信息,因此在非线性股票价格预测中表现不佳。虽然深度学习具有很好的非线性映射能力,但是股票交易数据间具有较强的时间关联和数据波动的短期连续性。为了打破时间序列差距,CHEN等人 [11] 提出了一种基于单个时间点和多个时间点的双重数据特征提取方法,将短期市场特征与长期时间特征相结合,以提高预测的准确性。但由于依赖于时间周期匹配阈值,导致模型方法在不同阈值下具有较差的预测稳定性。本文结合历史股票交易数据的五个基本交易指标,设计并实现了一个股票走势预测系统,为投资者推荐股票和股票走势预测服务,以降低或规避投资风险,从而为投资者带来相对稳定的经济回报。以transformer模型为网络主体架构,同时输入不同周期长度的时间序列特征,经过多个分支的编码器处理,最后通过CNN将输出特征进行融合,得到具有多个尺度的特征信息。
2. 相关工作
股票预测通过分析历史数据对未来股市参数进行预测与分析。涵盖了包括工商业、经济学、环境科学和金融等行业。根据数据的时间序列,预测问题可归类为短期预测(预测几秒,几分钟,几天,几周或几个月)、中期预测(预测1至2年)和长期预测(预测超过2年) [12]。即定义所选数据变量的时间顺序及周期做为观察序列,使算法模型具有对未来股票价格的预测能力,不同周期数据的预测问题具有不同序列长度的预测能力。
机器学习算法的主要问题是它们的性能在很大程度上取决于给定数据的表示 [13]。股票市场生成的时间序列数据最好被描述为随机游走,这使得股票数据的特征工程变得更加困难。因此,使用机器学习算法预测股票价格要困难得多。由于深度学习模型不需要单独执行特征工程,因此这些模型被广泛用于从大量过去数据中预测股价或股价趋势的方法 [14]。Huang等人 [15] 提出了一种名为双向门控循环单元(BGRU)的深度神经网络架构,用于预测标准普尔500指数上市的股票,并将BGRU与LSTM和GRU网络的性能进行了比较。为了评估金融新闻随着时间的推移对股票价格的影响,研究人员在许多时间间隔(即1天、2天、5天、7天和10天)上检查了预测方法。实验表明,在前24小时内获得了最高的准确度,使用BGRU实现的准确度高于LSTM和GRU实现的准确度。Dang Lien Minh等人 [16] 提出了双流门控循环单元(TGRU)和训练于股票新闻和情绪字典的嵌入模型Stock2Vec预测日内交易的短期股票走势,应用三个技术指标作为股票价格趋势预测的附加功能集,分析新闻是否立即影响或是短期(2天、1周)影响股价。类似地,Lu等人 [17] 选取具有不同特征的神经网络模型,从短期股价波动数据中提取有效的特征组合并且利用注意力机制进一步探索了预测K线模式。Chen等人 [11] 提出了一种基于编码器-解码器框架的股票价格趋势预测模型(TPM),采用分段线性回归方法和卷积神经网络提取金融时间序列在不同时间跨度的长期时间特征和短期市场特征。在编码器和解码器中都引入了注意力机制,以便自适应地选择和合并所有时间点特征的最相关维度,能够自适应地预测股价走势及其持续时间。Yang等人 [18] 提出了一种基于金融时间序列历史信息预测价格走势方向的深度学习框架。结合了用于特征提取的卷积神经网络(CNN)和用于预测的长短期记忆(LSTM)网络,为CNN构建了一个改进的三维输入张量(时间序列信息、技术指标信息以及股票指数)。使用多变量时间序列进行预测的目的是在给定先前和当前的几个单变量时间序列数据的情况下预测未来值,由于在快速波动的金融时间序列数据中很难测量噪声与信息信号混合的程度,因此设计一个好的预测模型并不是一项简单的任务。Park等人 [19] 提出了一种基于深度神经网络和趋势过滤的新预测框架,将嘈杂的时间序列数据转换为分段线性方式。
3. 多尺度的Transformer网络架构
Transformer是由Vaswani等人 [20] 提出来用于神经网络机器翻译任务的序列到序列的模型,目的是提取感兴趣区域在数据全局的重要程度。由于金融市场的不确定性,在不同时间周期下预测股票等金融证券的价格变化是一个重要且具有挑战性的任务。
3.1. Transformer模型结构
Transformer网络结构细节解析(图1):
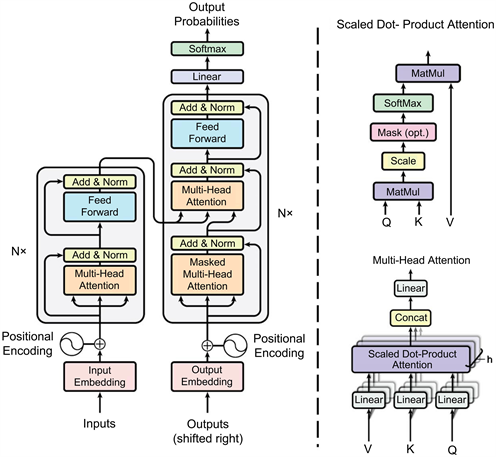
Figure 1. Transformer network standard architecture [20]
图1. Transformer网络标准结构 [20]
1) 自注意力机制
注意力机制的公式定义如式1所示:
(1)
其中
,这就是传统的缩放点乘注意力(Scaled Dot-Product Attention),把这个注意力理解为一个神经网络层,将
的序列Q编码成了一个新的
的序列。因为对于较大的
,内积会数量级地放大,太大的话softmax可能会被推到梯度消失区,softmax后就非0即1 (那就是hardmax),所以 按照比例因子
缩放。而自注意力机制即
,通过在序列自身做Attention,寻找序列自身内部的联系。
按照比例因子
缩放。而自注意力机制即
,通过在序列自身做Attention,寻找序列自身内部的联系。
2) 残差和正则化(Add&Norm)
残差(Add)和正则化(Norm)的计算公式如下:
(2)
其中Add指X + MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分。Norm指网络层正则化(Layer Normalization),通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
3) 位置编码(Position Embedding)
在解码时序信息时,LSTM模型通过时间步的概念以输入到输出流一次一个的形式编码的。而Transformer选择把时序编码为正弦波。这些信号作为额外的信息加入到输入和输出中以表达时序信息.这种编码使模型能够感知到当前正在处理的是输入(或输出)序列的哪个部分。位置编码可以学习或者使用固定参数。作者进行了测试(PPL, BLEU),显示两种方式表现相似。文中作者选择使用固定的位置编码参数:
(3)
(4)
其中pos是位置,i是维度。
3.2. 多尺度的Transformer模型结构
多尺度的transformer由三个transformerencoder-decoder分支组成,如图2所示,将输入的时间序列股票数据通过Word2Vec映射为模型输入特征,并将输入特征分别从20、40和60时间序列周期长度的三种尺度提取数据特征。然后对特征序列进行卷积运算,并对横纵坐标的位置编码进行加权处理,增强了模型保持特征序列顺序的能力;编码器将输入的时间序列股票数据
映射为模型输入特征
,然后,将顶部编码器的输出转换为一组注意向量K (Key向量)和V (Value向量)。每个解码器在编码–解码注意力层中使用这些注意向量,有助于解码器将注意力集中在输入序列中的适当位置。
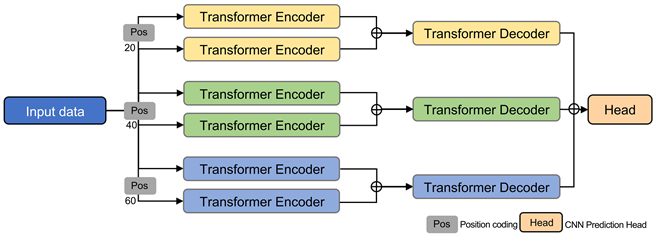
Figure 2. Multi-scale transformer model architecture
图2. 多尺度的transformer网络结构
在编码过程中,将t − 1时刻的状态
和t时刻的数据
输入到t时刻的编码单元中,从而得到t时刻的状态
,经过T个时间片以后,可以得到长度等于隐节点数量的特征向量c。在解码过程中,将特征向量c和上一时间片预测的输出
输入到解码单元中,得到该时刻的输出
,如此经过T'个时间段后,得到最终的输出结果。将每个尺度分支的模型输出进行逐一元素相加,然后分别通过1 × 3和1 × 5的卷积层对融合数据进行处理,并通过RELU激活函数消除负值的影响。最后通过MLP层将特征从嵌入维度转化为输出标签的特征维度,如公式5所示:
(5)
其中Proj表示由CNN和MLP组成的神经元传播方式,特征维度emb使网络模型定义的超参,本文使用512的特征嵌入维度。
4. 实验分析
4.1. 实验数据
本文获取的原始数据来自baostock证券数据平台。选取了四只不同行业的股票数据,分别是乐普医疗(300003),亿纬锂能(300014),浦发银行(600000)和东风汽车(600006)。选取2016年1月8日到2022年5月6日共1542个交易日的数据,前1342个数据作为训练值,后200个数据作为测试值来预测开盘价。考虑对股票价格影响比较重要的一些指标,选取了5个基本交易指标,分别是开盘价、最高价、最低价、收盘价、成交量,选取的不同行业股票数据开盘价如图3~图6所示。

Figure 3. Lepu Medical stock data opening price
图3. 乐普医疗股票数据开盘价
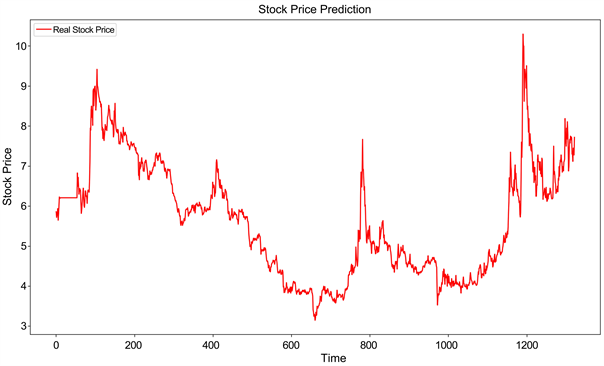
Figure 4. Dongfeng Motor stock data opening price
图4. 东风汽车股票数据开盘价
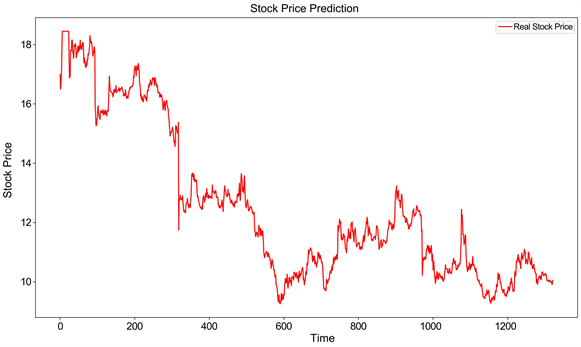
Figure 5. Shanghai Pudong Development Bank stock data opening price
图5. 浦发银行股票数据开盘价

Figure 6. Yiwei Lithium Energy stock data opening price
图6. 亿纬锂能股票数据开盘价
4.2. 结果分析
在实际问题中,单一数据集的样本特征具有不同的特性,在建立数学模型之前对数据进行规范化处理是十分必要的,使模型训练时避免极值对迭代的性能影响。本文首先将数据进行拟合,对数据进行某种统一处理(将数据映射到某个固定区间),消除极大值和极小值的影响,从而实现数据的标准化和归一化。同时数据的缩放能够避免在模型训练后的过拟合和欠拟合,同时在检验数据建模效果的时候能够更加直观。
在数据处理好之后,输入到transformer网络当中,采用前一日的特征指标来预测下一日的股票开盘价格。经设置不同的参数进行实验,发现选用Adam作为优化算法,学习率设置为0.005,迭代次数为200次,预测精度最高。同时选用均方根误差(RMSE)、平均绝对误差(MAE)决定系数(R2-score)来检验实验精度,R2反映因变量的全部变异能通过回归关系被自变量解释的比例。计算公式如下:
(6)
(7)
(8)
多尺度的transformer股票预测网络模型对乐普医疗、东风汽车、浦发银行和亿纬锂能的预测推广R2分数分别是0.9872、0.9970、0.9897和0.9944,与结合LSTM和Attention模块的AM-LSTM网络 [14] 相比,分别提高了0.0539、0.0632、0.0607和0.0622,同时对不同的时间结点的测试更具有性能稳定性。四个不同行业股票数据开盘价检测效果如图7~10所示。
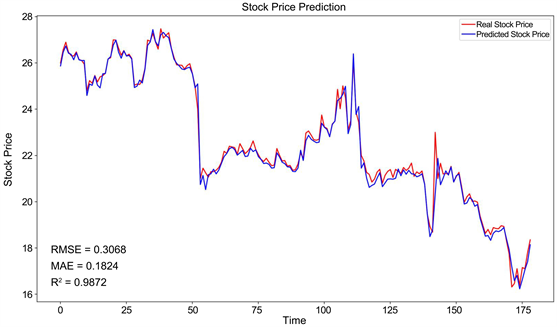
Figure 7. Lepu Medical stock data opening price prediction
图7. 乐普医疗股票数据开盘价预测
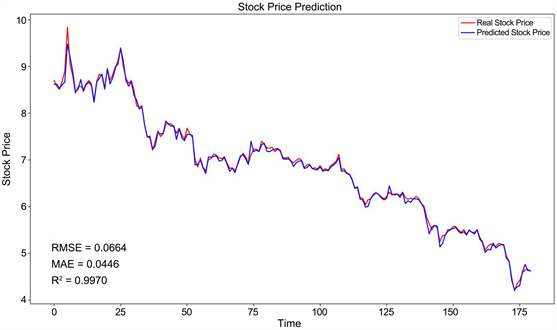
Figure 8. Dongfeng Motor’s stock data opening price prediction
图8. 东风汽车的股票数据开盘价预测

Figure 9. Shanghai Pudong Development Bank’s stock data opening price prediction
图9. 浦发银行的股票数据开盘价预测
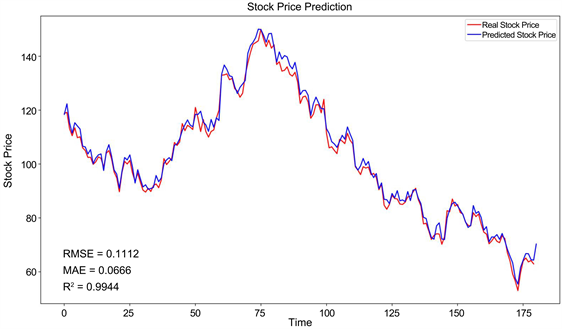
Figure 10. Yiwei Lithium Energy’s stock data opening price prediction
图10. 亿纬锂能的股票数据开盘价预测
5. 结论
传统方法无法提取相关特征来挖掘金融时间序列。为了解决这个问题,本研究提出了一种基于多尺度transformer的金融股票价格预测模型。首先,在数据预处理阶段,通过标准化和正则化将时间序列特征和转化为非离散数据,更有利于提取数据周期的时间序列特征;其次,我们从数据中提取不同周期长度的特征信息,并结合transformer模型,提取出多尺度的时间序列特征信息;最后将我们的多尺度transformer模型训练测试于四支股票中,实验证明该模型对单支股票具有很好的预测效果和稳定性。
基金项目
项目基金由“广东省教育厅项目,项目编号:GDJX2020009”和“广东省研究生教育创新项目,项目编号:2022SQXX040”资助。
NOTES
*通讯作者。