1. 引言
目前无人机目标检测已广泛应用于战场情报侦察、重要目标鉴别、矿产资源勘探、灾情环境监测等军用、民用各个领域 [1] - [6],与通用目标检测相比,无人机目标检测因无人机俯拍视角的特殊性,目标在图像中呈现出小尺度/多尺度、外观相似度高、背景复杂干扰大等特点,很难对目标进行高精度的定位检测。图1展示了VisDroneDet数据中影响精度的主要因素:1) 目标呈现小尺度/多尺度:航拍大视场场景中目标多以小的尺寸呈现,且目标尺度会随航拍高度呈现一定的多尺度变化。2) 目标外观相似高:航拍高度越高,目标的尺度越小、像素越少,其不同类别目标间的差异难以体现,如小汽车、面包车、货运车等差异性会被弱化,区分不同的目标类别更难。3) 背景复杂干扰大:不同于道路监控、海面监测等单一背景的目标检测任务,无人机航拍场景存在着城市街区、深山老林、道路交错等各类复杂场景,这些场景中的光线、阴影、遮挡等现象会影响着目标外观、大小,并带来一定的噪声。上述因素容易导致目标检测器出现误检、漏检,降低目标检测模型性能。
近年来,基于卷积神经网络的目标检测模型 [7] - [12] 在通用目标检测数据集 [13] [14] [15] 上取得了长足的进步,不断刷新检测记录。其中YOLO (You Only Look Once)一阶段目标检测方法经历了YOLOv1 [16]、YOLOv2 [17]、YOLOv3 [7]、TinyYOLO、YOLOv4 [8]、YOLOv5、YOLObile [18]、YOLOF [19] 的改进发展,因其时效性优越被广泛应用于实际工程项目中。2021年旷视科技发表了该系列最新改进算法YOLOX [20],并取得了非常不错的检测效果。但是,针对无人机航拍目标检测任务,在通用目标检测数据集训练出来性能出众的检测模型会存在着跨域适配问题,需要研究新的适配航拍场景目标检测的特定检测器部件或模块来提升性能。

Figure 1. The main factors affecting the accuracy of images in the VisDroneDet dataset
图1. VisDroneDet数据集图像影响精度的主要因素
作为YOLO系列最新的、效果最佳的目标检测模型YOLOX,其通过对主干网络的多个阶段输出特征进行融合实现了鲁棒的特征提取。其中,融合特征提取模块是基于特征金字塔网络(Feature Pyramid Network, FPN)改进的路径聚合网络(Path Aggregation Network, PANet) (如图2(a)所示),包含向上和向下两个方向的相邻阶段不同输出特征的融合操作。现有研究已经表明 [21] [22] [23] [24],主干网络不同阶段提取的特征是不同的,底层阶段输出的特征包含更多的纹理形状等信息,而高层阶段输出的特征包含更多的语义类别信息。YOLOX的路径聚合网络实现了对相邻阶段特征的融合,但是缺乏像HRNet [25]、DenseNet [26] 网络类似的对非相邻阶段特征的跨层融合,会存在一定程度上的特征融合提取不充分问题。
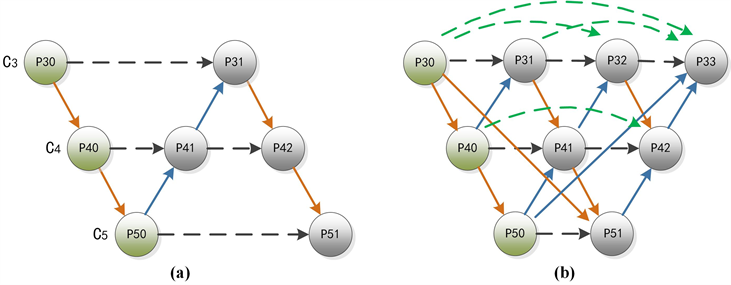
Figure 2. (a) Structure of PANet, (b) Structure of MDAD
图2. (a) 路径聚合网络结构,(b) 多距离关联依赖结构
为了提升YOLOX中PANet模块对特征的融合提取能力,我们提出一种改进PANet的多距离关联依赖(Multi-Distance Association Dependency, MDAD)模块,该模块结构如图2(b)所示。具体地,该模块包含跨层连接(Connection across Different Layers, CDL)和同层连接(Connection on the Same Layer, CSL)两种连接方式,其中CDL跨层连接对不同阶段特征层进行充分外部特征融合;CSL同层连接对同阶段特征层进行二次内部特征融合,增强特征表达和定位精度。与YOLOX中的PANet模块相比,改进模块可以更好地提取无人机航拍捕获的目标特征,提升模型的检测性能。
本文贡献及创新点如下:
1) 针对通用目标检测中常用于融合多尺度特征的路径聚合网络(Path Aggregation Network, PANet)模块,提出了一种改进PANet的多距离关联依赖MDAD (Multi-Distance Association Dependency)模块。
2) 基于YOLOX框架和所提出的MDAD模块,构建了更加适合航拍多尺度复杂目标的目标检测方法。在公开的典型航拍目标检测数据集VisDroneDet上,实验验证了本文所提模块和方法的有效性。
2. 相关工作
2.1. 一阶段目标检测
2016年,以速度快、实用强著称的YOLOv1 [16] 模型诞生,自此一阶段目标检测器得到了迅速发展和广泛应用。同年,Liu Wei等人提出单发多框检测器(Single Shot Multibox Detector, SSD) [9],该模型使用VGG-16作为主干网,新增加了4层不同尺寸的特征图,并利用不同尺寸的特征图进行不同尺度目标的检测,对多尺度目标尤其是小目标可以获得了更好的检测精度,但是由于不同层特征图之间没有进行融合,特征图包含的目标信息有限。2017年,Tsung-Yi Lin等人提出FPN [27],该模型使用性能更好的ResNet-50作为主干网,并将语义信息丰富的深层特征图进行2倍上采样后,与位置细节信息丰富的浅层特征图进行横向连接融合,从而得到不同尺度的特征金字塔,有效地增强了特征图的特征表示能力。同年,Redmon等人提出YOLOv3 [7],该模型借鉴了残差网络ResNet的设计思想,设计了更加高效强大的主干网Darknet-53,并借鉴了FPN的设计思想,对不同层次特征图进行了更加充分地融合,进一步提高了小目标的检测精度。
以上方法虽然在特征提取上通过融合多层特征实现了更强的特征表示,但是特征融合后的分类与定位任务中,分类和定位的检测头都是耦合在一起的,因为分类与定位任务不同,导致耦合任务存在冲突,会降低检测精度。2021年,YOLOX [20] 以YOLOv3 SPP版本为基础进行改进,将分类与定位的检测头解耦,分别计算定位损失、分类和置信度损失,并采用数据增强、无锚框设计和先进的标签分配方法SimOTA (Simple Optimal Transport Assignment)等策略,在MS COCO数据集上达到了目前最优的性能。但是,YOLOX中PANet模块仅对相邻阶段特征进行融合,缺乏像HRNet [25]、DenseNet [26] 网络类似的对非相邻阶段特征的跨层融合,会存在一定程度上的特征融合提取不充分问题。
2.2. 特征金字塔网络
目标检测是一项对目标尺度变化和空间位置信息都较敏感的计算机视觉任务,因此特征金字塔网络FPN [27] 及其改进方法PANet [20] 已广泛用于该领域以此提高多尺度目标检测性能。这些方法对不同阶段获取的特征图通过改变分辨率大小统一到相同尺度进行通道特征的拼接或合并,使得浅层细节、位置信息在深层表示的更丰富,深层语义信息在浅层表示的更完整,实现上下文彼此关联。然而,它们的特征融合仅仅体现在相邻特征层之间,忽视与其它特征层信息的交互依赖,降低语义差异效果受限。同时,在相同特征层之间也缺少如DenseNet这样的密集跳连融合,这也会带来特征位置偏差。
为了更好地处理多尺度特征,Tan Mingxing等人在EfficientDet中提出的加权双向特征金字塔网络BiFPN (Bidirectional Feature Pyramid Network) [28],通过引入类似Attention权重,更好地平衡不同尺度的特征信息。Guo Caoxu等人针对FPN融合前高层特征传递信息会随通道减少而丢失、不同特征层融合时会产生语义差异及融合后直接忽视某一特征层信息会带来融合特征不完整的问题,提出了AugFPN (Augmented FPN)特征金字塔结构 [29],利用设计的一致性监控、剩余特征增强和软RoI (Region of Intersect)选择三个模块解决上述特征融合缺陷。Tsung-Yi Lin 等人采用递归FPN的方式提出了Recursive-FPN (Recursive Feature Pyramid Network) [30],将传统FPN融合后的特征输出作为输入返回给Backbone,进行二次循环特征融合。然而,这些改进的特征金字塔网络因为缺乏不同特征层之间的远距离关联,彼此还存在着语义差异。GiraffeDet [31] 采用了轻Backbone、重Neck的设计,虽然最大化地实现了特征的充分融合,但是同时也增加了过多计算成本。ASFF (Adaptively Spatial Feature Fusion) [32] 的融合方法实现了每个特征层的输出节点特征都来自所有特征层输入节点的特征融合,不仅关联了相邻特征层间的语义信息,而且建立了不同特征层之间的远距离依赖,减少了语义差异,但因忽略橫向跳连,使得特征融合不够充分。
3. 本文方法
3.1. 模型架构

Figure 3. The architecture of the proposed model
图3. 所提模型架构
图3展示了本文所提模型的整体架构,由用于特征提取的Backbone模块、用于特征融合的MDAD Neck模块、用于预测输出的Head模块三个部分构成。
Backbone模块:采用和YOLOX一样的结构。对于一幅统一尺度的输入图像,主干网采用Focus、CBS、CPS1和SPP等卷积、下采样操作,在阶段C3、C4、C5输出特征,为后续特征融合并最终预测目标位置和类别提供多尺度特征信息。随着主干网深度的增加,输出特征图分辨率(尺寸)不断下降,低维细节空间特征会不断减少,高维抽象语义信息不断增加。借鉴YOLOX,本文也采用阶段C3、C4、C5输出三个不同尺度特征图
作为后续特征融合及预测的主要特征。
MDAD Neck模块:为了克服YOLOX中PANet Neck模块存在的层间和层内特征相互嵌入、彼此关联不足的问题,本文借鉴HRNet [25] 和DenseNet [26] 等稠密连接结构,提出了一种新的MDAD Neck模块,该模块通过同层跳连和跨层互联的连接方法,实现了层间和层内特征的充分融合。具体包括:一个双线性插值或转置卷积的上采样操作、CBS卷积或空洞卷积的下采样操作、将不同阶段或同一阶段不同层特征进行Concat拼接操作,以及用于定位目标的注意力机制操作。这些操作实现了对不同阶段、不同尺寸特征的融合,并对目标区域特征进行注意力增强,具体结构见3.2节。
Head模块:与YOLOX类似,本文在Head模块中将预测目标的类别、位置和置信度进行解耦计算,不仅能提高模型检测精度,而且能加快模型训练的收敛速度。该Head模块对MDAD输出的三个不同尺度的特征分别进行解耦操作,每个解耦操作都是先通过1 × 1大小的通道卷积来压缩通道数、降低计算量,再分解成判断类别、判断前背景和定位目标三个分支操作。其中,判断类别、判断前背景属于分类任务,通过两个3 × 3和一个1 × 1卷积映射到目标类别数和有无目标2类别数,再利用Sigmoid操作转化为预测概率;定位目标属于回归操作,也是通过两个3 × 3和一个1 × 1卷积映射至所需回归的4个坐标值(中心点横坐标、纵坐标、宽、高)。训练过程中,Head模块之后采用与YOLOX一样的损失函数。
3.2. MDAD模块结构
图3中展示的MDAD模块结构,由跨层连接(Connection across Different Layers, CDL) (不同尺度大小特征层层间互连)和同层连接(Connection on the Same Layer, CSL) (相同尺度大小特征层层内互连)两种信息传递路径,与三种尺度6个融合特征输出节点构成。该模块输入为Backbone模块第3、4、5阶段输出的多尺度特征(C3、C4、C5),输出为MDAD模块处理后的多尺度特征,特征个数和维度与输入相同。该模块能融合特征表示多尺度特征,具有更充分的特征提取能力。其中:
3.2.1. 跨层连接CDL
跨层连接是纵向连接相邻和非相邻阶段不同尺度的特征,通过汇集多尺度特征实现对低层细节特征与高层语义特征的融合。具体又可分为短距离相邻尺度特征融合和长距离非相邻尺度特征融合。
短距离相邻尺度特征连接:采用双线性插值上采样操作和步长为2的普通卷积下采样操作来统一相邻阶段的特征尺度。双线性插值将深层特征图的宽、高放大为原来的2倍,通道数缩小0.5倍;步长为2的普通卷积操作将浅层特征图的宽、高缩小为原来的0.5倍,通道数增大2倍。以上上采样和下采样操作为不同尺度特征的交互连接提供了统一的尺度,形式化表示如下:
(1)
(2)
其中,
表示第i阶段第j个层的输出特征,
表示卷积操作,
表示大小为1 × 1、步长为1的卷积操作参数,
表示双线性插值上采样,卷积用于改变特征通道数、上采样用于改变特征高度和宽度,目的是将第i阶段的特征
与第i − 1阶段特征
尺度统一;
表示大小为3 × 3、步长为2的卷积操作参数,用于改变特征高度和宽度,目的是将第i阶段的特征
与第i + 1阶段特征
尺度统一。
长距离非相邻尺度特征连接:采用转置卷积上采样操作和空洞卷积下采样操作来统一不同阶段的特征尺度。转置卷积将深层特征图的宽、高放大为原来的4倍,通道数减少原来的0.25倍,其相对于双线性插值信息冗余更小、映射能力更强。空洞卷积(膨胀率依次为r = 1、r = 2、r = 3)操作将浅层特征图的宽、高缩小为原来的0.25倍,通道数增大4倍,其相对于普通卷积能够获得更大的感受野。形式化表示如下:
(3)
(4)
其中,
表示第i阶段第j个层的输出特征,
表示卷积操作,
表示大小为1 × 1、步长为1的卷积操作参数,
表示转置卷积上采样,卷积用于改变特征通道数、上采样用于改变特征高度和宽度,目的是将第i阶段的特征
与第i − 2阶段特征
尺度统一;
表示大小为3 × 3空洞卷积操作参数,用于改变特征高度和宽度,目的是将第i阶段的特征
与第i + 2阶段特征
尺度统一。
3.2.2. 同层连接CSL
同层连接横向串连或跳连同尺度特征,汇聚同一尺度不同处理过程的特征进行融合。具体有可分为短距离串连和长距离跳连。对于同层连接的每个节点,除了接收不同阶段传递来的特征,还接收同阶段相邻节点特征和非相邻节点特征,所有特征以拼接方式组合后,采用卷积块注意力模块(Convolutional Block Attention Module, CBAM) [33] 实现对不同的多组特征进行充分融合,以及对目标主要区域进行注意力加权,增强对目标区域特征的表示能力,提升目标定位性能。
3.2.3. 特征汇聚融合
MDAD模块特征汇聚融合过程具体如下:
假设
表示第i (i = 3、4、5)阶段第j个操作节点输出特征(当j = 0时,
表示由主干网络输出的特征;当j > 0时,
表示MDAD模块融合后输出特征),则该特征计算过程为
(5)
其中,
表示空间域注意力机制 [33],
表示该项仅在
时存在,
表示卷积操作,
表示按通道拼接操作,
表示大小为1 × 1、步长为1的卷积操作参数,用于改变特征通道数,
计算过程如下:
(6)
(7)
(8)
其中,
表示CBAM注意力机制。当j > 0时,特征
由不同阶段、不同层特征融合后经CBAM注意力机制生成得到。
4. 实验
4.1. 数据集及参数设置
数据集:实验采用VisDroneDet2019数据集进行训练和测试。该数据集由无人机高空对街区、交通等场景拍摄回去的图像组成,包括12个类别标签(行人、人、自行车、小汽车、敞篷车、货车、三轮车、人力三轮车、公共汽车、摩托车,外加一个其他类和忽略区域),8629张图像,其中6471张用于训练,548张用于验证,1610张用于测试。单张图像宽度在2000像素左右,目标总数达到2,600,000个。该数据集图像成像于昼夜全时段,绝大多数图像以复杂场景为背景且密集遮挡情况严重,单张图像目标类别和个数较多,如图1。
参数设置:训练时,训练总迭代次数为100个epoch,并前2个epoch采用热启动Warmup,在85个epoch后终止Moasic增强。使用随机梯度下降(Stochastic Gradient Descent, SGD)优化器和余弦退火衰减学习机制调整学习率,初始学习率为0.01,SGD的动量设置为0.9,权重衰减为0.0005。使用2块英伟达2080Ti GPU计算,Batchsize大小设为16。测试时,Batchsize大小设为64。同时,使用了Mosaic [8]、Mixup [20] 数据增强方法,其中Mosaic方法通过4张图像的随机拼接再缩放至相同输入尺寸大小,不仅增加了小目标的数量,也加大了背景的复杂程度。类似的,Mixup方法通过叠加不同图像方式模拟了遮挡目标的效果。为了验证本文所提方法的有效性,将YOLOX模型作为基线模型,其中与本文方法的差异主要是Neck部分采用了不同的模块。
4.2. 实验结果与分析
定量实验结果分析
本文所提结构被称为MDAD结构(如图2(b)),它是在基准模型的PANet结构 [34] (如图2(a))基础上提出的。为了有效论证本文所提方法的有效性,我们同时还构建了另外两种不同的Neck结构(如图4(a)、图4(b))。其中,图4(a)展示了在C3、C5层中间添加两个特征输出节点,采用更加全面复杂的连接方式使每个特征输出节点与其它节点建立相互依赖关系,这种密集连接的结构被称为FCP (Fully Connected parallel)结构;图4(b)展示了将C5层的P52节点移到C3层中,形成倒梯形结构来加强浅层特征的表达能力,这种结构我们称为IT (Inverted Trapezoid)结构。
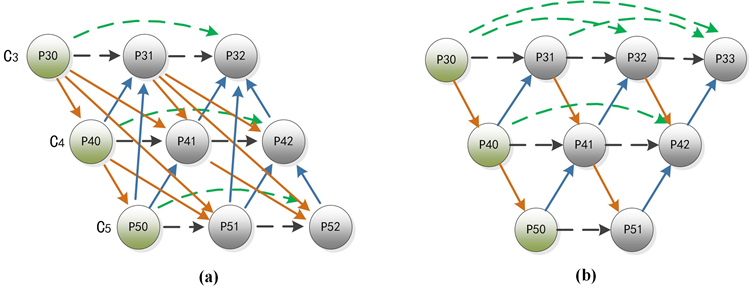
Figure 4. Schematic diagram of comparative analysis of different feature fusion Neck structures
图4. 不同特征融合Neck结构对比分析示意图
实验结果如表1所示。其中,评测指标AP、AR均采用数据集标准评测指标 [2]。

Table 1. Experimental results of the improved method on the VisDroneDet2019 dataset
表1. 改进方法在VisDroneDet2019数据集上实验结果
由表1可以发现,
1) 所提方法YOLOX (MDAD)的AP、AP50、AP75精度分别为22.54%、40/67%和22.41%,较YOLOX (PANet)的22.24%、40.29%和22.02%的精度有一定的提升。除了AR10指标外,YOLOX (MDAD)的AR指标均超过了YOLOX (PANet),验证了本文所提方法的有效性。
2) 对比YOLOX (FCP)和YOLOX (IT),YOLOX (IT)具有明显的性能优势,因为IT相对于FCP将C5层的最后一个特征输出节点移到了C3层,目的是增加浅层特征的表达能力,同时也去掉了冗余相邻层间的下采样融合;将所提方法与YOLOX (IT)对比,可以发现所提方法在AR10和AR100上稍低于YOLO (IT),但是在精度上有者较大的优势;
3) 对比YOLOX (PANet)和YOLOX (FCP),可以发现YOLOX (PANet)要更好,说明并不是任意增加连接就可以提升检测性能,需要进行一定的选择设计;同时,对比YOLOX (IT)和YOLOX (PANet),可以发现YOLOX (IT)相对更好,说明倒梯形结构相比于原网络结构性能更好。
4) 对比不同的Neck结构还可以发现,航拍图像目标检测的效果不是取决于特征输出节点数量的多少(PANet的节点数量为4个,FCP、IT、MDAD的节点数量相同均为6个),而是与结构中特征输出节点的位置有关,倒梯形结构要比平行连接结构好。
4.3. 定性可视化效果分析
为了更好地展示本文方法的有效性及不足,本文对图1展示的6幅测试图像进行预测,结果如图5所示,其中左上角的图像中存在大量密集的目标,且绝大部分都被有效检测到,但是,也可以发现中下方红色圆框位置存在多个骑车人的目标未被检测到。其他5幅图像总体上检测目标都较准,也存在个别目标漏检的问题。
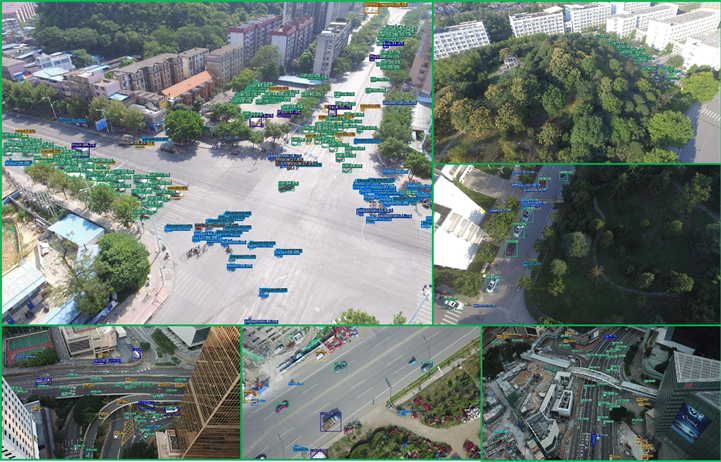
Figure 5. Detection results of the proposed method
图5. 所提方法检测结果
5. 结论
针对航拍目标检测中存在小尺度/多尺度、外观相似度高、背景复杂干扰大等挑战和问题,本文基于路径聚合网络结构模块,提出一种新的多距离关联依赖MDAD结构模块。同时,基于所提出的MDAD结构模块,改进YOLOX更加适合航拍目标检测。在公开的典型航拍目标检测数据集VisDroneDet上,实验验证了本文所提方法的有效性。
NOTES
*通讯作者。