1. 引言
外语学习者应该在他们的目标语言的交流中尽可能地实现自然和有效地表达 [1]。“自然和有效”除了意味着在文字层面上的自然和有效,还必然包括在语音层面,其中语调对情感和意图的表达是尤为重要的,有时甚至起到决定性作用。但德语语调的研究和教学尚未引起中国德语界的重视。目前知网上只能检索到3篇相关论文,而国内的德语教材的语调部分又显得过于简单粗糙:以《当代大学德语》 [2] 教材为例,教材仅以句子类型为分类,说明特定句子(在大多数情况下)使用某个调型,其他关于不同调型的使用并无详细阐述。本文旨在探究中国德语学习者使用降调的特点,为后续的教学改进策略提供事实基础。
本文分为三个部分。第一部分理论部分,笔者将展示德语语调的国内外相关研究现状,实验中所需的若干定义以及两个理论,即GToBI模型和“语调格局”理论;第二部分是实验过程,包括实验的设计,参数设定,以及数据展示,即通过语调格局公式归一化后得到的GToBI模型和被试朗读的句子的数据;最后把被试的数据和标准进行比较分析,得到数据结果;第三部分为归纳试验结论和未来展望。
2. 理论部分
2.1. 研究现状
在德语语言国家已经有了较多的德语语音语调相关的理论和实证研究,这些研究的结果为德语课程提供了一定的理论基础和教学方法论。Hunold (2009) [3] 在有关中国德语学习者语音层面问题的文章中,通过对10名高级德语的中国学习者进行考察,由7名审核人员通过听觉进行三角分析得出:中国德语学习者在语调方面的问题更加严重。Hirschfeld (2010) [4] 通过分析10名中国大学生的录音,归纳出中国德语学习者在超音段音位方面的错误,其中有关句子语调的错误有如下:句末的降调有些测试者没有达到降调标准的最低点;句子中过多使用的升调;逗号前应该使用平调的地方大多使用了降调。
在国内,李享在探究德语学习者在超音段层面的错误时,以曲拱变化分析发音表现,并得出中国德语学习者德语语调的问题为:“句子内的音调变化过于频繁,降调不够低,平调使用少;过多的停顿……这些错误的共同作用,给予听者留下的印象是:不流畅,节奏感不强……” [5] 以及2017年的论文中通过中文和德语音高范围的位置比较指出:“中国学习者在说德语时往往不注意德语这种单词的语调特点,语调变化频繁,单词之间的音高距离过大,用平调的地方用了降调,用降调时音调偏高,特别是句末单词的音调降不下去。”即中国德语学习者由于受到母语的负迁移影响存在“中国口音” [6]。
正如以上文献所反映,国内外关于中文母语者的德语语调的研究已经获得一些,但不多的成果,但验证方法为听觉判断或者以语图对比,但以听觉和视觉为判断标准无法保证评判足够客观,并且这些结论大多为定性分析。若能够把语调偏误量化,得出数据加以对比归纳,学生偏误的程度和特点能够更加客观和直观地被展现出来。
现能够量化语调并且能进行量化比较的方法有Cangemi,Aviad和Martine (2019) [7] 提出的建立语调模型的方法,它依赖于连续语调的参数化(F0曲拱和周期性轮廓F0-contours and periodicity profiles),而不是依赖于语调的离散化(分为语调目标(intonational targets))和文本的离散化(分为片段);Wehrle等(2019) [8] 在测量自闭症儿童语调风格时,使用的计算F0曲拱在一定时间内“改变方向”的次数,即在测量的语音部分中包含多少不同的上升和下降(Wiggliness),以及单独的上升和下降的斜率范围,即F0的最大偏移量(Spaciousness)两个参数的方法;国内有石峰提出的语调格局理论,原本用于分析汉语语调的音高表现、时长和强度 [9]。三个理论原本运用于分析完整句子或者说整段F0轮廓的特点,不用于量化单独调型,与本文目的并不相符,但由于语调格局理论的起伏度的理念更加适用于句末降调的测量,所以本文对语调格局起伏度公式加以变化,进而进行应用。尚春雨(2020) [10] 曾将语调格局方法应用于英语语调的研究,已经有了一定的经验,但语调格局还未应用于德语语调的研究,故笔者把语调格局应用于德语语调的研究,用语调格局理论来弥补现有相关文献中没有进行量化的不足。在下文中会对此做进一步的说明。
2.2. 语调
2.2.1. “自主音段——节律”理论
为说明本研究中如何运用GToBI模型中的符号确定参照样本和被试样本中的降调界音,有必要对GToBI中的符号,即AM理论中的符号进行说明。
Pierrehumbert提出,将自主语音学与韵律语音学相结合,从而建立了一个新的理论框架来研究语调,即自主音段–节律理论(autosegmenal-mericaltheory),简称为AM理论。在AM理论的框架内,语调成为正式成为语音学的研究对象 [11]。自此AM理论的运用也越来越广泛,下文笔者所用到的GToBI理论也是基于AM理论的。
Pierrehumbert (1980) [12] 提出英语语调包含三种不同类型的音调,七个音调重音(H*, L*, H* + L-, H- + L*, L* + H-, L- + H*, H* + H-),两个中间短语界音(H-, L-),以及两个界音(H%, L%),有时界音也可以存在于句首。笔者将举一个GToBI模型中的例子来展示AM理论如何标注句子:
2.2.2. 界音
在德语语言学界一般把德语的语调区分为两个范畴:标志着语调单元边缘的界音(Grenztöne)和强调对语篇信息重要的特定元素的音(Tonakzente) [13]。在本文中研究的对象是前者,句末的降调界音。若想确定边界音,就必须找到调核。在GToBI模型中调核的定义为短语中最后一个重音和唯一的必要的音节,在结构上是最重要的,因此是短语中最突出的要素(http://www.gtobi.uni-koeln.de/gm_gt_grenztoene.html) [14]。
为了确定调核的位置,有必要区分中间短语和语调短语的概念。在GToBI模型中,界音分为中间短语(Intermediärphrase)和语调短语(Intonationsphrase)。语调短语存在于句子末尾,一个语调短语至少由一个中间短语组组成,因此一个句子里总是包含至少两个边界音 [15]。该例子展示了对上述概念的解释:

在Melanie后和Ingo后分别存在一个中间短语(ip),整个句子又是一个完整的语调短语(IP)。本文中选择语调短语的边界音进行测量。本句的调核为第二个中间短语,也即整个的语调短语的末尾“Ingo”,从“Ingo”到句末便是本研究的研究对象界音。
2.2.3. GToBI模型
为了衡量中国德语专业学生德语降调的特点,必须找到一个可以被认为是“标准”的参照。即使非德语语音学家和德语母语者根据这个“标准”也应该有能力判断“标准”和被试的降调是否是标准的。如果有已经有被德语语音学家标注好了的降调的德语句子和这些句子的录音,这些句子和录音则很适合成为本研究所需要的参考。量化这些“标准降调”就可以找到降调的参考标准。笔者找到了这样的参照,即GToBI (German Tones and Break Indices)模型。
Grice和Baumann (2002) [16] 证明,GToBI的描述完整性明显大于其他德语语调的自主音段分类度量模型(Autosegmental-Metrischer Modellezur Intonation des Deutschen)。并且GToBI模型中有大量句子作为示例,相应地有德语母语者朗读的音频供使用者下载。文中的用于参考标准的句子都为GToBI模型中各调型的例句。
笔者在GToBI模型中选择了句末的下降界音,也就是语调短语(IP)的降调边界音作为参照标准,在GToBI模型中标注符号表示为L-%。图1为GToBI模型中以L-%结尾的一个例子:
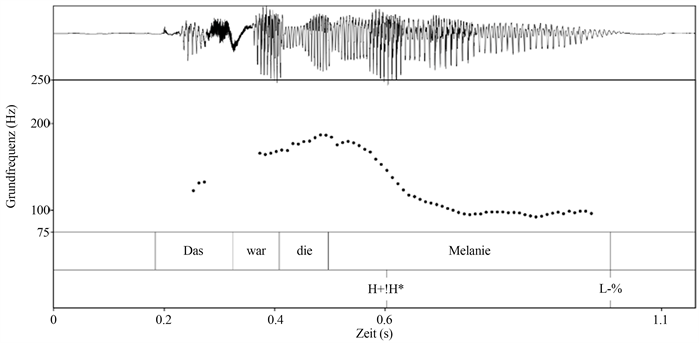 (http://www.gtobi.uni-koeln.de/gm_ta_hdownstephstern.html).
(http://www.gtobi.uni-koeln.de/gm_ta_hdownstephstern.html).
Figure 1. GToBI-Transcription of “Das war die Melanie”
图1. “Das war die Melanie”的GToBI标注
上图(见图1)和数据来自于Praat [17] ,基频值(F0)与曲线上的点相对应。笔者在句子中测量所需的F0,是从音节DIE到句末降调的最低点,即调核的拐点到句子末尾。但现实的德语学习者样本中,被试的音调并不总是平滑的曲线,这时人为地确定出降调开始的位置,会有出现偏差的可能。所以笔者用Praat的脚本Polytonia来确定降调开始位置。Polytonia能自动标注,并且能够显示音高的走势,其中的程式化(stylization)可以直接去除不重要的奇异音,并且可以直接显示出重要的语调音(intonational targets)的基频值,可以避免人工找降调的偏差 [18]。
相较于GToBI,Polytonia的音高等级划分得更加细致,音高等级由以下符号表示“L”(低),“H”(高),“M”(中),“T”(音域的顶部)和“B”(音域的底部)。音高移动将用“R”(大升)、“F”(大降)、“R”(小升)、“F”(小降)和“_”(平)表示。复合使用这些符号的序列:例如,“RF”(上升–下降),“_R”(水平–上升),“R_”(上升–水平)…… [18] ,在本文中使用Polytonia判断样本调型、拐点和结束点的位置即基频值即可,与GToBI的标注模型并不冲突。如图2就是句子Daswardie Melanie在Polytonia里的音调曲线,从H开始被标注的降调开始的位置。

Figure 2. Polytonia-transcription of “Das war die Melanie”
图2. “Das war die Melanie”的Polytonia标注
GToBI模型对语调采取符号化的标记。虽然它能够以简明、灵活和直观的方式表示语调,但它不能量化曲拱,这是该模式的一个缺点。因为每个人都有不同的音域,所以不可能仅仅用音高曲线来比较来自不同人的语音样本。
本文考察的降调界音在图2中即是H对应的F0到最低的L对应的F0之间的内容。句末降调的参考标准和被试样本的句末降调界音的界定皆依据此方法。
2.2.4. 语调格局
正如前文所述,目前没有发现合适的专门用语量化短曲拱的量化方法。目前所发现相对适合用以语用量化短曲拱的是“语调格局”理论。调格局是石峰提出的一种量化语调的理论,它从广义的语调出发,系统地分析和研究了音高、音长和音强的量化表现 [19]。通过综合研究,成为了研究音调的重要工具,使得语音实验具备了可操作性。
“语调格局”包括对语调、音长和强度的量化。由于音强对语调感知的作用很小 [13]。以及Jörg [20] 证明:“语速(V1a)、停顿时间(V1b)、IP长度(V1c)和短语与标点符号的协调(V1d, V1e)对母语者理解非母语者的表达是几乎没有影响的。”所以本研究中不将音强和音长作为研究目标,只研究最重要的语调参数,即音高。
“语调格局”公式的目的为量化整个句子的起伏度,但本文的研究对象为句末降调,故,借鉴“语调格局”中将句子归一化,把语调放入同一个百分比中进行比较的思想,测量句末降调起始点在句子中的百分比。其计算方法如下:
首先,将测量的赫兹值(Hz)转换为半音(semitone,缩写:St),公式如下:
[13]
其中“f”是要转换的赫兹值,“fr”是参考频率,男性设置为55赫兹,女性设置为64赫兹。然后以百分比计算不同组的起伏,以量化不同的音调范围。百分比的计算是一种相对化的归一化算法,其计算方法如下 [9]:
在这篇文章中,Gi是降调起始点的半音值(上线半音值),Gj是降调结束点的半音值(下线半音值)。Smax最高半音值,Smin是最低半音值。Ki是降调起始点在句子中的百分比,Kj是降调结束点在句子中百分比,Kr为降调的百分比跨度。Ki,Kj,Kr的值足够对比出标准与样本的区别,因此不再进行起伏度Q值的计算。
计算所需的基频值皆从Polytonia的Stylization文件中获得。
这里我们无法排除一种情况,就是被试错误使用了其他调型,计算出的值不在标准范围内。为了结论更加严谨,笔者把同样计算了其他两种调型的最大波动范围,即升调和平调。这里起伏度为负时表明语调上升,起伏度为正则表明语调下降。计算结果为:降调:0.00~100.00,升调:−100.00~0.00,平调:1.47~10.25。表1为GToBI模型里计算范围所使用的句子:

Table 1. Selected Sentences from the GToBI-model
表1. GToBI模型中的句子
(http://www.gtobi.uni-koeln.de/gm_gtobi_modell.html) [21].
3. 实验部分
3.1. 实验设计
第一步,选取6名女性和6名男性作为被试,被试从2017届德语系学生中随机抽样,要求他们朗读前文中从GToBI模型中选出的降调句子。试验在安静无噪音的语音室进行,用E-Prime展示句子,录音设备为Sudotack 40Hz-17000Hz HD300降噪录音话筒,保存为*.wav格式。
第二步,试验前告知被试两个必要条件,首先为不带感情地朗读句子。其次是在句末使用降调。然后给每位被试五分钟的时间来熟悉语料,由于选取的句子都为简单短句,所以被试能很快能通顺地进行朗读,要求每个被试将每个语料自然、语速平稳地朗读四遍。一共有5个句子作为语料,有被试12名,所以最终得到5 × 12 × 4 = 240个样本。这240份录音都将被用于研究分析。每句朗读四遍,一方面可以消除由于紧张造成的发音错误,另一方面,可以避免影响试验数据的偶发情况。例如,偶尔的失误,无法控制的偶发的环境噪音等。样本收集完毕后将录音导入Praat进行数据提取,语料为GToBI模型中以L-%为边界音的语调短语,即以降调结尾的短句。

第三步,取每名被试的四次录音得到的数据平均值(如果四遍中视觉上和听觉上有明显跟其他几遍不一致的,则不算在统计结果中)。分析软件为Praat里的脚本polytonia,对照polytonia所生成的语调标注,确定降调起始位置和F0的值,相较于在praat的语图中的取值,polytonia的值更加合理:由于praat非常灵敏,及其微小且不重要的赫兹值也会形成曲拱,故选取F0所在的位置很大程度上依靠操作者的经验和对语音的认知。而polytonia的语图仅显示重要的曲拱和转折点,很大程度上保证了数据的客观性。例如,被试1朗读了四遍句1,笔者将得到四个数据,即朗读第一遍F0min1,第二遍得到F0min2,……那么最终用于计算的F0是F0min1,F0min2,F0min3,F0min4的平均值。其他数据也遵循同样的方式。
最后,得出的数据将按照理论部分的描述进行处理和分析,并依照第二章中的各调型标准对其进行分类,对属于同一类别的特征进行比较和总结。
3.2. 数据展示
本章用于数据展示,本试验有6名女性被试和6名男性被试,分别表示为w1、w2、w3……m1、m2、m3……
首先在Polytonia中的Stylization文件中提取12个受试者的F0,并将其转换为半音值。在此基础上,进行归一化处理以获得百分比值。然后,将12名被试的降调起始所处的百分比值作为样本降调的上、下线(上线为降调起始位置的F0,下线为降调结束位位置的F0),最后算出被试降调范围的百分比跨度(见表2)。表3展示了降调开始的标准位置和被试降调的位置。由于数据数量庞大,表3只展示了被试的错误降调位置的数据。
Table 2. The percentages of the falling boundary tones (bold percentages stand for the standard percentage of the falling boundary tone)
表2. 降调界音范围百分比(黑体数据表示降调标准)
Table 3. The positions of each falling boundary tone
表3. 降调界音位置
3.3. 数据结果
上一章已经展示了数据,本章将对数据进行相应的分类以便进行分析样本。
被试的音调范围用EXCEL柱状图呈现(见图3~7),柱形上方的数据为Ki,下方为Kj,柱体长度则表示样本数据降调的跨度。从视觉上可以更直观地观察到样本与标准Ki,Kj和Kr的差异。为了判断被试的降调和GToBI模型中的降调是否具有显著差异,笔者利用SPSS对数据进行了威尔科森秩和检验(Wilcoxon rank-sum test),即检测被试和标准的Kr值是否有显著差异。通过结果可以分析出,p < 0.05时,可以认为样本与GToBI模型存在明显差异,
通过秩和检验和EXCEL表格涨跌柱的面积,可以从数据上和视觉上更科学直观地证明,被试样本与GToBI模型之间存在着显著的差异。
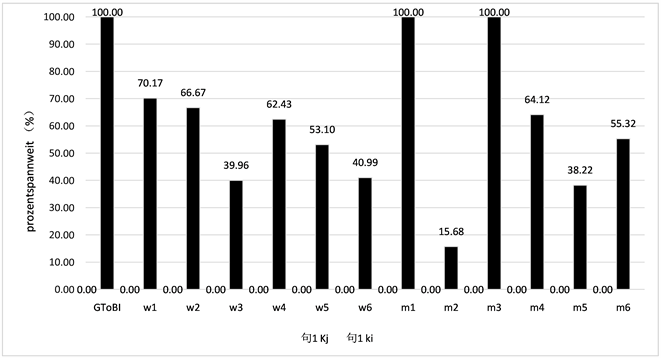 检验值1 = 0.005,p < 0.05。
检验值1 = 0.005,p < 0.05。
Figure 3. Pitch range percentage comparison of sentence 1
图3. 句1调域百分比对比表
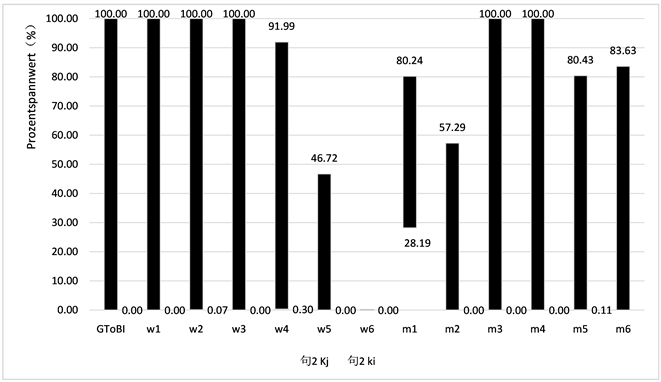 检验值2 = 0.018,p < 0.05。
检验值2 = 0.018,p < 0.05。
Figure 4. Pitch range percentage comparison of sentence 2
图4. 句2调域百分比对比表
 检验值3 = 0.012,p < 0.05。
检验值3 = 0.012,p < 0.05。
Figure 5. Pitch range percentage comparison of sentence 3
图5. 句3调域百分比对比表
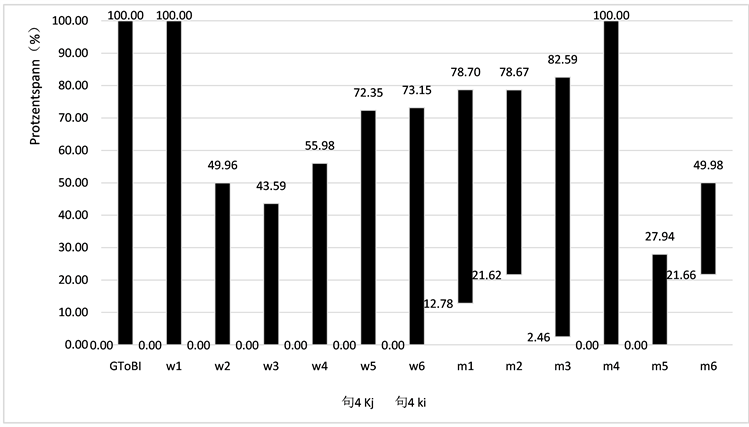 检验值4 = 0.005,p < 0.05。
检验值4 = 0.005,p < 0.05。
Figure 6. Pitch range percentage comparison of sentence 4
图6. 句4调域百分比对比表
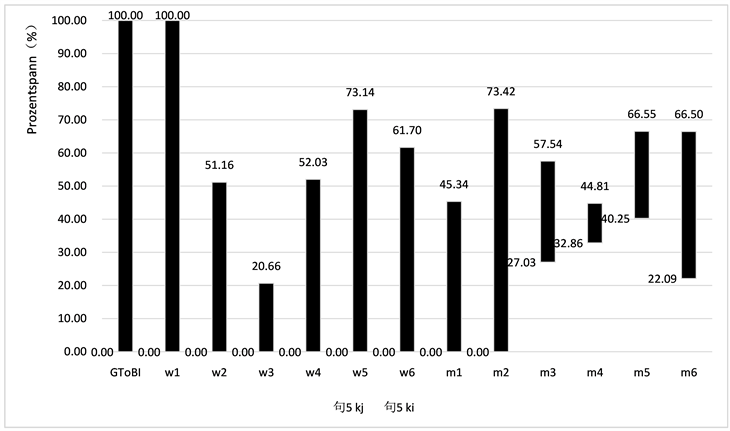 检验值5 = 0.003,p < 0.05。
检验值5 = 0.003,p < 0.05。
Figure 7. Pitch range percentage comparison of sentence 5
图7. 句5调域百分比对比表
由此,可将本研究的结论总结为:
a) 80%的样本完全没有达到标准降调调域,并且75%的样本的上线值低于标准。也就是与GToBI模型相比:样本的调域较窄,上线普遍低于标准,并且整体具有显著差异。
在所有被试中没有人在正确的声调范围内朗读所有的句子。其中大部分调域上线百分比值Ki都明显低于样本的水平。在语调格局一章中,笔者已算出降调的调域范围为0.00~100.00。通过计算只有20%的样本在降调范围内,其余的,即80%的样本调域都没有达到降调标准。
并且75%的样本的上线值低于标准。如图4~7中每个句子的上线(Ki)和下线(Kj)所示,被试的上线值普遍低于标准。而下线值基本稳定,与标准一致。Ladd [22] 的论文中表示:“……说话调域的底部(这里即下线值)是一个人的声音的一个相当稳定的特征。”上线值低于标准是大多数样本未达到标准降调调域的原因。
b) 16.7%的被试在错误的位置降调(在单词层面)。
根据端木三 [23] 中的“对立原则”,同一个音素在不同人那里的发音不可能完全一样,总是存在着细微的差别,在语音研究中应该区分哪些差别需要重视,哪些差异是无伤大雅的可以忽略不计的。
当被试m3和w9读句2时,他们的降调位置整整提前了一整个单词,改变了调核的位置。这里笔者同样使用Polytonia程序对存在偏误的音频进行了检验。虽然句子的词汇意义没有变化,但语调意义发生了变化,故笔者将这种情况作为一个特点提了出来,因为这大概率说明一些被试对调核没有概念。
c) 8.3%的被试使用错误的调型。
当被试w6朗读第2句时使用了升调,并且在重复朗读的四次中皆使用升调,被试在被告知要使用降调的情况下也并没有意识到正在错误使用调型。不仅在听觉上为明显的升调,句子句末在polytonia中同样被标注的为H (见图8)。

Figure 8. The read-sentence 2 of object w6 (Ploytonia)
图8. 被试w6朗读句2 (Polytonia)
d) 不仅从数据,从语图中我们也可以得出一些结论。被试产生的基频曲线显示在降调的末端会有一条上升的曲线,但这显然不是一个升调。该语调曲线表示的是被试无意识地延长了最后一个词词尾的音节产生的,而不是在调核后产生的语调走势变化。由于Praat灵敏度较高,在语图中也展示了这部分的语调,但这段曲线的基频值没有被计算在内。这里笔者以句子2 (以-st结尾)和句3 (以-en结尾)为例,展示被试与标准的语图,图9与图10红色虚线后的部分为无意识的延长的部分。图11与图12为标准例句句末的语图。

Figure 9. The syllable at the end of sentence 2 (w3)
图9. 句2末音节(w3)

Figure 10. The syllable the end the of sentence 3 (m9)
图10: 句3末音节(m9)
这种情况在样本中并不少见,笔者选取了较为典型的两个例子。被试在最后一个词的结尾不同程度地延长了音节。听中国学生在平时的外语表达中也会有听觉上的感知。这需要在教学中进行纠正也需要学习者有意识地改正。
4. 结论与展望
根据上述试验数据,笔者归纳了中国德语学生朗读句子末降调的特点:
1) 错误地使用调型;
2) 降调位置错误;
3) 降调降得不够(原因多为降调起始值低于标准);
4) 无意识地延长句子最后的音节。
在此还有必要对调格局中计算百分比的公式 [9] 进行进一步的讨论。
(1)
(2)
(3)
在公式1中Ki表示句末降调开始(即上线)位置在句子音域里所处的百分比位置。
在公式2中Kj表示句末降调结束(即下线)位置在句子音域里所处的百分比位置。
在公式3中的Kr表示该降调在句子音域里所占的比例。
本文中的计算范围都是单个句子的调域,但如果在计算中仅以该句子的音域为范围,会存在即使一个微小的语调起伏在狭窄的句调域里得出的数据则也将达到降调标准的情况。这种计算结果却与听觉和视觉上的结果完全不符。下图为笔者收集的样本之一,为被试m10朗读句1的样本语图:
该图为句句——Wieist Sommerin Mali?——Nichtwarmgenug.的后半部分。句末仅下降了10.4 Hz,0.86个半音。但最后的Kr值为98.48,计算结果显示这基本是一个标准的降调,但事实并非如此。从听觉上和视觉上该样本都不是一个降调。笔者同样用Polytonia进行检验,如图13 (图13的下半部分对应图14),证明该样本并非为末尾降调。同样的问题也曾在其他研究中发现过 [24]。

Figure 13. Sentence 1 of object m10 (Polytonia)
图13. 被试m10朗读句1 (Polytonia)
李宝贵,周甜甜 [25] ,宋臻怡 [26] ,谢小静 [27] 都采用的是单句句子的调域作为Smix和Smax,也就是这些样本研究所处的调域同样是绝对的句调域。
这就产生了以下一系列问题:1) 如果每句的分母不同,句子之间的起伏度的范围则不同,句与句之间在逻辑上则没有可比性。2) 如果出现上述的情况,公式则不能有效判断出不同语调是否真正有明显区别。
若想要对比不同的句子,即使是同一人在相同情况下读的同一个句子,也必须让句子的某段语调放在同一更具囊括性的调域中对比,比如将使用某种语言时的通常的总调域计算出来,也就是说,分母中Smax-Smin的值应该被换成一个更广泛的常数。这有待后续研究进一步的探索和完善。
本文只得出了中国德语学生降调朗读的特点,相应的改进策略还需要进一步研究。虽然实验过程中出现了上述状况,由于数量极少,仅有4个样本,所以本文的方法和一些数据仍可以为改善学生的语调的教学策略提供依据。
由于空间和条件的限制,文章中还存在有不足之处。课题的选择比较局限,被试仅仅为上海某一高校学生还不够有代表性。另外研究对象选择比较狭窄,本文只选取了短句,研究的方面只是德语语调的降调。未来的研究会进一步扩大研究范围。
NOTES
*通讯作者。