1. 引言
在新冠肺炎疫情后面对复杂的国际政治经济格局,中国的碳中和承诺彰显了我国构建人类命运共同体的大国责任与担当,体现了我国在应对气候变化问题上的决心和雄心,为疫后实现全球绿色复苏注入新的活力 [1]。党的十九届五中全会、2020年中央经济工作会议、2021年“两会”、中央财经委员会第九次会议等一系列会议都对碳达峰、碳中和作出了明确的战略部署 [2]。而大气污染治理作为碳中和、碳达峰目标中的重要一环,近年来,面临着许多问题需要解决。随着我国交通、建筑、制造和农业等领域发展势头迅猛,在促进社会经济稳定上涨的同时,也在一定程度上增加了废气、废物排放量,导致我国大气污染问题日益加剧,已经严重影响到社会群众健康发展。虽然党中央和政府机构针对大气污染环境治理出台了一系列政策措施,并在一定程度上提高了治理水平,但结合实际情况来看,治理效果与预想情况仍然存在很大差距 [3]。在进行大气污染治理的过程中,有一些问题值得探讨。
目前,许多学者对于大气污染问题进行了研究。蔡银寅等 [4] 从污染物排放和大气自然净化能力的平衡角度建立模型,描述了大气环境的污染和净化过程,揭示了大气环境资源的时空异质性。田时中、郭宇等 [5] 运用主成分分析法(PCA)和空间滞后模型(SLM),对中国30个省级行政区进行实证分析发现影响大气污染治理效果的多种因素,并据此提出相关政策建议。高明等 [6] 从政策网络理论的视角,运用罗茨的政策网络分类方法,从宏观、中观和微观层面对大气污染联防联控监管失灵进行分析,提出相应的路径优化策略。李鑫、马国顺等 [7] 利用演化博弈理论研究了政府及企业双方在有无主动干预两种情况下大气污染治理的结果,并根据研究结果提出了政策建议。孙雨薇等 [8] 研究了环境监测技术在大气污染治理中起到的作用,并围绕环境监测在大气污染治理中的应用进行了简要论述。刘满芝、杨继贤等 [9] 运用LMDI分解模型,对全国和30个省份2000~2010年间的主要大气污染物排放量的变化进行因素分解,并通过构建四象限法评价地区差异,分析了产生污染排放物的主要原因。从以上文献中可以看出,大多数研究关注政策应用或者基于数据分析的方法对大气污染治理进行研究,未能考虑中央政府、地方政府以及废气排放企业三方之间的博弈关系及其行为动态调整,或者只考虑了政府与企业双方之间的博弈,却未能考虑中央政府与地方政府在大气污染治理过程中的博弈。本文从演化博弈理论出发,在信息不对称条件下,分析了中央政府、地方政府以及废气排放企业之间决策行为的演化过程,并利用数值仿真的方法得到了改变部分参数可以使得各方处于最理想的治理状态。真正体现了大气污染治理过程中中央政府、地方政府以及废气排放企业之间关系的复杂性和特殊性。
2. 模型构建与分析
为了进行理论分析,我们进行一些基本假设。假定中央政府、地方政府以及废气排放企业均为有限理性的博弈群体,三方构成一个动态的演化系统,并且三方掌握不完全对称信息,且均以自身利益最大化为最终目标。中央政府具有两个策略选择,分别是政策导向和市场导向,记为AR (Administration-led Regulation)和MR (Market-oriented Regulation),政策导向是指由中央政府设立政策法规,利用补贴和政治惩罚以及加大税收等方式来对废气排放的各个影响主体进行干涉;对于地方政府而言,有两个策略选择,分别是严格执行和消极执行,记为SE (Strict Enforcement)和LE (Loose Enforcement),严格执行即严格遵守中央的各项政策法规,并且自身也利用监管补贴等方式促进废气排放企业进行减排;对于废气排放企业而言,有两个策略选择,分别是积极响应和消极响应,记为PR (Positive Response)和NR (Negative Response)。
2.1. 参数设置
C1:中央政府采用AR策略的政策成本,包括政策资源的消耗,信息获取费用以及人力成本。
C2:地方政府采用SE策略的执行成本,包括监管成本以及社会救济成本。
C3:废气排放企业采用PR策略的响应成本,包括劳动力安置成本以及更换设备成本。
I:废气排放企业采用NR策略时造成的大气污染所需的治理费用。
E:废气排放企业采用PR策略时为地方带来的环境收益。
α:地方环境质量与国家水平之比。
R1:废气排放企业采用PR策略时的企业收益。
R2:废气排放企业采用NR策略时的企业收益,一般我们认为
。
k:废气排放企业采用PR策略时进行机器与管理技术更新所为企业带来的额外收益。
θ:废气排放企业的革新程度。
F1:由于地方政府选择LE策略,所以会受到政治惩罚。(包括民众对地方政府的不满以及中央政府绩效评价的降低等)。
F2:废气排放企业缴纳的污染罚款。
F3:由于中央政府选择MR策略,所以会受到政治惩罚。(如民众对政府的政策不满等负面影响)。
β:当造成污染后,地方政府与中央政府同时选择消极和积极措施时,中央政府所付治理费用占总费用的比例。
S1:中央政府对减排企业的补贴。
S2:地方政府对减排企业的补贴。
x:中央政府采取AR策略的概率。
y:地方政府采取SE策略的概率。
z:废气排放企业采取PR策略的概率。
2.2. 模型构建
基于上述假设和参数设置,我们得到各方收益矩阵如表1所示:
其中:
2.3. 模型分析
2.3.1. 中央政府复制动态方程分析
令
是中央政府选择“政策导向”策略的期望收益,
是中央政府选择“市场导向”策略的期望收益,
是中央政府的平均期望收益,则有:
得到中央政府的复制动态方程如(1)式:
(1)
由复制动态方程稳定性定理知:
1) 当
时,
,意味着对于所有的x都是稳定状态,即中央政府无论选择何种概率的“政策导向”策略都是演化稳定策略。
2) 当
时,有
,
,于是
为演化稳定策略,即当地方政府选择“严格执行”策略概率小于
时,中央政府最终会逐渐趋向选择“市场导向”策略。
3) 当
时,有
,
,于是
为演化稳定策略,即当地方政府选择“严格执行”策略概率大于
时,中央政府最终会逐渐趋向选择“政策导向”策略。
由以上分析可知,当中央政府的补贴降低,实施政策导向的政策成本减少,或当对企业的惩罚加重,环境治理费用的比例维持在合理范围时,可以满足3)的条件,中央政府的策略选择将会由“市场导向”转为“政策导向”。
2.3.2. 地方政府复制动态方程分析
令
是地方政府选择“严格执行”策略的期望收益,
是地方政府选择“松散执行”策略的期望收益,
是地方政府的平均期望收益,则有:
得到地方政府的复制动态方程如(2)式
(2)
由复制动态方程稳定性定理知:
1) 当
时,
,意味着对所有的y均是稳定状态,即地方政府无论选择何种概率的“严格执行”策略均是演化稳定策略。
2) 当
时,有
,
,于是
为演化稳定策略,即废气排放企业选择“积极响应”的概率小于
时,地方政府会逐渐趋向选择“消极执行”。
3) 当
时,有
,
,于是
为演化稳定策略,即废气排放企业选择“积极响应”的概率大于
时,地方政府会逐渐趋向选择“积极执行”。
由以上分析可知,当地方政府严格执行的执行成本降低,对地方政府的惩罚加重,或对排污企业的惩罚加重,环境治理费用的比例维持在合理范围,以及地方政府的补贴降低时,可以满足3)的条件,地方政府最终将会选择“积极执行”策略。
2.3.3. 废气排放企业复制动态方程分析
令
是废气排放企业选择“积极响应”策略的期望收益,
是废气排放企业选择“消极响应”策略的期望收益,
是废气排放企业的平均期望收益,则有:
得到废气排放企业的复制动态方程如(3)式
(3)
由复制动态方程稳定性定理知:
1) 当
时,
,意味着对所有的z均是稳定状态,即废气排放企业无论选择何种概率的“积极响应”策略都是演化稳定策略。
2) 当
时,有
,
,于是
为演化稳定策略,即中央政府选择“政策导向”的概率小于
时,废气排放企业会逐渐趋向选择“消极响应”策略。
3) 当
时,有
,
,于是
是演化稳定策略,即中央政府选择“政策导向”的概率大于
时,废气排放企业会逐渐趋向选择“积极响应”策略。
由以上分析可知,当废气排放企业响应成本降低,废气排放企业消极响应时收益减少,废气排放企业积极响应时收益提高,技术革新带来的额外收益增多,对废气排放企业消极响应时的惩罚加重以及可获得的补贴额提高,都会促使废气排放企业最终选择“积极响应”策略。
2.4. 三方演化策略分析
根据以上分析,我们可以将中央政府,地方政府,废气排放企业三方的复制动态方程组成一个动态系统,令(1) (2) (3)三式都等于0,即可得到该动态系统的平衡点,根据Weibull和Ritzberger的研究 [10],我们主要对
,
,
,
,
,
,
,
的渐近稳定性进行讨论,其余的平衡点皆为非渐进稳定点不予讨论。根据Friedeman的研究 [11],我们可以利用Jocabin矩阵对动态系统稳定性进行判别,该动态系统的Jocabin矩阵如下:
(4)
中央政府:
地方政府:
废气排放企业:
由Liapunov第一定理 [12] 知,若平稳点为演化稳定点,则其所对应的Jocabin矩阵的特征根
,
,
的实部小于零,下面我们对动态系统各平衡点进行稳定性分析,结果如下表2所示:

Table 2. Stability analysis of equilibrium point
表2. 平衡点稳定性分析
本文的研究目的是为了让废气排放企业积极响应政府政策,以减少废气排放。所以我们主要研究废气排放企业选择“积极响应”策略的渐进稳定点,即
,
,
,
。
当满足条件
,
,
时,平衡点
是演化稳定点,如图1(a)。即中央政府选择“市场导向”策略,地方政府选择“松散执行”策略,排污企业主动去进行减排。这种情形下,虽然中央和地方政府没有选择干预排污企业,但是排污企业由于减少废气排放时的收益大于未减少废气排放时的收益,所以主动选择减少废气排放。这种情形一定程度上有助于大气污染治理,但是由于缺乏中央政府与地方政府的统筹安排,使得不能最大化发挥企业减排的效用,造成企业无序减排。这种稳定状态虽然有一定的积极作用,但并不是最理想的。
 (a)
(a)  (b)
(b) 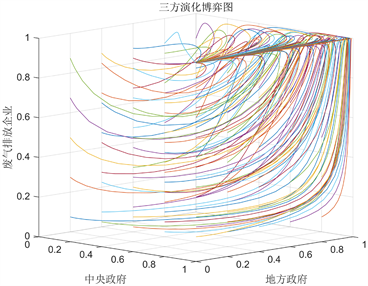 (c)
(c) 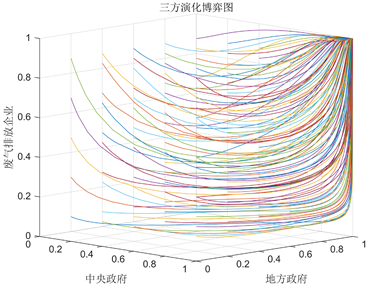 (d)
(d)
Figure 1. Evolutionary game diagram
图1. 演化博弈图
当满足条件
,
,
时,平衡点
是演化稳定点,如图1(b)。即中央政府选择“市场导向”策略,地方政府选择“严格执行”策略,而废气排放企业选择“积极响应”策略。在这种情形下,地方政府加强监管,为废气排放企业提供一定的补贴,而废气排放企业也选择进行减排,双方合作行为一定程度上对大气环境治理起到促进作用,但是由于缺少中央政府的统筹安排以及政策保障,很多企业减排的行为以及地方政府的监管容易没有尺度,显然这种稳定状态不是最佳的。
当满足条件
,
,
时,平衡点
是演化稳定点,如图1(c)。即中央政府选择“政策导向”策略,地方政府选择“松散执行”策略,而废气排放企业选择“积极响应”策略。其分析过程与上方类似。
当满足条件
,
,
时,平衡点
是演化稳定点,如图1(d)。即中央政府选择“政策导向”策略,地方政府选择“严格执行”策略,而废气排放企业选择“积极响应”策略。这种情况下,三方共同协作,中央政府积极解决大气污染问题,提供政策保障,地方政府也严格执行政策并且加强对废气排放企业的监管,而废气排放企业也积极响应政策进行减排,为大气污染治理贡献力量。这种良性循环使得各方都得到收益,是一种理想的稳定状态,应该努力促成这种稳定状态的实现。
3. 模拟仿真
基于本文的研究目的,为了能使我国大气污染的治理迈向新的台阶,我们主要考虑能够演化到最理想的稳定状态的情形,即演化稳定点为
。对此,我们利用数值仿真的方法将次一级的稳定状态向最理想的稳定状态进行转化。根据实际情况,我们得知中央政府为了促进大气污染治理,出台了多项政策以及激励措施。由此,我们认为中央政府会选择“政策导向”策略。
在此情形下,我们对部分参数进行敏感性分析,尝试使次一级稳定状态
,
在参数调整的情况下转化为最理想的稳定状态。三方初始群体比例记为
,
,
,接着我们采用控制变量的方法,保持其他参数的取值与初始值相同,使待研究参数在一定范围内选取不同的取值,然后利用Matlab进行数值模拟仿真,观察三方稳定策略的变化。
3.1. 次一级稳定状态(1,0,1)敏感性分析
首先,我们设置参数,令
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,地方政府对于废气排放企业的补贴
在一定范围内选取不同的值,其他参数保持不变多次仿真得到图2所示。可以看出当
设置较大时,中央政府选择“政策导向”策略,地方政府选择“松散执行”策略,废气排放企业选择“积极响应”策略;随着
的不断减小,地方政府政府由于期望收益的增加,开始转变策略向着“严格执行”方向演化,最终演化成为最理想的稳定状态。
我们设置参数,令
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,由于地方政府选择LE策略而受到的政治惩罚F1在一定范围内选取不同的值,其他参数保持不变多次仿真得到图3所示。可以看出当F1设置较小时,中央政府选择“政策导向”策略,地方政府选择“松散执行”策略,废气排放企业选择“积极响应”策略;随着F1的不断增大,地方政府由于期望收益的增加,开始转变策略向着“严格执行”方向演化,最终演化成为最理想的稳定状态。从三个分图中可以看出,随着F1的不断增大,各方都趋于协同合作的时间也在不断加快。
3.2. 次一级稳定状态(1,1,0)敏感性分析
同样,我们首先设置参数,令
,
,
,
,
,
,
,
,
,
,
,
,
,
,
,废气排放企业设备的革新程度
在一定范围内选取不同的值,其他参数保持不变多次仿真得到图4所示。可以看出当
设置较小时,中央政府选择“政策导向”策略,地方政府选择“严格执行”策略,废气排放企业选择“消极响应”策略;随着
的不断增大,废气排放企业由于期望收益的增加,开始转变策略向着“积极响应”方向演化,最终演化成为最理想的稳定状态。
4. 结论
本文与实际情形相结合,运用演化博弈理论建立了中央政府、地方政府以及废气排放企业的三方博弈模型,并分析了各个博弈方之间决策行为的演化路径,着重研究了最终会进行减排的几种情形。通过数值仿真运用控制变量的方法直观地展示如何将次一级稳定状态转向最理想的稳定状态(政策导向,严格执行,积极响应)。综合上述分析结果,若满足以下条件,最理想的稳定状态有可能达到:
1) 中央政府在选择“政策导向”补贴后的净收益大于“市场导向”策略下的利润。
2) 地方政府在选择“严格执行”策略后付出补贴和监管成本后的净收益大于“松散执行”策略下的利润。
3) 废气排放企业选择“积极响应”得到补贴以及进行设备革新后得到的净收益大于减排之前的利润。
在实际情形下,我们利用模拟仿真的结果得到次一级稳定状态的转化方法,以期通过部分调整来达到最理想状态:
1) 当中央政府与废气排放企业愿意协同合作,而地方政府“松散执行”时,我们可以通过适当降低补贴额和提高政治惩罚来使得地方政府选择“严格执行”策略。
2) 当中央政府与地方政府愿意协同合作,而废气排放企业“消极响应”时,我们可以通过加强补贴力度,帮助企业进行技术革新等方式吸引企业选择“积极响应”策略。
致谢
感谢国家自然科学基金项目:高维度复杂数据分析中的贝叶斯随机桥惩罚回归:理论、方法及应用(12061065);随机动态死亡率模型的统计性质及应用研究(12061066)的资助。
NOTES
Email: zjr3504353220@163.com