1. 引言
随着扶贫进程的深入推进,全国各贫困地区不断脱贫,但扶贫政策的效果逐渐减弱,有关贫困问题研究开始受到社会的广泛关注。刘玉杰在多维贫困视角下进行了空间聚类与相关性研究 [1];马绍东、万泽仁利用多维贫困分析方法“A-F (双重临界值法)”,在多维贫困视角下探究了民族地区返贫成因 [2];张昭等利用AF方法测算了农村老年人的多维贫困,并进一步通过贫困分解的方式考察了人口老龄化对农村多维贫困的影响 [3]。本文在多维贫困视角下,利用主成分分析、系统聚类方法对全国各省份进行了有效的分类,以探究各地区贫困成因的不同。
2. 材料与方法
2.1. 多维贫困指标选择
经济学家阿玛蒂亚·森提出多维贫困理论,他认为贫困包括收入、健康、教育、住房及公共物品的可获得性等多个维度的缺失 [1]。基于多维贫困理论,本文在已有文献的基础上进行补充,最终选取人口结构、经济水平、教育水平、医疗、文化以及交通运输六个维度,并进一步选取多个二级指标作为衡量贫困问题的指标,如表1所示。
1) 人口结构和经济水平
经济水平是最传统的衡量贫困问题的指标。经济水平直接反应人们的生活水平,影响着一个地区贫困现象的发生。同时,已有文献资料显示,人口结构对经济的增长具有显著影响 [4],进而对各地区贫困程度的影响也是不容忽视的问题。在人口结构和经济水平两个维度下,本文选取平均家庭户规模、总抚养比、居民人均可支配收入、公共预算收入、人均居民消费支出以及货物进出口总额作为二级指标。其中,总抚养比指人口总体中非劳动年龄人口数与劳动年龄人口数之比。
2) 教育和文化
一个地区的教育和文化水平直接反映了该地区居民的精神文化生活。在教育和文化两个维度下,本文选取了文盲人数占15岁以上人口比重、文化制造业企业数、广播节目综合人口覆盖率、文化制造业企业数作为二级指标。
3) 医疗和交通
一个地区的医疗和交通条件能够反映出该地区居民的生活便利度。一个医疗条件好、交通发达的地区往往经济水平更高,对一个地区的贫困程度也有着不可忽视的影响。在医疗和交通两个维度下,本文选取诊疗人次数和客运量作为二级指标。

Table 1. Selection of poverty index
表1. 贫困程度指标选择
2.2. 数据来源
本文数据来源于2020年《中国统计年鉴》。
2.3. 统计分析—主成分分析和系统聚类
由于本文选取的各个指标单位不同,为避免单位量纲的影响,首先利用统计软件R对原始数据进行标准化处理,对每个数据用以下公式进行处理:
(1)
其中,
为标准化后的数据,
为原始数据,
为第j个指标的均值,
为第j个指标的样本方差。
随后,我们从相关矩阵出发对标准化后的数据进行主成分分分析。根据累计贡献率选取少数几个主成分,在保留原始数据大部分信息的基础上,又很好的对原始数据进行了降维处理。
最后,利用降维后的数据进行ward聚类。本文选取欧式距离作为衡量样品之间的距离,通过树形图以及实际情况,最终确定分类个数,得到分类结果。
3. 结果与分析
3.1. 主成分分析降维结果
由于刚开始选入的十一个变量存在较高的相关性,观测数据中的信息在一定程度上有所重叠,因此本文利用主成分分析方法对十一个变量进行降维,从而使问题的分析得以简化。
利用R软件对数据进行标准化后,对十个变量进行主成分分析,分析结果如表2所示。
Table 2. Results of principal component analysis
表2. 主成分分析结果
由表2可以看出,前三个主成分的特征值均大于1,且前三个主成分的累计贡献率达到了82.88%,可以反映原始变量的大部分信息。同时,由陡坡图(见图1)也可以得到,选取三个主成分有较好的结果。
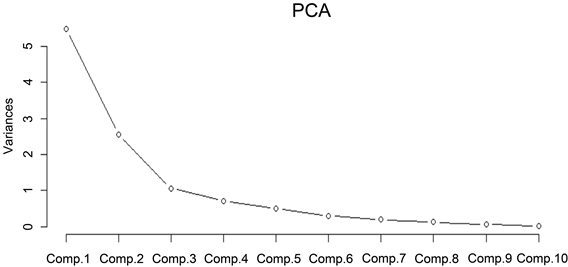
Figure 1. Steep slope map of principal component analysis
图1. 主成分分析陡坡图
进一步,得到前三个主成分分别为:
通过分析载荷,由于
在
上的载荷为正,其余为为负,则第一主成分可以看作度量人口结构和教育对贫困程度的正向影响变量。由于
在
上的载荷为负,因此可将第二主成分看作消费对地区贫困程度的负向影响变量。在第三主成分中,
上的载荷最大,故我们将
看作教育对地区贫困程度的影响变量。
利用R软件分析得到各地区主成分得分如图2所示:
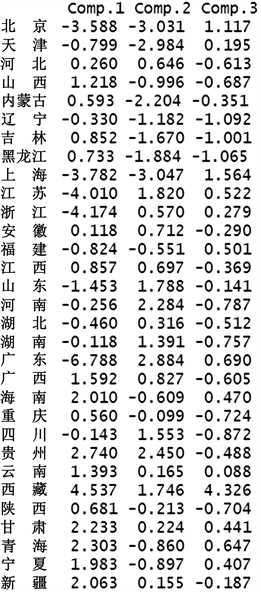
Figure 2. Scores of the first three principal components
图2. 前三个主成分得分
3.2. Ward聚类结果分析
Ward聚类法又称离差平方和法,是一种常见的系统聚类方法。在提取完主成分以后,对选择的前三个主成分进行系统聚类分析。在Ward聚类中,定义
和
之间的平方距离为
,其中
分别为
的离差平方和,每一步合并使离差平方和增量达到最小的两个类。主要的步骤是利用上述定义的类间距离测算31个地区的类间距离,同时生成距离矩阵,选择使离差平方和增量达到最小的两个类进行合并。重复以上步骤,最终所有31个地区将合并为一个大类。聚类结果如图3所示。
从统计角度来看,理想的聚类结果应该是:类的个数适当,类之间较分开而类内相近。如果在(15, 25)内切一刀,则分为两类;如果在11附近切一刀,则分为四类。从聚类的实际意义出发,分四类似乎更加符合实际情况。北京、上海、广东、江苏、浙江由于经济发展水平高,几乎无贫困现象发生,可将其定义为无贫困地区;河北、河南、山东等地由于人口较多,劳动力充足,属于轻度贫困地区;内蒙古、吉林、黑龙江等地由于地理位置偏远,属于中度贫困地区;青海、新疆、宁夏、甘肃等地区为少数民族聚集地,经济发展较为落后,生活便利程度低,属于深度贫困地区。
4. 讨论
4.1. 结论分析
1) 经济发展水平、教育、医疗水平、人口结构、交通发达程度均对各地区贫困程度有影响。通过主成分分析的载荷可知,不同主成分分别代表了不同维度指标对各地区贫困程度的影响。由主成分得分,我们可以得到各地区的贫困影响因素,从而有针对的提出建议。
2) 根据贫困程度不同,本文将31个地区共划分为四类。第一类:北京、上海、广东、江苏、浙江。第二类:福建、河北、河南、山东、重庆、安徽、陕西、山西湖北、湖南、四川。第三类:内蒙古、吉林、黑龙江、辽宁、天津。第四类:西藏、贵州、青海、宁夏、江西、广西、海南、云南、甘肃、新疆。
4.2. 建议
1) 政府应当通过生育政策的制定来控制当地的人口结构。由本文分析可知,人口结构是影响各地区贫困的重要原因,社会抚养比过大、平均家庭户规模过大都是造成贫困的重要原因。因此,制定一个适合的生育政策对于保持脱贫成果是十分必要的。
2) 根据分类结果,政府应当分区域采取不同的扶贫措施,而不是对所有地区采取相同的扶贫政策。基于本文聚类结果,西藏、贵州、青海等地划分为一类,说明少数民族地区仍然是我国扶贫的重点关注地区,政府应当充分分析当地实际情况,保证该地区脱贫不返贫,有效维护好脱贫的成果。
附录:R程序代码
data <- read.table(D:/data/data3.csv, header = T, sep = ) #读入数据
data1 <- scale(data[, -1])
#---------------------主成分分析-----------------------#
round(cor(data1), 3) #计算相关矩阵, 保留3位小数
PCA<-princomp(data1, cor=T) #从相关矩阵出发进行主成分分析
PCA
summary(PCA, loadings=T) #列出主成分分析的结果
screeplot(PCA, type=lines) #陡坡图,用直线图类型
scores<-round(PCA$scores, 3) #主成分得分, 保留3位小数
scores<-cbind(data[, 1], scores[, c(1, 2, 3)]) #将地区名与前3个主成分得分合并
scores
#------------------------ward聚类------------------------#
d <- dist(data1, diag = T)
#离差平方和法#
hc<- hclust(d, ward.D)
cbind(hc$merge, round(hc$height, 2))
plot(hc, hang=-1, labels = data[, 1]) #聚类分析树形图