1. 几种EN的讨论
1.1. 经典LASSO
针对高维数据的特殊性质,Tibshirani (1996)受到Frank (1993)提出的bridge regression和Breiman (1995)提出的non-negative garrote思想启发,提出了LASSO (least absolute shrinkage and selection operator)变量选择方法。Non-negative garrote比其他子集选择方法的预测误差小,而且当回归系数中有很多较小非零系数时,non-negative garrote方法也比ridge regression的预测误差小。Non-negative garrote方法在变量选择方面有很好的性质,但是它在进行参数估计时会过度依赖OLS估计值的符号和大小,LASSO方法避免了由于OLS估计带来的负面影响,所以LASSO估计在高维数据变量选择方面得到了广泛的应用,之后也有ALASSO、RLASSO、GLASSO等“优化”后的LASSO方法提出,LASSO估计定义为:
(1)
其中
为惩罚参数,可以用来控制参数的压缩量。选择适当的λ可以使得一些回归系数缩小并趋向于0,且可依据高维数据的特殊结构,不要求设计矩阵为满秩。
LASSO继承了non-negative garrote 的在变量选择方面的优良性质,同时改进了其缺点,之后Bradley Efron等提出的最小角回归(LARS)算法又解决了LASSO的计算问题,使得LASOO在高维数据变量选择方面得到广泛的应用 [1]。当变量间存在共线性的情况时,LASSO的效果不如岭回归,所以结合岭回归的优势,提出了和LASSO相似,能够进行变量选择(可解释的预测规则)和收缩(防止过度拟合)的EN (Elastic Net),而且EN还能以组的形式选入或者选出模型,这一思想也可以应用于图像识别处理技术上 [2]。
1.2. EN估计
Zou等提出了Elastic Net方法 [3],且说明了在具有共线性变量的时候EN效果会优于LASSO,高维数据中的协变量通常具有复共线性 [4]。LASSO分析在面对有多个强相关变量的时候,会选择只保留一个变量,而EN会全部保留。EN和LASSO一样,借鉴了NEN (Naive Elastic Net)的思想,折中了岭回归和LASSO回归 [5],通过混合比控制,其表达式可表现为:
(2)
当r = 0时,EN方法与岭回归方法同表达式;当r = 1时,EN方法与LASSO方法同表达式。NEN原本对具有共线性变量的数据就有很好的建模性质,克服了LASSO在针对共线性变量选择的不足后,也综合了岭回归在处理共线性变量问题上的优势,EN估计定义为:
(3)
其中,
。
和
为调和参数且均非负,当
时就是LASSO回归,
时就是岭回归,岭回归以增大模型的偏差作为代价,通过压缩模型的系数来减少模型的预测方差,但不会将系数压缩为0,因此达不到变量选择的理想效果。惩罚项
能得到稀疏模型, 也就能控制模型的稀疏度;
允许变量具有共线性,虽然会增大模型的偏差但是会使得预测方差变小,后两项就可以达到通过变量影响力降维的目的。
1.3. AEN估计
针对LASSO估计在某些情况下不相合的问题,Zou于2006年提出了具有Oracle性质的Adaptive LASSO方法 [6] [7] [8],很好的缓和了LASSO的不足。AEN针对变量共线性的性质在Cox模型上有很好的体现,即强相关变量得到的系数估计大致相同,这是呈递了EN的优点,但Elastic Net估计不具有Oracle性质,而Zou和Zhang在Elastic Net的基础上,结合Adaptive LASSO的Oracle性质,对一阶范数惩罚部分加权,提出了具有Oracle性质的Adaptive Elastic Net (Adaptive LASSO & Elastic Net)方法 [9],对应的,当建造的模型具有Oracle性质时说明选取的权重是合适的,AEN估计定义为:
(4)
其中
。
EN和AEN都能处理共线性问题,但是在遇到数据具有组效应时,AEN的表现会明显优于EN,相应的算法也会更加复杂一些。
1.4. WEN估计
高维数据会涉及很多的变量,且这些变量间不可避免的存在相关关系,有些变量甚至来自于同一个组类,然而对于决策者而言,需要知道的是最重要的哪几个变量。通常我们只想将重要的组,或者组中重要的变量选择出来(双重变量选择),在一定程度上可以解决LASSO中惩罚过度的情况 [10],此时对存在的重要变量需要赋予更高的权重,那么WEN (weight Elastic Net)就是很好的维数约简方法。当相关性较高时Fan和Li提出非凸罚函数SCAD (smoothly clipped absolute deviation)和MCP (minimax concave penalty)就有很好的表现,SCAD估计器具有许多理想的属性(比如oracle性质),而WEN中主要包含的就是SCAD与EN的结合Snet以及MCP与EN的结合Mnet。
1.4.1. Snet
SCAD结合岭回归和LASSO回归的思想, Zeng和Xie提出当变量相互相关且都与响应变量或者残差高度相关的时候,可以将变量归为同一组获取关于分组的信息,且通过以下方法在保证模型稀疏性质的同时减少预测误差 [11],SCAD可以解决LASSO情况下惩罚过度问题,其估计的定义为:
(5)
其中
,对应的SCAD函数为
(6)
1.4.2. Mnet
Mnet和Snet的约简思想相似,以提供一种惩罚函数用来处理高维数据中具有高度相关数据,Mnet估计定义为:
(7)
其中MCP函数为
(8)
从函数表达式可知,选取合适的惩罚参数后
时,
越大,
增大越缓慢;
时,
不变化,也就不惩罚对应的系数,这将改善模型中对较大系数的过度惩罚。
2. 数据分析试验
在实际的高维数据分析下,变量间有相关性的情况很多,变量间呈现成组出现也是常遇到的情况。Cox模型作为一种半参数模型在生存模型上的应用比较广泛,半参数模型比参数模型灵活,又比非参数模型更好解释。因为模型本身具有的优点,Cox模型在生存分析中一直得到研究者的关注,所以这方面的研究越来越多,本文研究中就用R自带的“smart”数据进行Cox建模分析,通过建立几种不同的高维数据模型得到的结果进行比较,并讨论出这几种处理方法的异同。
2.1. 模型结构
Smart数据集是有3873个观测值、29个变量的数据集,包含了27个变量,1个时间变量,1个结果变量的数字矩阵。SEX (男 = 1,女 = 2)、SMOKING(从不 = never,以前 = former,现在 = current)、ALCHOHL (从不 = never,以前 = former,现在 = current)、BMI (糖尿病)、DIABETES (血压)等变量,关于数据的详细信息可见R软件的官方网站 [12]。
在对数据进行生存分析时,Cox比例风险模型中因为参数估计稳健而成为目前最常用的分析方法,它会同时考虑生存时间与生存结局,但是该模型要求各自变量间相互独立,自变量个数要小于样本量,对于高维度、强相关、小样本的生存资料,Cox比例风险模型便不再适用。Tibshirani (1997)将LASSO方法应用于生存分析的Cox模型中进行变量选择与降维,闫丽娜等(2012)比较Cox模型的岭估计、基于LASSO的Cox模型和Elastic Net的原理,并通过模拟比较了三种方法对于小样本、高维度、强相关下生存数据分析的优劣,展示了惩罚Cox模型和Elastic Net技术在生存分析中的应用,在研究生存时间对协变量的依赖性时,Cox的比例危险模型包括一个受试者
是受试者在t时的危险函数,
是完全未指定的基线危险函数,
是回归系数的未知向量。
 (9)
(9)
模型解的稀疏性是变量选择的核心,稀疏性也能大致表现“降维”的结果。变量系数真实值为0并且估计值都为0的概率为1,则称函数解具有稀疏性。也就是使原本系数值就比较小的系数的估计值被设置为0,这样就将无效变量踢出了模型,目前解决稀疏问题比较有效的方法是惩罚方法。
2.2. EN和AEN方法
2.2.1. 诺曼图
诺莫图(Nomo gram)主要是以变量的系数大小来制定评分标准,给每个自变量的每种取值水平一个评分,由观测值对应的变量就可以得到一个综合评分,转换后和结果发生概率进行对比就能计算出观测值的结果发生概率。在试验中,检验方法我们都是选择的3-fold CV检验,在有关k-fold CV 的学习中,可以知道实验数据集选择3折交叉验证是不错的选择,满足试验要求而且计算量相对较简便一些。
计算得到的EN和AEN约简的诺曼图(见图1、图2)的结果可以知道,EN方法将之前的27个变量减少到了5个(AGE, AAA, CREAT, IMT, ALBUMIN),AEN方法则将变量减少到了6个变量,两者的降维效果都很显著。根据诺曼图可以“测度”一个变量的得分,比如AGE = 45,AAA = 15,CREAT = 400,IMT = 2.5,ALBUMIN = 2,那么综合得分就大约为117分,2年后的生存概率就约为87%,AEN诺曼图也是同理。诺曼图像一张“预测表”,将观测值对应的指标进行评分,再对应到综合评分对应的生存概率,这样就能预测到观测值的生存概率。

Figure 3. Survival analysis chart of EN
图3. EN方法的生存分析图
2.2.2. 建立Cox模型
直接运用诺曼图中选出的变量建立Cox生存模型,展示为图3和图4:
在两种生存分析图中,蓝色曲线(SEX = 2)都略高于黄色曲线(SEX = 1),说明女性在相同的情况下存活的概率更大,生存函数得到的系数估计值如表1所示。

Figure 4. Survival analysis chart of AEN
图4. AEN方法的生存分析图

Table 1. Model coefficients corresponding to EN and AEN
表1. EN和AEN对应的模型系数
系数表中有各变量对应的系数,可以看出变量AAA的系数在五个变量中最大,即变量AAA有较大权重影响模型结果。
2.3. Snet和Mnet方法
诺曼图
与EN、AEN同理,Snet、Mnet得到所示的诺曼图(见图5、图6):Snet和Mnet得到的结果相似,Snet方法维数约简后得到的变量较Mnet方法多,这也可以更加贴切的得到综合评分,预测也会更加贴合实际情况。Snet最终得到19个变量,Mnet最终得到的18个变量,此时影响较大的是变量依然是AAA,Snet和Mnet这两种方法的一致性大小是一样的,参考资料和实验数据可以知道在实际运用中Snet会更加优质一点,且Snet适应的情况更多,适应性更加广泛。
建模得到的系数结果如表2所示,可以看出变量AAA的影响力最大其次是变量IMT,这和EN和AEN方法的结果相似。Snet方法最终得到的变量比EN、AEN方法多很多,且一致性检验值比前两者都大,又达到了降维的目的,所以Snet方法即能降低模型的稀疏度,又可以防止过拟合的情况出现,是很好的一种建模方法。

Figure 5. Norman diagram of Snet method
图5. Snet方法的诺曼图
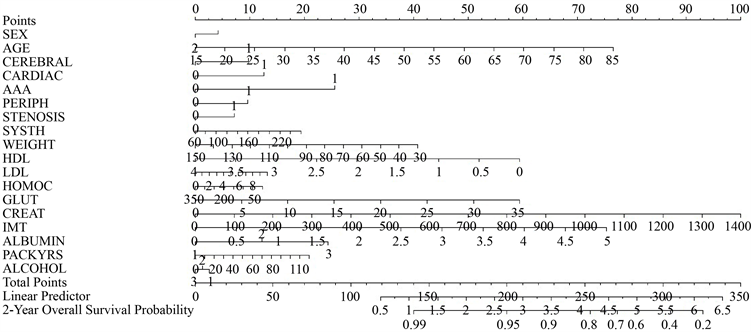
Figure 6. Norman diagram of Mnet method
图6. Mnet方法的诺曼图
Table 2. Model coefficients corresponding to Snet and Mnet
表2. Snet和Mnet对应的模型系数
3. 总结与讨论
随着大数据行业的不断发展,如何在海量数据中快速且有效的找到能展现总体特征的变量,对我们来说是很大的挑战,而针对高维数据的独特数据格式,LASSO系列算法又通过不同的考量得到了多种维数约简的解决方法。本文结合理论与实践,主要介绍了以EN为核心的多种维数约简方法,如何平衡变量的共线性和稀疏性成为几种方法的核心知识点,用不同的检验方法对这四种维数约简方法的结果做比较汇总得到表3的汇总表:
Table 3. Three test results of four dimensionality reduction methods
表3. 四种维数约简方法的三种检验结果
三种模型检验的结果说明Snet和Mnet的拟合效果比较好,这和之前的结果推测一致,次之是AEN方法,最后是EN方法。一致性检验是评价模型的预测性能的,仅适用于比较同一模型的“预测性能”。一致性检验会在0.5~1之间,然而在实际应用中较高的一致性是很难达到的,所以这里的0.691预测性能值可以是预测性能较好的表现。本文对几种维数约简的方法比较,是建立在Cox生存模型的基础上的,如何将LASSO系列的变量选择方法推广到更多统计模型的研究是必要的,且目前评估降维的方法较单一,如何寻找到合适的高维模型评估方法也应与维数约简方法同步发展,这也可以有利于进一步的研究更多高维数据分析方法的优劣性。
NOTES
*通讯作者。