1. 介绍
工业知识自动化势在必行,工业知识图谱亟需大力推行,而命名实体识别(NER)既是自然语言处理(NLP)中的一项重要任务,也NER被广泛认为是知识图构建过程中的第一步,是知识图谱构建过程中的下游自然语言处理的重要基础例如实体链接,关系提取,事件提取和共引用解析。
就一般的NER而言,高性能方法主要包括递归神经网络(RNN),支持向量机(SVM)或长短期记忆(LSTM)和门递归单元(GRU),以获取单词级别的上下文信息, [1] [2] 所示其在英文领域取得了巨大成功,而由于中文句子没有与英文句子相同的自然定界符,而且中文句子中不同的分词可能导致句子的含义完全不同。汉语分词的问题还没有得到很好的解决。 [3] [4] 可以看出,如果第一次错误地检测到边界,那么使用基于单词的NER模型进行正确提取就不可能了。最近,大多数用于中文NER的神经网络模型都严重依赖于出色的词嵌入表示形式和额外的词典,基于字符的方法比基于词汇的方法更适合中文NER [5]。
目前已有部分研究针对其他垂直邻域的实体抽取实验 [6] [7] [8] [9],可是前提都需要大量的工作和极度依靠预训练模型性能。就工业领域NER而言,存在数据低资源和知识高门槛两大问题。数据低资源不止体现在工业机器人领域文本数据量少,还有专业质量不一,例如工程师甲描述某件事故为“电机发热冒烟”,而工程师乙则描述为“电机转子铁芯硅钢片绝缘损坏,电机运行温度过高或冒烟”。工程师的描述不一致,同一件故障会有多种描述,甚至缺少实体,导致模型训练更难拟合,这种问题在缺少训练数据的情况下更为严重。数据集的质量差还体现在由于存在标准模糊,尺度难把握,认知水平存在差异等问题,甚至工程师撰写日志时图方便而自定义一套易记语言,或者时描述不清晰,缺少实体,都会导致数据的标注质量差。对于工业领域数据集的专业性,使用一般模型并不能很好地识别其中极具专业性的实体。例如“动圈铁芯”这样的实体一般很难出现在一般数据集上,而且模型很容易将其识别成“动圈”和“铁芯”两个实体,甚至其他,很明显这是错误的。
而在工业领域的NER研究少之又少,针对这一问题,在研究过程中利用工业生产场景下电动机工作日志作为我们本次实验的种种一个目标数据集。基于字符的NER无法充分利用显式单词和单词序列信息,这也会影响NER的性能。为了解决这个问题,我们提出了一种基于自我注意机制的变压器模块来表示字符并将潜在的词汇信息集成到基于字符的LSTM-CRF中。如图1所示,我们使用Transformer模块 [10] 搜索与上下文相关的字符,并输出包含与字符相关的信息的向量表示。门单元用于在包含多个字符信息的向量之间动态路由信息。最后,使用条件随机场(CRF)来整合和标准化在NER数据集上训练的预测,我们的方法可以从上下文中自动有效地找到更多有用的单词,从而获得更好的性能。与基于字符和基于单词的NER方法相比,我们的模型可以自动获取上下文词汇信息,而无需使用其他外部资源。而且由于其加入了Transformer模块和LSTM,能对前后文的特征信息有更充分的学习,更有利于学习专业性强的长实体。在OntoNote [11]、Weibo NER [12]、Chinese Resume [13] 和工业电机数据集上我们的方法在各项指标上都有具有竞争力的提升。
2. TB-LSTM-CRF模型
为了从相邻字符中捕获信息。我们采用LSTM-CRF作为主要网络结构,并研究了中文NER的Transformer模块,该模块由一个自我注意层组成。
在本文中,我们使用BIOES标记方案 [14] 进行实验。我们将输入句子序列表示为
,其中
表示句子
中第i个字符嵌入向量,而m表示最大句子长度。相应地,我们定义
作为句子预测序列,其中
表示句子Y中第i个字符嵌入向量。目的是通过模型函数
来获得实体类别序列。
2.1. Transformer模块
Transformer模块旨在对输入字符序列进行编码,并在上下文中隐式对含义相关的字符进行分类。
第i字符的d维嵌入向量用
表示。模块整体框架如图2所示。
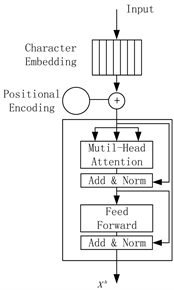
Figure 2. The overall framework of the transformer block
图2. Transformer模块整体框架
2.1.1. 位置编码
Transformer模块按照位置编码来理解语言的前后文,并使用self-attention机制和完全连接。Transformer模型没有递归神经网络的迭代操作,因此我们需要将每个单词的位置信息提供给Transformer模块,以便该模型可以识别句子中字符的顺序关系。位置嵌入被初始化为一个向量,其维度为(字典大小,嵌入维度),并按以下两个部分计算:
(1)
(2)
在上面公式里,pos表示字符在句子中的位置,取值范围是[0,最大句子长度]。i表示字符向量的第i个维度,取值范围是[0,最大嵌入维度]。d表示字符向量的维度数量。这里有一对正弦和余弦函数,它们是与嵌入向量维度相对应的一组奇数和偶数的维。
然后将字符嵌入和位置编码对应相加,最后获得了包含位置信息的新字符嵌入向量
。
表示第pos个字符的位置编码。
(3)
2.1.2. Self-Attention机制
为了有效地学习句子中单词的依存关系并捕获句子的内部结构 [15],我们使用多头注意力(multi-head attention)来处理先前的特征向量
。我们分配三个权重矩阵W_Q,W_Q,W_Q ∈ R ^ (embed.dim * embed.dim)并根据以下公式线性映射后获得三个权值矩阵
,和通过下面线性映射公式得到三个特征矩阵
:
(4)
(5)
(6)
然后,我们可以通过以下公式得到注意力矩阵:
(7)
表示注意力矩阵,
的目的是使注意力矩阵遵循标准正态分布,从而使softmax层的结果更稳定。
2.1.3. Add & Layer Normalization
上一小节获得了注意矩阵H。我们对其进行转置以使其与特征矩阵Λ的尺寸一致,然后由于元素的尺寸相同,直接将这两个矩阵相加。
(8)
Layer Normalization的作用是将神经网络中的隐藏层归一化为标准正态分布,从而加快训练和收敛速度:
(9)
其中
是注意力矩阵H的第i行和第j列,
是一个很小的数字,可以防止方程中被零除。引入两个可训练的参数
和
来弥补归一化期间丢失的信息。
注意,⊙表示元素乘法而不是点积。通常,我们将
初始化为1,将
初始化为0。
和
分别代表每行的均值和方差。计算公式如下,其中m表示矩阵H中的列数。
(10)
(11)
2.1.4. Feedforward
在前馈网络部分,此处使用两级线性映射,并通过ReLU激活函数进行激活。在前馈网络之后,后续的剩余连接和层规范化与前一小节中的类似,不同之处在于前一个H由前馈网络的输出代替。
2.2. Long Short-Term Memory (LSTM)
LSTM的目的是进一步处理上下文序列关系,其输入是Transformer模块输出的特征向量。
2.3. Conditional Random Field (CRF)
为了提高序列标签预测的准确性,我们需要参考相邻字符的预测结果。这是序列标记的问题,也是CRF可以完美适配的工作。在LSTM输出该句子中每个字符的隐藏状态
,
,
,
之后,我们利用标准的CRF层来接收它。
2.4. Training and Inference
一阶维特比算法用于在基于字符的输入序列上找到得分最高的标签序列。我们使用句子级别的对数似然损失和
正则化来训练模型:
(10)
此处
和
分别是为
正则的自定义设置参数。
3. 实验和结果
为了验证我们提出的方法的有效性,我们对涉及不同领域的几个中文NER数据集进行了一些实验。我们采用以下评估指标,分别采用标准精度(P),召回率(R)和F1得分(F1)。实验数据集的详细信息将在表1中显示。
我们的实验中使用了三个数据集,分别包含在OntoNote [11],Weibo NER [12] 和Chinese Resume [13]。OntoNote数据集和WeiboNER数据集均包含4个命名实体类别:PER (人),ORG (组织),LOC (位置)和GPE (地缘政治实体)。中文简历数据集使用八种类型的命名实体进行注释:CONT (国家/地区),EDU (教育机构),LOC,PER,ORG,PRO (专业),RACE (种族背景)和TITLE (职位)。
使用以上三个数据集,我们将TB-LSTM-CRF方法的性能与最新技术水平进行了比较,并形成了便于参考的表格。LSTM + CRF是基线方法。
3.1. OntoNote数据集
从表2的显示中可以看出,在包含4个实体分类的OntoNote数据集上,我们的方法在准确性和F1得分指标上取得了最佳结果。我们的方法比最近的Zhang et al. (2018) [13] 的准确性高2.43%,在F1分数上比最好的Zhang et al. (2018) [13] 高0.7%,比Zhu et al. (2019) [16] 低1.07%。与基线相比,我们提出的新方法已经取得了全面的改进。

Table 2. Result on OntoNote
表2. OntoNote数据集上的结果
3.2. WeiBo数据集
在WeiBo数据集上,与最近的高级方法相比,我们提出的方法仍在三个指标上进行了改进。与基线方法相比,F1得分甚至提高了8.48% (表3)。
3.3. Chinese Resume数据集
与之前的数据集相比,Chinese Resume数据集具有较少的命名实体和更多的命名实体类别。我们的方法在此数据集上的性能比前两种方法稍差。Zhu et al. (2019) [16] 在该数据集上的准确性和召回率均达到了最佳性能。我们的模型在F1得分上得分最高(表4)。
Table 4. Result on Chinese resume dataset
表4. 中文Resume数据集上的验证结果
3.4. 工业电机数据集
我们提供了一个全新的数据集,工业电机数据集。其中包含工业场景里电动机的运行状态及诊断信息,包含了大量富有专业性的长实体。由于网上极少公开工业相关的实体识别数据集,本次数据集合极有可能是第一个相关领域实体识别数据集。我们的电动机工业数据集的静态统计如表5。
Table 5. Statistics of industrial motor data set
表5. 工业电机数据集静态统计信息
在该数据集上,我们的方法在各项性能上都处于领跑地位(表6)。
Table 6. Result on industrial motor dataset
表6. 工业电机数据集上的验证结果
3.5. 联合数据集
为了验证我们的模型是否需要大量的外部资源,我们除了在单个数据集(工业电机数据集)中进行训练如3.4节实验外,我们还将模型从其余三个数据集上先预训练,保留训练结果后模型参数,最后将各参数作为初始值,重做一遍实验。得出结果如表所示。其F1分数值随迭代次数增加折线图如图3。
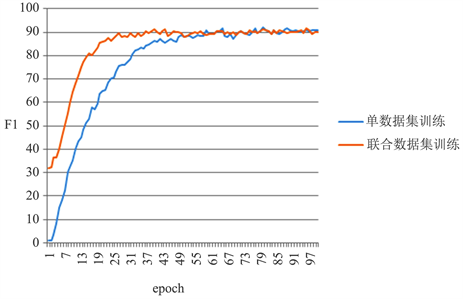
Figure 3. F1 score values of TB-LSTM-CRF experiments on the industrial motor dataset and the joint dataset
图3. TB-LSTM-CRF分别在工业电机数据集和联合数据集上实验的F1分数值
结果表明,虽然我们的模型在F1分数提升速度上比具有丰富资源的联合数据集方法训练模型时增长的快,可是最终两者的F1分数最终都趋于统一。表明,我们的模型在缺少训练样本,或外部特征资源时仍然具有竞争力。
4. 结论
在本文中,我们使用了Transformer模块和LSTM结合来提高中文NER模型的性能,在3.4节实验中说明我们的模型几乎无需依靠其他额外资源也能快速得到优异的F1分数值,而且我们的模型更加微型和实用。在3.1到3.3节实验表明,在不同的域数据集中,我们的模型可以比其他方法效果更好。
对于将来的工作,我们将继续改进我们的模型,使其更适合具有更多标签类别的任务。我们甚至将其扩展到实体关系的联合抽取任务上。
基金项目
《工业过程数据实时获取与知识自动化》,国家自然科学基金委员会资助项目,项目编号:U17012621006336。《广东省新兴海洋经济产业地图与大数据平台》,广东省促进经济高质量发展专项资金项目。
参考文献