1. 引言
随着我国汽车保有量的增加,城市面临的交通管理压力也越来越大,智能交通系统的建设迫在眉睫。车牌识别作为智能交通系统的重要组成部分,广泛应用于高速公路收费管理、停车场出入管理、道路交通监控等场景。
传统的车牌字符识别方法首先需要分割车牌字符,输出一组单个的字符图像,然后使用模板匹配 [1]、特征提取 [2] 和神经网络 [3] 等识别算法对其进行识别,将各个字符图像的识别结果顺序组合起来便得到车牌的识别结果。这些方法很大程度上依赖字符分割的准确性,而且在识别时需要对大量的车牌特征进行提取,识别效率低。近年来,由于强大的特征学习能力,卷积神经网络(CNNs)在解决许多经典的计算机视觉问题上取得了巨大的成功,例如图像分类和语义分割。基于CNN的车牌识别算法 [4] [5] 也相继被提出来,用于解决错误的字符分割导致车牌识别率下降的问题。Li等人 [6] 将车牌识别问题看作一个序列建模问题,利用CNN提取车牌区域特征,然后送入LSTM [7] 网络提取上下文关联信息,最后利用CTC [8] 算法进行判别得到车牌序列信息。Zherzdev等人 [9] 提出一种无需使用递归神经网络(RNN)的轻型卷积神经网络,用于快速识别车牌字符。Zhang等人 [10] 提出一个端到端的模型,直接通过CNN完成整个车牌的识别,比文献 [6] 中的方法更为简单。
上述基于CNN的车牌识别算法主要研究不同的网络结构对识别准确率的影响,他们由传统的卷积层组成。卷积层是CNN的核心构建模块。因此,这些核心模块的改进通常可以提高CNN的性能。一些用于替代传统卷积层的方法相继被提出来,这些方法可以提高CNN的特征学习能力或效率 [11] [12]。深度过参数化卷积 [13] (Depthwise Over-Parameterized Convolutional Layer, DO-Conv)由Cao等人提出,可以提高CNN在许多经典视觉任务上的性能,如图像分类、检测和分割。本文将其应用于车牌识别任务中,提出一种融合DO-Conv的车牌识别算法,用于提升车牌特征提取的有效性,从而提高车牌的识别准确率。
2. 深度过参数化卷积
与常规卷积不同,深度过参数化卷积DO-Conv在常规卷积的基础上添加一个用于过参数化的组件:深度卷积。一般认为,通过在网络中添加线性层和非线性层来增加网络深度可以提高网络的表达能力,提升网络性能。但是使用更深层次的网络结构往往会增加神经节点的计算量。过参数化的一个明显优势就是过参数化使用的多层复合线性操作在训练阶段之后可以折叠为紧凑的单层形式。然后在推理阶段仅使用单层计算,从而减少了计算量。此外,DO-Conv不仅可以提升融合模型的性能,还可以加快CNN的训练速度。
深度过参数化卷积的结构如图1所示。深度卷积算子
首先应用于深度卷积内核D和输入特征P,生成变换后的特征
。然后常规卷积运算符
应用于常规卷积内核W和特征
,生成变换后的特征
。因此,深度过参数化卷积的输出可表示为:
。在图1中,M和N为输入向量的空间维度,
为输入向量的通道数,
为输出的通道数,
为深度卷积的深度乘数。
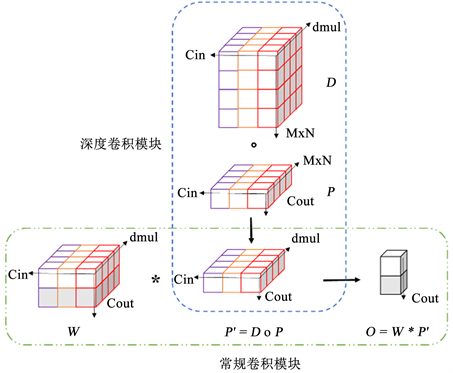
Figure 1. Deep over-parameterized convolutional structures
图1. 深度过参数化卷积结构
3. 基于DO-Conv改进的端到端识别网络
本文提出的基于DO-Conv改进的端到端车牌识别模型包含3个模块:基于DO-Conv改进的特征提取模块、特征序列化模块和序列解码模块。图2给出了所提模型的流程图,图3给出了所提模型的网络结构,模型中3个模块说明如下。

Figure 2. The flow chart of the proposed model
图2. 所提模型流程图
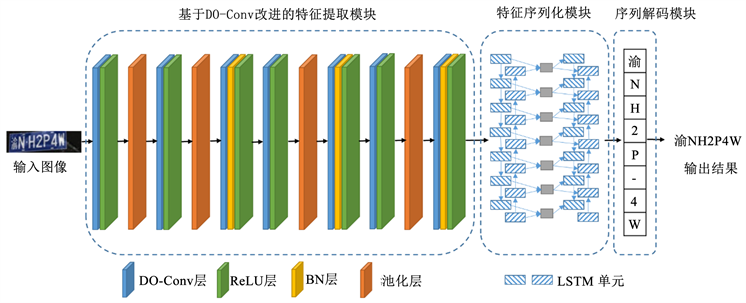
Figure 3. The proposed model network structure
图3. 所提模型网络结构
3.1. 基于DO-Conv改进的特征提取模块
随着卷积神经网络的发展,其网络结构使用的卷积层数也在不断增加,在增强网络的表达能力时也带来了更大的计算量。针对这种情况,本文设计了一种基于DO-Conv改进的卷积神经网络,通过引入DO-Conv替换传统的卷积方式,可以在不增加网络层数的情况下提升网络的特征提取能力。
本文网络结构以VGG网络作为基础网络框架,其网络结构如图3所示。其中,输入图像统一处理为110 × 32大小的灰度图像。就网络卷积过程而言,整个卷积网络由7个DO-Conv层及最大池化层构成。此外,Batch Normalization和ReLU函数被用来加速训练过程,提高网络的泛化能力。该网络通过对样本进行卷积、池化操作进行特征提取。
DO-Conv层:卷积网络中的特征提取层。卷积过程如第1章所述,卷积操作之后传递给激活函数,得到的结果是一组特征图。不同的特征图提取不同的特征。
池化层:也叫下采样层,本文采用最大池化,主要操作是取区域上的一个值做下采样;其目的是进一步减少网络的参数,保持某种不变性(旋转、平移等)。
网络的具体参数设置如表1所示,其中filters表示卷积核的个数,k表示卷积核的尺寸,s表示步长,p表示填充。

Table 1. Fusion of CNN parameter settings for DO-Conv
表1. 融合DO-Conv的CNN参数设置
3.2. 特征序列化模块
特征序列化模块是将提取出来的图像特征进行序列化,并实现与输入标签的序列到序列映射。本文采用长短时记忆网络(Long Short-Term Memory, LSTM)来进行序列化。整个模块由两层双向LSTM和全连接层组成,如图2所示。其中,每个双向LSTM层均由两个相对的LSTM构成,每个LSTM都有128个隐藏节点。全连接层有71个由Relu激活的神经元,对应71个类别(即37个中文字符,10个数字,24个字母,不含“I”、“O”)。当输入特征序列X时,全连接层的输出可表示为
,其中
为第t个特征序列对应的序列标签。
3.3. 序列解码模块
本文采用链接时序主义分类(Connectionist Temporal Classification, CTC)来对特征序列化模块的输出进行解码,预测最终的识别结果。CTC通过使用Softmax层将循环层的输出
转换成概率序列
,其中T是特征序列的长度且
(1)
首先,用L表示任务中的所有标签。定义一组长度为T的序列
,
。
包含所有预定义的标签,包括一个“blank”标签
。我们将在全部时间步长里依次观察到的标签作为路径π。
为了处理路径π和目标序列l之间的关系,CTC定义了多对一映射β。β首先删除重复的标签,然后删除所有的空白标签。给定标签序列l,将可行路径定义为能够从l映射到β的所有π。每个目标的条件概率被定为所有可行路径概率的和,即:
(2)
其中
(3)
其中
是路径
中的第t个元素,
是标签
的评估概率。
4. 实验结果分析
4.1. 数据集
由于没有公开的大型中文数据集,本文使用opencv根据国内车牌规则生成各种类型的合共12万张车牌图像的合成数据集,图像的分辨率均为110 × 32。部分生成图像如图4所示。训练集和测试集之比为8:2,即训练集104,000张,测试集26,000张。
为了验证所提模型在真是环境中的性能,本文还使用了开源中文车牌数据集SYSU [14]。SYSU数据集采集了超过3000张来自道路交通监控探头的车牌图像样本。由于该数据集未标注车牌位置,采用开源软件HyperLPR对车牌区域进行定位,成功定位3671张图像,其中2939张被用于训练,剩余732张被用于测试。
4.2. 实验设置
本文实验算法采用编程语言Python、C++编写,使用pytorch框架实现。其他软硬件配置如下:Intel Core i7-8700k 3.70 GHZ 12核8G内存,NVIDIA 1080ti显卡,显存11 GB,ubuntu16.04LTS系统。
网络训练的学习率为1e-5,模型的batch size为128,模型使用RMS优化器进行优化。
4.3. 评价指标
本文采用识别准确率(RA) [15] 来评估车牌识别模型的性能,计算公式如下:
(4)
其中R是正确识别所有字符的车牌数量,N是用于测试的车牌数量。
4.4. 实验结果
为了探讨DO-Conv卷积层对车牌识别准确率的影响,本文将模型中的DO-Conv层替换为常规卷积,然后分别在SYSU数据集和合成车牌数据集上进行消融实验。实验结果如表2所示。
Table 2. Comparison of structural performance of different models
表2. 不同模型结构性能对比
由表2可知,本文所提模型在SYSU数据集和合成数据集上分别比使用常规卷积的模型高0.27%和0.52%,两者的性能差距证实了本文提出的识别模型有助于提升车牌识别的准确率。绘制了合成数据集中测试准确率与训练次数关系图,如图5所示。从该图中可以看出,在训练过程中使用Do-Conv卷积层的网络的准确率上升速度更快,且明显高于使用传统卷积层Conv的准确率曲线,表明使用DO-Conv层不仅可以提高车牌识别的准确率,还可以加快神经网络的训练。
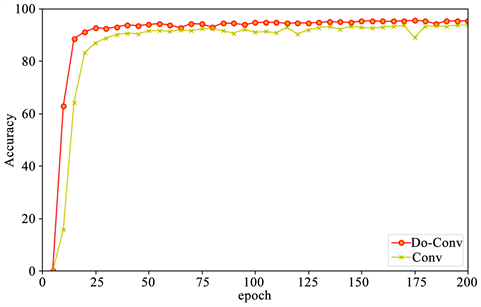
Figure 5. Relationship between test accuracy and training times in synthetic data set
图5. 合成数据集中测试准确率与训练次数关系
此外,为了进一步验证本文模型的有效性,还与文献 [9] 的方法进行了对比,实验的结果如表3所示。与文献 [9] 的方法相比,本文提出的基于DO-Conv改进的端到端车牌识别方法在两个数据集里都获得了较高的准确率。
表3. 不同方法性能对比
5. 结论
由于大多数基于CNN的车牌识别算法主要研究不同网络结构对车牌识别准确率的影响,很少有方法研究不同卷积层对识别准确率的影响。本文提出了基于DO-Conv改进的端到端车牌识别算法。该算法对传统的端到端算法进行改进,在特征提取阶段将原有的卷积方式替换为为深度过参数化卷积DO-Conv,提升图像特征提取的有效性,然后使用LSTM网络对提取的特征进行序列化,最后使用CTC算法进行解码输出。通过在合成车牌数据集和SYSU数据集上的实验表明,改进后的网络模型对于车牌识别的准确率更高,分别达到了97.42%和95.08%。同时,改进后的模型的训练效果更好。与现有方法的对比也进一步表明了本文所提方法的有效性。