1. 引言
回归分析是一种确定多个变量之间依赖关系的统计分析方法,已经广泛应用于各大学科领域,例如经济学 [1]、医学 [2]、气象学 [3]、人文学 [4] 等一系列的领域。随着统计学的不断发展,回归分析模型更广泛的应用于数据分析。施龙青等人 [5] 基于多元回归方法进行防隔水断层的预测,这种多元的回归方法,基于先前的经验,人工给定参考模型,虽然预测结果也是相对准确的,但需要人工干预。卢骏等人 [6] 对大坝变形问题进行了变系数回归建模,该方法需要事先给出一种模型,然后进行参数估计。Taylor首先提出了回归神经网络,不仅能运用到金融方面,避免了那些不必要的损失之外,而且还能用神经网络的结构预测没有开发出来的、潜在的曲线模型,对其进行较为准确的预测。虽然回归神经网络能对数据进行相对准确的预测,但是它的操作是一个黑箱操作,无法看清箱内的计算过程和产生的模型,在多数情况下,是很难理解这一过程的。
通过以上分析,现有回归分析方法一般要求用户给出参考模型,通过数据样本分析,求出最佳的模型参数。然而,在多数情况下,用户难以给出参考模型,或者所给出模型具有较大的误差。因此,针对该问题,本文提出一种基于遗传算法 [7] 的模型寻优方法。利用了遗传进化的思想,首先随机产生大量初始模型种群,然后按照一定的遗传进化法则对模型进行淘汰,找出一个接近于最优解的模型,最后对该模型进行参数估算。
2. 方法设计
首先给出问题定义,然后基于遗传算法进行模型设计。根据个体编码随机产生N个初始模型的种群,然后进行交叉、变异操作,按照适应度函数和个体的选择方式,从种群中选出下一代种群,继续进行寻优过程,不断迭代直到找出较优解。
2.1. 问题定义
在参考模型未知时,对数据进行回归分析,将该问题定义如下:
已知:1) n个自变量的个数和取值。
2) 可供选择的基本单目运算符:“x”,“x2”,“
”,双目运算符号:“+”、“−”。
3) 双目运算符的个数N (决定回归方程的长短,N越大,回归方程越长)。
求解:因变量y关于x的回归方程。
2.2. 个体编码
2.2.1. 编码长度
对回归模型进行编码,模型的长度是由其中双目运算符的个数确定的,不同的双目运算符个数,产生的编码长度是不同的。把双目运算符的个数记为n,那么编码长度N (N的初始值为2)和双目运算符个数n之间的关系可以用公式(1)来表示:
(1)
2.2.2. 编码规则
将参与回归模型编码的算子分为三类,分别是单目运算符、双目运算符和操作数。然后对这3种类型的算子进行编码设计,如表1所示。
这3种算子按照单目运算、操作数1、双目运算、操作数2的顺序进行组合,随机产生个体编码。不同的编码长度对应的编码规则有所不同,编码规则采用嵌套的格式,其中操作数可以由单目运算和操作数的组合产生。例如,当n = 0时,编码长度为2位,只存在单目运算和操作数,是最简单的原子操作,对某个操作数进行单目运算。例如:编码“21”表示“
”;“32”表示“
”;“23”表示“
”。当n = 1时,编码长度为6位。例如:编码“121132”表示“
”;“212123”表示“
”;“321122”表示“
”。
2.3. 交叉和变异因子
假设染色体的长度为L,那么计算机随机产生一个(1, L)范围内的整数r,然后把要交叉 [8] 的两个母代个体从r这个位置截为两段,分别交换母代个体的后半段,就产生了新子代个体。
种群中每个个体都要按照变异概率判断是否变异 [9],一般情况下变异概率是小于0.5的,甚至小于0.1,所以最终的种群中只有一少部分的个体发生了变异,本文采用单点变异的方法,变异的位置点是随机产生的。
2.4. 个体的选择方式
选择操作在遗传算法中起到关键作用,选择出的个体是否优胜会决定后代个体的质量,在此,适应度函数选用均方误差(MSE)来评判。使用轮盘赌算法 [10] 对种群中的个体进行选择。假设,先把个体适应度函数的值记为F(i),种群中所有个体适应度的值为TotalF,每个个体被选中的概率记为p(i),那么
(2)
由公式(2)得出,个体i适应度值越大,p(i)的值越大。把后代种群数量记为S,就意味着,一共要执行S次轮盘赌算法,从原始种群中选择出S个个体,放入子代种群中进行交叉变异等操作。
2.5. 建立回归模型的基本步骤
基于遗传算法的回归模型寻优方法,主要利用遗传算法适者生存、优胜劣汰的思想寻找较优的模型,然后利用梯度下降法进行参数回归。其基本步骤如下:
输入:含有N个自变量值的文本文件;
输出:回归模型。
Step1:根据遗传算法参数初始化的历史经验,对种群规模(M)、交叉发生的概率(Pc)、变异发生的概率(Pm)、终止进化的代数(G)进行初始化。根据1.2节编码规则,随机产生第一代初始种群Pop;
Step2:do

Step3:根据Step2产生的模型,用梯度下降法进行参数回归。初始化迭代步数为S,模型参数为
;
Step4:迭代更新这些参数使目标函数J(θ)不断变小,直到迭代次数到达S停止迭代,J(θ)的计算如公式(3)所示:
(3)
3. 实验与结果分析
为了验证本文所得模型预测的准确性,进行回归分析实验。本次实验对一组化学动力学反应的数据进行回归分析,该数据是在数学建模比赛中测得的真实数据,主要分析反应速度和反应物含量的关系。将相同的实验数据分别用于本文方法和最小二乘法回归分析方法,比较两种方法结果的误差大小。本次实验采用的操作系统是Windows2007,编译工具为myeclipse2014。
3.1. 实验过程
3.1.1. 基于遗传算法的回归模型寻优方法
首先,将化学动力学反应数据存入一个文本文件,各个变量之间用空格隔开,实验数据如表2所示。初始化算法参数,设置种群大小为50,交叉的概率为60%,变异的概率为0.3,迭代次数为50。

Table 2. Relationship between reaction rate and reactant content
表2. 反应速度和反应物含量的关系
实验得到编码为“113131”的模型,根据1.2节个体编码可以得出,该编码对应的回归模型为:
,得到参数估算结果分别为:0.76和0.3,综上所述,本文方法所得的模型为:
。
3.1.2. 最小二乘法回归分析方法
“统计产品与服务解决方案(spss) [11] ”软件可以对数据进行回归分析,使用该软件对化学动力学反应数据进行最小二乘法回归分析得到的结果如图1所示。t值是单样本检验,展现了该自变量对因变量是否有显著性影响,最后一列的t值所对应的Sig值,如果小于0.05,代表该自变量对结果的影响程度越高,表中系数一列表达了该自变量在回归方程中的系数,如果系数为正,该自变量与因变量则为正比例的关系;如果系数为负数,那么自变量与因变量就为反比例的关系。
由图1可得,反应物氧气x1,对应系数为:−0.386,反应物戊烷x2,对应系数为0.701,反应物异构戊烷x3,对应系数为−0.509。综上所述,最小二乘法回归分析所得模型为:
。
3.2. 两种模型预测应用
分别运用以上两个模型对化学动力学反应中的反应速度进行预测,预测结果如表3所示。
Table 3. Comparison of prediction results of two models
表3. 两种模型预测结果对比
将以上预测数据进行对比,结果如图2所示。使用本文方法所得模型进行预测,结果波动不大,与原始数据相差较小,而最小二乘法回归模型预测出现负值,波动较大,与原始数据相差较远。
由公式(4)计算两种模型预测结果的均方根误差,最小二乘法回归分析预测结果的误差为14.24,本文方法得出模型预测结果的误差为9.59。
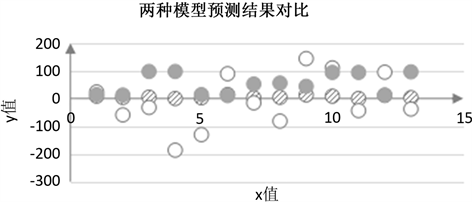
Figure 2. Comparison of prediction results of two models
图2. 两种模型预测结果对比图
(4)
两个误差结果比较可得:
,显然,本文方法得到的模型误差更小。但在设计个体编码的过程中,由于单目运算和双目运算种类的限制,模型的表达范围缩小,使得模型的准确度降低,误差仍然较大。
4. 结语
本文提出了一种基于遗传算法的回归模型寻优方法,该方法能够在参考模型未知的情况下计算出回归模型,并进行参数估算。实验表明,基于遗传算法的回归分析模型,在进行预测时,与最小二乘法回归分析模型比较,误差更小。本文方法仅针对双目运算符中的加减运算进行了研究,下一步工作是增加单目以及双目运算符的种类,使模型变得更加通用。
基金项目
国家自然科学基金青年项目(61702408);国家自然科学基金重点项目(51634007);陕西省自然科学基础研究计划项目(2019JM-020)。